机器学习|(I)机器学习概述
第一章 机器学习概述
文章目录
- 第一章 机器学习概述
-
- 1. 机器学习
- 2. 机器学习基础
-
- 2.1 数据的表达
- 2.2 内积与投影
- 2.3 基于矩阵的距离运算
- 2.4 优化:牛顿迭代和梯度下降算法
1. 机器学习
机器学习是一门多学科交叉专业,涵盖概率论知识,统计学知识,近似理论知识和复杂算法知识,使用计算机作为工具并致力于真实实时的模拟人类学习方式,并将现有内容进行知识结构划分来有效提高学习效率。
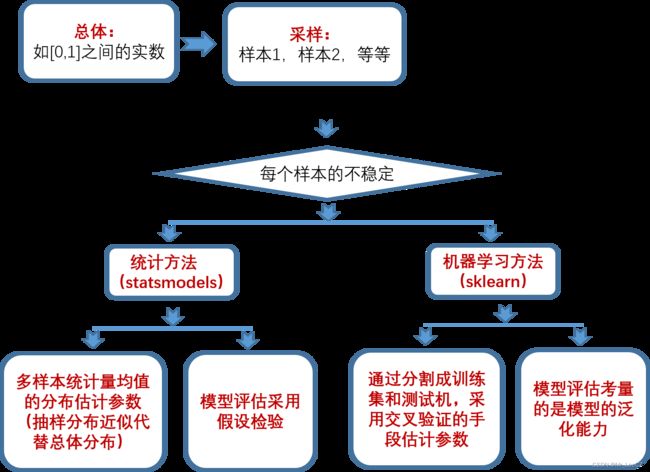

2. 机器学习基础
2.1 数据的表达
矩阵或者向量来源于线性方程组的求解
A x = b (1) \mathbf{Ax}=\mathbf{b}\tag{1} Ax=b(1)
其中, A ∈ R n × m \mathbf{A}\in\mathbb{R}^{n\times m} A∈Rn×m 称为矩阵, x ∈ R m \mathbf{x}\in\mathbb{R}^m x∈Rm 和 b ∈ R n \mathbf{b}\in\mathbb{R}^n b∈Rn 称为向量。式(1)中矩阵可看作列向量的堆砌 A = [ a 1 , a 2 , ⋯ , a m ] = [ w 1 ⊤ w 2 ⊤ ⋮ w n ⊤ ] \mathbf{A}=[\mathbf{a}_1,\mathbf{a}_2,\cdots,\mathbf{a}_m]=\left[ \begin{array}{c} \mathbf{w}_1^\top\\ \mathbf{w}_2^\top\\ \vdots \\ \mathbf{w}_n^\top \end{array} \right ] A=[a1,a2,⋯,am]=⎣ ⎡w1⊤w2⊤⋮wn⊤⎦ ⎤, x = [ x 1 , x 2 , ⋯ , x m ] ⊤ \mathbf{x}=[x_1,x_2,\cdots,x_m]^\top x=[x1,x2,⋯,xm]⊤, b = [ b 1 , b 2 , ⋯ , b n ] ⊤ \mathbf{b}=[b_1,b_2,\cdots,b_n]^\top b=[b1,b2,⋯,bn]⊤。可从不同的视角认识式(1)
-
矩阵的线性算子
矩阵 A \mathbf{A} A 可看作是一个线性算子,包括对向量 x \mathbf{x} x 的平移、旋转或者伸缩三种线性作用,这种线性运算在数学表达式上是加权求和的形式,即式(1)可表示为
A x = [ w 1 ⊤ w 2 ⊤ ⋮ w n ⊤ ] ⋅ x = [ w 1 ⊤ x w 2 ⊤ x ⋮ w n ⊤ x ] = [ b 1 b 2 ⋮ b n ] (2) \mathbf{Ax}=\left[ \begin{array}{c} \mathbf{w}_1^\top\\ \mathbf{w}_2^\top\\ \vdots \\ \mathbf{w}_n^\top \end{array} \right ]\cdot\mathbf{x}=\left[ \begin{array}{c} \mathbf{w}_1^\top\mathbf{x}\\ \mathbf{w}_2^\top\mathbf{x}\\ \vdots \\ \mathbf{w}_n^\top\mathbf{x} \end{array} \right ]=\left[ \begin{array}{c} b_1\\ b_2\\ \vdots \\ b_n \end{array} \right ]\tag{2} Ax=⎣ ⎡w1⊤w2⊤⋮wn⊤⎦ ⎤⋅x=⎣ ⎡w1⊤xw2⊤x⋮wn⊤x⎦ ⎤=⎣ ⎡b1b2⋮bn⎦ ⎤(2)
即
[ w 1 ⊤ x = b 1 w 2 ⊤ x = b 2 ⋮ w n ⊤ x = b n ] \left[ \begin{array}{c} \mathbf{w}_1^\top\mathbf{x}=b_1\\ \mathbf{w}_2^\top\mathbf{x}=b_2\\ \vdots \\ \mathbf{w}_n^\top\mathbf{x}=b_n \end{array} \right] ⎣ ⎡w1⊤x=b1w2⊤x=b2⋮wn⊤x=bn⎦ ⎤
