python绘图(子图、Loss+标准差、坐标轴缩放、美化格式)
文章目录
- 一、Loss曲线(+子图)
- 二、Loss曲线对比+标准差范围
- 三、缩放x/y轴,坐标间等距,数值不等距
-
- 1、需求和原理说明
- 2、完整代码
- 3、子步骤
- 4、问题
- 四、图像美化
- 五、参数设置
- 六、问题
-
- 1、子图+缩放+美化
一、Loss曲线(+子图)
import os
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1.inset_locator import inset_axes
# 读取数据
# data1 = pd.read_csv('./1.csv',index_col=0)
# 或自动获取文件夹下的所有数据
path = r"data\\"
file = os.listdir(path)
fig = plt.figure(figsize = (7,5)) #figsize是图片的大小
# g = green,“-” = 实线,label = 图例的名称,一般要在名称前面加一个u
## 子图设置
ax1 = fig.add_subplot(1, 1, 1) # 子图
rect1 = [0.6, 0.25, 0.35, 0.35] # 子图位置,[左, 下, 宽, 高] 规定的矩形区域 (全部是0~1之间的数,表示比例)
axins = ax1.inset_axes(rect1)
# 设置想放大区域的横坐标范围
tx0 = 0
tx1 = 150
# 设置想放大区域的纵坐标范围
ty0 = 1000
ty1 = 2500
sx = [tx0,tx1,tx1,tx0,tx0]
sy = [ty0,ty0,ty1,ty1,ty0]
plt.plot(sx,sy,"purple")
axins.axis([tx0,tx1,ty0,ty1]) # 坐标范围
lab = ['1','2','3','4']
color = ['g','b','r']
for i in range(0,len(file)-1):
data_csv=file[i]
data = pd.read_csv(path+data_csv,index_col=0)
# 横坐标Episode,纵坐标Loss
x = data['Episodes']
y = data['Loss']
# 整体loss曲线
plt.plot(x, y, color[i],label =lab[i])
# 局部loss曲线
axins.plot(x, y,color[i])
# 最后一个数据的后半截用虚线展示
data_csv = file[len(file)-1]
data = pd.read_csv(path+data_csv,index_col=0)
x_s = data[data['Episodes'] <= 100]['Episodes']
y_s = data[data['Episodes'] <= 100]['Loss']
x_x = data[data['Episodes'] > 100]['Episodes']
y_x = data[data['Episodes'] > 100]['Loss']
