从零开始yolov3的tensorfow-gpu环境搭建到实现迁移学习全过程
从零开始yolov3的tensorfow-gpu环境搭建及成功实现迁移学习全过程
-
从零开始yolov3的tensorfow-gpu环境搭建及成功实现迁移学习全过程 -
- 一、tensorflow-gpu环境搭建
-
- 1.1、给conda设置镜像源
- 1.2、conda安装tensorflow-gpu
- 1.3、其他依赖模块安装
- 二、yolov3复现
-
- 2.1、voc数据集的下载及处理
- 2.2、使用聚类计算anchors
- 2.3、convert.py生成h5模型文件
- 2.4、使用train.py模型训练
- 2.5、运行train.py报错解决办法
- 2.6、yolo_video.py预测
- 2.7、预测图片报错及解决办法
- 三、迁移学习,训练自己数据
-
- 3.1、制作训练集txt文件
- 3.2、聚类生成自己数据anchors
- 3.3、使用train.py训练模型
- 3.4、使用yolo_video.py做预测
- 四、总结
-
- reference
yolov3所需环境为tensorflow-gpu和keras,keras很简单,但是搭建tensorflow-gpu并且使yolov3程序可以跑起来却不是那么容易,在本人第二次搭建环境的情况下,却也折腾了一个白天,中途出现各种问题,要不就是可以运行程序,但不是在GPU上运行;要不就是直接各种报错,最后还是成功搭建好,并且能够运行了,下面我将把整个流程(环境安装,成功运行程序)记录下来。本实验程序为github上大神qqwweee项目:
https://github.com/qqwweee/keras-yolo3
一、tensorflow-gpu环境搭建
在这里我还是建议使用anaconda进行tensorflow-gpu的安装,因为conda安装可以省去很多cuda和cudnn的配置,这这两个的版本配置还跟tensorflow-gpu版本有很大关系,所以自行配很容易出错,这里直接使用conda安装,anaconda的安装可以直接去anaconda官网下载安装(注:安装时候记得勾选自动设置环境变量,要不然在命令提示符界面conda指令就运行不了),如果不小心没有设置好环境变量,可以自行在设置界面搜索”环境变量“,然后进入后在系统变量那一栏找到”path“,双击后把下面四行一个一个的添加上去并保存即可:
C:\ProgramData\Anaconda3
C:\ProgramData\Anaconda3\python
C:\ProgramData\Anaconda3\Scripts
C:\ProgramData\Anaconda3\Library\bin
1.1、给conda设置镜像源
因为conda自带的安装源速度特别慢,所以如果你不设置镜像源下载几乎还是安装不了,中途会自动断开,这里我选择清华镜像源,首先打开anaconda prompt,依次输入以下四个指令:
添加镜像源:conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
添加镜像源:conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
设置搜索时显示通道地址:conda config --set show_channel_urls yes
显示镜像源设置情况:conda config --show channels
这里最后一行为显示镜像源设置情况,如果看到结果显示有上述链接表示设置成功。当然也有删除镜像源的指令如下:
删除镜像源:conda config --remove channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
1.2、conda安装tensorflow-gpu
这里我建议使用conda创建一个新环境给tensorflow-gpu,因为这样在这个环境下任何修改不会影响到其它环境,当然更重要的是,在其他环境下的一些操作不会影响到这,要不然可能你之后运行其他程序导致tensorflow需要的一些模块改变容易导致yolo运行报错。
创建新环境指令为:conda create -n tensorflow-gpu tensorflow-gpu==1.14.0
创建环境名为tensorflow-gpu的新环境,并且在新环境安装tensorflow-gpu1.14.0版本,此版本可以运行yolov3,本人目前也在使用此版本,稍等片刻后会弹出一个让你选择是否下载的选项,输入y就行,这个时候就等安装成功即可。
环境创建好后,就是进入新环境了,因为后续操作都是在新环境下,所以需要先进入新环境,使用下面一些指令可以激活和退出、删除等对环境的操作:
1、激活环境:activate tensorflow-gpu
2、退出环境:deactivate
3、删除环境(慎重):conda env remove -n tensorflow-gpu
4、列出所有虚拟环境:conda env list
5、列出当前环境所有包:conda list
1.3、其他依赖模块安装
因为yolov3还需要安装keras、pil、matplotlib、cv2,所以直接使用以下指令在新环境tensorflow-gpu内下载安装即可:
pip install keras
pip install pillow
pip install matplotlib
pip install opencv.python
二、yolov3复现
首先我相信你已经在github上下载好了代码,下面将从实现voc数据集训练及预测开始到迁移学习训练自己数据集来讲解yolov3的使用.
