-------------------------------------------------------------------------------------------------------------------------------------------------------------------
译文
摘要:在深度卷积网络(ConvNet)的帮助下,边缘检测已经取得了重大进展。基于ConvNet的边缘检测器在标准基准测试中达到了人类水平。我们提供了对于这些检测器输出的系统研究,且经研究表明它们没有准确定位边缘,这对于需要清晰的边缘输入的任务来说可能是背道而驰的。此外,我们提出了一种新颖的细化架构来解决使用ConvNet学习边缘检测器的挑战性问题。我们的方法利用自顶向下的向后细化路径,逐步增加特征映射的分辨率以生成清晰的边缘。我们的结果在BSDS500上取得了令人满意的性能表现,在使用标准规范( standard criteria)时超越了人类的识别准确性,并在使用更严格的标准时大大优于最先进的方法。我们进一步证明了清晰边缘映射对于估计光流,生成对象建议和语义分割是大有裨益的。另外,所提出的细化架构可以很容易地推广到显著性检测任务,在五个常用的显著性检测( saliency detection)基准上取得了最先进的实验结果。
关键词索引:边界检测、清晰边界
1 INTRODUCTION
边缘检测在计算机视觉中是一个成熟的问题。 在自然图像中发现感知显著的边缘对于中等视觉(任务)是重要的。 此外,在边界映射方面,边缘检测输出通常用于其他视觉任务,包括光流,对象建议和目标识别。 自从我们的团队采用基于学习的方法以来,我们已经看到了边缘检测方面的重大进展。 特别是,利用深度ConvNet检测边缘的全局边缘检测器(HED)等先进方法,在BSDS500等标准数据集上达到了人类水平。
那么边缘检测是一个已经解决了的问题吗? 在图1(a)中,我们展示了人类标记的边缘的可视化,与来自HED(当前现有技术水平)和PMI(用于精确地定位边缘的设计)的输出相比较。 虽然HED结果得分较高,但边缘图的质量不太令人满意——边缘模糊,并且不符合实际的图像边界。 精确的边缘检测器必须在边缘的“正确性”(区分边缘和非边缘像素)和边界的“清晰度”(精确地定位边缘像素)之间进行平衡。在基准期间匹配地面真实边缘时,我们可以通过降低最大允许距离来实现“清晰度”。 当我们缩小评估标准(最大允许距离从d减小到d / 4)时,HED与人类之间的F1分数差距增加,HED与PMI之间的差距减小(见图1(b))。

Fig. 1. (a) Visualization of edge maps from PMI and HED with input
images and ground-truth edges; (b) Performance (on the left image) drops
with decreased matching distance. With a tighter distance, the gap between
PMI and HED decreases and the gap between HED and human increases.
These results suggest that edges from HED are not well aligned with image
boundaries. We seek to improve the localization ability of ConvNet based
edge detector in this paper.
定性和定量结果都表明,来自ConvNet的边缘映射是高度“正确的”,而“清晰的”边缘映射则不是很好。这个问题深深扎根于现代ConvNet架构[11]。首先,由于连续的合并层,特征的空间分辨率在较高辨别性的顶层(Top Layers)中大大降低,导致边缘输出模糊。其次,由于大的感受域,完全卷积体系结构促使相邻像素的相似响应,因此可能无法产生一个“单薄”的边缘映射。这样一个厚而模糊的边缘图可能是其他视觉任务的阻碍[10]。例如,最近的光流方法[12],[3]需要准确和清晰的边缘输入来内插稀疏匹配结果,因此可能产生一个伴随模糊边界的次优性能。
