Saleforce发布跨模态框架LAVIS,涵盖数据、任务、模型

作者 | HJZ
来源 | 机器之心
Salesforce 亚洲研究院推出了一站式视觉语言开源框架 LAVIS。
视觉语言模型在内容推荐、电子商务里有广泛应用,例如图像描述生成、文本图像检索以及多模态内容分类。依托于海量互联网数据,多模型模型近期得到长足发展,其性能在下游任务上得到了广泛的验证。
尽管如此,现阶段的视觉语言方向的发展也存在其局限性。例如,由于语言视觉任务的多样性和复杂性,特别是对于初学者或者其他领域的工程研究人员,训练和评估现有视觉语言模型并不容易, 其较陡的学习曲线让很多新接触视觉语言方向的人望而却步。究其原因,这些障碍主要是模型、数据集和任务评估的接口不一致所致。另外,视觉语言预训练微调实验所需的实验环境搭建相对比较繁复,例如下载组织各个任务数据集、实验环境搭建等环节,不利于快速方法迭代,也容易产生疏漏。
现存的视觉语言框架往往只支持较少一部分任务和数据集,模型往往也不够新。例如,MMF 主要支持性能较弱的下游任务微调模型;X-modaler 支持非常有限的任务和数据集,对预训练模型的支持也不足。另外一些工作例如 torchmultimodal 和 unilm 尚在开发初期,不支持开源训练或推理。此外,这些库的接口设计并不统一,不利于访问数据集或是模型,这为想要利用视觉语言模型能力的用户提供了诸多不便。最后,这些库中的大多数不提供微调的模型检查点或基准测试结果。这对复现模型性能制造了额外的困难。
为了使得更广泛的工程研究人员更好地利用视觉语言多模态模型能力,推动其在生产场景里的应用,以及减少重复开发的负担,Salesforce 亚洲研究院推出了开源框架 LAVIS (LAnguage-VISion 的简称)。

Github 仓库:
https://github.com/salesforce/LAVIS
技术报告:
https://arxiv.org/abs/2209.09019
支持文档:
https://opensource.salesforce.com/LAVIS//latest/index.html
官方博客:
https://blog.salesforceairesearch.com/lavis-language-vision-library/
LAVIS 框架全方位支持 10+ 视觉语言任务,20+ 数据集,并提供 SOTA 模型性能和可复现预训练及微调实验配置。LAVIS 一大特点是统一和模块化的接口设计,极大降低训练、推理和开发的难度,致力于让研究和工程人员快速利用到近期多模态发展成果。
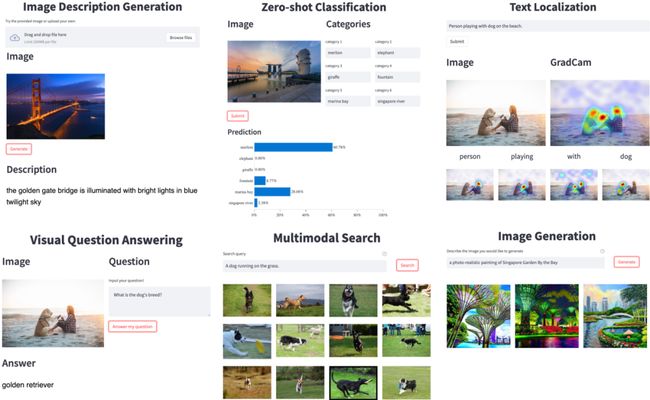 ▲图 1: 随 LAVIS 一起开源的 GUI demo,展示丰富的视觉语言应用场景。
▲图 1: 随 LAVIS 一起开源的 GUI demo,展示丰富的视觉语言应用场景。
LAVIS: 一站式视觉语言框架,任务数据集模型全方位支持