2.1、voc数据集的下载及处理
正如你看到的,keras-yolov3-master文件夹里有一个voc_annotation.py文件,这是用来将voc数据集处理成txt文件类型以方便模型进行训练,所以我们首先也是要使用voc_annotation.py程序来获取我们需要的train.txt文件,当然在这之前你肯定需要将pascal_voc数据集下载好,这里我给出下载地址,官网有时候打不开,推荐使用镜像链接:
镜像下载地址: https://pjreddie.com/projects/pascal-voc-dataset-mirror/
官网下载地址: http://host.robots.ox.ac.uk/pascal/VOC/
在运行voc_annotation.py程序之前,还是有几点需要注意,首先是voc数据集下载后你解压的位置,如果你不想后续麻烦我建议直接解压到keras-yolo3-master的目录下,这样可以直接在这个路径上运行程序,如果你解压到其他路径上就需要在voc数据集的vocdevkit目录地址上运行程序,并且解压是直接将三个压缩包一起解压就行;同时作者程序是默认只生成voc_2007的数据集,如果你想用2012的数据集,需要在程序中修改一下sets里面数字。
运行好voc_annotation.py后,你就会在当前目录下看到生成的train.txt和val.txt以及test.txt文件,当然yolov3训练程序还是只会用到train.txt,验证集是从train_data里面划分出来的。然后你只需要把这些txt文件放在keras-yolo3-master的目录下即玩成了这一步。
2.2、使用聚类计算anchors
在文件中,有一个model_data文件夹,里面已经存放了作者默认的yolo_anchors和tiny_yolo_anchors两个文件,但是如果你想要使用更适合你自己数据集的anchors,那么你就需要使用kmeans.py程序了,首先,你还是要打开kmeans.py,滑到最下面几行代码:
if __name__ == "__main__":
cluster_number = 9
filename = "2012_train.txt"
kmeans = YOLO_Kmeans(cluster_number, filename)
kmeans.txt2clusters()
将cluster_number设置为你的个数,如果你想用完整版yolov3,那就填9,如果你想用tiny-yolov3那就填6;filename就填你之前产生的训练集的txt文件名。运行后会产生一个名为yolo_anchors.txt文件,当然这个文件名你也可以在程序的第61行处修改。产生的该文件就可以复制到model_data文件夹里面去。
2.3、convert.py生成h5模型文件
这一步其实不是必须的,但是可以通过这一步直接获取已经训练好的模型权重,方便快速实现模型预测,想跳过这一步的直接可以看下一节使用train.py模型训练。当然一些必要的准备工作还是必须的,逆你需要提前下载好权重.weight文件,这些文件可以通过下面链接下载,对应于不同类型模型的权重:
yolov3.weights:https://pjreddie.com/media/files/yolov3.weights
yolov3-tiny.weights:https://pjreddie.com/media/files/yolov3-tiny.weights
darknet53.weights:https://pjreddie.com/media/files/darknet53.conv.74
上述链接都可以在yolo官网找到: https://pjreddie.com/darknet/yolo/
下载好后可以直接就放在master文件内的目录下,然后在终端上直接输入下面指令,当然,不同模型权重你需要更改.cfg的文件名和保持的h5文件名,过完这一步其实已经可以做预测了,可以直接跳转到2.6节。
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
2.4、使用train.py模型训练
到这里必要的准备工作差不多已经做完,差不多可以开始训练了,训练呢肯定就是使用train.py文件,需要明白的是,训练这里其实分为两种,一种是不含初始权重的训练,另一种是使用上一节生成的h5模型文件继续训练,如果你是做跟voc或者coco数据集类似的数据集训练,第二种方法可以更快让你模型收敛,但是如果你训练集跟它们完全不一样,比如细胞的检测,那么我还是建议直接从0开始训练,也就不需要之前的h5模型文件。