我们解决了使用ConvNet学习边缘检测器的挑战性问题,并试图提高HED的定位能力。为此,受到最近在密集图像标记方面研究进展的启发[13],[14],我们提出了一种新颖的改进体系结构。我们的方法配备了一个清晰的边缘检测(CED)网络,具有自上而下的后向细化路径,它使用高效的子像素卷积逐步提高了特征映射的分辨率[14]。细化路径为网络增加了额外的非线性,进一步降低了相邻像素内的边缘响应之间的相关性。我们的方法在BSDS500上取得了令人满意的结果,在使用标准规范时超越了人类的表现,而且在使用更严格的评估标准时,在很大程度上超越了最先进的方法。更重要的是,由于骨干网络对深度学习方法至关重要,因此我们改进HED和CED以及最先进的主干网络[15]和所有边输出(side-output)的附加卷积层[16]。改进的CED在BSDS500上实现了最先进的实验效果。而且我们也深入了解了原有CED和CED的改进。
边界检测是其他更高级视觉任务的基础。 EpicFlow [3]是一种先进的光学流量估计方法,通过稀疏匹配执行边缘保持插值(edge-preserving interpolation)以实现精确的密集匹配。 一些对象建议生成方法还需要在对象边界周围进行精确的边缘预测,例如用预测的对象边界计算分层分割的MCG [4]。 作为基于标准FCN [17]语义分割方法的后处理步骤,BNF [18]计算精确的对象边界来优化由FCN产生的类似blob的( blob-like)和不好定位的预测。 通过三个对比实验(特别是对于我们的方法和原始HED之间的比较),我们展示了光流的边缘清晰度,对象建议和语义分割的好处。
最后,我们证明提出的网络可以很容易地扩展到其他相关的任务,如显著性检测[19]。 基于ConvNet的边界检测和显着区域检测方法均输出与原始图像具有相同分辨率的响应图。 并且响应图中的每个像素指示输入图像中对应像素的概率为对象的边界或属于显著区域。 因此,边界检测CED网络可以很容易地适用于显著的区域检测。 通过这种方式,我们在五个常用的显著性检测数据集上获得了最新的结果,表明了CED网络的一般性。
因此我们的贡献分为四部分:
1 我们提出了来自ConvNet的边缘映射的系统研究。我们证明ConvNet擅长对边缘像素进行分类,但是定位能力较差。
2 我们将细化方案[13]和子像素卷积[6]结合成一个新颖的架构,专门设计以用于学习清晰的边缘检测器。我们在BSDS500上的结果比所有匹配距离上的最先进的方法都要好。
3 我们证明,清晰边缘映射可以改善光流估计,对象建议生成和语义分割。
4 我们通过显著性检测任务来证明我们所提出网络的一般性。 在没有架构修改的情况下,在五个常用的显著性检测数据集上达到了最先进的结果。
我们组织我们的论文如下:
第二部分回顾了边缘检测的相关工作。
第三部分介绍了我们对ConvNet的边缘映射的研究。
第四部分详细介绍我们的方法。
第五部分展示了边界检测的实验结果。
第六节展示了清晰界限带来的好处。
最后,第七节说明了我们提出的网络显著性检测的一般性。
注:当下,由于课题研究需要,接下来,只翻译学习本文的第三部分、第四部分、第六部分、第七部分
3 来自于ConvNet的薄边缘(标题翻译得不好)
我们首先研究HED的输出边缘映射[7],最近一个成功的边缘检测器使用ConvNet。 HED预测网络不同层的边缘置信度,从而得到一组边缘映射。 这些映射由于网络中的连续池化操作而被下采样。 然后,进一步通过双线性插值对其进行上采样以适应输入分辨率,并对其进行平均以产生最终的边缘映射。在图2(a)中我们展示了边缘映射的一个例子。 尽管检测器在BSDS上实现了0.78的ODS,但边缘图的视觉质量并不令人满意。 边缘看起来模糊,视觉上有缺陷。

Fig. 2. (a) Thick and noisy edge map generated with HED [7] before non-
maximal suppression(NMS); (b) Optimal Dataset Score (ODS) for both HED
and human drop with decreased matching distance on the BSDS500 test set.
However, the performance gap between HED and human increases from 2.3%
to 4.7% as the distance decreases from d to d/4.
