【小样本目标检测实践VOC格式】Frustratingly Simple Few-Shot Object Detection
文章目录
- 数据准备
-
- 数据来源
- 数据预处理
- FSDet
-
- step1.配置环境,跑通demo.py
- step3.准备base model
- step3.制作自己的few-shot数据集
-
- builtin.py
- builtin_meta.py
- meta_pascal_voc.py
- prepare_voc_few_shot.py
- python prepare_voc_few_shot.py
- step4.修改配置文件
- step5:运行
-
- 1shot
- 2shot
- 3shot
- 5shot
- 7shot
本文记录一下,使用FSDet进行小样本目标检测的一个实践过程(以铝材瑕疵数据为例)。
数据准备
数据来源
使用的数据集为 [飞粤云端2018]广东工业智造大数据创新大赛—智能算法赛 的数据,百度云链接: https://pan.baidu.com/s/1sncD_D12PkR4D8huei3d6Q 提取码: egwc
使用的数据为赛制第二阶段的数据,数据格式为:

在每个类别中随机挑选了15张-20张图片组成小样本数据集。
数据预处理
- 将文件中的中文改为英文
# -*- coding=utf-8-*-
"""
@Time : 22-7-12下午4:49
@Author : MaQian
@language : Python2.7
"""
import os
import numpy as np
import codecs
import json
from glob import glob
import cv2
import shutil
from xml.dom import minidom
import xml.etree.cElementTree as ET
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedShuffleSplit
# 将中文名字改为英文名 瑕疵名字用拼音代替
def change_cn2en():
cn2en_names = {'不导电': 'BuDaoDian', '喷流': 'PenLiu', '擦花': 'CaHua', '杂色': 'ZaSe',
'桔皮': 'JuPi', '漆泡': 'QiPao', '漏底': 'LouDi', '脏点': 'ZangDian',
'角位漏底': 'JiaoWeiLouDi', '起坑': 'QiKeng', '正常': 'ZhengChang'}
path = './few-shot-lvcai-data'
imgdir = os.listdir(path)
for id in imgdir:
file_path = os.path.join(path, id)
# print id.decode(encoding='utf-8')
# print(file_path)
file_names = os.listdir(file_path)
for file_name in file_names:
# print(file_name)
name = file_name.strip().split('.')[0]
type = file_name.strip().split('.')[1]
xiaciname = name[0:name.index('2018')]
if xiaciname.__contains__(','):
xcnames = xiaciname.strip().split(',')
for xcn in xcnames:
name = name.replace(xcn, cn2en_names[xcn])
name = name.replace(',', "And")
else:
name = name.replace(xiaciname, cn2en_names[xiaciname])
name = name[0:name.index('对照')]
name = name + '.' + type
# print(name)
# os.rename(file_name, name)
os.rename(os.path.join(file_path, file_name), os.path.join(file_path, name))
# 将文件夹也改为英文
def change_cn2en2():
cn2en_names = {'不导电': 'BuDaoDian', '喷流': 'PenLiu', '擦花': 'CaHua', '杂色': 'ZaSe',
'桔皮': 'JuPi', '漆泡': 'QiPao', '漏底': 'LouDi', '脏点': 'ZangDian',
'角位漏底': 'JiaoWeiLouDi', '起坑': 'QiKeng', '正常': 'ZhengChang'}
path = './few-shot-lvcai-data'
imgdir = os.listdir(path)
for id in imgdir:
if len(id) < 5:
# print(id, cn2en_names[id])
os.rename(os.path.join(path, id), os.path.join(path, cn2en_names[id]))
- 将json文件转换为xml文件
# 将数据集转换为VOC格式
# 处理json文件,生成xml文件
def handel_json2xml():
label_warp = {
'不导电': 'BuDaoDian',
'喷流': 'PenLiu',
'擦花': 'CaHua',
'杂色': 'ZaSe',
'桔皮': 'JuPi',
'漆泡': 'QiPao',
'漏底': 'LouDi',
'脏点': 'ZangDian',
'角位漏底': 'JiaoWeiLouDi',
'起坑': 'QiKeng'}
# 保存路径
saved_path = "./VOC2007/"
# 创建要求文件夹
if not os.path.exists(saved_path + "Annotations"):
os.makedirs(saved_path + "Annotations")
if not os.path.exists(saved_path + "JPEGImages/"):
os.makedirs(saved_path + "JPEGImages/")
if not os.path.exists(saved_path + "ImageSets/Main/"):
os.makedirs(saved_path + "ImageSets/Main/")
src_path = './few-shot-lvcai-data'
src_filepath = os.listdir(src_path)
json_paths = []
# image_paths = []
for id in src_filepath:
if not id.__contains__('图片'):
file_path1 = os.path.join(src_path, id)
file_names = os.listdir(file_path1)
for file_name in file_names:
if file_name.endswith('json'):
json_paths.append(os.path.join(file_path1, file_name))
# image_paths.append(os.path.join(file_path1, file_name.strip().split('.json')[0]+'.jpg'))
# print(len(json_paths))
# print(len(image_paths))
# 读取标注信息并写入 xml
for json_file_path in json_paths:
json_file_name = json_file_path.strip().split('.json')[0].split('/')[3]
json_file = json.load(open(json_file_path, "r"))
img_file_path = json_file_path.strip().split('.json')[0] + '.jpg'
# print(img_file_path)
height, width, channels = cv2.imread(img_file_path).shape
with codecs.open(saved_path + "Annotations/" + json_file_name + ".xml", "w", "utf-8") as xml:
xml.write('\n' )
xml.write('\t' + 'LvCai_data' + '\n')
xml.write('\t' + json_file_name + ".jpg" + '\n')
xml.write('\t\n' )
xml.write('\t\tLvCai Data \n')
xml.write('\t\tLvCai \n')
xml.write('\t\tflickr \n')
xml.write('\t\tNULL \n')
xml.write('\t\n')
xml.write('\t\n' )
xml.write('\t\tNULL \n')
xml.write('\t\tLvCai \n')
xml.write('\t\n')
xml.write('\t\n' )
xml.write('\t\t' + str(width) + '\n')
xml.write('\t\t' + str(height) + '\n')
xml.write('\t\t' + str(channels) + '\n')
xml.write('\t\n')
xml.write('\t\t0 \n')
for multi in json_file["shapes"]:
points = np.array(multi["points"])
labelName = multi["label"]
# 此处注意,根据自己的数据集判断是否需要-1操作
xmin = min(points[:, 0]) # -1
xmax = max(points[:, 0]) # -1
ymin = min(points[:, 1]) # -1
ymax = max(points[:, 1]) # -1
# label = multi["label"]
label = label_warp[multi["label"]]
if xmax <= xmin:
pass
elif ymax <= ymin:
pass
else:
xml.write('\t)
xml.write('\t\t' + label + '\n')
xml.write('\t\tUnspecified \n')
xml.write('\t\t1 \n')
xml.write('\t\t0 \n')
xml.write('\t\t\n' )
xml.write('\t\t\t' + str(int(xmin)) + '\n')
xml.write('\t\t\t' + str(int(ymin)) + '\n')
xml.write('\t\t\t' + str(int(xmax)) + '\n')
xml.write('\t\t\t' + str(int(ymax)) + '\n')
xml.write('\t\t\n')
xml.write('\t\n')
# print(json_file_name, xmin, ymin, xmax, ymax, label)
xml.write('')
- 将所有jpg图片移动到JPEGImages/路径下
# 复制图片到 JPEGImages/下
def move_img():
# 保存路径
saved_path = "./VOC2007/"
src_path = './few-shot-lvcai-data'
src_filepath = os.listdir(src_path)
image_paths = []
for id in src_filepath:
if not id.__contains__('图片'):
file_path1 = os.path.join(src_path, id)
file_names = os.listdir(file_path1)
for file_name in file_names:
if file_name.endswith('jpg'):
image_paths.append(os.path.join(file_path1, file_name))
# print(len(image_paths))
# image_files = glob(image_paths)
print("copy image files to $DataPath/JPEGImages/")
for image in image_paths:
shutil.copy(image, saved_path + "JPEGImages/")
- 划分train和test集合
此处粘贴两份代码,第一份是使用随机抽样,第二份是使用分层抽样。
因为本文是小样本目标检测,数据量较少,如果使用随机抽样会导致test集合中种类覆盖不全,而分层抽样可以覆盖完全。
- 随机抽样
def split_train_test():
# 保存路径
saved_path = "./few-shot-lvcai-data-voc/"
txtsavepath = saved_path + "ImageSets/Main/"
ftrainval = open(txtsavepath + '/trainval.txt', 'w')
ftest = open(txtsavepath + '/test.txt', 'w')
ftrain = open(txtsavepath + '/train.txt', 'w')
fval = open(txtsavepath + '/val.txt', 'w')
total_files = glob(saved_path + "/Annotations/*.xml")
total_files = [i.replace("\\", "/").split("/")[-1].split(".xml")[0] for i in total_files]
isUseTest = True
if isUseTest:
trainval_files, test_files = train_test_split(total_files, test_size=0.15, random_state=55)
else:
trainval_files = total_files
for file in trainval_files:
ftrainval.write(file + "\n")
# split
train_files, val_files = train_test_split(trainval_files, test_size=0.15, random_state=55)
# train
for file in train_files:
ftrain.write(file + "\n")
# val
for file in val_files:
fval.write(file + "\n")
for file in test_files:
print(file)
ftest.write(file + "\n")
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
- 分层抽样
def split_train_test():
# 保存路径
saved_path = "./VOC2007/"
txtsavepath = saved_path + "ImageSets/Main/"
