cs224w(图机器学习)2021冬季课程学习笔记12 Knowledge Graph Embeddings
诸神缄默不语-个人CSDN博文目录
cs224w(图机器学习)2021冬季课程学习笔记集合
VX号“PolarisRisingWar”可直接搜索添加作者好友讨论。
更新日志:
2021.11.16 删除PPT链接,美化公式排版
文章目录
- 1. Heterogeneous Graphs and Relational GCN (RGCN)
- 2. Knowledge Graphs: KG Completion with Embeddings
- 3. Knowledge Graph Completion: TransE, TransR, DistMult, ComplEx
YouTube 视频观看地址1 视频观看地址2 视频观看地址3
本章主要内容:
本章首先介绍了 异质图heterogeneous graph 和 relational GCN (RGCN)。
接下来介绍了 知识图谱补全knowledge graph completion 任务,以及通过图嵌入方式的四种实现方式及其对关系表示的限制:TransE,TransR,DistMult,ComplEx。
1. Heterogeneous Graphs and Relational GCN (RGCN)
- 本节课任务:
之前课程的内容都囿于一种边类型,本节课拓展到有向、多边类型的图(即异质图)上。
介绍RGCN,知识图谱,知识图谱补全任务的表示方法。
图的节点和边都可以是异质的 - 异质图:
节点集 V V V,节点 v i v_i vi
边集 E E E,边 ( v i , r , v j ) ∈ E (v_i,r,v_j)\in E (vi,r,vj)∈E
节点类型 T ( v i ) T(v_i) T(vi)
边类型集合 R R R,边类型 r r r
- 异质图举例:生物医学知识图谱或事件图
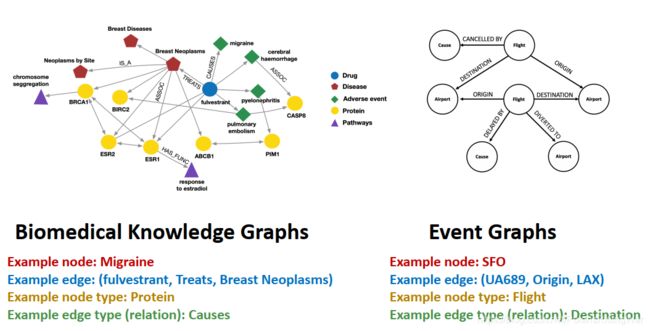
- Relational GCN1
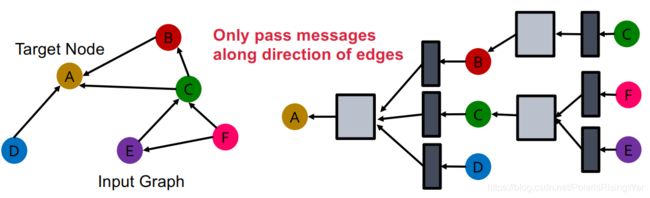
将GCN2拓展到异质图上- 从只有一种边类型的有向图开始:通过GCN学习节点A的表示向量,即沿其入边形成的计算图进行信息传播(message + aggregation)。

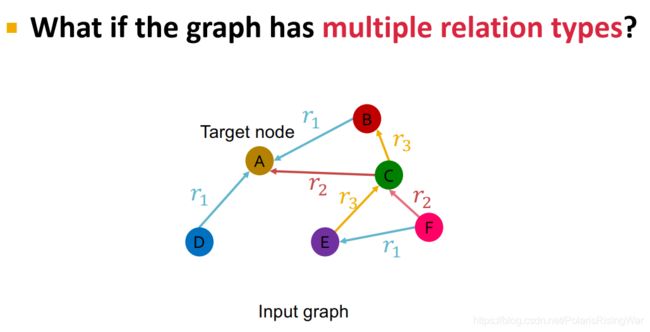
- 对于有多种边类型的情况:在信息转换时,对不同的边类型使用不同的权重 W W W
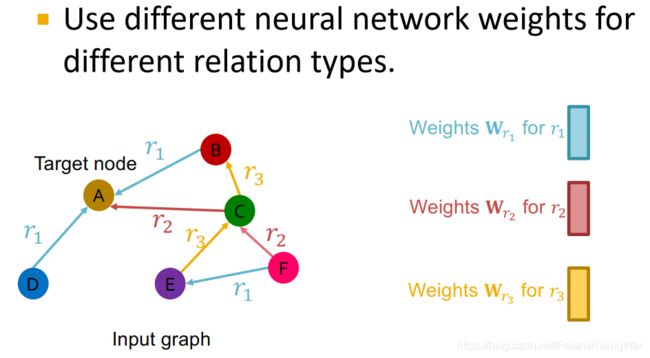
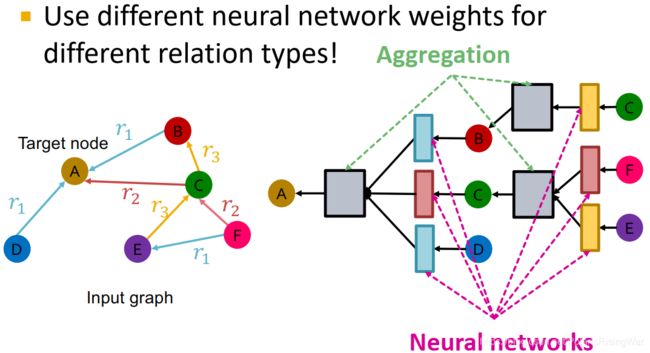
- Relation GCN定义3
公式: h v ( l + 1 ) = σ ( ∑ r ∈ R ∑ u ∈ N v r 1 c v , r W r ( l ) h u ( l ) + W r ( 0 ) h v ( l ) ) \mathbf{h}_v^{(l+1)}=\sigma\left(\sum\limits_{r\in R}\sum\limits_{u\in N_v^r}\dfrac{1}{c_{v,r}}\mathbf{W}_r^{(l)}\mathbf{h}_u^{(l)}+\mathbf{W}_r^{(0)}\mathbf{h}_v^{(l)}\right) hv(l+1)=σ(r∈R∑u∈Nvr∑cv,r1Wr(l)hu(l)+Wr(0)hv(l))