为什么这样一个模糊的边缘映射在基准测试中达到了高分? 标准评估[9]遍历所有置信度阈值,并使用双向图匹配在二值化边缘映射与Ground-truth边缘之间进行匹配。 匹配由最大允许距离d控制。 只要与最近的Ground-truth之间的距离小于d像素,错位的边缘像素仍然被认为是正确的。 通过一个正确的d,即使边缘稍微偏移,我们也可以获得较好的分数。
实际上,边缘检测必须在边缘的“正确性”(边缘和非边缘像素之间的区分)和边界的“清晰度”(精确定位边缘像素)之间进行平衡[10]。清晰的边缘对于其他视觉任务(如光流或图像分割)可能是至关重要的。可以通过减小基准中的d来测量“清晰度”。 如图2(b)所示,人的表现随着d的减小而逐渐减弱。然而,HED输出显示更大的性能下降,表明HED边缘与实际图像边界不一致。这符合我们对边缘图的视觉检查。
4 使卷积边界清晰
如何从ConvNet出发完成一个清晰的边缘映射呢?我们从分析HED的体系结构开始。 像现代的ConvNets一样,由于连续的池化操作,更具有辨别力的顶层空间的分辨率显著降低。 HED进一步在不同分辨率的图层上附加一个线性分类器,并使用双线性插值(实现为反卷积)将其输出上采样到原始分辨率。 这个设计有两个主要问题。 首先,完全卷积体系结构内的线性分类器在相邻像素处产生相似的响应,这使得在相邻像素区域很难产生一个边缘出来。更重要的是,简单的上采样不能恢复原始的空间细节,并且进一步模糊了边缘映射。
因此,生成清晰的边缘映射需要修改架构。 在本节中,我们通过提出一种新颖的架构来解决设计一个边缘检测器(CED)的挑战性问题。 我们的方法补充了HED网络的后向细化路径,它使用高效的子像素卷积逐步向上采样特征[14]。 CED能够生成更好地与图像边界对齐的边缘映射。我们将介绍CED的细节并解释我们的设计选择。
A 架构概述
图4显示了CED的两个主要组成部分:前向传播途径和后向细化(改善)途径。 向前传播途径类似于HED。 它生成具有丰富语义信息的高维低分辨率特征图。 后向细化路径将沿着向前传播路径的特征图与中间特征进行融合。 这个细化是通过细化模块多次完成的。 每次我们使用子像素卷积将特征分辨率提高一个小的因子(2x),最终达到输入分辨率。 网络细节在下面小节中详细说明。

Fig. 4. Our method of Crisp Edge Detector (CED). We add a backward-refining pathway, which progressively increase the resolution of feature maps. Our
refinement module fuses a top-down feature map with feature maps on the forward pass, and up-samples the map using sub-pixel convolution. This architecture
is specially designed for generating edge maps that are well-aligned to image boundaries.
B 细化模型
跳层连接为HED提供了使用不同层上的特征来查找边缘的重要能力[7]。
图3显示了来自所有侧输出层和最终输出边缘映射(HED-fuse)的示例边缘映射预测。较低层(HED-dsn1,HED-dsn2,HED-dsn3)捕获更多的空间细节,同时缺乏足够的语义信息。 相反,更深的层次(HED-dsn4,HED-dsn5)编码更丰富的语义信息,但空间细节丢失。HED简单地平均来自所有边输出层的独立预测。我们认为这不是一个好的设计,因为它没有探索ConvNet的层次特征表示。为了更好地融合多层特征,我们引入了精化模块的后向细化路径,类似于[13]。请注意,我们的检测稀疏边的任务与[13]中的分割对象明显不同。因此,直接应用[13]中的相同模块导致次优性能。
细化模块重复几次,以提高特征图的分辨率。关键的想法是使用中间特征映射聚集通过路径边缘的证据(evidence)。模块的详细结构在第4部分(即本部分)的最后给出。每个模块将来自后向路径的自上而下的特征图与来自前向路径中的当前层的特征图相融合,并且进一步通过小的因子 (2x)进行上采样,然后通过路径。 该模块有两个核心组件,即融合和上采样。
