Spark机器学习:MLlib
本章主要介绍Spark的机器学习套件MLlib。MLlib从功能上说与Scikit-Learn等机器学习库非常类似,但计算引擎采用的是Spark,即所有计算过程均实现了分布式,这也是它和其他机器学习库最大的不同。但读者在学习MLlib的时候,大可不必关注其分布式细节,这是MLlib组件与其他组件很不一样的地方,这里不用考虑GraphX、Structured Streaming中的关键抽象、分布式计算框架,而只需关注那些机器学习任务本身的一些东西,如参数、模型、工作流、测试、算法调优等。
本章包含以下内容:
- 机器学习;
- Spark MLlib与Spark ML;
- 数据预处理;
- 分类算法应用;
- 聚类算法应用;
- 推荐系统应用;
- 训练之后;
- 流式机器学习。
6.1 机器学习
在本节中,我们将试着从计算机科学、统计学和数据分析的定义角度来机器学习。机器学习是计算机科学的一个分支,为计算机提供了无须明确编程的学习能力(Arthur Samuel,1959)。这个研究领域是从人工智能中的模式识别和计算学习理论的研究中演化而来的。
更具体地说,机器学习探讨了启发式学习和基于数据进行预测的算法的研究和构建。这种算法通过从样本输入构建模型,通过制订数据驱动的预测来代替严格的静态程序代码。现在来看看卡耐基梅隆的Tom M. Mitchell教授对机器学习的定义,他从计算机科学的角度解释了机器学习的真正意义:
对于某类任务T和性能度量P,如果一个计算机程序在T上以P衡量的性能随着经验E而自我完善,那么就称这个计算机程序从经验E中学习。
基于该定义,我们能够得出计算机程序或者机器能够:
- 从历史数据中学习;
- 通过经验而获得提升;
- 交互式地增强可用于预测问题结果的模型。
典型的机器学习任务是概念学习、预测建模、聚类以及寻找有用的模式。最终目标是提高学习的自动化程度,从而不再需要人为地干预,或尽可能地降低人为干预的水平。
6.1.1 典型的机器学习工作流
一个典型的机器学习应用程序涉及从输入、处理到输出的几个步骤,形成一个科学的工作流程,如图6-1所示。典型的机器学习应用程序涉及以下步骤。
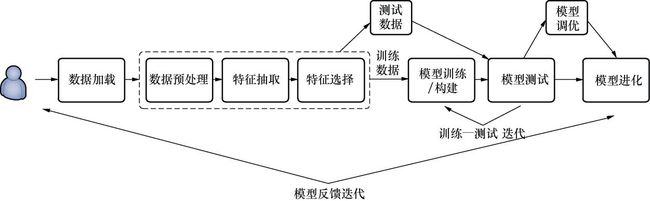
图6-1 机器学习流程
(1)加载样本数据。
(2)将数据解析为算法所需的格式。
(3)预处理数据并处理缺失值。
(4)将数据分成两组:一组用于构建模型(训练数据集),另一组用于测试模型(验证数据集)。
(5)运行算法来构建或训练你的ML模型。
(6)用训练数据进行预测并观察结果。
(7)使用测试数据测试和评估模型,或者使用第三个数据集(称为验证数据集)运用交叉验证技术验证模型。
(8)调整模型以获得更好的性能和准确性。
(9)调整模型扩展性,以便将来能够处理大量的数据集。
(10)部署模型。
在步骤4中,实验数据集是随机分割的,通常被分为一个训练数据集和一个称为采样的测试数据集。训练数据集用于训练模型,而测试数据集用于最终评估最佳模型的性能。更好的做法是尽可能多地使用训练数据集以提高泛化性能。另一方面,建议只使用一次测试数据集,以在计算预测误差和相关度量时避免过度拟合问题。
6.1.2 机器学习任务的学习类型
根据学习系统学习反馈的本质,机器学习任务通常被分为以下3类,即监督学习、无监督学习以及增强学习,如图6-2所示。

图6-2 机器学习的任务类型
1.监督学习
监督学习的目标是学习将输入映射到与现实世界相一致的输出的一般规则。例如,垃圾邮件过滤数据集通常包含垃圾邮件以及非垃圾邮件。因此,能够知道训练集中的数据是垃圾邮件还是正常邮件。我们有机会利用这些信息来训练模型,以便对新来的邮件进行分类。如图 6-3所示,该图为监督学习的示意图。算法找到所需的模式后,可以使用这些模式对未标记的测试数据进行预测。这是最常见的机器学习任务类型,MLlib 也不例外,其中大部分算法都是监督学习,如朴素贝叶斯、逻辑回归、随机森林等,监督学习的数据处理流程大致如图 6-3所示。

图6-3 监督学习流程
从图中可以看出,经过数据预处理后,数据被分为两部分,一部分为测试集,另一部分为训练集,通过学习算法,可以由训练集得到我们所需的模型,模型会用测试集进行验证,工程师会根据验证的情况对模型进行调优,实现一个数据驱动的优化过程。
2.无监督学习
在无监督学习中,数据没有相关的标签,也就是说无法区分训练集与测试集。因此,我们需要用算法上加上标签,如图 6-4 所示。因此,标签必须从数据集中推断出来,这意味着无监督学习算法的目标是通过描述结构,以某种结构化的方式对数据进行预处理。

图6-4 无监督学习流程
为了克服无监督学习中的这个障碍,通常使用聚类技术,基于某些相似性度量来对未标记样本进行分组。因此,无监督学习任务会涉及挖掘隐藏的模式、特征学习等。聚类是智能地对数据集中的元素进行分类的过程。总体思路是,同一个类中的两个元素比属于不同类中的元素彼此更为“接近”。“接近”的定义可以有很多种。
