【论文笔记】Transformer-based deep imitation learning for dual-arm robot manipulation
【论文笔记】Transformer-based deep imitation learning for dual-arm robot manipulation
Abstract
问题:In a dual-arm manipulation setup, the increased number of state dimensions caused by the additional robot manipulators causes distractions and results in poor performance of the neural networks.
深度模仿学习在解决简单的灵巧操作问题很好,但是双臂维度上升时难度就很大。
We address this issue using a self-attention mechanism that computes dependencies between elements in a sequential input and focuses on important elements.
针对这个问题使用自注意力机制来计算输入元素序列之间的依赖/联系和关注重要的元素
实验结果:使用基于Transformer的网络处理传感器之间重要的特征,降低计算消耗,与非Transformer的baseline相比性能效果好
Keywords
- Imitation Learning;
- Dual Arm Manipulation;
- Deep Learning in Grasping and Manipulation
I. INTRODUCTION
端到端深度模仿学习,通过模仿专家的演示来控制机器人,由于其可能应用于不需要建模环境或物体的灵巧操作任务,而在机器人界广受欢迎。
由于人工操作者熟悉双臂操作,因此使用远程操作很容易转移人的双手技能。因此,通过人类远程操作生成演示数据的模拟学习框架足以用于复杂的双臂操作任务。
However, we believe the problem to solve for deep imitation learning on dual-arm manipulation tasks lies in the distractions caused by the increased dimensions of the concatenated left/right robot arm kinematics states, which is essential for the collaboration of both arms for dual-arm manipulation.
然而,我们认为双臂操作任务的深度模仿学习需要解决的问题在于左右机器人臂运动学状态的增加引起的干扰,这对于双臂操作的协作是必不可少的。
之前的工作:This study measured the human gaze position with an eye-tracker while teleoperating the robot to generate demonstration data and used only the foveated vision around the predicted gaze position for deep imitation learning to suppress visual distraction from task-unrelated objects.
远程操作生成模仿数据的时候,使用眼动仪来捕获人的注意位置,并仅使用预测注视位置周围的凹视进行深度模仿学习,来抑制与任务无关的视觉分散。基于注视的视觉注意机制需要机器人从其体感信息中获得机器人的运动学状态,因为外围视觉应该被掩盖,以抑制视觉干扰。
For example, when the robot reaches its right arm to an object, the left arm kinematics states are not used to compute the policy and become distractions.
例如,当机器人的右臂到达一个物体时,左臂的运动学状态不会被用来计算策略,从而成为干扰。
自注意力架构,特别是Transformer,评估输入序列上元素之间的关系。自注意力架构首先被引入来解决自然语言处理,并被广泛应用于许多不同的领域,如图像分类、目标检测和高分辨率合成,以及使用一个模型学习多个领域。这种自我注意在不同领域的广泛应用可能意味着它也可以用来抑制运动学状态下的干扰,这是双臂操纵中的一个问题。
Because the transformer dynamically generates attention based on the input state, this architecture can be applied to suppress distractions on kinematics states without attention signal.
由于Transformer基于输入状态动态地产生注意力attention,因此该体系结构可以用于抑制没有注意信号的运动学状态下的干扰。
In this architecture, each element of the sensory inputs (gaze position, left arm state, and right arm state) as well as the foveated image embedding is input to the Transformer to determine which element should be paid attention.
在这种结构中,感官输入的每个元素(注视位置、左臂状态和右臂状态)以及凸出的图像嵌入被输入到Transformer中,以确定哪些元素应该被注意。
将Transformer使用到以下场景:
- an uncoordinated manipulation task (two arms executing different tasks)
- a goal-coordinated manipulation task (both arms solving the same task but not physically interacting with each other)
- a bi-manual tasks (both arms physically interacting to solve the task)
II. RELATED WORK
A. Imitation learning-based dual-arm manipulation
1. based on key-points selected by hidden Markov models (HMM) to reproduce the movements of arms
2. an imitation learning framework was proposed
- segments motion primitives and learns task structure from segments for dual-arm structured tasks in simulation.
- The proposed framework was tested on a pizza preparation scenario, which is an uncoordinated manipulation task.
3. a deep imitation learning model is designed
- captures relational information in dual-arm manipulation tasks to improve bi-manual manipulation tasks in the simulated environment
- their work required manually defined task primitives
To the best of our knowledge, the performance of a self-attention-based deep imitation learning method for dual-arm manipulation has not been studied in a real-world robot environment.