ftrainval = open(txtsavepath + '/trainval.txt', 'w')
ftest = open(txtsavepath + '/test.txt', 'w')
ftrain = open(txtsavepath + '/train.txt', 'w')
fval = open(txtsavepath + '/val.txt', 'w')
total_files = glob(saved_path + "Annotations/*.xml")
# print(total_files)
classes = ['BuDaoDian', 'PenLiu', 'CaHua',
'ZaSe', 'JuPi', 'QiPao', 'LouDi',
'ZangDian', 'JiaoWeiLouDi', 'QiKeng']
x = []
y = []
for file in total_files:
file_name = file.strip().split('.xml')[0].split('/')[-1]
xiaci_name = file_name[0:file_name.index('2018')]
x.append(file_name)
y.append(classes.index(xiaci_name))
# 划分train和test集合
# 因为数据量较少,直接随机划分会导致test集合无法包含所有的瑕疵类别
ss = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=20)
tt = ss.split(x, y)
trainval_files = []
test_files = []
for train_index, test_index in tt:
for i in train_index:
trainval_files.append(x[i])
for j in test_index:
test_files.append(x[j])
train_files, val_files = train_test_split(trainval_files, test_size=0.15, random_state=55)
# trainval
for file in trainval_files:
ftrainval.write(file + "\n")
# train
for file in train_files:
ftrain.write(file + "\n")
# val
for file in val_files:
fval.write(file + "\n")
# test
for file in test_files:
# print(file)
ftest.write(file + "\n")
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
- 将信息写入(class_name)_test.txt、(class_name)_train.txt、(class_name)_val.txt、(class_name)_trainval.txt
# 将信息写入(class_name)_test.txt、(class_name)_train.txt、(class_name)_val.txt、(class_name)_trainval.txt
def per_class_trainval_test():
Classes_name = ['BuDaoDian', 'PenLiu', 'CaHua', 'ZaSe', 'JuPi', 'QiPao', 'LouDi', 'ZangDian',
'JiaoWeiLouDi', 'QiKeng', 'ZhengChang']
# 保存路径
saved_path = "./VOC2007/"
txtsavepath = saved_path + "ImageSets/Main/"
ftrainval = open(txtsavepath + '/trainval.txt', 'r')
ftest = open(txtsavepath + '/test.txt', 'r')
ftrain = open(txtsavepath + '/train.txt', 'r')
fval = open(txtsavepath + '/val.txt', 'r')
trainval = ftrainval.readlines()
test = ftest.readlines()
train = ftrain.readlines()
val = fval.readlines()
# print(trainval)
# print('ZangDian20180831094211' in trainval)
xml_file_path = saved_path + "/Annotations"
total_xml = os.listdir(xml_file_path)
# print(len(total_xml))
for idx in range(len(Classes_name)): # 每一个类单独处理
class_name = Classes_name[idx]
# print('class_name:', class_name)
# 创建txt
class_trainval = open(os.path.join(saved_path + 'ImageSets/Main', str(class_name) + '_trainval.txt'), 'w')
class_test = open(os.path.join(saved_path + 'ImageSets/Main', str(class_name) + '_test.txt'), 'w')
class_train = open(os.path.join(saved_path + 'ImageSets/Main', str(class_name) + '_train.txt'), 'w')
class_val = open(os.path.join(saved_path + 'ImageSets/Main', str(class_name) + '_val.txt'), 'w')
for file in os.listdir(xml_file_path):
# print('file:', file)
file_name = file.strip().split('.')[0]
tree = ET.parse(os.path.join(xml_file_path, file))
root = tree.getroot()
for obj in root.findall('object'):
name = obj.find('name').text
# print('name:', name)
if class_name == name:
flag = 1
else:
flag = -1
if file_name + '\n' in trainval:
class_trainval.write(file_name + ' ' + str(flag) + "\n")
if file_name + '\n' in train:
class_train.write(file_name + ' ' + str(flag) + "\n")
else:
class_val.write(file_name + ' ' + str(flag) + "\n")
else:
class_test.write(file_name + ' ' + str(flag) + "\n")
# print('==' * 20)
class_trainval.close()
class_test.close()
class_train.close()
class_val.close()
以上文件放置在FSDet/datasets/路径下。如图所示:(其中vocsplit文件在后面的章节中再生成。)