LAVIS 最大的特点是提供统一模块化接口,极大简化模型训练评测,实现模型和数据集开箱即用,并且最小化重复开发成本。LAVIS 力求为工程研究人员提供一站式视觉语言方案,助力视觉语言社区发展,从而扩大多模态模型研究的实际影响力。
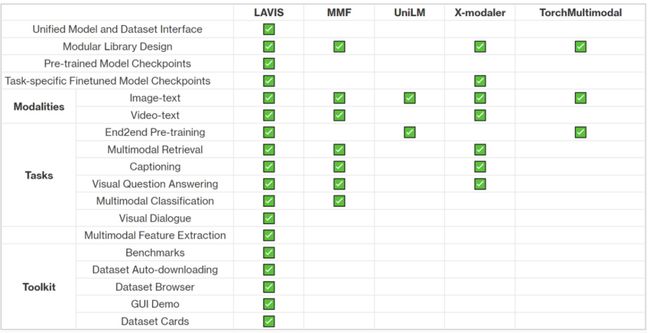
LAVIS 是当前对视觉语言方向支持最全面的开源框架,其包含超过 10 种视觉语言任务,包括图片描述生成(image captioning)、 图像文本检索 (image-text retrieval)、视频文本检索 (video-text retrieval)、图像问答 (visual question answering)、视频问答 (video question answering)、多模态分类、多模态图像、视频对话、视觉语言推理、多模态预训练等实用任务,和多模态特征提取等功能;20 余标准数据集及评测结果,包括 COCO, Visual Genome, Flickr30k, NoCaps, NLVR, OK-VQA, A-OKVQA, MSRVTT, MSVD, DiDeMo, SBU, Conceptual Captions 等;以及 SOTA 的预训练和微调模型,开箱即用。上图展示了 LAVIS 和现有的多模态库的对比,突出 LAVIS 对视觉语言任务、数据集、模型的全方位支持。
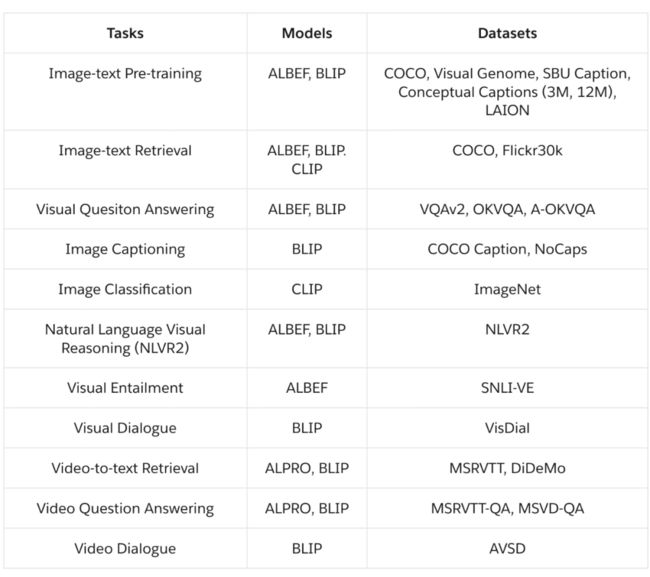
LAVIS 主要支持四种领先的基础视觉语言模型架构,包括 ALBEF (NeurIPS 21’ Spotlight)、BLIP(ICML 22’)、CLIP 和 ALPRO(CVPR 22’)。其中 ALBEF,CLIP 主要支持图像文本任务,ALPRO 支持视频文本任务,BLIP 对图像文本、视频文本任务均提供支持。各个模型对任务和数据集支持的详细信息见下表。
统一模块化接口设计,一键模型数据加载,轻松拓展定制
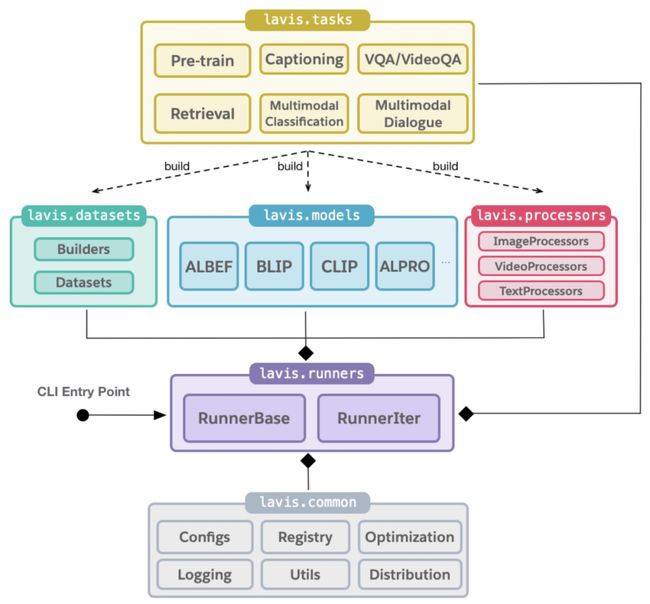
LAVIS 的最大特点是提供了简单且统一的接口以训练评测模型、加载模型数据,以及便于未来拓展新的任务、数据集、模型。例如,用户可以利用 LAVIS 提供的 load_model(), load_dataset() 一键加载所需模型和数据集。下图描述了 LAVIS 模块之间的依赖关系。更多模型数据集加载实例可见于官方文档。此外,LAVIS 可以实现数据到训练高定制化,给予开发者充分空间研究新模型、新多模态能力、新引用场景。
丰富的配套资源工具
除了框架本身,LAVIS 还附带了丰富的开源资源和工具。包括模型预训练和在下游任务上微调的 checkpoint、用于可视化的图形界面 GUI Demo (图 1)、以及一键式下载公开数据集的脚本工具,全方位促进视觉语言方案复现、研发周期和成本。
LAVIS 将持续更新维护,在未来会支持更多更强大的视觉语言预训练模型,和更多的视觉语言任务,比如文本图像生成。同时作者也期待和欢迎开源社区对于 LAVIS 的反馈和贡献。
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群