无监督的例子包括聚类、频繁模式挖掘以及降维等。MLlib也提供了 k均值聚类、潜在狄利克雷分布(Latent Dirichlet Allocation)、主成分分析(Principal Component Analysis)、奇异值分解(Singular value decomposition)等聚类与降维算法。
3.增强学习
作为一个人,我们也曾从过去的经验中学习。多年来积极的赞美和负面的批评都有助于塑造出今天的我们。通过与朋友、家人,甚至陌生人互动,我们可以了解什么让人开心,什么让人难过。当你执行某个操作时,你有时会立即得到奖励。例如,在附近找到购物中心可能会产生即时的满足感,但也有些时候,奖励不会马上兑现,比如长途跋涉去寻找某个地方。这些都与增强学习密切相关。
因此,增强学习是一种模型本身从一系列行为中学习的技术。数据集或样本的复杂性对于需要算法成功学习目标函数的增强学习非常重要。此外,为了达到最终目标,每条数据都需要做到一点,即在保证与外部环境相互作用的同时,应确保奖励函数的最大化,如图 6-5所示。

图6-5 增强学习流程
从图 6-5 中也可以看出增强学习与监督学习最大的不同是其训练集包含着一个尝试的过程,会试图从环境中获得评价或者反馈。如围棋这种博弈类游戏,会有两个代理互相用已有的模型制订策略,并根据最后的结果修正自己的模型的过程。谷歌公司的AlphaGo就是深度学习与增强学习相结合的一个很好的例子。总而言之,增强学习在行动——评价的环境中获得知识,改进行动方案以适应环境。增强学习在物联网环境、路线问题、股市交易、机器人等场景得到了广泛应用。
6.2 Spark MLlib与Spark ML
在Spark MLlib模块中,可以看到它的源码主要分为两个包:spark.ml与spark.mllib,我们将前者称为Spark ML API,后者称为Spark MLlib API,有些算法在两个包中都可以找到,如协同过滤,有些算法只有MLlib有,如SVD。除此以外,它们还有一些区别。
一言以蔽之,MLlib与ML之间最大的区别在于,ML基于DataFrame,而MLlib API基于RDD,这与GraphX和GraphFrame之间的关系类似。在Spark 2.0后,基于RDD的API,也就是MLlib API,就已经进入了维护状态,而Spark MLlib首要的API为ML API。虽然如此,Spark MLlib仍然会以修复Bug的方式支持MLlib API,但不会增加新特性了。在Spark 2.x的版本中,ML API会逐渐变得与MLlib API一样,在完成这个过程后,MLlib API会被弃用。在Spark 3.0中,MLlib API会被彻底舍弃。
Spark MLlib转而提供基于DataFrame API的原因有以下3点。
- 使用DataFrame可以享受到Spark 2.x带来的性能优化,以及跨语言的统一API。
- DataFrame易于使用ML Pipelines特性,这在特征转换方面尤其有用,其中Spark ML Pipelines会在下一节介绍。
- ML提供了一套跨语言以及跨机器学习算法的API。
本书提到的Spark ML,并不是一个正式的名字,而是指Spark MLlib中基于DataFrame的那一套API,它主要是由org.apache.spark.ml的包名,以及术语Spark ML Pipelines得名而来。此外,由于MLlib API是注定会被替代的,因此本书不会对其着墨太多,主要以Spark ML API为主。
Spark ML Pipelines
Spark MLlib想成为大数据机器学习的最佳实践,简化机器学习过程,并使其可扩展。Spark ML API引入了Pipelines API(管道),这类似于Python机器学习库Scikit-Learn中的Pipeline,它采用了一系列API定义并标准化了6.1.1节中工作流,它包含了数据收集、预处理、特征抽取、特征选择、模型拟合、模型验证、模型评估等一系列阶段。例如,对文档进行分类也许会包含分词、特征抽取、训练分类模型以及调优等过程。大多数机器学习库不是为分布式计算而设计的,也不提供Pipeline的创建与调优,而这就是Spark ML PipeLines要做的。
Spark ML Pipelines就是对分布式机器学习过程进行模块化的抽象,这样使得多个算法合并成一个Pipeline或者工作流变得更加容易,下面是Pipelines API的关键概念。
- DataFrame:DataFrame与Spark SQL中用到的DataFrame一样,是Spark的基础数据结构,贯穿了整个Pipeline。它可以存储文本、特征向量、训练集以及测试集。除了常见的类型,DataFrame还支持Spark MLlib特有的Vector类型。
- Transformer:Transformer对应了数据转换的过程,它接收一个DataFrame,在它的作用下,会生成一个新的DataFrame。在机器学习中,在涉及特征转换的过程中经常会用到,另外还会用于训练出的模型将特征数据集转换为带有预测结果的数据集的过程,Transformer都必须实现transform()方法。