融合:一个简单的融合策略是直接连接两个特征图。 然而,这是存在问题的,因为它们的特征通道数不同。 直接连接这些特征会存在淹没(drown)低维信号的风险。 类似于[13],我们通过降维来匹配两幅特征图之间的特征通道的数量。 这是通过附加的卷积层减少两个特征映射的维度来完成的。 然后我们将这两个低维特征映射与相同的通道连接起来。
我们用kh表示输入前向通道特征映射的通道数。经过卷积和ReLU操作后,通道数减少至k’h,远远少于kh。对先前细化模块的特征映射进行相同的操作,以从ku生成k’u。我们将上述功能图连接成一个新功能映射到k’u+k’h个通道,并通过3×3的卷积层将其减少到k’d个通道的特征映射。因此,整体计算成本降低,并且两个输入特征图是平衡的。
上采样:融合后,我们的精化模块也将提高功能图的分辨率。我们用一个子像素卷积来对融合的特征图进行上取样[36]。子像素卷积与上采样[37,38,39]的流行反卷积不同,是标准卷积,随后是特征值的附加重新排列,称为相移。 它有助于消除图像超分辨率任务中的块伪影( block artifact ),并保持较低的计算成本。 我们发现使用子像素卷积对于更好的边缘定位是重要的。
假设我们有输入通道i和期望的输出通道o,卷积层的内核大小表示为(o,i,r,c),其中r和c分别表示内核宽度和内核高度。考虑到输出特征图的分辨率比输入分辨率大k倍,传统的反卷积层将采用的内核大小为(o,i,k×r,k×c)。子像素卷积不是通过单个反卷积层直接输出放大的特征映射,而是由一个卷积层和一个跟随的相移层组成。 卷积层的核大小为(o×k2,i,r,c),从而生成具有相同分辨率的o×k2个特征通道的特征映射。 然后,我们应用相移将输出特征映射组合成具有o个特征通道的特征映射,但以固定顺序将分辨率提高k倍。
Relationship to [7] and [13]:CED包含HED [7],是个特殊情况,其中3x3卷积和ReLU被线性分类器替代,并且使用渐进式上采样。我们的方法与[13]不同,因为我们用子像素卷积来代替双线性插值。这使得生成一个具有少量额外参数的更具表现力的模型成为可能。我们的边缘检测任务也不同于[13]中的对象分割。
C 实现细节
我们的实验基于开源的HED代码[7],使用Caffe[40]。 对于训练,我们用预训练的HED模型初始化前向传播路径。其他层用高斯随机分布进行初始化,固定均值(0.0)和方差(0.01)。包括初始学习率,权重衰减和动量在内的超参数分别设置为1e - 5,2e - 4和0.99。
对于后向精细化路径,顶层的卷积核的数量被设置为256。 这个数字在路径上减半。 例如,第一,第二和第三自上而下细化模块将分别具有128,64和32个特征通道。 由于特征映射的分辨率在每次合并操作之后都减小了2倍,因此子像素卷积在每个细化模块中将输入特征映射上采样2x。
6 清晰边界所带来的好处(只翻译学习与我研究内容相关的D部分)
如论文第一部分所述,边界检测对于一些较高级别的视觉任务是至关重要的。我们通过实验来展示清晰边界对于其他相关任务的的好处。我们把我们的方法插入光流估计,对象建议生成和语义分割,并评估其对每个任务的好处。
D 语义分割与清晰边界
我们还展示了语义分割中应用清晰边界所带来的好处。语义分割是一个重要的高级视觉任务,旨在从预定义的一组类别中进行密集的像素级分类。在完全卷积网络(FCNs)的帮助下,语义分割得到了快速发展[17]。然而,正如文献[18]中所讨论的,由于卷积层的大接受区域和连续下采样层的分辨率大大降低,基于FCN的方法产生的分段是斑点状的(blob-like),并且在物体边界周围效果很差。引入了一些后处理程序来缓解这个问题。而不是像[51]中所述使用颜色亲和函数,[18]提出了边界神经场(BNF),其特点是基于边界的像素亲和函数以及全局优化策略。BNF用输入边缘映射计算两个像素之间的亲和力,越过两个像素之间的直线路径的边界的幅度值越大,两个像素之间的亲和性越低。因此,更清晰的边界促进更精确的像素亲和度估计。原始的BNF采用在FCN内部用插值卷积特征映射的线性组合生成的边缘映射。我们简单地用HED和CED结果代替它。同样,HED和CED都只在BSDS500数据集上训练。我们选择Deeplab [51]作为最终的后处理步骤来生成初始分割结果和具有不同边缘检测器的BNF。
