NLP学习笔记6--Lecture/语言模型/预处理/独热编码/word2vec/文本特征工程
语言模型用来判断:是否一句话从语法上通顺
先分词 然后算出联合概率 怎么算? chain rule


条件很长的时候 会遇到一个问题 sparsity 数据的稀疏性
用马尔科夫假设 最简单的假设 之前的单词不影响当前单词的条件 unigram model
一阶假设 可以理解为 只被最近的单词影响 bigram model 不能考虑单词之间的先后顺序
二阶假设 只被最近的两个单词影响 trigram model
结合起来就是N-gram model 最常用的可能是bigram 既要考虑数据稀疏性 又要考虑准确度
语言模型也是训练的过程 就是从语料库中统计概率的过程
给定CORPUS 训练出多个language model
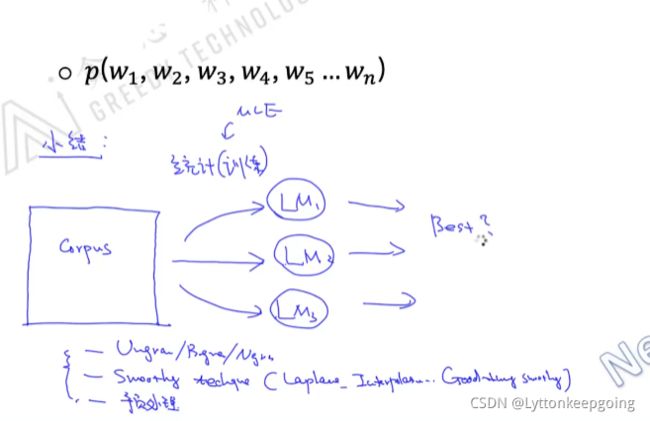
选出一个最好的语言模型 N-gram Smoothy 预处理

有没有更简单的评估方法? 比如不需要放到特定的任务中
语言模型本事是有能力预测下一个单词的
一个好的语言模型会使输出的概率越来越大
perplexity perplexity越小 x 越大 模型就越好

Add-one Smoothing(Laplace Smoothing)

语言模型在拼写纠错中的应用
怎么纠错?
如果不考虑整句话

通过编辑距离 做一个排序 得到一个候选集 再做一个处理
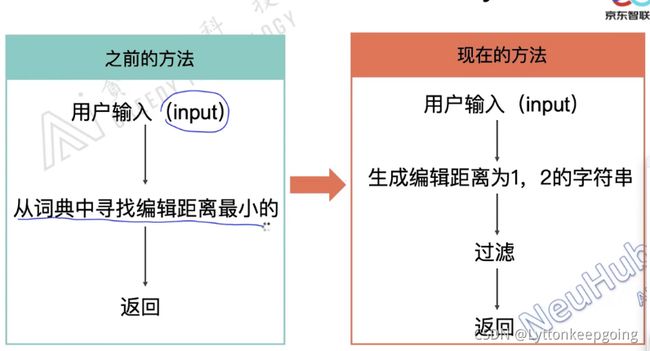
降低了时间复杂度 从输入开始筛选 先找出和输入编辑距离为1,2的字符串
怎么过滤?根据上下文
1.词拼写错误
2.没有错词:语法
文本预处理
过滤词
对于NLP的应用 我们通常把停用词(的 is the)、特殊的标点符号、出现频率很低的词过滤掉
英文里面 词的标准化 normalization
went go going 意思都类似 怎么合并?
stemming:one way to normalize 根据规则来 但不保证最终出来的词一定在词库
lemmazation:可以保证最后标准化的单词是有效单词 词库里的单词
分词算法 最大匹配算法 hmm crf
最常用的分词工具

word /sentence representation
文本也要转换成特征向量
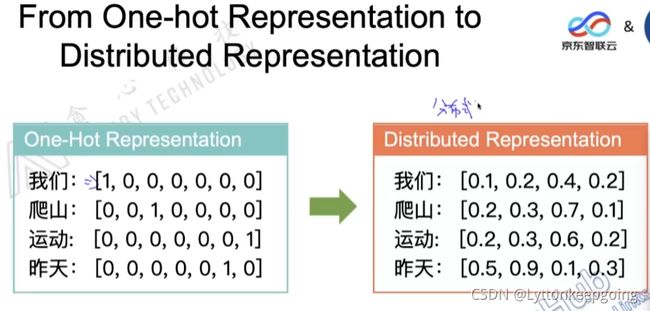
最简单的 独热编码
句子的独热编码 分词后 按是否出现排列0,1

如何衡量两个句子之间的关系? 欧氏距离表示两个句子之间的相似度

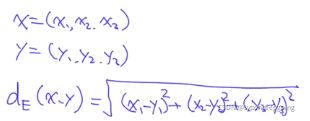
计算相似度(余弦相似度)内积本身就是余弦相似度的特例

并不是出现的越多就越重要 并不是出现的越少就越不重要
就要有一个加权 再乘以的出现频率 于是就有了tf-idf
TF-IDF term frequency TF(一个单词出现了多少次) inverse document frequencyIDF(Y一个单词的重要性 )