- Estimator:从上面 Transformer 的定义可以得知,训练完成好的模型也是一个Transformer,那么Estimator包含了一个可以让数据集拟合出一个Transformer的算法,Estimator必须实现fit()方法。
- Pipeline:一个Pipeline将多个Transformer和Estimator组装成一个特定的机器学习工作流。
- Parameter:所有的Estimator和Transformer共用一套通用的API来指定参数。
文档分类是一个在自然语言处理中非常常见的应用,如垃圾邮件监测、情感分析等,下面通过一个文档分类的例子来让读者对Spark的Pipeline有一个感性的理解。简单来说,任何文档分类应用都需要以下4步。
(1)将文档分词。
(2)将分词的结果转换为词向量。
(3)学习模型。
(4)预测(是否为垃圾邮件或者正负情感)。
比如在垃圾邮件监测中,我们需要通过邮件正文甄别出哪些是垃圾邮件,邮件正文一般会是一段文字,如:代开各种发票,手续费极低,请联系我。这样一段文字是无法直接应用于Estimator的,需要将其转换为特征向量,一般做法是用一个词典构建一个向量空间,其中每一个维度都是一个词,出现过的为1,未出现的为0,再根据文档中出现的词语的频数,用TF-IDF算法为文档中出现的词维度赋予权重。这样的话,每个文档就能被转为一个等长的特征向量,如下:
(0, 0, …, 0.27, 0, 0, …, 0.1, 0)
接着就可以用来拟合模型并输出测试结果。
用一个流程图来表示整个过程,如图6-6所示,其中Tokenizer和HashingTF为Transformer,作用分别是分词和计算权重,训练出的模型也是Transformer,用来生成测试结果;Estimator采用的是逻辑回归算法(LR);DS0-DS3都是不同阶段输出的数据。这就是一个完整意义上的Pipeline。

图6-6 Spark ML Pipeline模型
下面用代码实现整个Pipeline,如下:
package com.spark.examples.mllib
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.feature.{HashingTF, Tokenizer}
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
object PipelineExample{
def main(args: Array[String ]): Unit = {
val spark = SparkSession
.builder
.master("local[2]")
.appName("PipelineExample")
.getOrCreate()
import spark.implicits._
// 准备训练数据,其中最后一列就是该文档的标签,即是否为垃圾邮件
val training = spark.createDataFrame(Seq(
(0L, "a b c d e spark", 1.0),
(1L, "b d", 0.0),
(2L, "spark f g h", 1.0),
(3L, "hadoop mapreduce", 0.0)
)).toDF("id", "text", "label")
// 配置整个Pipeline,由3个组件组成:tokenizer(Transformer)、hashingTF(Transformer)
// 和 lr(Estimator)
val tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol("words")
val hashingTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("features")
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.001)
val pipeline = new Pipeline()
.setStages(Array(tokenizer, hashingTF, lr))
// 拟合模型,得到结果
val model = pipeline.fit(training)
// 将模型持久化
model.write.overwrite().save("/tmp/spark-logistic-regression-model")
// 将Pipeline持久化
pipeline.write.overwrite().save("/tmp/unfit-lr-model")
// 加载模型
val sameModel = PipelineModel.load("/tmp/spark-logistic-regression-model")
// 准备无标签的测试集
val test = spark.createDataFrame(Seq(
(4L, "spark i j k"),
(5L, "l m n"),
(6L, "spark hadoop spark"),
(7L, "apache hadoop")
)).toDF("id", "text")
