[机器学习、Spark]Spark MLlib实现数据基本统计
博主:发量不足
本期更新内容:Spark MLlib基本统计
下篇文章预告:Spark MLlib的分类
简介:耐心,自信来源于你强大的思想和知识基础!!
目录
Spark MLlib基本统计
一.摘要统计
二.相关统计
三.分层抽样
Spark MLlib基本统计
MLlib提供了很多统计方法,包含摘要统计、相关统计、分层抽样、假设检验、随机数生成等统计方法,利用这些统计方法可帮助用户更好地对结果数据进行处理和分析
MLlib三个核心功能:
1.实用程序:统计方法,如描述性统计、卡方检验、线性代数、模型评估方法等
2.数据准备:特征提取、变换、分类特征的散列和一些自然语言处理方法
3.机器学习方法:实现了一些流行和高级的回归,分类和聚类算法
![[机器学习、Spark]Spark MLlib实现数据基本统计_第1张图片](http://img.e-com-net.com/image/info8/57844c6bb7184c519d13c3e9a5b18954.jpg)
一.摘要统计
![[机器学习、Spark]Spark MLlib实现数据基本统计_第2张图片](http://img.e-com-net.com/image/info8/fbd5a2a0c3ee4ba89285afa057c34370.jpg)
导包
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.stat.{MultivariateStatisticalSummary,Statistics}
![]()

创建密集矩阵
val observations=sc.parallelize(Seq(Vectors.dense(1.0,10.0,100.0),Vectors.dense(2.0,20.0,200.0),Vectors.dense(3.0,30.0,300.0)))![[机器学习、Spark]Spark MLlib实现数据基本统计_第3张图片](http://img.e-com-net.com/image/info8/75489a2c18da42678fcaba935949cbc9.jpg)
计算列摘要统计信息
val sum:MultivariateStatisticalSummary=Statistics.colStats(observations)

打印平均值

打印方差
![]()
打印每列非零元素的个数
![]()
二.相关统计
相关系数是反应两个变量之间相关关系密切程度的统计指标,这也是统计学中常用的统计方式,MLlib提供了计算多个序列之间相关统计的方法,目前MLlib默认采用皮尔森相关系数计算方法。皮尔森相关系数也称皮尔森积矩相关系数,它是一种线性相关系数。
导包
![[机器学习、Spark]Spark MLlib实现数据基本统计_第4张图片](http://img.e-com-net.com/image/info8/318c129f48f64fa1a5d887db5da2e715.jpg)
创建序列
val seriesX:RDD[Double]=sc.parallelize(Array(1,2,3,3,5))
val seriesY:RDD[Double]=sc.parallelize(Array(11,22,33,33,555))

计算seX和seY的相关系数
val correlation:Double = Statistics.corr(seriesX,seriesY,"pearson")

打印数据
println(s"Correlation is : $correlation")
![]()
利用皮尔森方法计算密集矩阵相关系数
val data:RDD[Vector]=sc.parallelize(Seq(Vectors.dense(1.0,10.0,100.0),Vectors.dense(2.0,20.0,200.0),Vectors.dense(5.0,33.0,366.0)))![]()
val corMx:Matrix = Statistics.corr(data,"pearson")

打印数据
println(corMx.toString)

三.分层抽样
分层抽样法也叫类型抽样法,它是先将总体样本按照某种特征分为若干次级(层),如何再从每一层内进行独立取样,组成一个样本的统计学计算方法。
创建键值对RDD
val data=sc.parallelize(Seq((1,'a'),(1,'b'),(2,'c'),(2,'d'),(2,'e'),(3,'f')))
![]()
设定抽样格式
val fra = Map(1->0.1,2->0.6,3->0.3)
![]()
从每层获取抽样样本
val app=data.sampleByKey(withReplacement=false,fractions=fra)
![]()
从每层获取精确样本

打印抽样样本
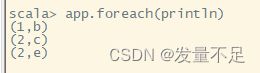
打印精确样本
