NLP-D6-李宏毅机器学习L3hw-L4self-attention-L5seq2seq(Transformer)
昨天的进度被一些意外的事情打乱了,而且搞得心烦意乱,但是没关系!!!留得青山在,不怕没柴烧,昨天第一次给同学讲解ML,发现了自己不牢固的知识,感觉很好!
----0553
开始预习hw3的slides&&看课。
----------0609
看了作业要求,感觉很干!!!打算边吃饭边看。
------0628吃完了,产生了问题
1、交叉验证不会使模型提前见到训练集嘛?
我自己的想法:我们本来做的就是用val调model,交叉验证只不过是另一种利用val的方法。
------0710大概看完了,然后主要讲的就是数据增强和交叉验证以及代码。突然发现kaggle是可以编辑之前的版本的,之前我都是自己复制的,太拉跨了。然后刚刚试跑了hw3的模型,现在查一下tqdm是啥,就下去收拾宿舍。
1、tqdm—显示进度条的
Tqdm 是一个快速,可扩展的Python进度条,可以在 Python 长循环中添加一个进度提示信息,用户只需要封装任意的迭代器 tqdm(iterator)。
总之,它是用来显示进度条的,很漂亮,使用很直观(在循环体里边加个tqdm),而且基本不影响原程序效率。名副其实的“太强太美”了!这样在写运行时间很长的程序时,是该多么舒服啊!
原文链接:https://blog.csdn.net/qq_33472765/article/details/82940843
2、第一天可视化的工具是?
tensorboard
好像没看到怎么调用,有时间研究下hw1代码
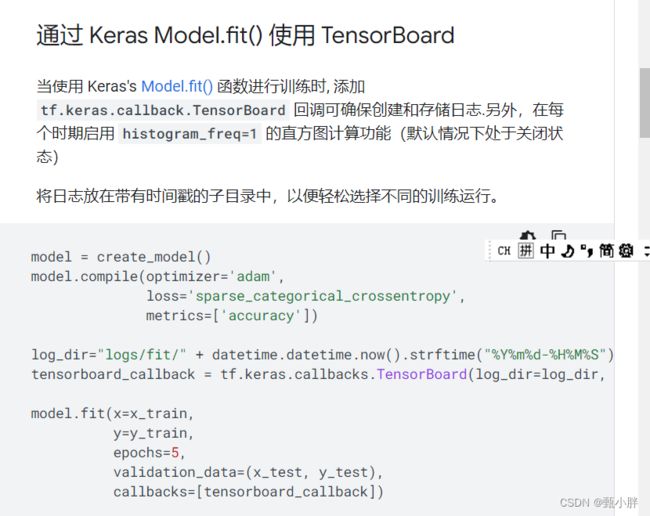
官网用法:https://www.tensorflow.org/tensorboard/get_started?hl=zh-cn
-------0747回来看下怎么用tensorboard


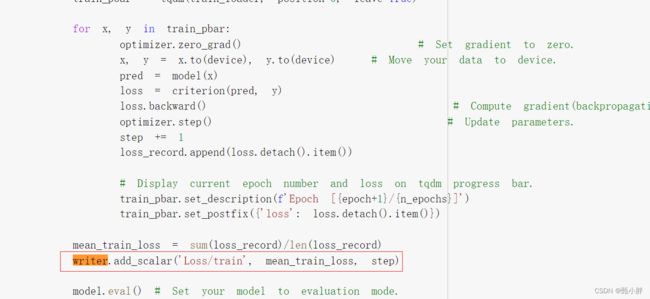


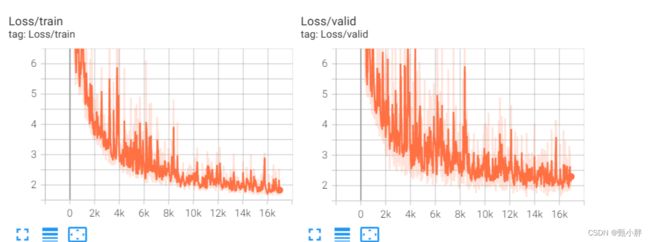
—0753现在来看下代码,正好ipad笔没有电了。
1、gradient_norm就是梯度截断,为了防止梯度爆炸。
代码:
![]()
参考资料:
https://blog.csdn.net/csnc007/article/details/97804398
2、test_pred.cpu()到底在做什么
其实,我也知道是在切换gpu、cpu,只是想查查。发现这其实是一种数据类型?