( c v , r = ∣ N v r ∣ c_{v,r}=|N_v^r| cv,r=∣Nvr∣ 用节点in-degree进行归一化)
message:
对特定关系的邻居: m u , r ( l ) = 1 c v , r W r ( l ) h u ( l ) \mathbf{m}_{u,r}^{(l)}=\dfrac{1}{c_{v,r}}\mathbf{W}_r^{(l)}\mathbf{h}_u^{(l)} mu,r(l)=cv,r1Wr(l)hu(l)
自环: m v ( l ) = W r ( 0 ) h v ( l ) \mathbf{m}_v^{(l)}=\mathbf{W}_r^{(0)}\mathbf{h}_v^{(l)} mv(l)=Wr(0)hv(l)
aggregation:加总邻居和自环信息,应用激活函数: h v ( l + 1 ) = σ ( Sum ( { m u , r ( l ) , u ∈ { N ( v ) } ∪ { v } } ) ) \mathbf{h}_v^{(l+1)}=\sigma\left(\text{Sum}(\{\mathbf{m}_{u,r}^{(l)},u\in\{N(v)\}\cup\{v\}\})\right) hv(l+1)=σ(Sum({mu,r(l),u∈{N(v)}∪{v}}))
- 从只有一种边类型的有向图开始:通过GCN学习节点A的表示向量,即沿其入边形成的计算图进行信息传播(message + aggregation)。
- RGCN的scalability
每种关系都需要 L L L(层数)个权重矩阵: W r ( 1 ) \mathbf{W}_r^{(1)} Wr(1), W r ( 2 ) \mathbf{W}_r^{(2)} Wr(2) … W r ( L ) \mathbf{W}_r^{(L)} Wr(L)
每个权重矩阵的尺寸为 d ( l + 1 ) × d ( l ) d^{(l+1)}\times d^{(l)} d(l+1)×d(l)( d ( l ) d^{(l)} d(l) 是第 l l l 层的隐嵌入维度)
参数量随关系类数迅速增长,易产生过拟合问题
2种规则化权重矩阵的方法:block diagonal matrices 和 basis/dictionary learning
- block diagonal matrices
使权重矩阵变稀疏,减少非0元素数量。
做法就是如图所示,让权重矩阵成为这样对角块的形式。如果用B个低维矩阵,参数量就会从 d ( l + 1 ) × d ( l ) d^{(l+1)}\times d^{(l)} d(l+1)×d(l) 减少到 B × d ( l + 1 ) B × d ( l ) B B\times\dfrac{d^{(l+1)}}{B}\times\dfrac{d^{(l)}}{B} B×Bd(l+1)×Bd(l)。
这种做法的限制在于,这样就只有相邻神经元/嵌入维度可以通过权重矩阵交互了4。要解决这一限制,需要多加几层神经网络,或者用不同的block结构,才能让不在一个block内的维度互相交流。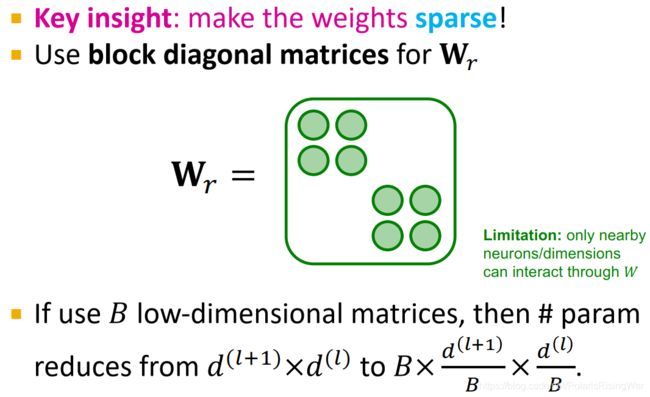