一种基于自我注意的深度模拟学习方法对双臂操作的性能还没有在真实世界的机器人环境中得到研究。
(2021年的8月提出的论断)
B. Transformer-based robot learning
1. the Transformer-based seq-to-seq architecture
-
to improve meta-imitation learning
-
they used the Transformer to capture temporal correspondences between the demonstration and the target task.
-
these studies did not apply the self-attention architecture to robot kinematics states
因此,我们的工作旨在设计一个基于Transformer的架构,以确定当前状态下对多个感官输入的注意,以鲁棒输出,以对抗机器人运动状态增加引起的干扰。
III. METHOD
A. Robot system
- a human operator teleoperates two UR5 (Universal Robots) manipulators
- a head-mounted display (HMD,头戴式显示器) provides vision captured from a stereo camera(立体相机) mounted on the robot(戴在机器人的头上)
- During teleoperation, the human gaze is measured by an eye-tracker mounted in the HMD(戴在HMD上的眼动仪)
In this research, the left camera image is resized into 256 × 256 (called the global image) and recorded at 10 Hz with the two-dimensional gaze coordinate of the left eye and with the two-dimensional gaze coordinate of the left eye and robot kinematics states of both arms.
在本研究中,将左侧摄像机图像调整为256×256(称为全局图像),并10 Hz记录以左眼的二维注视坐标和机器人双臂的运动学状态
每一个状态都包含10个维度:
| 每个子维度的意义 | 子维度的数量 |
|---|---|
| the end-effector position(末端执行器的位置) | 3,空间中的点坐标 |
| the orientation(末端执行器的方向) | 6,三维欧拉角的正弦和余弦值 |
| the gripper angle | 1,张开/闭合 |
B. Gaze position prediction
1. human gaze was used to achieve imitation learning of a robot manipulator that is robust against visual distractions.
- predicts gaze position(预测凝视点)
- crops the images around the predicted gaze position to remove task irrelevant visual distractions(收获在凝视点周围的图片来消除任务无关的视觉分散)
2. using a mixture density network
-
a neural network architecture that fits a Gaussian mixture model (GMM) into the target, for estimating the probability distribution of the gaze position.
-
The gaze predictor inputs the entire 256 × 256 × 3 256 × 256 × 3 256×256×3 RGB image and outputs μ ∈ R 2 × N \mu ∈ R^{2×N} μ∈R2×N , σ ∈ R 2 × N \sigma ∈ R^{2 × N} σ∈R2×N , ρ ∈ R 1 × N \rho ∈ R^{1×N} ρ∈R1×N , p ∈ R N p ∈ R^{N} p∈RN , which comprises the probability distribution of a two-dimensional gaze coordinate location where N N N is the number of Gaussian distributions that compose the GMM.
在本文工作中, N N N=8
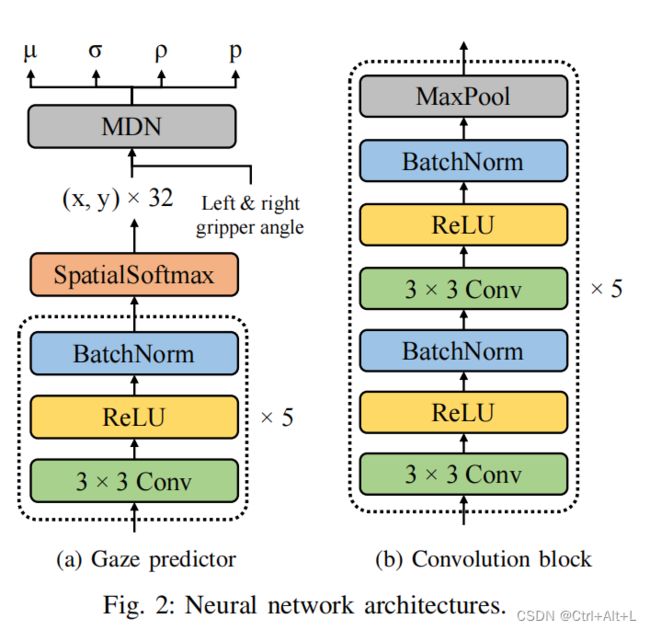
因为夹持器也能提供有效的信息,因此在流程中夹持器的状态被加入了进来
-
This network is trained by minimizing the negative log-likelihood of the probability distribution with the measured human gaze as target e e e
C. Transformer-based dual-arm imitation learning
-
从整个 256 × 256 256\times 256 256×256 的三维照片中提取二维的凝视点
-
从二维凝视点中生成 64 × 64 64\times 64 64×64 的凸性图(foveated image)
-
将凸性图导入到5层卷积层和一层全局池化层
-
将预测的注视位置和左右机器人机械手状态连接成22维状态
(凝视点2维、左臂机器人10维,右臂机器人10维)
在这项工作中,为了学习机器人状态的每个元素之间的依赖关系,机器人状态被分离为标量值。
我们给每个值添加了一个22维的 one-hot 向量作为位置嵌入。
每个(1+22)维的状态元素与一个表示位置的单热向量通过一个线性投影,生成一个具有学习到的位置嵌入的64维状态表示。
最后,编码的特征被扁平,并通过一个具有一个隐藏层的 MLP 来预测双臂的动作。
关于夹持器的力变化:
The gripper is controlled by the last element of the predicted action. However, this element only predicts the angle of the gripper and does not provide enough force to grasp any object. Therefore, a binary signal for the gripper open/close command is also predicted. If this binary signal predicts that the gripper should be closed, the gripper command additionally tries 5 5 5 to provide enough force to grasp objects.