// 用模型预测测试集,得到预测结果(标签)
model.transform(test)
.select("id", "text", "probability", "prediction")
.collect()
.foreach { case Row(id: Long, text: String, prob: Vector, prediction: Double) =>
println(s"($id, $text) --> prob=$prob, prediction=$prediction")
}
}
}这样就用Spark完整实现了一个机器学习的流程。由上面的代码可以看出,这样的结构非常有利于复用Transformer与Estimator组件。
Spark MLlib(ML API)的算法包主要分为以下几个部分:
- 特征抽取、转换与选择;
- 分类和回归;
- 聚类;
- 协同过滤;
- 频繁项集挖掘。
其中每一类都有若干种算法的实现,用户可以利用Pipeline按需进行切换,下面将就这几个类别,分别实现一些真实数据的案例,让读者可以直接上手应用。
此外,在上面代码中,我们用Pipeline API将模型序列化成文件,这样的好处在于可以将模型看成一个黑盒,非常方便模型上线,而不用在上线应用时再去对模型进行硬编码,这将在6.8.3节中有所体现,类似于Python的Pickle库的用法。
6.3 数据预处理
在机器学习实践中,数据科学家拿到的数据通常是不尽如人意的,例如存在大量的缺失值、特征的值是不同的量纲、有一些无关的特征、特征的值需要再次处理等情况,这样的数据无法直接训练,因此我们需要对这些数据进行预处理。预处理在机器学习中是非常重要的步骤,如果没有按照正确的方法对数据进行预处理,往往会得到错误的训练结果。下面介绍几种常见的预处理方法。
6.3.1 数据标准化
通常,我们直接获得的数据包含了量纲,也就是单位,例如身高180 cm,体重75 kg,对于某些算法来说,如果特征的单位不统一,就无法直接进行计算,因此在很多情况下的预处理过程中,数据标准化是必不可少的。数据标准化的方法一般有z分数法、最大最小法等。
1.z分数法
这种方法根据原始数据(特征)的均值(mean)和标准差(standard deviation)进行数据的标准化,将原始数据转换为z分数,转换函数如下:
![]()
其中μ为所有样本数据的均值,σ为所有样本数据的标准差。Spark MLlib内置了z分数标准化转换功能的Transformer实现类StandardScaler,代码如下:
import org.apache.spark.ml.feature.StandardScaler
val dataFrame = spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt")
val scaler = new StandardScaler()
.setInputCol("features")
.setOutputCol("scaledFeatures")
.setWithStd(true)
.setWithMean(false)
// 计算汇总统计量,生成ScalerModel
val scalerModel = scaler.fit(dataFrame)
// 对特征进行标准化
val scaledData = scalerModel.transform(dataFrame)
scaledData.show()2.最大最小法
这种方法也称为离差标准化,是对原始数据的线性变换,使结果值映射到 [0 - 1] 之间。转换函数如下:
![]()
其中max为样本数据的最大值,min为样本数据的最小值。这种方法的缺陷是当有新数据加入时,可能导致max和min的变化,需要重新定义,但这种情况在训练过程中很少见。这种方法对于方差特别小的特征可以增强其稳定性。Spark MLlib内置了最大最小转换功能的Transformer实现类MinMaxScaler。
import org.apache.spark.ml.feature.MinMaxScaler
import org.apache.spark.ml.linalg.Vectors
val dataFrame = spark.createDataFrame(Seq(
(0, Vectors.dense(1.0, 0.1, -1.0)),
(1, Vectors.dense(2.0, 1.1, 1.0)),
(2, Vectors.dense(3.0, 10.1, 3.0))
)).toDF("id", "features")
val scaler = new MinMaxScaler()
.setInputCol("features")
.setOutputCol("scaledFeatures")
// 计算汇总统计量,生成MinMaxScalerModel
val scalerModel = scaler.fit(dataFrame)
// rescale each feature to range [min, max].