plt.plot(x_s, y_s,'y-', label =lab[len(file)-1])
plt.plot(x_x, y_x,'y--') # 对于虚实要统一颜色,均设为y
axins.plot(x_s, y_s,'y-')
axins.plot(x_x, y_x,'y--')
plt.legend() # 显示
# 坐标/标题设置
plt.xlabel(u'iters')
plt.ylabel(u'loss')
plt.title('Compare loss for different models in training')
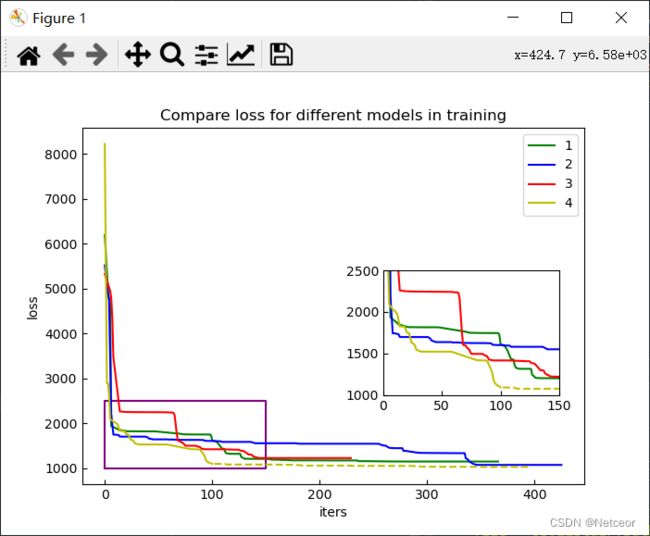
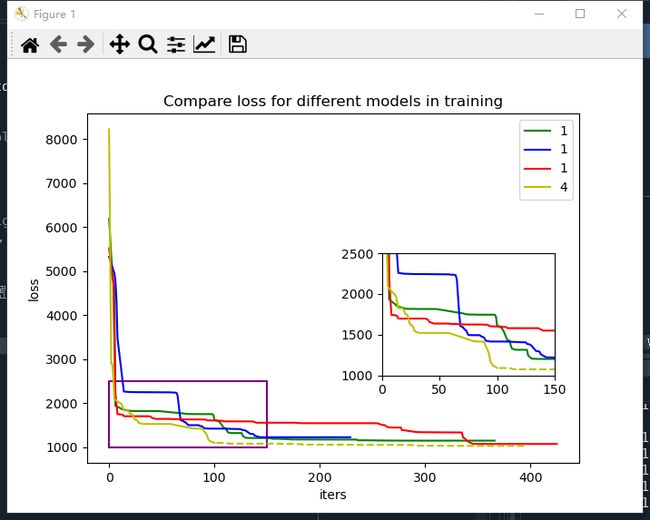
参考链接
如何通过python画loss曲线的方法
二、Loss曲线对比+标准差范围
import os
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 读取文件名
our = 'our'
path_stand = r"F:\temp\data\standard\\"
file_stand = os.listdir(path_stand)
path_our = r'F:\temp\data\our\\'
file_our = os.listdir(path_our)
# diff和our各iter的数据
# 迭代500次,每次5组数据
iter_num=500
N = 5
loss_stand=[]
loss_our=[]
for i in file_stand:
data = pd.read_csv(path_stand+i,index_col=0)
loss_stand.append(data['Loss'].tolist())
for i in file_our:
data = pd.read_csv(path_our+i,index_col=0)
loss_our.append(data['Loss'].tolist())
fig = plt.figure(figsize = (7,5)) #figsize是图片的大小
# stand求mean和std
loss_mean=[]
loss_var=[]
for i in range(iter_num):
loss_cur = [loss_stand[j][i] for j in range(N)]
loss_mean.append(sum(loss_cur)/len(loss_cur))
loss_var.append(np.std(loss_cur,ddof=1))
# 绘制stand的图像
iters=range(0,iter_num)
plt.plot(iters, loss_mean,'b-', label = u'diffhand')
np1=np.array(loss_mean)
np2=np.array(loss_var)
plt.fill_between(iters, np1 + np2, np1 - np2,'b',alpha=0.3,zorder=3)
# our求mean和std
loss_mean=[]
loss_var=[]