IV. EXPERIMENTS
A. Task setup
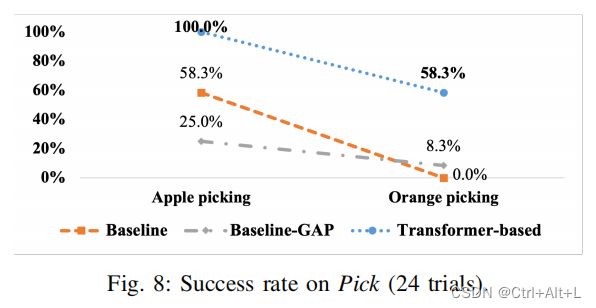
Pick
- 在这项任务中,机器人必须用它的左端执行器拿起玩具苹果,然后拿起玩具的橙色,它总是放在苹果的右边,用它的右端执行器。
- 这个任务评估不协调的操作,因为捡起苹果和橙色是相互独立的。
- 苹果和橙色被随机放置在机器人手臂够得及的桌子上。
BoxPush
- 在这个任务中,机器人必须使用两只双臂将盒子推到目标位置。
- 这个任务是为了评估双手操作。
ChangeHands
- 这个任务评估机器人是否能够完成涉及抓握的精确双手操作。
- 机器人必须首先用左臂抓住玩具香蕉,把它站起来,用右手重新抓住它,最后翻转(flip)香蕉。
- 这种再抓取行为需要根据左手的位置来准确地预测右手的抓取位置。
KnotTying
- 在这个任务中,机器人操纵者试图打结,这是一个复杂的目标协调操作任务,涉及一系列考虑可变形结的几何形状的子任务。
- 这个结被放置在一个 α α α 的形状中。机器人必须用右手拾起交叉部分的中心(Pick Up),适当引导左手进入环内,避免碰撞,抓住绳子的一个末端(Grasp),将末端拔出环(Pull Out),松开爪,用右手拾起绳子的另一端(Regrasp),最后打结。
90 % 90\% 90% 的训练集和 10 % 10\% 10% 的测试集
在测试过程中,目标对象被定位到尽可能靠近在随机打乱的验证集图像上记录的目标的初始位置
Knot Tying 的中间隐藏层数量更多,因为涉及的动作更加复杂
B. Baselines
与两个没有用 Transformer 编码器的 baseline 进行测试
- 第一个GAP模型(baseline-GAP)保留了GAP层,但用一个完全连接的层替换了每个Transformer 编码器层
- 第二个baseline模型(baseline)不包括用于图像处理的 GAP 和 Transformer 编码器。
C. Performance evaluation
The result indicates that the Transformer-based method outperforms both baseline methods in terms of success rates of picking up each object.
Because the baseline-GAP performed the worst among the three models, it was excluded from further experiments.