val scaledData = scalerModel.transform(dataFrame)
println(s"Features scaled to range: [${scaler.getMin}, ${scaler.getMax}]")
scaledData.select("features", "scaledFeatures").show()3.p范数法
p范数法指的是通过计算样本的p范数,用该样本除以该样本的p范数,得到的值就是标准化的结果。p范数的计算公式如下:
![]()
当p = 1时,p范数也叫L1范数,此时L1等于样本的所有特征值的绝对值相加。当p = 2时也叫L2范数,此时L2等于样本x距离向量空间的原点的欧氏距离:
![]()
归一化的结果为:
![]()
Spark MLlib内置了p范数标准化转换功能的Transformer实现类Normalizer,其代码如下:
import org.apache.spark.ml.feature.Normalizer
import org.apache.spark.ml.linalg.Vectors
val dataFrame = spark.createDataFrame(Seq(
(0, Vectors.dense(1.0, 0.5, -1.0)),
(1, Vectors.dense(2.0, 1.0, 1.0)),
(2, Vectors.dense(4.0, 10.0, 2.0))
)).toDF("id", "features")
// 设置p = 1
val normalizer = new Normalizer()
.setInputCol("features")
.setOutputCol("normFeatures")
.setP(1.0)
val l1NormData = normalizer.transform(dataFrame)
l1NormData.show()
// 设置p = -∞
val lInfNormData = normalizer.transform(dataFrame, normalizer.p -> Double.PositiveInfinity)
println("Normalized using L^inf norm")
lInfNormData.show()6.3.2 缺失值处理
对于缺失值的处理,需要根据数据的具体情况,比如如果特征值是连续型,通常用中位数来填充;如果特征值是标签型,通常用众数来补齐;某些情况下,还可以用一个显著区别于已有样本中该特征的值来补齐。Spark并没有提供预置的缺失值处理的Transformer,这通常需要自己实现,在后面的例子中,我们会实现一个对缺失值处理的自定义Transformer。
6.3.3 特征抽取
特征抽取(feature extraction)是从原有特征中按照某种映射关系生成原有特征的一个特征子集,而6.3.4节中将提到的特征选择(feature selection),是根据某种规则对原有特征筛选出一个特征子集。特征选择和特征抽取有相同之处,它们都试图减少数据集中的特征数目,但具体方法不同,特征抽取的方法主要是通过特征间的关系,如组合不同特征得到新的特征,这样就改变了原来的特征空间;而特征选择的方法是从原始特征数据集中选择出子集,是一种包含关系,没有更改原始的特征空间,如图6-7所示。
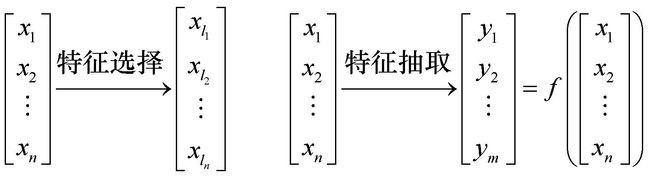
图6-7 特征抽取与特征选择
Spark 也提供了很多种特征抽取的方法,常见的如主成分分析、广泛应用于文本的Word2Vector等。
1.主成分分析
如果在样本中特征与特征互相关联,无关的特征太多,就会影响模式的发现。我们需要用降维技术从样本中生成用来代表原有特征的一个特征子集。
在了解主成分分析(PCA)之前,需要先了解协方差的概念,X特征与Y特征之间的协方差为:
![]()
如果协方差为正,说明X和Y是正相关关系。协方差为负说明是负相关关系。协方差为0时,X和Y相互独立。如果样本集D有n维特征,那么两两之间的协方差可以组成一个n×n的矩阵,如下是n = 3的情况:
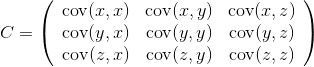
然后需要对这个矩阵进行特征值分解,得到特征值和特征向量,再取出最大的m(m < n)个特征值对应的特征向量(w1, w2,…, wm),组成特征向量矩阵W,对每个样本xi执行如下操作,得到降维后的样本zi,如下:
![]()
则降维后的数据集为:
![]()
下面以数据挖掘领域著名的鸢尾花数据集(IRIS)来用PCA实现降维操作,鸢尾花数据集是常用的分类数据集,包含150个样本,分3种类别,各50条,每个样本4个维度,分别是花萼长度、花萼宽度、花瓣长度和花瓣宽度,代码如下:
package com.spark.examples.mllib
import org.apache.spark.ml.feature.{PCA, VectorAssembler}