for i in range(iter_num):
loss_cur = [loss_our[j][i] for j in range(N)]
loss_mean.append(sum(loss_cur)/len(loss_cur))
loss_var.append(np.std(loss_cur,ddof=1))
iters=range(0,iter_num)
# # 绘制our的图像
plt.plot(iters, loss_mean,'r-', label = our)
np1=np.array(loss_mean)
np2=np.array(loss_var)
plt.fill_between(iters, np1 + np2, np1 - np2,'r',alpha=0.3,zorder=3)
plt.legend()
plt.title('Compare loss for different models in training')
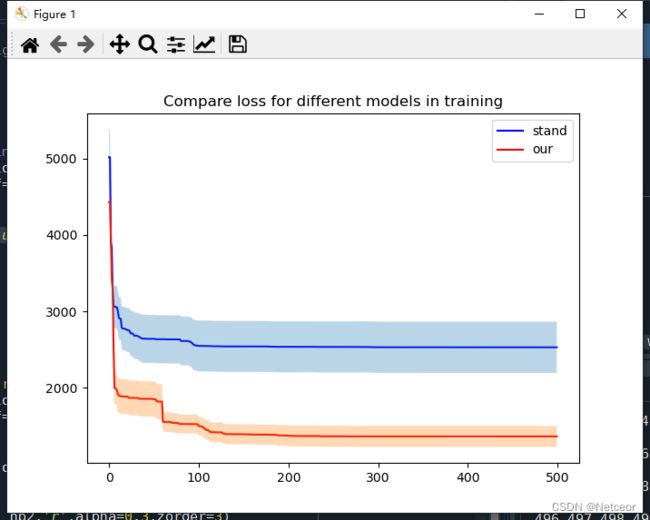
三、缩放x/y轴,坐标间等距,数值不等距
1、需求和原理说明
假设y的数据是在4000-10000之间,但是6000-10000的数据非常少,希望等距刻度显示的范围分别是4000-5000,5000-6000,6000-10000。这样可以间接放大4000-6000之间的波动
理解这个博客中的内容,python画图,等间距坐标距离,不等间距数据值
其实核心原理就是要把6000-10000的数据归一化到6000-7000之间,让数据均匀地按照1000的间距分布。
此时,数据可以均匀显示在图像上。此后,修改坐标轴的刻度显示,虽然数据实际上已经归一化到6000-7000之间,但是让坐标轴上的文字分别显示 “6000”、“10000”。
所以主要有以下几个步骤:
- 定义上下界 up=10000,under=6000。[under,up]间的数据归一化到6000-7000
- 设置坐标按1000的间距输出数据
- 设置坐标的文字为实际数值
先贴完整代码,第二小板块是分开的步骤,便于理解。x轴和y轴的处理是同理的。
2、完整代码
这里舍去了导入数据 y 的过程,就自己弄数据就好。
import matplotlib.pyplot as plt
import numpy as np
# 原始代码
fig = plt.figure(figsize = (7,5))
x=np.array(range(0,len(y)))
plt.plot(x, y) # 实线
修改后代码
import os
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 数据缩放
space = 1000 # 间距
mini = 4000 #坐标轴下界
under = 6000 # 缩放下界
up = 10000 # 缩放上界
y=np.array(y) # 转array
index = np.where(y[y>under])
y[index]=(y[index]-under)/(up-under)*space+under # 归一化到[under,under+space]
y=y.tolist() # 转回list
