时序异常检测方法总结
异常检测(Anomaly detection)是时序数据分析最成熟的应用之一,目的是从正常的时间序列中识别不正常的事件或行为的过程。
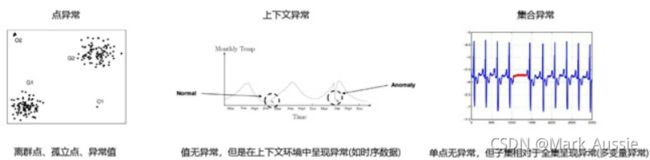
异常类型:点异常,上下文异常,集合异常。
异常检测方法
1)直接检测:针对点异常,直接定位离群点,也称离群值检测。
2)间接检测:上下文或集合异常先转化成点异常,然后再求解。
3)时间跨度检测: ARIMA, 回归模型,LSTM等,核心思想:模型学习一段历史数据,再预测, 比对真实值与预测值的偏差判断是否异常。预测类算法在股市交易、量化金融领域有着广泛应用。
4)序列跨度检测:许多传感器应用程序产生的时间序列通常彼此紧密相关。如在一个传感器上的鸟叫通常也会被附近的传感器记录下来。此时可使用一个序列预测另一个序列。与此类预期预测的偏差可以报告为异常值,如隐式马尔科夫链HMM等。
非数值变量:如 categorical, text, mixed data 的处理转化
分布概率转化:变量不再默认服从特定分布(如高斯),而单独根据具体数据集定义概率分布,按乘积方式与数值变量组合以创建单个多元分布。
线性转化:
1.One-Hot 码二进制转换,一个值对应一个种类,可能维度爆炸,且无法体现不同类别的不同权重。可以通过将每列除以其标准偏差(deviation)做归一化。
2.潜在语义分析(Latent Semantic Analysis)
基于相似度量的转化:
1.基于数据的统计邻域计算相似度,比如文本变量中“红色”和“橙色”比“红色”和“蓝色”更相近,但要人为区分属性值之间的语义关系。
2.邻域相似度计算
时序异常检测算法
1. 基于统计的算法,如假设服从高斯分布
对单变量数据:
- 集中不等式:描述了随机变量是否集中在某个取值附近
- 马尔可夫不等式: 给出了一个实值随机变量取值大于等于某个特定数值的概率的上限。设X是一个随机变量,a > 0为正实数,则不等式成立:
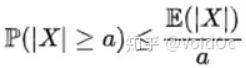
- 比切雪夫不等式:马尔可夫不等式给出了随机变量处于区间 [a,+inf] 概率的上限估计。切比雪夫不等式则给出了随机变量集中在距离其数学期望值距离不超过 a 的区间概率的上限估计:
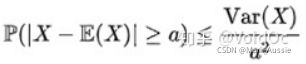
- 统计置信度检验:3-sigma,(μ−3σ,μ+3σ)区间内的概率为99.74。当数据分布区间超过这个区间时,即可认为是异常数据。
- t检验,f检验,卡方检验:检验一个正态分布的总体的均值是否在满足H0假设的值之内
- ARIMA类
预处理:
-对于纯随机序列(白噪声序列),序列的间没有关系, 是无序的随机波动, 终止对该序列的分析。
-对于平稳非白噪声序列, 其均值和方差是常数。ARMA 模型是最常用的平稳序列拟合模型。
-对于非平稳序列, 其方差和均值不稳定,一般是将其转化成平稳序列。 可用ARIMA 模型分析。
针对多变量数据:
- 马氏距离:计算样本X与中心点 μ 的距离,也可做异常分值,计算方式:
![]()
马氏距离引入数据间的相关性(协方差矩阵)。 且不需要任何参数,通常简单的最近邻算法加上马氏距离就可以强于很多复杂的检测模型;但马氏距离需要强分布假设。
2. 基于相似度的算法
a) 基于距离度量:
KNN:数据集D,参数k,对每个点计算其k邻近距离->按照距离降序排序->前N个点为离群点。
方便计算,无假设分布;只能找到点不能找到簇,适合全局异常
b) 基于密度度量:
LOF(Local Outlier Factor):局部离群因子检测方法,该算法会给数据集中的每个点计算一个离群因子: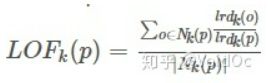 ;判断LOF是否接近于1来判定是否是离群因子。若LOF远大于1,则认为是离群因子,接近于1,则是正常点。可找到局部异常,异常为连续分值而非二分类;高维数据计算量很大。
;判断LOF是否接近于1来判定是否是离群因子。若LOF远大于1,则认为是离群因子,接近于1,则是正常点。可找到局部异常,异常为连续分值而非二分类;高维数据计算量很大。
KDE 核密度估计:核密度估计,采用平滑峰值函数(“核”)拟合观察的数据点,对真实的概率分布曲线模拟: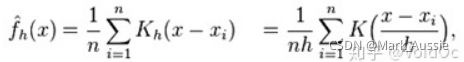
原理:“核”是一个函数,提供权重。如高斯函数 (Gaussian) 就是常用核函数,如果某一个数在观察中出现了,可认为这个数的概率密度很大,和这个数比较近的数的概率密度也会比较大,而那些离这个数远的数的概率密度会比较小。非参数估计,无分布假设;数据量少是无法准确拟合,边界区域会有边界效应。
基于聚类:K-means,GMM,缺点:聚类参数难界定,导致检测效果偏差;聚类训练开销较大
基于树:孤立森林(Isolation Forest)
基于集成学习(Ensemble),适用于连续数据的异常检测,通过多颗 iTree形成森林来判定是否有异常点;如果数据分布不是沿着特征轴,而是随意分布,或者流型分布,就需要选择别的方式了。
基于谱(线性模型):通过与正常谱型进行残差对比,发现异常。
- One-class SVM 矩阵分解法: 无监督,解决极度不平衡数据;OneClassSVM不是一种异常点检测方法,而是一种奇异值检测方法,其训练集不应该掺杂异常点(训练集只有一类),否则可能在训练时影响边界的选取。 但在数据维度很高,或者对相关数据分布没有任何假设的情况下,OneClassSVM也可以作为一种很好的outlier detection方法。
- Replicator Neural Networks and Deep Autoencoders:基于神经网络(需要构造必要特征)适用于连续数据的异常检测,并通过寻找神经网络的重构误差来区分正常点和异常点。
深度学习的时间序列异常检测算法
a) 对正常数据进行训练建模,通过高重构误差来识别异常点,即生成式(Generative)的算法,通常为无监督的,如自编码器(Auto Encoder)类或回声状态网络(Echo State Networks)。
b) 对数据的概率分布进行建模,根据样本点与极低概率的关联性来识别异常点,如DAGMM。
c) 通过标注数据,训练模型识别正常数据,异常数据,有监督算法训练分类模型,判别式算法。
在判别式里面,包括时间序列的特征工程和各种有监督算法,还有端到端的深度学习方法。在端到端的深度学习方法里面,包括前馈神经网络,卷积神经网络,或者其余混合模型等常见算法。
参考:时间序列异常检测(一)—— 算法综述 - 知乎
时间序列异常检测(二)—— 基于KDD99数据集的实战 - 知乎