import org.apache.spark.sql.{Dataset, Row, SparkSession}
import org.apache.spark.ml.feature.StandardScaler
import org.apache.spark.sql.types.{DoubleType, StringType, StructField, StructType}
import org.apache.spark.ml.Pipeline
object IRISPCA {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local[2]")
.appName("IRISPCA")
.getOrCreate()
// 数据结构为花萼长度、花萼宽度、花瓣长度、花瓣宽度
val fields = Array("id","Species","SepalLength","SepalWidth","PetalLength","PetalWidth")
val fieldsType = fields.map(
r => if (r == "id"||r == "Species")
{StructField(r, StringType)}
else
{StructField(r, DoubleType)}
)
val schema = StructType(fieldsType)
val featureCols = Array("SepalLength","SepalWidth","PetalLength","PetalWidth")
val data=spark.read.schema(schema).csv("data/iris")
val vectorAssembler = new VectorAssembler()
.setInputCols(featureCols)
.setOutputCol("features")
val vectorData=vectorAssembler.transform(data)
// 特征标准化
val standardScaler = new StandardScaler()
.setInputCol("features")
.setOutputCol("scaledFeatures")
.setWithMean(true)
.setWithStd(false)
.fit(vectorData)
val pca = new PCA()
.setInputCol("scaledFeatures")
.setOutputCol("pcaFeatures")
// 主成分个数,也就是降维后的维数
.setK(2)
val pipeline = new Pipeline()
.setStages(Array(vectorAssembler,standardScaler,pca))
val model = pca.fit(data)
// 对特征进行PCA降维
model.transform(data).select("Species", "pcaFeatures").show(100, false)
}
}降维后的数据只有两个维度,如下:

2.Word2Vector
在自然语言处理领域,训练集通常为纯文本,这样的数据是无法直接训练的,前面提到的TF-IDF就是一种生成词向量的方式。但是TF-IDF的缺点在于单纯以“词频”衡量一个词的重要性,不够全面,忽略了上下文信息,例如“阿里巴巴成立达摩院”与“人工智能应用有望加速落地”字面无任何相似之处,但它们之间有很强的关联,这用TF-IDF却无法体现。Word2Vec最先出现在谷歌公司在2013年发表的论文“Efficient Estimation of Word Representation in Vector Space”中,作者是Mikolov。Word2Vec的基本思想是采用一个3层的神经网络将每个词映射成n维的实数向量,为接下来的聚类或者比较相似性等操作做准备。这个3层神经网络实际是在对语言模型进行建模,但在建模的同时也获得了单词在向量空间上的表示,即词向量,也就是说这个词向量是建模过程的中间产物,而这个中间产物才是Word2Vec的真正目标。
Word2Vec采用了两种语言模型:CBOW与Skip-gram,前者是根据上下文预测下一个词,后者是根据当前词预测上下文。以CBOW为例,如图6-8所示。

图6-8 CBOW语言模型