FSDet
代码地址:https://github.com/wz940216/few-shot-object-detection#data-preparation
另外还有一个参考博客: https://blog.csdn.net/qq_35030874/article/details/116996814
step1.配置环境,跑通demo.py
这一步按照github中的步骤,可以比较容易的完成。
step3.准备base model
我下载的是"voc/split1/base_model/model_final.pth"作为基础模型,放置在./base_model文件夹下。
执行以下命令,会在save_dir下生成model_reset_surgery.pth文件。
python -m tools.ckpt_surgery --src1 ./base_model/model_final_base.pth --method randinit --save-dir checkpoints/coco/faster_rcnn/faster_rcnn_R_50_FPN_base
step3.制作自己的few-shot数据集
主要需要修改的是这几个代码。

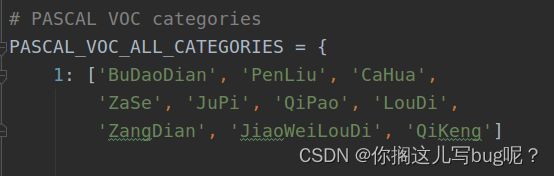
我的数据集是铝材数据,共有10种瑕疵。
builtin.py
修改register_all_pascal_voc()方法
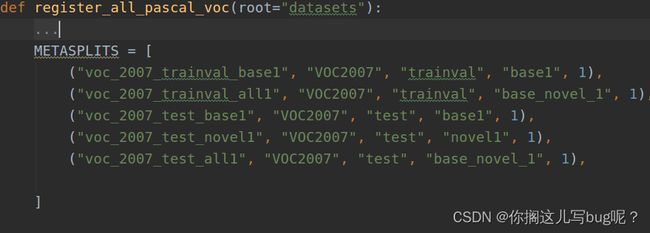


builtin_meta.py
修改为自己数据集的类别

meta_pascal_voc.py
1.该文件主要修改的就是路径,和自己数据集的路径对应即可。

2.注意此处:

prepare_voc_few_shot.py
修改为自己的数据集类别

注意修改路径

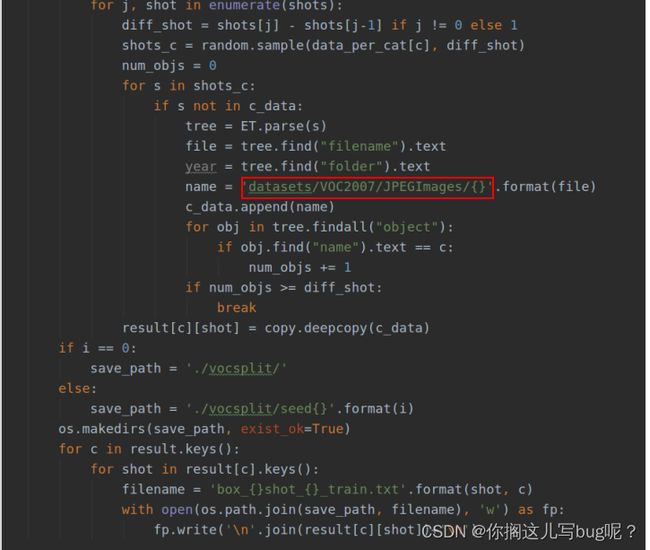
python prepare_voc_few_shot.py
运行该文件,则会在vocsplit路径下生成如下图所示的文件。

