一分钟一个Pandas小技巧(一)
在逛Kaggle的时候发现了一篇不错的Pandas技巧,我将挑选一些有用的并外加一些自己的想法分享给大家。
本系列虽基础但带仍有一些奇怪操作,粗略扫一遍,您或将发现一些您需要的技巧。
原网址:kaggle
纸上得来终觉浅,绝知此事要躬行,所谓的熟练使用Pandas是建立在您大致了解每个函数功能上,希望本系列能给您带来些许收获。
本篇所涉及知识点:
- 创建测试数据
- 行列索引设置
- 行列索引切片查询
- 统计函数
- 缺失值处理
- 显示维度过多数据
创建测试数据
Pandas自带的函数,避免了自己手写测试数据的痛苦。

索引设置
重命名索引
使用rename()可以对索引/列进行重命名,使用赋值的方法必须写出所有的列名,所以推荐rename()。
图中出现的axis=1是指列方向上进行操作,axis=0是行。这个很好记忆,只要想着1->竖的->列,那另一个0自然就是行了。

列索引添加前后缀
这个功能比较少用。

索引位置修改
修改列的位置其实就是通过列名进行索引,然后将查询返回的值赋值给原来的df就完成了列位置修改。
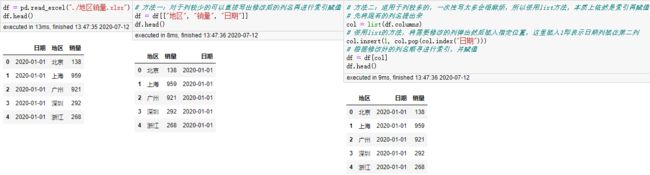
删除列
删除列,能少一行代码是一行。drop,del,pop任你选。
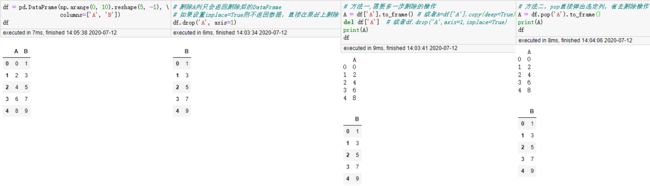
巧妙使用F-String创建列
“”.format()也是不错的选择。
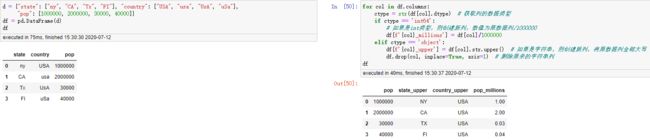
日期时间索引
日期索引可以玩出很多花式索引。
| 属性 | 说明 |
|---|---|
| year | datetime 的年 |
| month | datetime 的月 |
| day | datetime 的日 |
| hour | datetime 的小时 |
| minute | datetime 的分钟 |
| second | datetime 的秒 |
| microsecond | datetime 的微秒 |
| nanosecond | datetime 的纳秒 |
| date | 返回 datetime.date(不包含时区信息) |
| time | 返回 datetime.time(不包含时区信息) |
| timetz | 返回带本地时区信息的 datetime.time |
| dayofyear | 一年里的第几天 |
| weekofyear | 一年里的第几周 |
| week | 一年里的第几周 |
| dayofweek | 一周里的第几天,Monday=0, Sunday=6 |
| weekday | 一周里的第几天,Monday=0, Sunday=6 |
| weekday_name | 这一天是星期几 (如,Friday) |
| quarter | 日期所处的季节:Jan-Mar = 1,Apr-Jun = 2 等 |
| days_in_month | 日期所在的月有多少天 |
| is_month_start | 逻辑判断是不是月初(由频率定义) |
| is_month_end | 逻辑判断是不是月末(由频率定义) |
| is_quarter_start | 逻辑判断是不是季初(由频率定义) |
| is_quarter_end | 逻辑判断是不是季末(由频率定义) |
| is_year_start | 逻辑判断是不是年初(由频率定义) |
| is_year_end | 逻辑判断是不是年末(由频率定义) |
| is_leap_year | 逻辑判断是不是日期所在年是不是闰年 |

有时候,我们拿到的数据不一定是一列时间数据,而是分开的,我们就可以做如下操作,合并多列为DatetimeIndex。
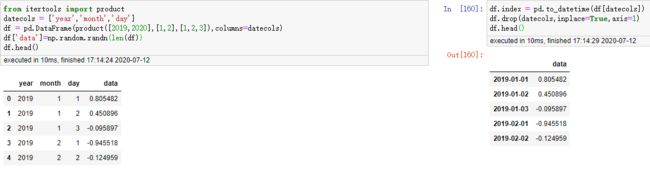
索引查询
单标签索引

切片
df.iloc[x1:x2:x3,y1:y2:y3]指的是搜索[x1,x2)行,间隔x3行(x3默认为1),搜索[y1,y2)列,间隔y3列(y3默认为1)。

loc/iloc/ix
loc,iloc,ix都是用来索引的,只是使用方式略有不同。
loc,iloc,ix的区别:
- loc是根据行列标签来进行索引
- iloc是根据位置来查询的,即行号列号
- ix是混合查询,即可以通过行列号也可以通过行列标签索引,但是要注意,行索引必须是行标签而不能是行号,列索引可以是列标签也可以是列号
我个人更喜欢用ix,虽然官方文档有写从Pandas 0.20.0起,这个方法将被弃用,但我用的版本是0.25.3,这个方法却仍然适用,只是会报错误警告。
官方推荐使用更为严谨的索引方式,即标签索引用loc,定位索引用iloc