下面我们具体来讲讲怎样修改train.py文件实现模型训练,首先打开train.py代码,可以看到前面可修改参数:
def _main():
annotation_path = 'train.txt' #训练集的txt文件名
log_dir = 'logs/000/' #模型保存的文件夹,这个需要自己提前创建好
classes_path = 'model_data/voc_classes.txt' #数据集的class.txt文件
anchors_path = 'model_data/yolo_anchors.txt' #anchors文件
根据具体情况可以对上述变量赋值,接下来是跳转到train.py程序第30行和第33行
if is_tiny_version:
model = create_tiny_model(input_shape, anchors, num_classes,
freeze_body=2, weights_path='model_data/tiny_yolo_weights.h5')
else:
model = create_model(input_shape, anchors, num_classes,
freeze_body=2, weights_path='model_data/yolo_weights.h5')
这里是当你准备选用第二种方式训练模型(即使用已有模型h5文件继续训练),需要将准备继续训练的h5文件路径写入weight_path中。但是如果你准备使用第一种训练方法,那你就需要跳转到代码第105和135行(分别对应yolo和tiny_yolo)的模型生成函数处,将load_pretrained参数设置为False,如下所示:
def create_model(input_shape, anchors, num_classes, load_pretrained=False, freeze_body=2,
weights_path='model_data/yolo_weights.h5'):
当然,你可以在代码的第57行和76行设置你的batch_size的大小,在63和82行设置你的训练轮数等,你可能会问这里怎么有两次模型训练代码,因为这里作者是这样设计的:第一次模型训练是一直训练完毕设置的epochs,而第二次训练其learn_rate会自行调节,并且有早停功能,即发现loss一直不降会直接停止训练并且保存最优模型,所以其实这一部分训练所需内存很大,因为要保存很多次模型结果,如果你发现到这一步会保错,可以试着降低batch_size。
需要设置的部分差不多就这些了,然后你就可以开始训练了,直接控制台运行python train.py即可。
2.5、运行train.py报错解决办法
当然本人还是遇到一些问题,如果你跟我一样遇到下面报错,那就使用下面方法解决,下面是报错图片:
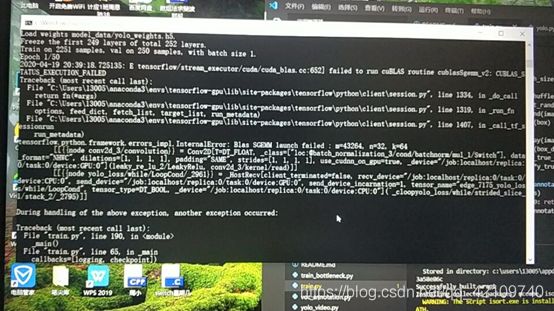
具体来说就是下面这个错误:
IternalError:Blas SGEMM launch failed : m=43264, n=32, k=64
我的解决办法是在train.py代码的前面加上这几行代码:
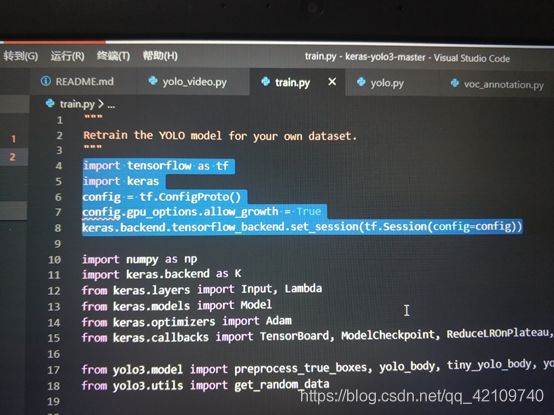
import tensorflow as tf
import keras
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
keras.backend.tensorflow_backend.set_session(tf.Session(config=config))
接着运行一下发现可以运行了。nice!!!!(这里再插播一条,如果你做预测时也遇到同样问题,也还是同样解决办法,再yolo_video.py代码前加上述代码)
2.6、yolo_video.py预测
模型训练完后,或者之前convert产生的h5文件,就可以拿来做预测了,yolo_video.py其实更像是一个脚本文件,真正我们很多需要更改的参数其实是在yolo.py程序里,所以,我们打开yolo.py代码,可以看到前面参数设置:
class YOLO(object):
_defaults = {
"model_path": 'model_data/yolo.h5', #模型文件地址
"anchors_path": 'model_data/yolo_anchors.txt', #anchors地址
"classes_path": 'model_data/coco_classes.txt', #数据集的class地址