- basis learning
在不同关系之间共享权重参数。
做法:将特定关系的权重矩阵表示为 基变换basis transformations 的 线性组合linear combination 的形式: W r = ∑ b = 1 B a r b ⋅ V b \mathbf{W}_r=\sum^B_{b=1}a_{rb}\cdot\mathbf{V}_b Wr=∑b=1Barb⋅Vb( V b \mathbf{V}_b Vb 在关系间共享)
V b \mathbf{V}_b Vb 是 basis matrices 或 dictionary
a r b a_{rb} arb 是 V b \mathbf{V}_b Vb 的 importance weight
这样我们对每个关系就只需要学习 { a r b } b = 1 B \{a_{rb}\}^B_{b=1} {arb}b=1B 这 B 个标量了
- block diagonal matrices
- 示例
- 实体/节点分类
目标:预测节点标签。
RGCN使用最后一层产生的表示向量。
举例:k-way分类任务,使用节点 A A A 最后一层(prediction head)的输出 h A ( L ) ∈ R k \mathbf{h}_A^{(L)}\in\mathbb{R}^k hA(L)∈Rk(比如可能是经softmax输出),每个元素表示对应节点属于对应类的概率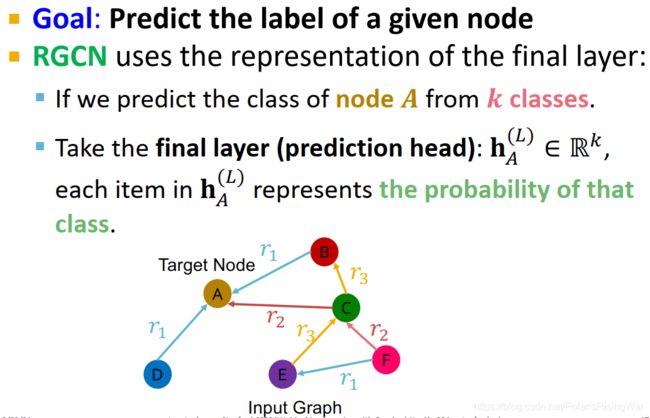
- 链接预测
在异质图中,将每种关系对应的边都分成 training message edges, training supervision edges, validation edges, test edges 四类5(切分每种关系所组成的同质图)。
这么分是因为有些关系类型的边可能很少,如果全部混在一起四分的话可能有的就分不到(比如分不到验证集里……之类的)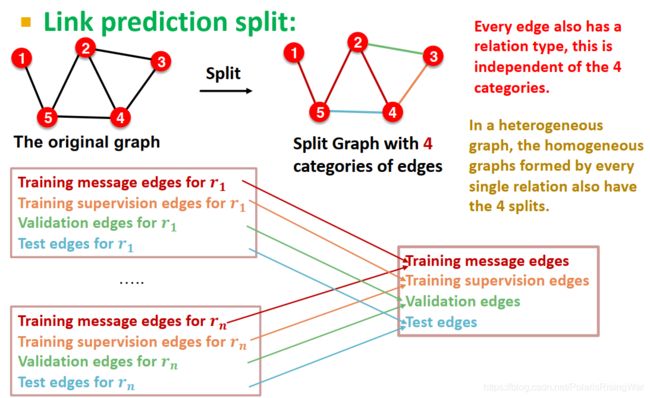
RGCN在链接预测任务上的应用:
假定 ( E , r 3 , A ) (E,r_3,A) (E,r3,A) 是 training supervision edge,则其他边都是 training message edges。
用RGCN给 ( E , r 3 , A ) (E,r_3,A) (E,r3,A) 打分:
首先得到最后一层节点 E E E 和节点 A A A 的输出向量: h E ( L ) \mathbf{h}_E^{(L)} hE(L) and h A ( L ) ∈ R d \mathbf{h}_A^{(L)}\in\mathbb{R}^d hA(L)∈Rd
然后应用 relation-specific 的打分函数 f r : R d × R d → R f_r:\mathbb{R}^d\times\mathbb{R}^d\rightarrow\mathbb{R} fr:Rd×Rd→R
(举例: f r 1 ( h E , h A ) = h E T W r 1 h A , W r 1 ∈ R d × d f_{r_1}(\mathbf{h}_E,\mathbf{h}_A)=\mathbf{h}_E^T\mathbf{W}_{r_1}\mathbf{h}_A,\ \mathbf{W}_{r_1}\in\mathbb{R}^{d\times d} fr1(hE,hA)=hETWr1hA, Wr1∈Rd×d 6)