at/iat
[]索引会消耗更多的资源来判断你需要的是什么,如果你只想查询某一个值,可以直接用at/iat,使用方式类似于loc/iloc。
at/iat只能使用标签/位置作为参数,不能使用切片":"。
实际测试下来同样取单个值at/iat和loc/iloc仅仅相差1ms(仿佛在逗我)。
所以,还是用loc/iloc/ix吧,记太多麻烦。
布尔索引(复杂索引)
Pandas的判断符号:
- &与,两者同时满足
- |或,两者满足其一即可
- ~非,满足条件的相反情况
- 切记’==‘判断是否相等,’='是赋值
使用多个条件进行过滤时,每个条件都需要用圆括号括起来
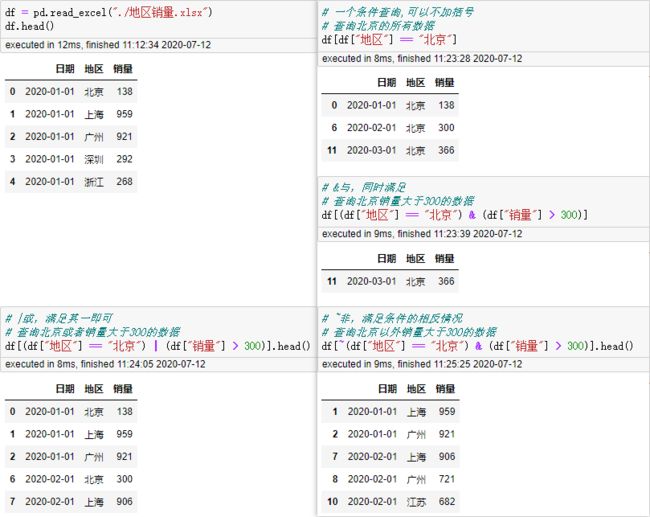
如果过滤条件过多我们可以将代码进行修改。 例如现在我要查询2020年1月份上海的销量。

上述方法适用于过滤条件很多很多的时候,不然,没啥必要。
快速计算离散值百分比
value_counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True)
| 参数 | 说明 |
|---|---|
| normalize | 默认false,如为true,则以百分比的形式显示 |
| sort | 默认True,根据ascengding排序排序 |
| ascending | 默认False,根据计数降序排列 |
| dropna | 默认True,删除np.nan |
| bins | 默认None,类似于qcut,输入数值自动分桶 |

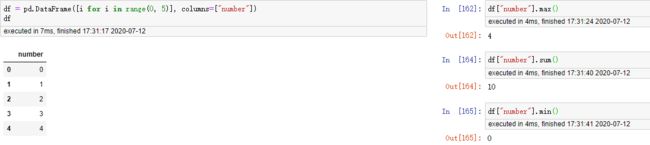
常见统计函数
| 方法名 | 函数功能 |
|---|---|
| sum() | 计算数据样本的总和(按列计算) |
| mean() | 计算数据样本的算术平均数 |
| var() | 计算数据样本的方差 |
| std() | 计算数据样本的标准差 |
| corr() | 计算数据样本的Spearman(Pearman)相关系数矩阵 |
| cov() | 计算数据样本的协方差矩阵 |
| skew() | 样本值的偏度(三阶矩) |
| kurt() | 样本值的峰度(四阶矩) |
| describe() | 给出样本的基本描述(基本统计量如均值、标准差等) |
统计函数返回的是一个值,并不是列。
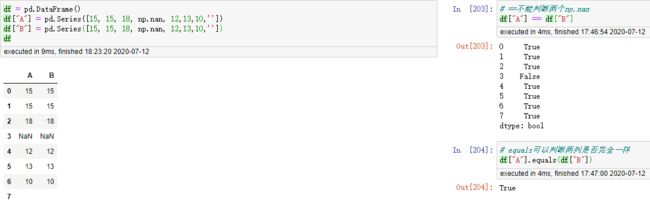
缺失值处理
处理缺失值的方法为:删除、填补、不处理。
更多的情况下我们根据缺失数值列的数据类型来判断处理方式:
- 缺失数据为连续性数据时,常采用均值填补
- 缺失数据为离散性数据时,常采用众数填补
- 机器学习,通过其他数据来拟合填补缺失值
判断空值的函数有isin(),isna(),isnull()(isnull()其实是isna()的别称)

判断两列是否相等。
缺失值填补。

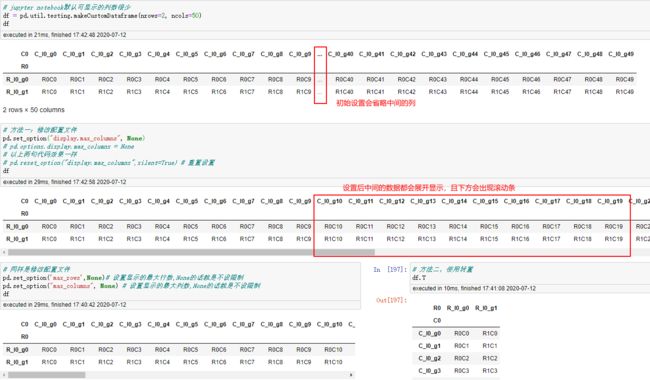
显示维度过多的数据
jupyter默认设置显示行数列数太少,当维度太多时,常常会出现…省略,所以下面给出两种方式。
- 修改配置文件
- 使用转置
str = “自从关注了这个公众号,我的追求者排队到五环开外{}!”

str.format(,做梦)
后台回复“pandas1”即可获取源码及数据哦!