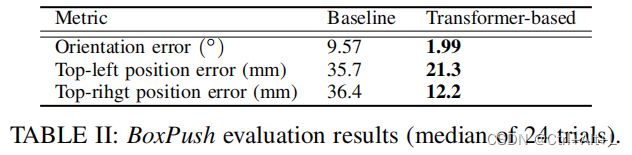
为了进行定量评估,我们测量了机器人执行任务后,盒子的左上角和右上角的最终位置,并计算出两个角到理想目标位置的欧氏距离;
根据两个测量的位置计算出方向误差,即测量盒子相对于理想目标方向的倾斜程度(约为0◦)。
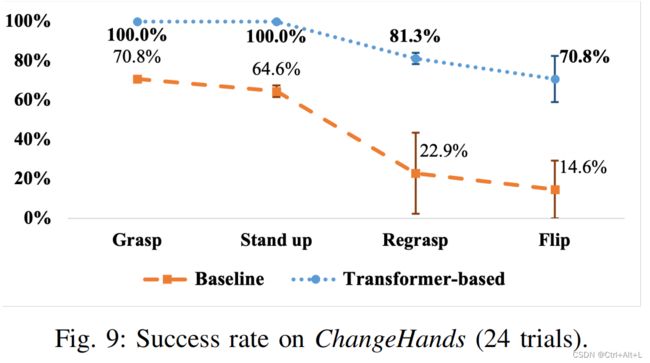
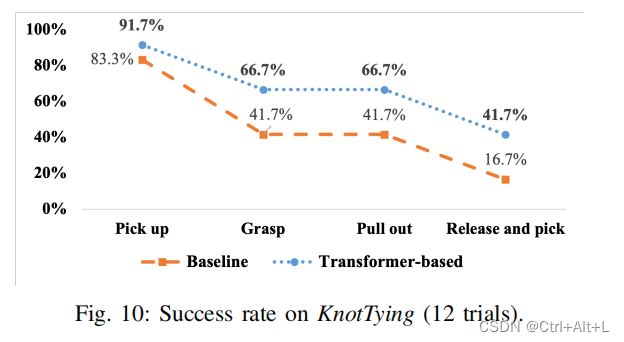
我们发现,在 Release And Pick 期间模仿释放行为并不成功,这可能是因为确切的释放时间与当前的感官输入没有很强的关系。
相反,人工操作者可以在子任务拉出完成后随时释放夹具,导致释放信号被稀释。
因为我们的目的是使自我注意适应当前的感觉输入,我们设定了释放行为,如果右手闭合,右手在左手右侧,只打开右手一次。
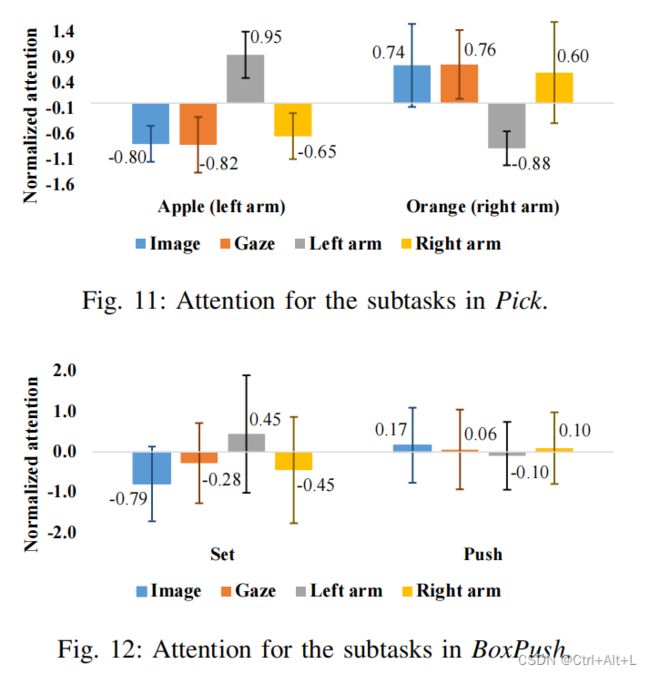
D. Attention weight assessment
To determine which sensory input the Transformer attends, we investigated the attention weights for each sensory input.
- attention rollout,它是所有 Transformer 层对所有注意头部的平均注意权重的递归乘法。
- 感觉输入的注意值属于凸性图、注视位置、左臂状态,从 23 × 23 23×23 23×23 注意推出开始计算出右臂状态。
- Then, each time series attention values in each input domain (Image, Gaze, Left, Right) was normalized because we want to see the change of attention values on each input domain.
V. DISCUSSION
-
Our Transformer-based deep imitation learning architecture is not specialized for dual arms but instead can be expanded to more complicated robots such as multi-arm robots or humanoid robots by concatenating more sensory information into the state representation.
-
In our experiment, closed-chain bimanual manipulation tasks such as moving heavy objects using both arms were not tested. In our teleoperation setup without force feedback, the counterforce from the object is not transferred back to the human, causing failure while teleoperating the closed chain manipulation tasks.