参考资料:
https://blog.csdn.net/moshiyaofei/article/details/90519430

所以源代码先转为cpu tensor再,转换为numpy()再求最大值。
4、代码看完了,但是没看到residual network呀,好像是自己写的,那就自己尝试一下!
感觉不行,还是找了官方正解,学习一下。感觉这是一个未完待续的版本,但是已经有思路了。
https://www.kaggle.com/code/a24998667/ml2022hw3-report-questions
先网上找一份残差网络代码看看,发现直接加就可以了,我之前以为是线性组合呢哈哈
参考资料:https://zhuanlan.zhihu.com/p/169460083
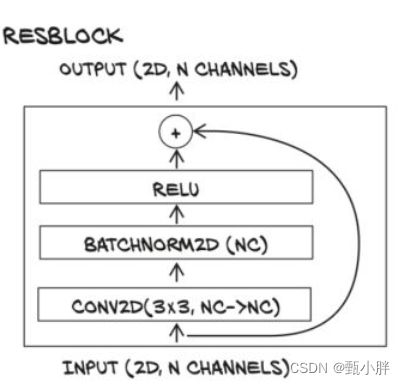
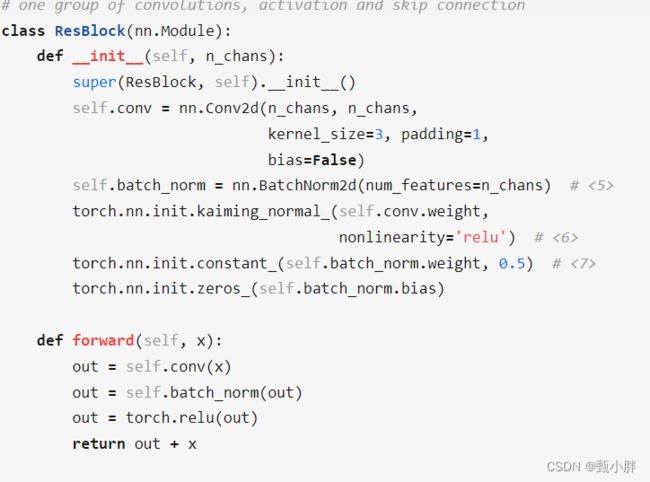
下面只是简单地组建了一个残差网络,但具体的cnn block的设置其实还需要研究。就我理解,相加的两个块的size应该是相同的,至少我验证了一下,sample里的blocks相加的时候,channel都是相同的
from torch import nn
class Residual_Network(nn.Module):
def __init__(self):
super(Residual_Network, self).__init__()
self.cnn_layer1 = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1),
nn.BatchNorm2d(64),
)
self.cnn_layer2 = nn.Sequential(
nn.Conv2d(64, 64, 3, 1, 1),
nn.BatchNorm2d(64),
)
self.cnn_layer3 = nn.Sequential(
nn.Conv2d(64, 128, 3, 2, 1),
nn.BatchNorm2d(128),
)
self.cnn_layer4 = nn.Sequential(
nn.Conv2d(128, 128, 3, 1, 1),
nn.BatchNorm2d(128),
)
self.cnn_layer5 = nn.Sequential(
nn.Conv2d(128, 256, 3, 2, 1),
nn.BatchNorm2d(256),
)
self.cnn_layer6 = nn.Sequential(
nn.Conv2d(256, 256, 3, 1, 1),
nn.BatchNorm2d(256),
)
self.fc_layer = nn.Sequential(
nn.Linear(256* 32* 32, 256),
nn.ReLU(),
nn.Linear(256, 11)
)
self.relu = nn.ReLU()
def forward(self, x):
# input (x): [batch_size, 3, 128, 128]
# output: [batch_size, 11]
# Extract features by convolutional layers.
x1 = self.cnn_layer1(x)
x1 = self.relu(x1)
x2 = self.cnn_layer2(x1)
# 自己写的哦
x2 = x1 + x2
x2 = self.relu(x2)
x3 = self.cnn_layer3(x2)
x3 = self.relu(x3)
x4 = self.cnn_layer4(x3)
x4 = x3+x4
x4 = self.relu(x4)
x5 = self.cnn_layer5(x4)
x5 = self.relu(x5)
x6 = self.cnn_layer6(x5)
x6 = x5 + x6
x6 = self.relu(x6)
# The extracted feature map must be flatten before going to fully-connected layers.
xout = x6.flatten(1)
# The features are transformed by fully-connected layers to obtain the final logits.
xout = self.fc_layer(xout)
return xout
---------------0906看完代码啦~休息一下,回来看课了!