- 训练阶段:用 training message edges 预测 training supervision edges
- 用RGCN给 training supervision edge ( E , r 3 , A ) (E,r_3,A) (E,r3,A) 打分。
- 通过 扰乱perturb supervision edge 得到 negative edge7:corrupt ( E , r 3 , A ) (E,r_3,A) (E,r3,A) 的尾节点,举例得到 ( E , r 3 , B ) (E,r_3,B) (E,r3,B)。
注意 negative edge 不能属于 training message edges 或 training supervision edges。 - 用GNN模型给 negative edge 打分
- 优化交叉熵8 损失函数,使 training supervision edge 上得分最大,negative edge 上得分最低:
ℓ = − log σ ( f r 3 ( h E , h A ) ) − log ( 1 − σ ( f r 3 ( h E , h B ) ) ) \ell=-\log\sigma\left(f_{r_3}(h_E,h_A))-\log(1-\sigma(f_{r_3}(h_E,h_B))\right) ℓ=−logσ(fr3(hE,hA))−log(1−σ(fr3(hE,hB)))
( σ \sigma σ 是sigmoid函数)


- 验证阶段(测试阶段类似):
用 training message edges 和 training supervision edges 预测 validation edges: ( E , r 3 , D ) (E,r_3,D) (E,r3,D) 的得分应该比所有 negative edges 的得分更高
negative edges:尾节点不在 training message edges 和 training supervision edges 中的以 E E E 为头节点、 r 3 r_3 r3 为关系的边(举例: ( E , r 3 , B ) (E,r_3,B) (E,r3,B) )

具体步骤:- 计算 ( E , r 3 , D ) (E,r_3,D) (E,r3,D) 的得分
- 计算所有 negative edges: { ( E , r 3 , v ) ∣ v ∈ { B , F } } \{(E,r_3,v)|v\in\{B,F\}\} {(E,r3,v)∣v∈{B,F}} 的得分
- 获得 ( E , r 3 , D ) (E,r_3,D) (E,r3,D) 的 排名 ranking RK
- 计算指标:
- Hits@k: RK ≤ k \text{RK}\leq k RK≤k 的次数,越高越好
- Reciprocal Rank: 1 RK \dfrac{1}{\text{RK}} RK1,越高越好

- 训练阶段:用 training message edges 预测 training supervision edges