"score" : 0.3, #预测框分数阈值,如果预测框少可以试着调小
"iou" : 0.45, #iou阈值,如果预测框少可以试着调小
"model_image_size" : (416, 416), #不用更改
"gpu_num" : 1, #gpu使用数
}
更改完上述参数,保存好,你就可以直接使用指令:
python yolo_video.py [video_path] [output_path (optional)]
来实现对视频的预测,上述两个参数是视频地址和预测结果保存的地址,本人使用的是.mp4文件,结果也保存为.mp4文件。
当然,如果你想实现对图片预测,而不是视频,你就需要使用指令:
python yolo_video.py --image
或者你直接到yolo_video.py的48行将default=False改成True。然后就直接使用python yolo_video.py指令即可。
2.7、预测图片报错及解决办法
本人在预测图片过程中又出现了一个报错:
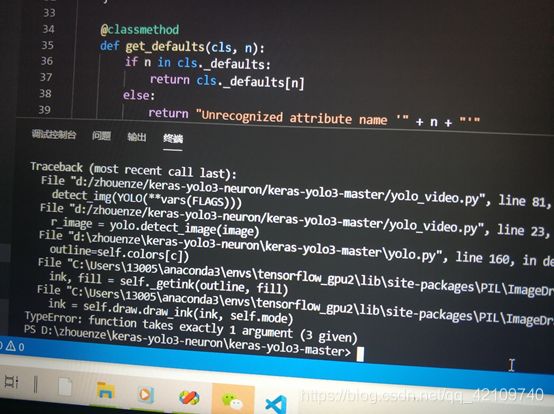
即报错:
TypeError: function takes exactly 1 argument (3 given)
解决办法是将yolo.py第158、161、162这三行的代码改一下,因为好像是pil库的draw函数对于颜色选择不支持rgb数字表达形式,改成英文单词形式,即改成:
for i in range(thickness):
draw.rectangle(
[left + i, top + i, right - i, bottom - i],
outline='white')
draw.rectangle(
[tuple(text_origin), tuple(text_origin + label_size)],
fill='white')
draw.text(text_origin, label, fill='black', font=font)
继续运行,发现可以画图了。至此这次复现yolov3算是结束了。
三、迁移学习,训练自己数据
本人训练的数据为神经元胞体数据,实现yolov3对胞体的检测,如下图,当然数据集你先要准备好,标签也要为.xml的文件:

3.1、制作训练集txt文件
第一步肯定还是制作train.txt文件,这是迁移学习最重要一步,也是唯一工作量大的一步。格式也肯定要按之前要求来,但是肯定已经不可以直接使用voc_annotation.py程序,你需要做一些修改,至于怎么修改我肯定不能直接给一个适合所有人的代码,这个需要你自己再原作者的代码基础上改就行,其实还是比较简单的(这里提示一下,主要就是先生成一个保存你所有训练集图片名,不带后缀的txt文件,然后通过image_ids参数调用所有图片名)
3.2、聚类生成自己数据anchors
这里你可以根据之前操作使用kmean.py生成自己数据集的anchors,当然你也可以使用作者提供的anchors做对比(本人发现自己数据集生成的anchors预测结果视乎反而变差了)。
3.3、使用train.py训练模型
当然这里你可以根据你自己数据集大小选择使用yolo还是tiny-yolo,或者你两个都是用做对比,本人所用的数据集含有三百来张图,实测发现tiny-yolo效果反而更好。
3.4、使用yolo_video.py做预测
这里跟之前介绍的方法一样,参照前面。
四、总结
总的一套下来,其实大致学会了怎样使用yolov3,但是如果你想做更多的创新改动那就需要你理解代码,本人也在学习当中,后续工作也是对模型进行更改,比如更改dark-net结构或者使用其他网络结构。希望上述分享对大家有所帮助。
reference
1、提高 Anaconda 安装 TensorFlow-gpu的速度:https://blog.csdn.net/atzhangzt/article/details/84578049
2、 anaconda查看删除增加镜像源:https://www.cnblogs.com/jeshy/p/10532983.html
3、Pascal voc 数据集下载网:https://blog.csdn.net/w782373711/article/details/88257152
4、Failed to get convolution algorithm. This is probably because cuDNN failed to initialize解决办法:https://blog.csdn.net/qq_41868689/article/details/98503069