-----------------0913回来啦!!!预习L4的pre1啦!!!迫不及待听课!
-----------1317上午听完了self-attention机制,然后去吃饭、签单子、翻了很久快递,回来趴了一小会,发现睡不着,那就泡个咖啡继续看课了。
和rb讨论了attention中qdot product k衡量相似度的问题,我很接受向量中夹角的理论,他说不一定,我还不太理解,以后再看看。
Self-attention机制中有三个参数,k,q,v矩阵,分别用来transformkey,query和对相似度做组合。self-attention是复杂版的cnn,能够自己学习receptive-field。
与rnn相比,可以并行计算+不会遗忘+(单向rnn不能学全局信息,但双向rnn解决了这个问题)
------1323大概总结了一下,准备预习、看下一课了!向Transformer进发!居然L4结束了,RNN和GNN的视频之后再看。稍微看下hw的slides,决定要不要先做,还是先看。感觉里面提到了transformer,还是先学叭
----------1353看完了hw4的视频,发现里面要用transformer和conformer。虽然都没怎么讲,但是看代码可以大致理解transformer,conformer不太行。老师L5会讲,所以决定去直接看了,现在下载一下资料。
—1402下完资料,去打了杯水,预习L5pre1了
----------1522其实L5pre1很短,只有30分钟,但是我反反复复看了好几遍。讲的是BN。从为什么要做feature normalization,讲到如何用BN做,其中讲到为什么叫BN,其实最初的norm只需要一组数据自己做就可以了;但是到了第二层的时候,就涉及到前面所有批的数据了,但是所有的数据太多了,算不起,就改为了batch,这个batch不能太小,不然后面算的均值和方差没啥意义。
后来又谈到为什么有用,我觉得意思是说,不知道为啥有用,但就是有用。**以后再探究好了,先存疑。**去接个水,休息一下,可以看transformer了!!!哦对,发现goodnotes后面可以加页,这样笔记就不会在slides上很乱了。学习方法也在精进中!嘿嘿!
-------1529进军transformer啦!!!
---------1752终于看完transformer啦!!原来是一个seq2seq的模型。
1、seq2seq用来预测不知道输出是多长的序列的模型
2、transformer的一个block里encoder和decoder差不多;只是相差了一个块块和一个mask-attention(因为decoder没有后续数据呀)。一个块块就是就是一个cross attention,把两个连接。主要用decoder的q去查询encoder的输出向量(下图transformer应该是做的多头的,但是老师也没仔细说),做完后输出,然后就结束了呃呃呃呃。
3、下面的图就是整体羊毛了,encoder的块N,decoder的块N,分别对应 做cross attention,最后fc后做softmax。里面还包含了一些残差的东西,老师说有其他课专门讲这个。【刚刚查问题,突然意识到,不是encoder的每一层都对应decoder这样,而是encoder的最后一层输入decoder,参考下图】,这里面的文字也验证了我下面的问题1编码器的输出序列作为decoder的输入。这篇文章应该写的不错,可以好好读读。另外,原文是6层。
https://zhuanlan.zhihu.com/p/48508221

4、还讲了如何训练,是衡量cross-entropy,但最后生成的test打分使用BLUE,不太一致。
5、也讲了训练时forcy teacher的问题
总之,就是问题居多,很复杂,但也能听懂,还需要不断巩固。老师读的论文一看就很多,理解也透彻,需要向老师学习。
所以,我的问题:
1、两个蓝色是不是代表很多个encoder的输出序列呀?
这篇的意思是输出输入那个cross attention,感觉像是我理解的意思。https://zhuanlan.zhihu.com/p/47812375

**2、transformer的好处???**是不是之前说的attention的并行运算??之后补坑叭!

机器学习、深度学习的坑实在太大了,但是很有意思!!!都是古圣先贤的智慧,很庆幸自己有机会接触,并且能咬牙没放弃,看到现在这么精彩的部分。希望日后继续努力。等看完、吃透这套课程,再看看有没有李老师其他的好听的课程。想读《统计学习原理》了。
—1742,要去吃饭了,ipad也没电了,晚上还有事情,不能继续学了呜呜呜。先发了叭,有机会学再改,另外ipad也没电了我丢。