我们在Pascal上下文测试集上报告像素精度(PA),平均像素精度(MPA)和均值交叉点(平均IOU),如表五所示.HED和CED都在Pascal上下文训练集上重新训练。最初的Deeplab平均IOU为42.6%,经过HED和CED生成的边缘图BNF后处理程序的评估结果都得到了改善。CED-BNF在所有三个评估指标上都取得了最好的结果。图11显示了Deeplab的初始语义分割结果,带有HED和CED的边缘映射,HED-BNF和CED-BNF的后处理语义分割结果。清晰锐利的边界(CED边缘),CED-BNF可以沿着物体轮廓更多细节地改善初始分割结果。这些结果证明了语义分割的清晰界限的好处。
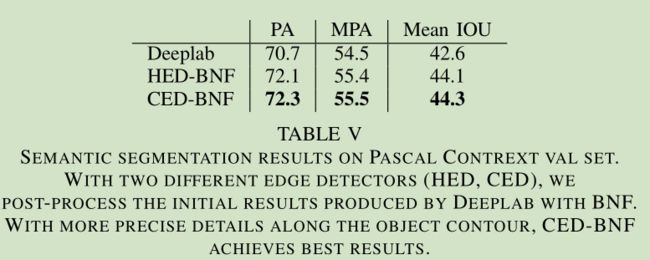

Fig. 11. Sample semantic segmentation results on Pascal Context val set. With
two different edge detectors (HED, CED), we post-process the initial results
produced by Deeplab with BNF. With sharp and clean edge maps (CED edge),
CED-BNF achieves better segmentation results, and captures more precise
details along object contour.
7 CED用于显著性检测
在本节中,我们证明与CED相同的体系结构可以在显着性检测任务上达到最先进的实验结果。视觉显著性检测是一项重要且基本的任务,旨在检测图像中最明显的对象或区域。许多计算机视觉任务需要显著性检测结果以用于以后的处理,如图像检索[54]和图像分割[55]。传统的显著性检测方法依赖于低级特征[56]或高级信息[57]。基于ConvNet的方法不是使用这些人为制作的特征,而是基于补丁或像素级的方式,大大超越了传统的方法[19]。
同边界检测,显著性检测可以被处理为像素级显著性估计任务。两个任务都生成密集的像素级响应图,每个像素指示对应像素属于显著区域或对象边界的概率。因此,即使没有网络架构修改,HED和CED网络也可以很容易地推广到视觉显著性检测任务。
A 数据集和评估指标
跟随文章[16],我们在5个广泛使用的基准数据集上评估HED和CED:MSRA-B [56],ECSSD [59],HKU-IS [58],PASCAL-S [60]和SOD [61] 62。MSRA-B包含5000个图像,主要是一个显著的对象。数据集分为训练集,验证集和测试集,分别包含2,500,500,2,000个图像。该数据集是从“人”,“马”,“花”等数百个常见类别中收集而来的。ECSSD由具有复杂背景的1,000幅具有挑战性的图像组成。HKU-IS是一个新的大型和具有挑战性的数据集,创建了4447个自然图像。与MSRA-B数据集不同,MSRA-B数据集通常包含位于图像中心的单个显着对象,HKU-IS数据集中的图像更可能包含具有不同位置的多个显着对象。PASCAL-S数据集建立在PASCAL VOC [49] 2010分割挑战的验证集之上,包含850个具有杂乱背景的具有挑战性的图像。基于Berkeley分割数据集(BSD)[2],[9]构建的SOD由300个具有多个复杂显着对象的图像组成。为了与现有方法保持一致[16,63],我们只对MSRA-B训练集和由3000幅图像构成的验证集训练HED和CED,并对MSRA-B测试集上训练好的模型进行评估。也在其他四个数据集进行同样的评估。
使用两个标准评估指标,F-measure(Fβ)和平均绝对误差(MAE)来评估HED和CED。对于给定的连续显著图,我们可以使用阈值将其转换为二进制掩码。F-measure表示显著性检测结果的综合性能,考虑到精度和召回率。精度是指正确预测的显著像素的百分比,召回对应于预测显著像素与Ground-truth显著像素的比例。如[64]所述,F-measure是一种基于重叠的评估方法,它忽略了正确标记为非显著性的像素。此外,在某些应用中,加权连续显著图比二元掩模(用于F-measure)更重要[65]。 应该采用更全面的评估指标。 MAE计算Ground-truth注释和预测的显著图之间的平均逐像素差异。
B Ablation Study
注:这里先科普一下何为“Ablation Study”?