我们选择一个固定的窗口作为语境(上下文):t − 2 — t + 2,在输入层是4个n维的词向量(初始为随机值),隐藏层做的操作是累计求和操作,隐藏层包含n个结点,输出层是一棵巨大的二叉树,构建这棵二叉树的算法就是霍夫曼树,它的叶子结点代表了语料中的M个词语,语料中有多少个词,就有多少个叶子结点。假设左子树为1,右子树为0,这样每个叶子结点都有一个唯一的编码。最后输出的时候,CBOW采用了层次Softmax算法,隐藏层的每个结点都与树的每个结点相连,则霍夫曼树上的每个结点都会有M条边,每条边都有权重,对于输入的上下文,我们需要预测的是在上下文一定的情况下,使得预测词w的概率最大,以010110为例,说明霍夫曼树有5层,我们希望在根结点,词向量与根结点相连,也就是第一层,经过回归运算得到第一位等于0的概率尽量等于1,依次类推,在第二层,希望第二位的值等于1的概率尽可能等于 1。这样一直下去,路径上所有的权重乘积就是预测词在当前上下文的概率P(wt),而在语料中我们可以得到当前上下文的残差1 − P(wt),这样的话,就可以使用梯度下降来学习参数了。
由于不需要标注,Word2Vec本质上是一种无监督学习,对自然语言处理有兴趣的读者不妨仔细阅读谷歌公司的那篇论文。
Spark MLlib内置了Word2Vec算法的Transformer实现类Word2Vec,代码如下:
import org.apache.spark.ml.feature.Word2Vec
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.Row
// 每一行输入数据都是来源于某句话或是某个文档
val documentDF = spark.createDataFrame(Seq(
"Hi I heard about Spark".split(" "),
"I wish Java could use case classes".split(" "),
"Logistic regression models are neat".split(" ")
).map(Tuple1.apply)).toDF("text")
// 设置word2Vec参数
val word2Vec = new Word2Vec()
.setInputCol("text")
.setOutputCol("result")
.setVectorSize(3)
.setMinCount(0)
val model = word2Vec.fit(documentDF)
val result = model.transform(documentDF)
result.collect().foreach { case Row(text: Seq[_], features: Vector) =>
println(s"Text: [${text.mkString(", ")}] => \nVector: $features\n") }6.3.4 特征选择
特征选择的目标通常是提高预测准确性、提升训练性能、能够更好地解释模型。特征选择的一种很重要思想就是对每一维的特征打分,这样就能选出最重要的特征了,基于这种思想的方法有:卡方检验、信息增益以及相关系数。相关系数主要量化的是任意两个特征是否存在线性相关,信息增益会在下一节介绍,本小节主要介绍卡方检验。
卡方检验是以卡方分布为基础的一种常用假设检验方法,它的原假设是观察频数与期望频数没有差别。该检验的基本思想是:首先假设原假设成立,基于此前提计算出
![]()
值,它表示观察值与理论值之间的偏离程度。根据卡方分布及自由度可以确定在原假设成立的条件下获得当前统计量及更极端情况的概率P。如果P值很小,说明观察值与理论值偏离程度太大,应当拒绝无效假设,表示比较资料之间有显著差异;否则就不能拒绝无效假设,尚不能认为样本所代表的实际情况和理论假设有差别。
假设样本的某一个特征,它的取值为A和B两个组,而样本的类别有0和1两类。对样本进行统计,可以得到表6-1所示的统计表。
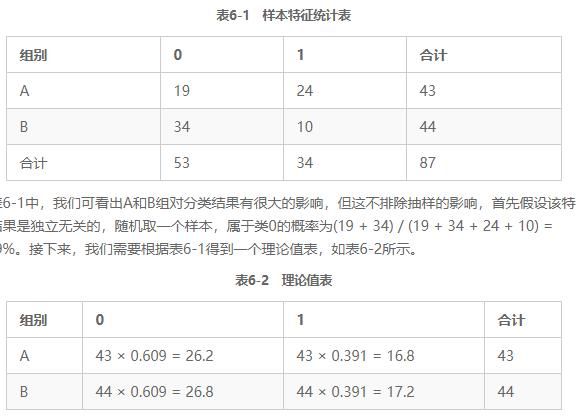
如果两个变量是独立无关的,那么表6-2中的理论值与实际值的差别会非常小。
χ 2值的计算公式为:
![]()
其中A为实际值,也就是表6-1中的4个数据,T为理论值,也就是表6-2中给出的4个数据,计算得到χ 2值为10.01。得到该值后,需要在给定的置信水平下查得卡方分布临界值,如表6-3所示。
表6-3 给定置信水平下的卡方统计量的值

显然10.01 > 7.88,也就是说该特征与分类结果无关的概率小于0.5%,换言之,我们应该保留这个特征。
Spark MLlib内置了卡方检验组件ChiSqSelector,代码如下:
import org.apache.spark.ml.feature.ChiSqSelector
import org.apache.spark.ml.linalg.Vectors
val data = Seq(
(7, Vectors.dense(0.0, 0.0, 18.0, 1.0), 1.0),
(8, Vectors.dense(0.0, 1.0, 12.0, 0.0), 0.0),
(9, Vectors.dense(1.0, 0.0, 15.0, 0.1), 0.0)
)
val df = spark.createDataset(data).toDF("id", "features", "clicked")
// 配置卡方检验参数
val selector = new ChiSqSelector()
