可解释人工智能XAI
可解释人工智能XAI
本文基于Freddy Lecue博士在2022年国际人工智能顶会AAAI上完成的可解释人工智能进展报告,腾讯研究院在2022年发布的国内业界首份《可解释AI发展报告2022——打开算法黑箱的理念与实践》,以及可解释人工智能领域的相关论文,对可解释人工智能(Explainable Artificial Intelligence, XAI)进行介绍,主要包括:①XAI介绍及动机;②XAI概念及相关研究;③AI的挑战及XAI的应用。
文章结构
- 可解释人工智能XAI
- 1. XAI介绍及动机
-
- 1.1 XAI与透明度、问责制
- 1.2 AI偏见
- 1.3 XAI的意义
- 2. XAI概念及相关研究
-
- 2.1 XAI概念
- 2.2 XAI相关研究
- 3. AI的挑战及XAI的应用
-
- 3.1 人力资源--Linked in可解释人才招聘
- 3.2 航天航空--THALES可解释的航班延误预测
- 3.3 医疗卫生--腾讯天衍可信可解释的疾病风险预测模型
- 参考资料
1. XAI介绍及动机
1.1 XAI与透明度、问责制
随着各界对AI伦理的日益重视,AI系统的可解释性也逐渐成为热点,甚至上升到立法和监管的要求。许多人工智能领域的专家都把 2021 年视为“AI 可解释元年”,在这一年,不仅政府出台相应的监管要求,国内外许多科技公司,譬如谷歌、微软、IBM、美团、微博、腾讯等,也都推出了相应的举措。
人工智能被采用需具备以下5个要求:有效性、负责任、隐私保护、可信任以及可解释性。2021年11月,联合国 UNESCO通过的首个全球性的Al伦理协议《人工智能伦理建议书》,提出的十大Al原则就包括“透明性与可解释性”,即算法的工作方式和算法训练数据应具有透明度和可理解性。
对可解释 Al的讨论往往离不开两个关联概念,即透明度和问责制。概言之,透明度是可解释Al的主要目标,而可解释性是实现透明度的一种方式;问责制是可解释Al的必要保障机制,而可解释性主要是为了确保能够问责。
具体而言,透明度是指对外提供Al算法的内部工作原理,包括Al系统如何开发、训练和部署,以及披露Al相关活动,以便人们可以进行审查和监督。透明度的目的是为相关对象提供适当的信息,以便他们理解和增进信任。
关干可解释性与问责制,根据经合组织的说法,问责制是指让适当的组织或个人承担Al系统正常运作的责任的能力。问责制处于AI伦理层次结构的顶端,其他AI伦理目标都要为之作出贡献。在Al可解释的思路下,问责制要求Al具备一些理想的特征,如尊重人类价值和公平性、透明度、稳健性和安全性等原则。人类价值和公平性要求对Al系统进行灵活的、针对特定背景的解释。可以说,可解释Al的核心目标之一就是确保能够对Al系统进行问责。
1.2 AI偏见
2022年3月16日,美国国家标准与技术研究院(NIST)发布了《迈向识别和管理人工智能偏见的标准》(Towards a Standard for Identifying and Managing Bias in Artificial Intelligence),其目的是揭示人工智能偏见的突出问题,并为识别和管理人工智能偏见的技术提供指导。
人工智能风险管理旨在最大限度地减少人工智能的负面影响,包括对公民自由和权利的威胁等。而在谈论人工智能风险时,“偏见”是一个重要话题。虽然人工智能偏见并不总是负面的,如通过自动化系统决策为公众提供生活便利。然而,人工智能模型和系统中表现出的某些偏见也可能对个人、组织和社会造成永久化和放大的负面影响,如下图。《迈向识别和管理人工智能偏见的标准》中,将人工智能偏见分为系统性偏见、统计性偏见和人类偏见三大类别。