- 矩阵列表达
A x = [ a 1 , a 2 , ⋯ , a m ] [ x 1 x 2 ⋮ x m ] = x 1 a 1 + x 2 a 2 + ⋯ + x m a m = b \mathbf{Ax}=[\mathbf{a}_1,\mathbf{a}_2,\cdots,\mathbf{a}_m]\left[ \begin{array}{c} x_1\\ x_2\\ \vdots \\ x_m \end{array} \right ]=x_1\mathbf{a}_1+x_2\mathbf{a}_2+\cdots+x_m\mathbf{a}_m=\mathbf{b} Ax=[a1,a2,⋯,am]⎣ ⎡x1x2⋮xm⎦ ⎤=x1a1+x2a2+⋯+xmam=b
2.2 内积与投影
定义: ⟨ x , y ⟩ = x ⊤ y = y ⊤ x = ∑ i = 1 n x ( i ) y ( i ) \lang\mathbf{x},\mathbf{y}\rang=\mathbf{x}^\top\mathbf{y}=\mathbf{y}^\top\mathbf{x}=\sum_{i=1}^nx(i)y(i) ⟨x,y⟩=x⊤y=y⊤x=∑i=1nx(i)y(i)
特殊情况: ⟨ x , x ⟩ = x ⊤ x = ∑ i = 1 n x ( i ) 2 = ∥ x ∥ 2 \lang\mathbf{x},\mathbf{x}\rang=\mathbf{x}^\top\mathbf{x}=\sum_{i=1}^nx(i)^2=\Vert\mathbf{x}\Vert^2 ⟨x,x⟩=x⊤x=∑i=1nx(i)2=∥x∥2
在距离中的应用: ⟨ x − y , x − y ⟩ = ( x − y ) ⊤ ( x − y ) = ∑ i = 1 n [ x ( i ) − y ( i ) ] 2 = ∥ x − y ∥ 2 \lang\mathbf{x-y},\mathbf{x-y}\rang=(\mathbf{x}-\mathbf{y})^\top(\mathbf{x}-\mathbf{y})=\sum_{i=1}^n[x(i)-y(i)]^2=\Vert\mathbf{x}-\mathbf{y}\Vert^2 ⟨x−y,x−y⟩=(x−y)⊤(x−y)=∑i=1n[x(i)−y(i)]2=∥x−y∥2
向量的方向性对于数据空间位置,特别是数据集特征之间的相关性的衡量有重要的意义,且这种衡量可以通过射线之间的夹角来完成。两个向量的夹角越小,即原点和两个数据点越近似在一条直线上,则说明两个特征向量的线性相关性非常强。对于这一现象,我们在中学阶段已经接触过,当两个向量 x \mathbf{x} x 和 y \mathbf{y} y 相互垂直时,其内积满足: ⟨ x , y ⟩ = 0 \lang\mathbf{x},\mathbf{y}\rang=0 ⟨x,y⟩=0。将向量的垂直关系进一步推广到任意夹角 θ \theta θ,则可获得向量的另一个内积公式:
⟨ x , y ⟩ = ∥ x ∥ ⋅ ∥ y ∥ ⋅ cos θ \lang\mathbf{x},\mathbf{y}\rang=\Vert \mathbf{x}\Vert\cdot\Vert \mathbf{y}\Vert\cdot\cos\theta ⟨x,y⟩=∥x∥⋅∥y∥⋅cosθ
如图所示,O,X,Y三点是否在一条直线附近(或称 O X ⃗ \vec{OX} OX 和 O Y ⃗ \vec{OY} OY 可以线性表出,即存在非零常数 α \alpha α 满足 O Y ⃗ = α ⋅ O Y ⃗ \vec{OY}=\alpha\cdot\vec{OY} OY=α⋅OY ),这种度量线性相关性的量即是内积,与两个向量的长度和夹角的余弦有直接关系。
公式两边同时除以向量 y \mathbf{y} y 的长度 ∥ y ∥ \Vert\mathbf{y}\Vert ∥y∥ 得,