词向量 如何判断两个向量之间的相似度?
sim(爬山 运动)> sim(我们 昨天)
(1)欧式距离
(2)余弦相似度
但是没有办法表示之间的含义 独热编码不能表达出一个单词具体的含义
而且 sparsity 非常多的0 很稀疏
稀疏矩阵处理

用更稠密的方式表示 分布式表示法 distributed representation
可以自定义dimension
这样就很容易判断出 两个单词之间的相似度
 问题为 如何训练一个词向量?
问题为 如何训练一个词向量?
Q:100维的one-hot表示法最多可以表示多少个不同的单词?100
Q:100维的分布式表示法最多可以表示多少?无穷个 capacity
通过一个model去训练出词向量
input :corpus(语料库) 多少个文档
output:词向量
model:经典的模型 skipgram、glove、cbow 词向量模型 传统方式
考虑上下文的词向量训练方法 elmo、bert、xlnet
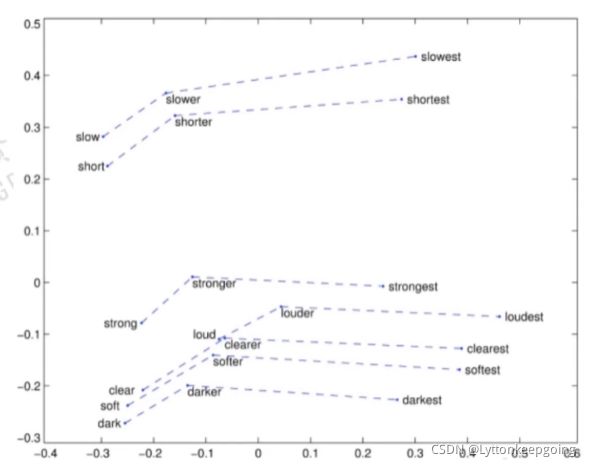
假设我们训练出一个词向量 我们把词向量映射到一个二维空间里面
通过降维的方式 把一百维的向量降维到一个二维空间里面 然后可视化
降维的方法:T-sne(在词向量领域用的最多) PCA等等
有了词向量的表示之后 句子的向量字母表示?
词向量是一个向量
最简单的方法 加和求平均 也叫average pooling

也可以在句子向量后面加上一些 tf-idf特征或者n-gram
词向量怎么学习?review里面详解
词向量学习的逻辑
分布式假设 当我去理解一个单词的时候 我们可以根据他周围的单词去理解 猜测
假设我们要训练的单词 为h今天 h疫情 h由于
根据h今天 和h 疫情预测出h由于 如果词向量训练的很好 我们是可以预测的
相邻的单词之间在语义上类似
后面的所有的算法都是基于分布式假设

skip gram model
能不能用中间的单词预测周围?? skip gram的中心思想 肯定给cbow更难
刚才的思想是 根据周围的单词预测中间的单词 也叫cbow
希望有一个词向量模型 可以得到一个词向量 预测的能力越大越好
skip gram训练的方式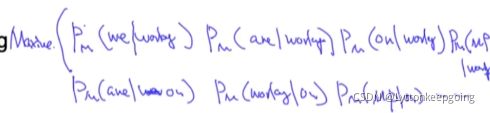
概率的乘积就是我们的目标函数 我们要最大化我们的概率 就是训练的过程

具体的细节
语料库:AI 的 发展 很 快 window_size=1
maximize: 用AI 来预测的 用的来预测AI 用的来预测发展 用发展来预测的 用发展预测很 用很来预测发展 用很来预测快 用快来预测很 ![]()
每个概率我们需要用一个参数表示 这样才能最终优化
简化一下上面的式子
每个单词有两个角色 一个叫上下文词 一个叫中心词 为了区分 用u代表上下文矩阵 v代表中心词矩阵 w表示中心词 c表示上下文词 用w预测c 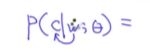
字母表示 类似softmax 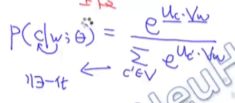 内积越大 相似度越高 条件概率越大 也满足设计理念 分母就是做一个归一化的操作
内积越大 相似度越高 条件概率越大 也满足设计理念 分母就是做一个归一化的操作
为什么非要定义成这样的形式? 只要c和w意思相近 只要输出的概率越大就行 内积距离都行
整个skipgram目标函数的推导过程