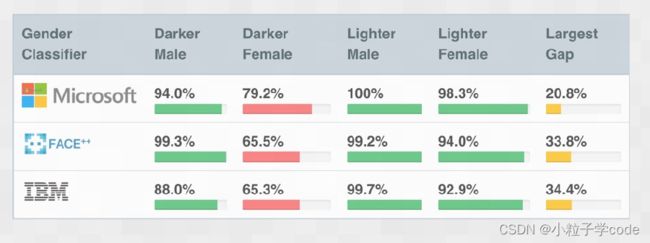
(1)系统性偏见。系统性偏见源于特定机构的程序和实践,其运作方式导致某些社会群体处于有利或有利地位,而其他群体处于不利地位或贬值。这不一定是有意识的偏见或歧视的结果,而是大多数人遵守现有规则或规范的结果。制度上的种族主义和性别歧视是最常见的例子。这些偏见存在于人工智能使用的数据集中,以及整个人工智能生命周期以及更广泛的文化和社会中的制度规范、实践和过程中。如图,人脸识别算法在非白人和女性人脸上表现较差,其原因在于用于训练人工智能的数据往往偏向于单一的人口统计学,即白人男性。当一个程序看到的数据不在该人口统计学中时,它的表现很差。并非巧合,这是因为是白人主导了人工智能研究。其次,超分辨率算法 PULSE29将美国前总统奥巴马的肖像图转化为白人男性的形象,这起乌龙事件的主要“凶手”,就是该神经网络的训练所使用的Flickr-Faces-HQ(FFHQ,人脸图像数据集),而这个数据集中大部分的图像素材都是白人照片。
(2)统计性偏见。统计和计算偏差源于样本不能代表总体时产生的错误。这些偏差在没有偏见、偏袒或歧视意图的情况下也可能发生。在人工智能系统中,这些偏差存在AI应用程序开发中使用的数据集和算法中。误差可能来源于异质数据、复杂数据、错误数据和算法偏差,如过度拟合和欠拟合、异常值处理以及数据清理和插补因子。
(3)人类偏见。类偏见是人类思维的基本部分,反映了人类思维中的系统性错误。这些偏见通常是隐含的,往往与个人或群体如何感知信息(如自动AI输出)以做出决策或填写缺失或未知信息有关。这些偏见在整个人工智能生命周期的机构、团队和个人决策过程中。
1.3 XAI的意义
(1)帮助用户增强对Al系统的信心与信任。对Al的自动决策提供一个解释,可以在很大程度上增进人们对 Al系统的信心与信任,尤其是在预测的准确性与合理性方面。用户寻求解释的目的多种多样,包括深入学习、与社会良性互动、分配责任等。通过对算法决策的解释,一方面能够保障公众基本的知情权和同意权,另一方面也有利于增强公众对AI产品的信心与信任。
(2)防止偏见,促进算法公平。可解释Al旨在对算法黑箱、算法失灵等问题作出回应,赋予用户对算法决策机制的知情权等,通过算法透明化机制倒逼开发者、提供者采取有效的措施防范算法歧视、决策偏差等问题,从而促进算法公平,实现科技向善。
(3)满足监管标准或政策要求。透明度或可解释性对于行使围绕Al系统的法律权利、证明产品或服务符合监管标准,以及帮助解决有关责任的问题具有重要意义。在满足监管标准的条件下,可解释 Al将摆脱决策合法性的质疑,能够更加高效无误地执行特定事务,而无须担忧决策结果是否会引发政府的干预和制裁.从而提升决策的效率。此外,Al 可解释性对干确保问责也至关重要,至少可以为质疑 Al系统的输出、结果提供基础。
(4)理解和验证Al系统的输出,推动系统设计的改进。可解释性可以帮助开发人员探究、分析Al系统以某种方式产出某种结果的原因,并对 Al系统的输出进行验证,进而帮助开发人员理解 Al系统,做出正确的决定,在此基础上对 Al系统做出改进。例如,在自动驾驶汽车中,了解系统为什么以及如何发生故障;在医疗保健领域,可解释性可以帮助医疗人员理解结果,研发人员可以跟踪系统故障等,如图。

2. XAI概念及相关研究
2.1 XAI概念
在可解释AI领域,存在两个术语,分别是Interpretable和Explainable,这两个术语在英文里本身就是同义词,表示“capable of being understood”。不同文献对这两个词的定义都各有不同,有一些文献不区分这两个词,例如Miller 1认为需要区分Interpretable和Explainable,前者表示模型决策可以被理解的性质,后者表示对某个特定实例的解释。具体而言,Interpretable表示模型固有的性质,即模型自身的决策过程对人类来说即是可理解的,例如(广义)线性模型、决策树等;Explainable表示对模型决策过程的事后可重建性,而模型本身的决策可以是黑盒、不透明的,这种重建的解释不一定和真实的模型决策一致。

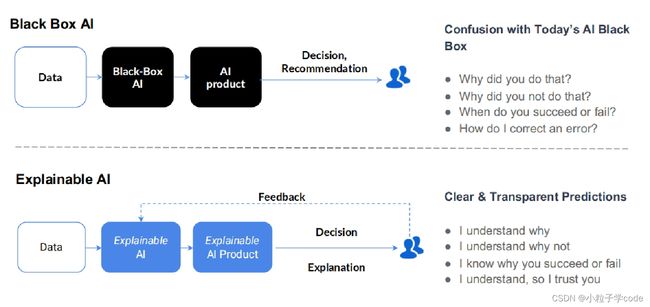
可解释AI 不论是学术界还是工业界都没有一个统一的定义。根据美国国防部先进研究项目局(DARPA),如图,可解释AI的目的就是要解决用户面对模型黑盒遇到问题,从而实现:①用户知道AI系统为什么这样做,也知道AI系统为什么不这样做;②用户知道AI系统什么时候可以成功,也知道AI系统什么时候失败;③用户知道什么时候可以信任AI系统;④用户知道AI系统为什么做错了。
2.2 XAI相关研究
针对模型的可解释性,一个用户可能会存在多个连续的问题,其次不同的用户所关心的问题是不一样的,因此文献 2认为解释系统应该是交互式的,可以为一个用户的多个后续问题进行解释,也能为不同用户提出来的问题进行解释。该文献设想一个交互式的解释系统,在向用户提供初始解释后,该系统支持许多不同的后续和深入操作。为了使这些想法具体化,下图显示了一个可能的对话框,用户试图理解构建在深层神经网络Inception v3上的狗/鱼分类器的稳健性,如图所示:①计算机正确预测图像描绘了鱼;②用户请求解释,计算机使用LIME模型为用户提供解释;③用户担心分类器更关注背景而不是鱼本身,要求查看影响分类器的训练数据,计算机则使用影响函数计算最近邻,找到两张对该分类结果具有较大影响的训练样本图像;④为了获得置信度,用户删除输入图像的背景,将其重新提交给分类器并检查解释。