step4.修改配置文件
1shot对应的配置文件为:faster_rcnn_R_101_FPN_ft_all1_1shot.yaml

其中,两个路径和自己的路径对应,
TRAIN填写自己想要训练的数据所在文件夹,例:
'voc_2007_trainval_novel1_1shot','voc_2007_trainval_novel1_1shot_seed1','voc_2007_trainval_novel1_1shot_seed2','voc_2007_trainval_novel1_1shot_seed3','voc_2007_trainval_novel1_1shot_seed4','voc_2007_trainval_novel1_1shot_seed5','voc_2007_trainval_novel1_1shot_seed6','voc_2007_trainval_novel1_1shot_seed7','voc_2007_trainval_novel1_1shot_seed8','voc_2007_trainval_novel1_1shot_seed9','voc_2007_trainval_novel1_1shot_seed10','voc_2007_trainval_novel1_1shot_seed11','voc_2007_trainval_novel1_1shot_seed12','voc_2007_trainval_novel1_1shot_seed13','voc_2007_trainval_novel1_1shot_seed14','voc_2007_trainval_novel1_1shot_seed15','voc_2007_trainval_novel1_1shot_seed16','voc_2007_trainval_novel1_1shot_seed17','voc_2007_trainval_novel1_1shot_seed18','voc_2007_trainval_novel1_1shot_seed19'
step5:运行
1shot
运行命令为:
python3 -m tools.train_net --num-gpus 2 --config-file configs/PascalVOC-detection/split1/faster_rcnn_R_101_FPN_ft_all1_1shot.yaml --opts MODEL.WEIGHTS ./checkpoints/voc/faster_rcnn/faster_rcnn_R_50_FPN_base/model_reset_surgery.pth
- 测试结果
[07/19 12:26:56 fsdet.evaluation.pascal_voc_evaluation]: Evaluate per-class mAP50:
| BuDaoDian | PenLiu | CaHua | ZaSe | JuPi | QiPao | LouDi | ZangDian | JiaoWeiLouDi | QiKeng |
|---|---|---|---|---|---|---|---|---|---|
| 0.000 | 0.000 | 0.000 | 100.000 | 0.000 | 0.000 | 0.000 | 9.091 | 0.000 | 0.000 |
[07/19 12:26:56 fsdet.evaluation.pascal_voc_evaluation]: Evaluate overall bbox:
| AP | AP50 | AP75 | nAP | nAP50 | nAP75 |
|---|---|---|---|---|---|
| 8.068 | 10.909 | 10.909 | 8.068 | 10.909 | 10.909 |
2shot
2shot对应的配置文件为:faster_rcnn_R_101_FPN_ft_all1_2shot.yaml
也是相应的修改以上三个地方,运行命令中改为2shot即可。
运行命令为:
python3 -m tools.train_net --num-gpus 2 --config-file configs/PascalVOC-detection/split1/faster_rcnn_R_101_FPN_ft_all1_2shot.yaml --opts MODEL.WEIGHTS ./checkpoints/voc/faster_rcnn/faster_rcnn_R_50_FPN_base/model_reset_surgery.pth
- 测试结果
[07/19 15:25:58 fsdet.evaluation.pascal_voc_evaluation]: Evaluate per-class mAP50:
| BuDaoDian | PenLiu | CaHua | ZaSe | JuPi | QiPao | LouDi | ZangDian | JiaoWeiLouDi | QiKeng |
|---|---|---|---|---|---|---|---|---|---|
| 0.000 | 0.000 | 0.000 | 100.000 | 2.020 | 0.000 | 0.000 | 27.273 | 0.000 | 0.000 |
[07/19 15:25:58 fsdet.evaluation.pascal_voc_evaluation]: Evaluate overall bbox:
| AP | AP50 | AP75 | nAP | nAP50 | nAP75 |
|---|---|---|---|---|---|
| 10.697 | 12.929 | 12.727 | 10.697 | 12.929 | 12.727 |
3shot
运行命令:
python3 -m tools.train_net --num-gpus 2
--config-file configs/PascalVOC-detection/split1/faster_rcnn_R_101_FPN_ft_all1_3shot.yaml --opts MODEL.WEIGHTS ./checkpoints/voc/faster_rcnn/faster_rcnn_R_50_FPN_base/model_reset_surgery.pth