ablation study就是为了研究模型中所提出的一些结构是否有效而设计的实验。比如你提出了某某结构,但是要想确定这个结构是否有利于最终的效果,那就要将去掉该结构的网络与加上该结构的网络所得到的结果进行对比,这就是ablation study。
说白了,ablation study就是一个模型简化测试,看看取消掉模块后性能有没有影响。根据奥卡姆剃刀法则,简单和复杂的方法能够达到一样的效果,那么简单的方法更好更可靠。
Quora.com上的解释是:
Examples:
- An LSTM has 4 gates: feature, input, output, forget. We might ask: are all 4 necessary? What if I remove one? Indeed, lots of experimentation has gone into LSTM variants, the GRU being a notable example (which is simpler).
- If certain tricks are used to get an algorithm to work, it’s useful to know whether the algorithm is robust to removing these tricks. For example, DeepMind’s original DQN paper reports using (1) only periodically updating the reference network and (2) using a replay buffer rather than updating online. It’s very useful for the research community to know that both these tricks are necessary, in order to build on top of these results.
- If an algorithm is a modification of a previous work, and has multiple differences, researchers want to know what the key difference is.
- Simpler is better (inductive prior towards simpler model classes). If you can get the same performance with two models, prefer the simpler one.
为了进行消融分析,我们首先在PASCAL-S上测试HED和CED。并且注意,在我们的实验中没有采用后处理步骤,例如基于条件随机场(CRF [67])的平滑方法。如表七所示,HED达到了0.801的F值,而CED则提升了0.7%。这证明了CED对显著性检测的有效性。然后我们用V-D中提到的Improved-HED和Improved-CED进行实验。除基于ResNet50的改进型HED和改进型CED外,我们还分别用VGG16-Improved-HED和VGG16-Improved-CED取代了骨干网络。 改良型的VGG16HED的F值为0.822,比vanilla HED高出2.1%。VGG16-Improved-CED进一步提高了VGG16改进型HED的0.9%,甚至在没有任何后处理步骤的情况下表现优于大多数现有技术。当用ResNet50作为骨干网络时,Improved-HED和Improved-CED都取得了较好的性能,其中F-measure分别为0.826和0.846。并且注意到,由于我们在多尺度评估策略中没有获得收益,所以我们在测试阶段用单尺度图像进行评估。此外,如图12所示,与Improved-HED(第四列)相比,Improved-CED(第三列)产生了更精确的显着图,并且明显地显示了显着区域和背景之间的更高对比度。定量和定性结果都表明CED网络对HED的优越性能。


C 与先进方法的比较
我们将性能最好的改进型CED与现有的基于ConvNet的6种方法(包括MDF [58],DCL [66],ELD [68],MC [69],DHS [19]和DSC [16] 2个经典方法,GC [70]和DRFI [63]进行比较。我们将我们的方法与以前的方法在F-measure和MAE分数方面进行了比较。详细的结果列于表六。没有复杂的基于CRF的后处理步骤,Improved-CED已经达到了最新的结果。经过基于CRF的后处理[16],[66],改进的CED-CRF得到了更好的结果。图12提供了我们的方法与以前的方法的视觉比较。改进CED捕捉到了更完整的显著性细节,特别是沿着对象的边界。

终于完了。。。。。。,由于要做弱监督学习框架下的图像语义分割,用到显著性检测这一模块,这篇文章是3天前发布在arxiv上面的,不错的一篇文章,仔细翻译了几个小时,希望能够对感兴趣的同领域的朋友有些微帮助。我的研究生课题是以前从未涉足过的,其实我还处于也当然处于摸着石头过河的初级阶段,不明朗,踌躇而彷徨。但我有勇气有信心我会成功到达彼岸。最后,文艺的我还是附上一句小诗以激励自己与各位同仁:千淘万漉虽辛苦,吹尽狂沙始到金。总会守得云开见月明!