研究 3为了探索用户更喜欢哪种解释方式,进行交叉分析研究,对六种较为流行的解释方法进行对比,以实证方式确定哪种方法更适合解释模型决策。参与者被要求在图像、文本、音频和感官识别等领域中对不同的解释方法进行对比。通过比较六种流行的解释方法,以确定哪些风格在理解DNN模型决策中最受欢迎。六种解释方法分别为LIME,GradCAM++,Anchor,SHAP,显着性图和示例解释。每个参与者分别对解释方法进行一一对比,并选择他们认为提供更好解释的方法,从而提供解释方法的相对排名。下图提供了描述图像、文本和心电图输入的解释方法。

3. AI的挑战及XAI的应用
3.1 人力资源–Linked in可解释人才招聘
在寻找候选人时,如何简化招聘人员的人才搜索,是当今的一个挑战。其中候选人的特征是动态的且计算成本高。招聘人员有兴趣对两名候选人进行对比以进行选择。Linked in公司采用广义线性混合模型、人工神经网络以及XGBoost等模型进行建模,从而实现人才选择。广义线性混合模型自身固有可解释能力,其次通过XGBoost中可获得特征重要性。
3.2 航天航空–THALES可解释的航班延误预测
全球每年有323,454个航班延误。去年航空公司造成的延误共计2020万分钟,给该公司带来了巨大的成本。现有的内部技术预测航班延误的准确率达到53%,不提供任何时间估计(以分钟为单位,而不是真/假),并且无法捕捉根本原因(解释)。THALES公司集成AI相关技术,即机器学习(深度学习/递归神经网络)、推理(通过语义增强的基于案例的推理)和自然语言处理,以建立一个健壮的模型,该模型可以以分钟为单位预测飞行延迟,并通过与历史案例的比较来解释延迟 4。

3.3 医疗卫生–腾讯天衍可信可解释的疾病风险预测模型
建立基于历史电子病例的个性化医疗预测模型已成为一个活跃的研究领域。得益于强大的特征提取能力,深度学习(DL)方法在许多临床预测任务中取得了良好的性能。然而,由于缺乏可解释性和可信度,很难将DL应用于实际的临床决策案例中。
可解释性要求临床决策模型能够提供决策的依据,即决策的规则、参考因素以及各类因素对最终决策的权重占比;可信度要求模型能够提供DL模型在认知层面上的不确定度,即能够识别训练数据分布以外的样本。基于此,天衍实验室的研究人员在自解释深度模型基础上,将模型扩展为参数不确定的贝叶斯神经网络,如图。
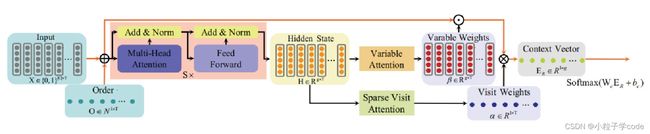
如图所示,以心力衰竭风险评估为例,医生在借助天衍疾病风险预测模型诊断过程中,既能看到输入的各个症状对最终预测结果的贡献度(图左),又能通过观察模型对该患者患病风险评估的概率分布(图右,方差越大越不确定)来判断模型对该评估过程在认知层面上的确定程度。举例来说,如果所预测的概率分布方差超过一定阈值,就表明模型对该次诊断是极度不确定的。在这种情况下,天疾病风险预测系统会提醒医生该次诊断结果的参考价值不高,并推荐对该病例进行多专家会诊。腾讯天衍疾病风险预测模型着眼于与模型落地相关问题中极为重要的两方面,即可解释性和可信度,以此来增加模型的透明性。一方面告诉医生模型对预测结果的判断依据,另一方面能在模型自身认知不足的情况下主动提醒医生而不是不计后果地"随机猜测"。

参考资料
Miller, T. (2019). Explanation in artificial intelligence: Insights from the social sciences. Artificial intelligence, 267, 1-38. ↩︎
Weld D S, Bansal G. The challenge of crafting intelligible intelligence[J]. Communications of the ACM, 2019, 62(6): 70-79. ↩︎
Jeyakumar J V, Noor J, Cheng Y H, et al. How can i explain this to you? an empirical study of deep neural network explanation methods[J]. Advances in Neural Information Processing Systems, 2020, 33: 4211-4222. ↩︎
Jiaoyan Chen, Freddy Lécué, Jeff Z. Pan, Ian Horrocks, Huajun Chen: Knowledge-Based Transfer Learning Explanation. KR 2018: 349-358 ↩︎