- 测试结果
[07/19 18:21:31 fsdet.evaluation.pascal_voc_evaluation]: Evaluate per-class mAP50:
| BuDaoDian | PenLiu | CaHua | ZaSe | JuPi | QiPao | LouDi | ZangDian | JiaoWeiLouDi | QiKeng |
|---|---|---|---|---|---|---|---|---|---|
| 0.000 | 0.000 | 0.000 | 100.000 | 2.797 | 0.000 | 0.000 | 36.364 | 0.000 | 0.000 |
[07/19 18:21:31 fsdet.evaluation.pascal_voc_evaluation]: Evaluate overall bbox:
| AP | AP50 | AP75 | nAP | nAP50 | nAP75 |
|---|---|---|---|---|---|
| 11.629 | 13.916 | 13.636 | 11.629 | 13.916 | 13.636 |
5shot
运行命令:
python3 -m tools.train_net --num-gpus 2 --config-file configs/PascalVOC-detection/split1/faster_rcnn_R_101_FPN_ft_all1_5shot.yaml --opts MODEL.WEIGHTS ./checkpoints/voc/faster_rcnn/faster_rcnn_R_50_FPN_base/model_reset_surgery.pth
- 测试结果
[07/20 14:08:23 fsdet.evaluation.pascal_voc_evaluation]: Evaluate per-class mAP50:
| BuDaoDian | PenLiu | CaHua | ZaSe | JuPi | QiPao | LouDi | ZangDian | JiaoWeiLouDi | QiKeng |
|---|---|---|---|---|---|---|---|---|---|
| 0.000 | 0.000 | 0.000 | 100.000 | 12.121 | 0.000 | 0.000 | 36.364 | 0.000 | 0.000 |
[07/20 14:08:23 fsdet.evaluation.pascal_voc_evaluation]: Evaluate overall bbox:
| AP | AP50 | AP75 | nAP | nAP50 | nAP75 |
|---|---|---|---|---|---|
| 12.394 | 14.848 | 14.848 | 12.394 | 14.848 | 14.848 |
7shot
运行命令:
python3 -m tools.train_net --num-gpus 2
--config-file configs/PascalVOC-detection/split1/faster_rcnn_R_101_FPN_ft_all1_7shot.yaml
--opts MODEL.WEIGHTS ./checkpoints/voc/faster_rcnn/faster_rcnn_R_50_FPN_base/model_reset_surgery.pth
- 测试结果
[07/20 18:57:56 fsdet.evaluation.pascal_voc_evaluation]: Evaluate per-class mAP50:
| BuDaoDian | PenLiu | CaHua | ZaSe | JuPi | QiPao | LouDi | ZangDian | JiaoWeiLouDi | QiKeng |
|---|---|---|---|---|---|---|---|---|---|
| 0.000 | 0.000 | 0.000 | 100.000 | 12.121 | 0.000 | 0.000 | 36.364 | 0.000 | 0.000 |
[07/20 18:57:56 fsdet.evaluation.pascal_voc_evaluation]: Evaluate overall bbox:
| AP | AP50 | AP75 | nAP | nAP50 | nAP75 |
|---|---|---|---|---|---|
| 12.273 | 14.848 | 14.545 | 12.273 | 14.848 | 14.545 |
从上述结果可以看出,效果并不好,多个类别的AP为0,,在尝试了各种方法,还是没有改善之后,看到了这个issue.从这个issue中的描述,我们将配置文件中的 BACKBONE的FREEZE改为 False之后,得到的结果如下所示:
[07/25 12:06:00 fsdet.evaluation.pascal_voc_evaluation]: Evaluate per-class mAP50:
| BuDaoDian | PenLiu | CaHua | ZaSe | JuPi | QiPao | LouDi | ZangDian | JiaoWeiLouDi | QiKeng |
|---|---|---|---|---|---|---|---|---|---|
| 100.000 | 72.727 | 45.455 | 100.000 | 100.000 | 63.636 | 100.000 | 72.727 | 100.000 | 100.000 |
[07/25 12:06:00 fsdet.evaluation.pascal_voc_evaluation]: Evaluate overall bbox:
| AP | AP50 | AP75 | nAP | nAP50 | nAP75 |
|---|---|---|---|---|---|
| 62.803 | 85.455 | 67.273 | 62.803 | 85.455 | 67.273 |
效果有明显提升,至于具体的原因,目前还未找出。