.setNumTopFeatures(3)
.setFeaturesCol("features")
.setLabelCol("clicked")
.setOutputCol("selectedFeatures")
val result = selector.fit(df).transform(df)
println(s"ChiSqSelector output with top ${selector.getNumTopFeatures} features selected")
result.show()6.4 分类算法应用
分类器是机器学习最常见的应用,MLlib中也内置了许多分类模型,本节将会介绍决策树和随机森林,以及用Spark MLlib的随机森林分类器实现根据身体监控数据判断人体状态的实例。
6.4.1 决策树
决策树是一种机器学习的方法,本质上是通过一种树形结构对样本进行分类,每个非叶子结点是一次判断,每个叶子结点代表了分类结果。决策树是一种典型的监督学习,需要一定量的样本来学习的一个树形结构,常见的决策树构造树算法有C4.5与ID3。
下面先来看一个例子,是信贷审批常见的场景:根据信息判断客户是否会逾期,表6-4所示是一些样本,一共有4个特征,以及最后的分类结果,为了简单这是一个二分类场景。
表6-4 信贷审批样本(表略)
如果两个变量是独立无关的,那么表6-2中的理论值与实际值的差别会非常小。
χ 2值的计算公式为:
![]()
其中A为实际值,也就是表6-1中的4个数据,T为理论值,也就是表6-2中给出的4个数据,计算得到χ 2值为10.01。得到该值后,需要在给定的置信水平下查得卡方分布临界值,如表6-3所示。
表6-3 给定置信水平下的卡方统计量的值

显然10.01 > 7.88,也就是说该特征与分类结果无关的概率小于0.5%,换言之,我们应该保留这个特征。
Spark MLlib内置了卡方检验组件ChiSqSelector,代码如下:
import org.apache.spark.ml.feature.ChiSqSelector
import org.apache.spark.ml.linalg.Vectors
val data = Seq(
(7, Vectors.dense(0.0, 0.0, 18.0, 1.0), 1.0),
(8, Vectors.dense(0.0, 1.0, 12.0, 0.0), 0.0),
(9, Vectors.dense(1.0, 0.0, 15.0, 0.1), 0.0)
)
val df = spark.createDataset(data).toDF("id", "features", "clicked")
// 配置卡方检验参数
val selector = new ChiSqSelector()
.setNumTopFeatures(3)
.setFeaturesCol("features")
.setLabelCol("clicked")
.setOutputCol("selectedFeatures")
val result = selector.fit(df).transform(df)
println(s"ChiSqSelector output with top ${selector.getNumTopFeatures} features selected")
result.show()6.4 分类算法应用
分类器是机器学习最常见的应用,MLlib中也内置了许多分类模型,本节将会介绍决策树和随机森林,以及用Spark MLlib的随机森林分类器实现根据身体监控数据判断人体状态的实例。
6.4.1 决策树
决策树是一种机器学习的方法,本质上是通过一种树形结构对样本进行分类,每个非叶子结点是一次判断,每个叶子结点代表了分类结果。决策树是一种典型的监督学习,需要一定量的样本来学习的一个树形结构,常见的决策树构造树算法有C4.5与ID3。
下面先来看一个例子,是信贷审批常见的场景:根据信息判断客户是否会逾期,表6-4所示是一些样本,一共有4个特征,以及最后的分类结果,为了简单这是一个二分类场景。
以上内容摘选自《Spark海量数据处理:技术详解与平台实战》

本书基于Spark发行版2.4,循序渐进,主要分为基本理论、应用实践和总结。本书主要有下面3个特点。
- 突出实践。本书第一部分包含20余个Spark应用的例子,绝大部分带有真实数据集,供读者实践;本书第二部分是一个选自生产环境的完整的真实案例,并针对本书做了相应的优化与简化。
- 层次分明,循序渐进。本书针对学习曲线进行了优化,对于应用型内容,主要突出使用方法与实践案例;对于原理与关键问题,会深入讲解,甚至少部分还会涉及源码解读与相关论文解析。
- 技术版本新。Spark 2.0是Spark一个非常重要的版本,在设计理念与使用方式上都与以前版本有较大不同,本书完稿前的新版本2.4.4,包含了这一版本的新特性,并根据社区进展对Spark 3.0的相关特性进行了讨论与展望。