⟨ x , y ^ ⟩ = ⟨ x , y ∥ y ∥ ⟩ = ∥ x ∥ ⋅ cos θ \lang\mathbf{x},\hat{\mathbf{y}}\rang=\lang\mathbf{x},\frac{\mathbf{y}}{\Vert\mathbf{y}\Vert}\rang=\Vert \mathbf{x}\Vert\cdot\cos\theta ⟨x,y^⟩=⟨x,∥y∥y⟩=∥x∥⋅cosθ
向量 x \mathbf{x} x 与单位向量 y ^ \hat{\mathbf{y}} y^ 的内积是直角三角形斜边长度与夹角余弦的乘积,数值上等于灰色线段的长度,我们称之为向量 x \mathbf{x} x 在向量 y \mathbf{y} y 上的投影。内积的这种投影的应用在后续度量点到直线的距离和向量位置关系的时候至关重要,是模型建立的基础性应用。
公式两边同时除以向量 x \mathbf{x} x 的长度 ∥ x ∥ \Vert\mathbf{x}\Vert ∥x∥ 和向量 y \mathbf{y} y 的长度 ∥ y ∥ \Vert\mathbf{y}\Vert ∥y∥ 得,
⟨ x ^ , y ^ ⟩ = ⟨ x ∥ x ∥ , y ∥ y ∥ ⟩ = cos θ \lang\hat{\mathbf{x}},\hat{\mathbf{y}}\rang=\lang\frac{\mathbf{x}}{\Vert\mathbf{x}\Vert},\frac{\mathbf{y}}{\Vert\mathbf{y}\Vert}\rang=\cos\theta ⟨x^,y^⟩=⟨∥x∥x,∥y∥y⟩=cosθ
公式(2-7)在不考虑向量的长度因素情况下只考虑夹角,则两个单位向量的内积退化成夹角的余弦值,如图2-7 ©所示。
2.3 基于矩阵的距离运算
在做分类时,常常需要估算两个样本间的相似性度量(SimilarityMeasurement),这时经常就用到两个样本间的“距离”(Distance),采用什么样的方法计算距离是很讲究,甚至关系到分类的正确与否。经常使用的度量方法是欧式距离,欧氏距离是最易于理解的一种距离计算方法,源自欧氏空间中两点间的距离公式。
给定 m × n m\times n m×n 阶矩阵 X \mathbf{X} X,满足 X = [ x 1 , x 2 , ⋯ , x n ] \mathbf{X}=[\mathbf{x}_1,\mathbf{x}_2,\cdots,\mathbf{x}_n] X=[x1,x2,⋯,xn],其中, x i ∈ R m \mathbf{x}_i\in\mathbb{R}^m xi∈Rm,则各向量(样本点)的距离定义为
D i j = ∥ x i − x j ∥ = ∑ t = 1 m ( x i , t − x j , t ) 2 D_{ij}=\Vert\mathbf{x}_i-\mathbf{x}_j\Vert=\sqrt{\sum_{t=1}^m(x_{i,t}-x_{j,t})^2} Dij=∥xi−xj∥=t=1∑m(xi,t−xj,t)2
由于在机器学习中所用到的距离都是距离的平方的形式,因此,这里提供 4 中编程方法来实现距离的计算:
方法一:标准方法是通过使用两层 for 循环来实现
D i j 2 = ∥ x i − x j ∥ 2 = ∑ t = 1 m ( x i , t − x j , t ) 2 D_{ij}^2=\Vert\mathbf{x}_i-\mathbf{x}_j\Vert^2=\sum_{t=1}^m(x_{i,t}-x_{j,t})^2 Dij2=∥xi−xj∥2=t=1∑m(xi,t−xj,t)2
方法二:利用矩阵内积计算 D i j D_{ij} Dij,使用 numpy 的 norm 方法,这个方法从数学上讲,其计算公式是:
D i j 2 = ∥ x i − x j ∥ 2 = ( x i − x j ) ⊤ ( x i − x j ) D_{ij}^2=\Vert\mathbf{x}_i-\mathbf{x}_j\Vert^2=(\mathbf{x}_i-\mathbf{x}_j)^\top(\mathbf{x}_i-\mathbf{x}_j) Dij2=∥xi−xj∥2=(xi−xj)⊤(xi−xj)