优化的过程 用梯度下降法求解 log sum没办法简化 时间复杂度很高没办法解决
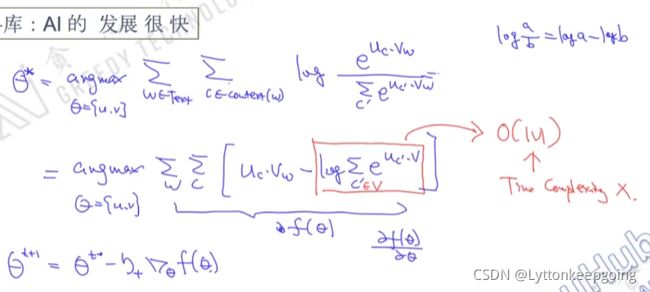
简化的方式:Negative sampling 和Hierarchical softmax
总结 skipgram 用中心词预测周围的词 不断用这种方式 训练模型 最终可以得出一个向量
CBOW 和Skip Gram 区别 之前讲过
skip gram 最经典 效果也是最好的之一 还有 glove
Subword Model with Skipgram
Fasttext 刚才讲的skipgram那些问题不能解决?
OOV: out of vocabulary 语料库里有大量单词 测试库里有很复杂的单词 但是没有出现在语料库里面 或者说出现的次数很少 那自然预测出来的不准确
这时候就要用到一个fasttext 用到N-gram features
假设手里面已经知道了几个单词的向量或者含义
walk study studying typing(及中文意思) 以上是训练集中出现的
但是walking 没有出现在训练数据里面 没办法得到词向量 但是人类一眼可以看出 根据训练集中的数据可以推测出
如何让模型也知道这件事情呢?
walking 分解为 4-gram features 
walking整体没有出现 但是walking的子模块可能出现过
glove(global vectors for word representation )
结合了矩阵分解MF 和 skipgram

一词多义怎么办
contexualized embedding 动态调整当前单词的词向量 之后会讲
语言模型在分词中的应用

贪心算法 不会考虑语义 只考虑匹配的关系
考虑语义的方法: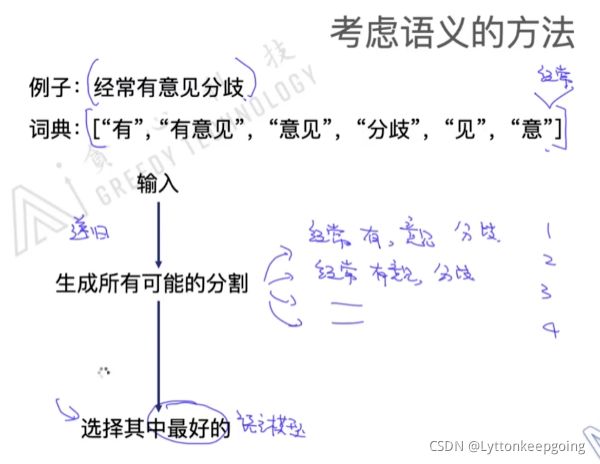
但是生成所有可能的分割是非常多的(指数级的)
viterbi算法 使计算变得更加高效
word segmentation with unigram model ,using viterbi
找路径最短 dp动态规划
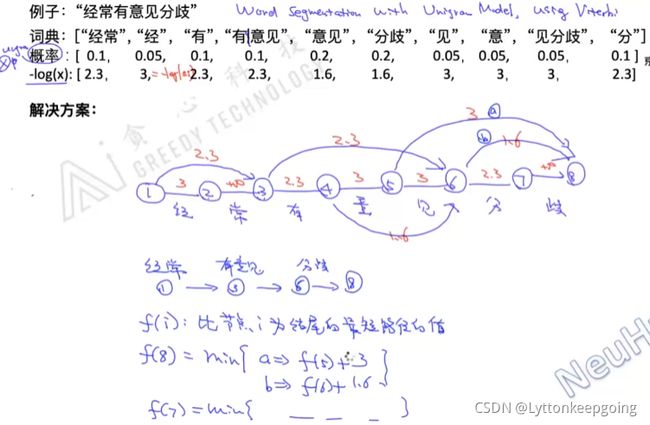
文本特征工程
可以把以下特征结合在一起
TF-IDF特征 、embedding特征(word2vec)、n-gram特征、pos(词性特征)、主题特征(LDA模型 学习一个主题的分布)、Task-specific feature (一句话里面多少个单词,大写有多少个,是否有人名、整个字符的长度)
具体的特征就看具体任务
就是把每个句子对应到一个embedding里面

测试集是拿不到的
n-gram的s和v怎么理解
如bi-gram 就是把两个单词结合看成一个单词 然后把s对应成向量

降维的两种方式
特征选择
高维特征映射到低维
CBOW更符合根据上下文填空 为什么skipgram效果更好
从样本的角度
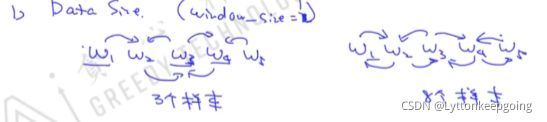
从难易度
CBOW简单 SKIPGRAM 难
从smoothing effects
对于出现次数少的单词效果不太好
但是出现次数多的 效果还是可以