python爬虫——爬取小说
一、导入requests和parsel库
requests是一个HTTP请求库,像浏览器一样发送THHP请求来获取网站信息。
parsel是对 HTML 和 XML 进行解析库,
import requests
import parsel二、获取小说网站内容
通过 url = "https://www.777zw.net/1/1429/" 爬取小说网站内容。
url = "https://www.777zw.net/1/1429/"
response = requests.get(url)
responses = response.text.encode('iso-8859-1').decode('gbk')
print(responses)在爬取小说网站时遇见一个错误爬取中文编译乱码:
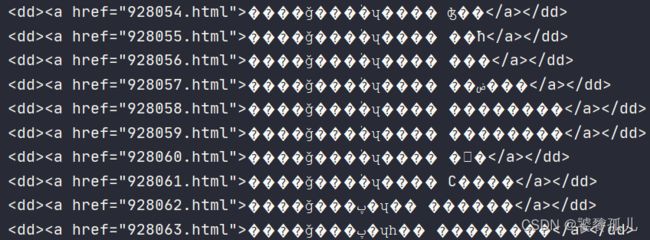
之后查找资料发现是由于网页编码用的方式不同 :
解决方法
查看网站所用编码方法,打开想爬取页面开启开发人员工具,在控制台输入document.charse查看文本格式

将常规的 "utf-8" 格式转换成 "gbk"
# utf-8格式
response.encoding = 'utf-8'
# 改成gbk格式
response.text.encode('iso-8859-1').decode('gbk')获取网页内容代码:
url = "https://www.777zw.net/1/1429/"
response = requests.get(url)
responses = response.text.encode('iso-8859-1').decode('gbk')
print(responses)三、获取小说名和获取小说章节
在开发者工具中找到小说名:

爬取方法
selector = parsel.Selector(responses)
novel_name = selector.css('#info h1::text').get() #小说名#info 获取 id 是 info,h1 存取小说名,小说名是文本文件所以用text
找到小说章节

爬取代码
href = selector.css('#list dd a::attr(href)').getall() #小说章节get() 获取一个,getall() 获取所有小说章节
四、获取章节名和小说内容
这一步原理和步骤一样就不多赘述了
五、源代码
import requests
import parsel
url = "https://www.777zw.net/1/1429/"
response = requests.get(url)
responses = response.text.encode('iso-8859-1').decode('gbk')
print(responses)
selector = parsel.Selector(responses)
novel_name = selector.css('#info h1::text').get() #小说名
href = selector.css('#list dd a::attr(href)').getall() #小说章节
for link in href:
link_url = 'https://www.777zw.net/1/1429/' + link
response_1 = requests.get(link_url)
responses_1 = response_1.text.encode('iso-8859-1').decode('gbk')
selecter_1 = parsel.Selector(responses_1)
title_name = selecter_1.css('.bookname h1::text').get() #小说章节
content_list = selecter_1.css('#content::text').getall() #小说内容
content = '\n'.join(content_list)
break
# 保存
with open(novel_name + '.txt',mode = 'a',encoding = 'utf-8') as f:
f.write(title_name)
f.write('\n')
f.write(content)
f.write('\n')
# print(title_name)
print(novel_name)
print(content_list)六、结果