方法三:避免循环内点积运算,减少 dot 调用次数
尽管 numpy 底层可能对点积运算做了优化,但还可以进一步优化。将向量差的内积进一步分解:
D i j 2 = ∥ x i − x j ∥ 2 = ( x i − x j ) ⊤ ( x i − x j ) = x i ⊤ x i − 2 x i ⊤ x j + x j ⊤ x j \begin{align} D_{ij}^2&=\Vert\mathbf{x}_i-\mathbf{x}_j\Vert^2\\ &=(\mathbf{x}_i-\mathbf{x}_j)^\top(\mathbf{x}_i-\mathbf{x}_j)\\ &=\mathbf{x}_i^\top\mathbf{x}_i-2\mathbf{x}_i^\top\mathbf{x}_j+\mathbf{x}_j^\top\mathbf{x}_j \end{align} Dij2=∥xi−xj∥2=(xi−xj)⊤(xi−xj)=xi⊤xi−2xi⊤xj+xj⊤xj
其中, x i ⊤ x i , x i ⊤ x j , x j ⊤ x j \mathbf{x}_i^\top\mathbf{x}_i,\mathbf{x}_i^\top\mathbf{x}_j,\mathbf{x}_j^\top\mathbf{x}_j xi⊤xi,xi⊤xj,xj⊤xj 均属于 Gram 矩阵 G = X ⊤ X \mathbf{G}=\mathbf{X}^\top\mathbf{X} G=X⊤X 中的元素,可通过 for 循环进行赋值
D i j 2 = G i i − 2 G i j + G j j D_{ij}^2=\mathbf{G}_{ii}-2\mathbf{G}_{ij}+\mathbf{G}_{jj} Dij2=Gii−2Gij+Gjj
方法四:利用复制对角向量避免for循环
由于 D i j 2 = x i ⊤ x i − 2 x i ⊤ x j + x j ⊤ x j D_{ij}^2=\mathbf{x}_i^\top\mathbf{x}_i-2\mathbf{x}_i^\top\mathbf{x}_j+\mathbf{x}_j^\top\mathbf{x}_j Dij2=xi⊤xi−2xi⊤xj+xj⊤xj 可通过构造矩阵 H = [ diag ( G ) , ⋯ , diag ( G ) ] \mathbf{H}=[\text{diag}(\mathbf{G}),\cdots,\text{diag}(\mathbf{G})] H=[diag(G),⋯,diag(G)] 计算 距离矩阵的平方
D 2 = H + H ⊤ − 2 G \mathbf{D}^2=\mathbf{H}+\mathbf{H}^\top-2\mathbf{G} D2=H+H⊤−2G
import numpy as np
import numpy.linalg as la
import time
X = np.array([range(0, 500), range(500, 1000)])
m, n = X.shape
#方法1:标准方法使用两层循环计算Dij
#时间复杂度O(n*n)
t = time.time()
D = np.zeros([n, n])
for i in range(n):
for j in range(i + 1, n):
D[i, j] = la.norm(X[:, i] - X[:, j]) ** 2
D[j, i] = D[i, j]
print(time.time() - t)
#方法2:利用矩阵内积dot计算Dij
# 时间复杂度O(n*n)*O(m)
t = time.time()
D = np.zeros([n, n])
for i in range(n):
for j in range(i + 1, n):
d = X[:, i] - X[:, j]
D[i, j] = np.dot(d, d)
D[j, i] = D[i, j]
print(time.time() - t)
#方法3:避免循环内点积运算,减少dot调用次数
# 时间复杂度O(n*n)
t = time.time()