num = (under-mini)/space
# 假坐标
# y_index = [4000, 5000, 6000, 7000] # 自己定义
y_index = [mini+i*space for i in range(int(num+2))] # 自动
# 真坐标
# y_index2=['4000','5000','6000','10000'] # 自己定义
y_index2 = []
for i in range(len(y_index)-1):
y_index2.append(str(y_index[i]))
y_index2.append(str(up)) # 最后一个显示真坐标 up
# 绘图
fig = plt.figure(figsize = (7,5))
x=np.array(range(0,len(y)))
plt.plot(x, y) # 实线
plt.yticks(y_index,y_index2) # 假坐标和显示的真坐标
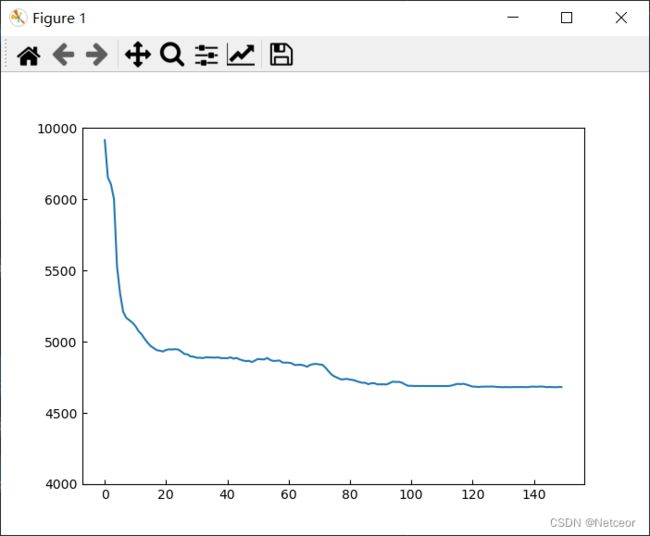
原图

新图
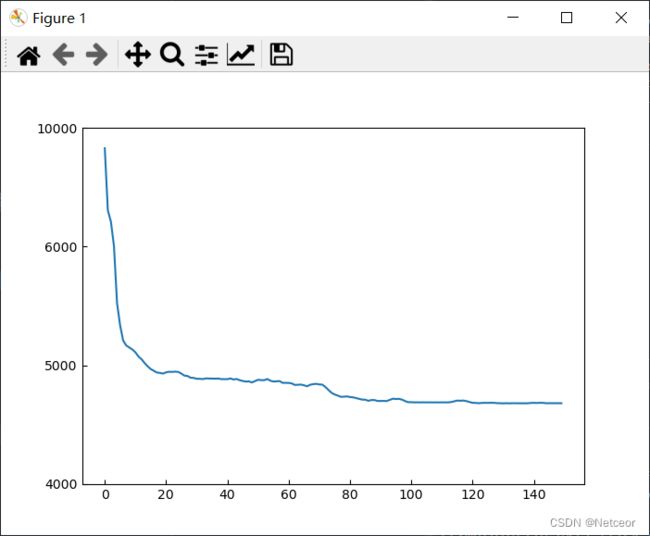
可以看到上面被压缩了,下面的波动被放大了。4000-6000之间以1000为间距,剩余的刻度等距,但表示了4000的数据
如果想让刻度更密集一点,可以修改间距space或者自定义真假坐标,以500为间距,使其更紧密一点
space = 500
# 或修改真假坐标
# y_index = [4000, 4500, 5000, 5500, 6000, 6500]
# y_index2 = ['4000', '4500', '5000', '5500', '6000', '10000']
3、子步骤
- (1)数据缩放
这里的y数据是一个list,所以转一下array再更新
# 数据缩放
space = 1000 # 间距
under = 6000 # 下界
up = 10000 # 上界
y=np.array(y) # 转array
index = np.where(y[y>under])
y[index]=(y[index]-under)/(up-under)*space+under # 归一化到[under,under+space]
y=y.tolist() # 转回list
- (2)设置假坐标【等距】
y_index = [4000+i*space for i in range(7)] # [4000, 5000, 6000, 7000]
- (3)设置实际数值【不等距】
y_index2=['4000','5000','6000','10000']
- (4)绘图
fig = plt.figure(figsize = (7,5))
x=np.array(range(0,len(y)))
plt.plot(x, y) # 实线
plt.yticks(y_index,y_index2)
4、问题
这里有一个坑就是一定要把plt.yticks(y_index,y_index2) 代码写在plt.plot(x, y)的后面,不然可能会刻度显示异常
其它参考链接
python X/Y轴缩放
在数据采样不均匀的情况下,如何使yscale均匀地显示图像?