G = np.dot(X.T, X)
D = np.zeros([n, n])
for i in range(n):
for j in range(i + 1, n):
D[i, j] = G[i, i] - G[i, j] * 2 + G[j,j]
D[j, i] = D[i, j]
print(time.time() - t)
#方法4:利用重复操作替代外部循环
t = time.time()
G = np.dot(X.T, X)
#把G对角线元素拎出来,列不变,行复制n遍。
H = np.tile(np.diag(G), (n, 1))
D = H + H.T - G * 2
print(time.time() - t)
结果
0.6473026275634766
0.2762320041656494
0.12765932083129883
0.0029916763305664062
2.4 优化:牛顿迭代和梯度下降算法
导数定义(定义要精确)
f ′ ( x ) = lim x → x 0 f ( x ) − f ( x 0 ) x − x 0 f'(x)=\lim_{x\rightarrow x_0}\frac{f(x)-f(x_0)}{x-x_0} f′(x)=x→x0limx−x0f(x)−f(x0)
即
f ( x ) = f ( x 0 ) + f ′ ( x ) ( x − x 0 ) + o ( ( x − x 0 ) 2 ) f(x)=f(x_0)+f'(x)(x-x_0)+o\big((x-x_0)^2\big) f(x)=f(x0)+f′(x)(x−x0)+o((x−x0)2)
泰勒展开式
f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) + f ′ ′ ( x 0 ) ( x − x 0 ) 2 + o ( ( x − x 0 ) 2 ) f(x)=f(x_0)+f'(x_0)(x-x_0)+f''(x_0)(x-x_0)^2+o\big((x-x_0)^2\big) f(x)=f(x0)+f′(x0)(x−x0)+f′′(x0)(x−x0)2+o((x−x0)2)
牛顿迭代法
从泰勒展开式到牛顿算法
泰勒展开式
f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) + f ′ ′ ( x 0 ) ( x − x 0 ) 2 + o ( ( x − x 0 ) 2 ) f(x)=f(x_0)+f'(x_0)(x-x_0)+f''(x_0)(x-x_0)^2+o\big((x-x_0)^2\big) f(x)=f(x0)+f′(x0)(x−x0)+f′′(x0)(x−x0)2+o((x−x0)2)
当需要求 y = f ( x ) y=f(x) y=f(x)的根时,即 f ( x ) = 0 f(x)=0 f(x)=0
只取泰勒展开式的前两项作为近似,则
f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) ≈ 0 f(x_0)+f'(x_0)(x-x_0)\approx 0 f(x0)+f′(x0)(x−x0)≈0
得
x ≈ x 0 − f ( x 0 ) f ′ ( x 0 ) x\approx x_0-\frac{f(x_0)}{f'(x_0)} x≈x0−f′(x0)f(x0)
迭代格式为:
x n + 1 : = x n − f ( x n ) f ′ ( x n ) x_{n+1}:=x_n-\frac{f(x_n)}{f'(x_n)} xn+1:=xn−f′(xn)f(xn)
从泰勒展开式到牛顿算法
泰勒展开式
f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) + f ′ ′ ( x 0 ) ( x − x 0 ) 2 + o ( ( x − x 0 ) 2 ) f(x)=f(x_0)+f'(x_0)(x-x_0)+f''(x_0)(x-x_0)^2+o\big((x-x_0)^2\big) f(x)=f(x0)+f′(x0)(x−x0)+f′′(x0)(x−x0)2+o((x−x0)2)
当需要求 y = f ( x ) y=f(x) y=f(x)的极值时,即 f ′ ( x ) = 0 f'(x)=0 f′(x)=0,则可把 f ( x ) f(x) f(x)看作 ( x − x 0 ) (x-x_0) (x−x0)的二次函数,即求
f ′ ′ ( x 0 ) 2 ( x − x 0 ) 2 + f ′ ( x 0 ) ( x − x 0 ) + f ( x 0 ) \frac{f''(x_0)}{2}(x-x_0)^2+f'(x_0)(x-x_0)+f(x_0) 2f′′(x0)(x−x0)2+f′(x0)(x−x0)+f(x0)
的极值
则
x − x 0 = − f ′ ( x 0 ) f ′ ′ ( x 0 ) x-x_0=-\frac{f'(x_0)}{f''(x_0)} x−x0=−f′′(x0)f′(x0)
迭代格式为:
x n + 1 : = x n − f ′ ( x n ) f ′ ′ ( x n ) x_{n+1}:=x_n-\frac{f'(x_n)}{f''(x_n)} xn+1:=xn−f′′(xn)f′(xn)
梯度下降法
求 y = f ( x ) y=f(x) y=f(x)的极值
x n + 1 : = x n − α f ′ ( x n ) x_{n+1}:=x_n-\alpha f'(x_n) xn+1:=xn−αf′(xn)
其中, α \alpha α是步长,负梯度方向 − f ′ ( x n ) -f'(x_n) −f′(xn)为下降方向
# 梯度下降法的python实现,梯度下降算法是神经网络、深度学习的基础
# 本脚本通过梯度下降算法求函数y(x)的最小值
# 作者:MR_LeeCZ
import numpy as np
import matplotlib.pyplot as plt
def y(x): # 定义函数,求函数的极小值
y = (x-10)*(x-10) + 10*np.sin(x) - 3*x +60
return y
def dy(x): # 函数y(x)的导数
dy = 2*(x-10) + 10*np.cos(x) -3
return dy
def gradient_descent(x0, a, d0): # 梯度下降法,x0为初始值,a为学习率,d0为算法的收敛条件
value_appr = x0
for i in range(1000): # 迭代1000次,无论是否收敛都将终止程序
d = y(x0) - y(x0-a*dy(x0)) # 更新前后函数值的增减幅度,确定是否停机
if d < d0: # 判断是否满足收敛条件
break
else:
x0 = x0 - a*dy(x0) # x0通过梯度更新,下降最快
value_appr = np.append(value_appr,x0)
return x0, value_appr
x0, xs = gradient_descent(0, 0.05, 0.0001)
x = np.linspace(0, 20, 40)
y_fun = y(x)
y_op = y(xs)
plt.plot(x,y_fun)
plt.scatter(xs,y_op,c='r')
plt.show()
print('最优解为: {x_hat},相应的最优值为:{y_hat}'.format(x_hat=xs[-1],y_hat=y_op[-1]))
最优解为: 11.076141044662462,相应的最优值为:17.96209387410127

)
x = np.linspace(0, 20, 40)
y_fun = y(x)
y_op = y(xs)
plt.plot(x,y_fun)
plt.scatter(xs,y_op,c=‘r’)
plt.show()
print(‘最优解为: {x_hat},相应的最优值为:{y_hat}’.format(x_hat=xs[-1],y_hat=y_op[-1]))
最优解为: 11.076141044662462,相应的最优值为:17.96209387410127