四、图像美化
- 原始代码和图像
import os
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据
path = r"data\\"
file = os.listdir(path)
#设置图片的大小
figsize=7,5
fig, ax = plt.subplots(figsize=figsize) # axes
lab = ['1','2','3','4']
colors = ['#D62627','#1D76B3','#FF8113','#2A9F2A']
for i in range(0,len(file)):
data_csv=file[i]
data = pd.read_csv(path+data_csv,index_col=0)
# 横坐标Episode,纵坐标Loss
x = data['Episodes']
y = data['Loss']
# 整体loss曲线
plt.plot(x, y, colors[i],label =lab[i])
plt.legend()
plt.xlabel("Episode")
plt.ylabel("Loss")
plt.title('Compare loss for different models in training') # 图片标题

- 改进代码
将最后四行更换为如下代码
# 图像设置
plt.rcParams['xtick.direction'] = 'in' ####坐标轴刻度朝内
plt.rcParams['ytick.direction'] = 'in' ####坐标轴刻度朝内
ax.tick_params(which='major',axis='x',length =8,width=1) #,top=True
ax.tick_params(which='major',axis='y',length =8,width=1)#,right=True
ax.tick_params(which='minor',axis='x',length =4,width=1) #,top=True
ax.tick_params(which='minor',axis='y',length =4,width=1) #,right=True
ax.spines['bottom'].set_linewidth(1);###设置底部坐标轴的粗细
ax.spines['left'].set_linewidth(1);####设置左边坐标轴的粗细
ax.spines['right'].set_linewidth(1);###设置右边坐标轴的粗细
ax.spines['top'].set_linewidth(1);####设置上部坐标轴的粗细
ax.yaxis.grid(True,which='major',linestyle='--',c='grey')
labels = ax.get_xticklabels() + ax.get_yticklabels()
[label.set_fontname('Times New Roman') for label in labels]
#设置横纵坐标的名称以及对应字体格式
font2 = {'family' : 'Times New Roman','weight' : 'normal','size' : 16,}
font3 = {'family' : 'Times New Roman','weight' : 'normal','size' : 13,}
# 坐标/标题设置
plt.legend(prop=font3)
plt.xlabel("Episode",font2)
plt.ylabel("Loss",font2)
plt.title('Compare loss for different models in training',font2) # 图片标题
# plt.savefig("flip_loss_cmopare.jpg", dpi=300)
plt.show()
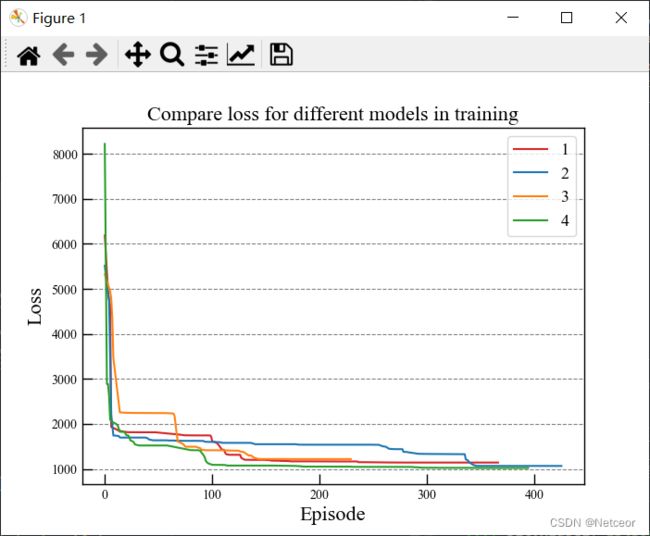
修改了字体,添加了网格,变得美观了一些
五、参数设置
- 关于颜色
颜色设置:分享python中matplotlib指定绘图颜色的八种方式
颜色表:python常用画图颜色
- 关于子图
子图位置:如何在matplotlib中设置inset_axes位置
六、问题
1、子图+缩放+美化
如果是子图 + 缩放 + 美化,需要注意的是如以下代码中
# 大图plt和ax
figsize = 7,5
figure, ax = plt.subplots(figsize=figsize)
# 子图axins
rect1 = [0.6, 0.35, 0.35, 0.3]
axins = ax.inset_axes(rect1)
此处 ax 是大图的Axes,axins是小子图的 axins。如果想调整各自的格式,可能会存在不同的调用方式【持续更新】
# 处理ax/plt——大图
plt.yticks(y_index,y_index2)
plt.plot(x,y)
# 处理axins——小子图
axins.set_yticks(y1_index,y2_index)
axins.plot(x,y)
各种区别说明参考他人博客【Python画图】Matplotlib中fig、ax、plt的区别及其用法(入门)