- 实体/节点分类
- 总结
- Relational GCN:用于异质图的图神经网络模型
- 可用于实体分类和链接预测任务
- 类似思想可以扩展到其他RGNN模型上(如RGraphSAGE,RGAT等)

2. Knowledge Graphs: KG Completion with Embeddings
- 知识图谱 Knowledge Graphs (KG)
以图形式呈现的知识
捕获实体entity(节点)、类型(节点标签)、关系relationship(边)
一种异质图实例
- 示例
- bibliographic networks
bibliographic书目的;书籍解题的;著书目录的
通过定义节点类型、关系类型及其之间的关系,得到如图所示的schema 9: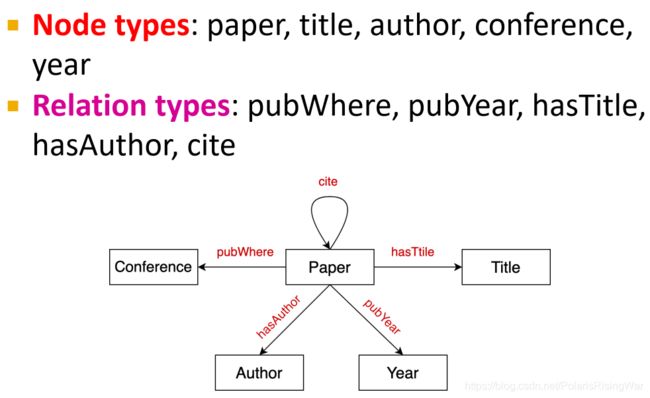
- bio knowledge graphs
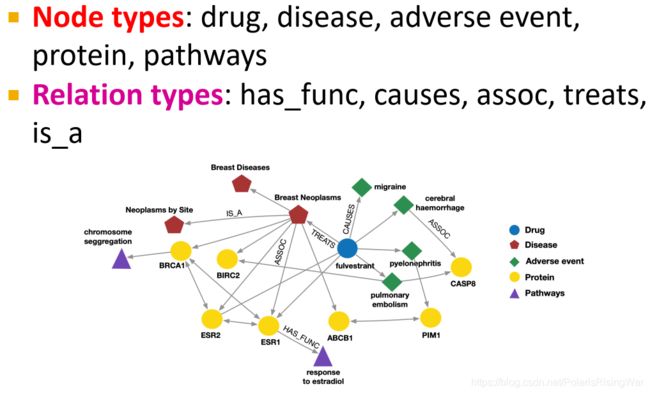
adverse event 不良反应
pathway 总之是个专业术语,过程、反应之类的10
- bibliographic networks
- 知识图谱应用实例(就我本来想把这些介绍网址啥的列出来的,但我最近不能上某些网站了,而且我又现在不用,就先直接截图了。以后有缘可以搞一下。如果真的有读者看到这里而且有这样需求的话也可以戳我催更)


- 公开可用的知识图谱有:FreeBase, Wikidata, Dbpedia, YAGO, NELL, etc.
这些知识图谱的共同特点是:大,不完整(缺少很多真实边)
对于一个大型KG,几乎不可能遍历所有可能存在的事实,因此需要预测可能存在却缺失的边
- 举例:Freebase11
大量信息缺失
有 complete 的子集供研究KG模型
3. Knowledge Graph Completion: TransE, TransR, DistMult, ComplEx
-
知识图谱补全 KG Completion Task
已知 (head, relation),预测 tails(注意,这跟链接预测任务有区别,链接预测任务是啥都不给,直接预测哪些链接最有可能出现)
举例:已知(JK罗琳,作品流派),预测 tail “科幻小说”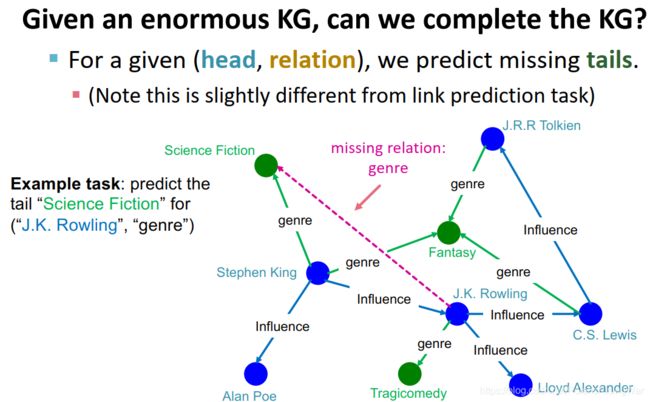
-
在本节课中使用 shallow encoding12 的方式来进行图表示学习,也就是用固定向量表示图数据
(虽然这里不用GNN,但是如果愿意的话也可以用) -
知识图谱表示
边被表示为三元组的形式: ( h , r , t ) (h,r,t) (h,r,t) head, relation, tail
将实体和边表示到嵌入域/表示域( R d \mathbb{R}^d Rd)中(使用shallow embeddings)
给出一个真实的三元组 ( h , r , t ) (h,r,t) (h,r,t),目标是对 ( h , r ) (h,r) (h,r) 的嵌入应靠近 t t t 的嵌入
以下介绍如何嵌入 ( h , r ) (h,r) (h,r) 、如何定义相似性
-
TransE13
(translate embeddings)
给出三元组 ( h , r , t ) (h,r,t) (h,r,t),将实体和关系都映射到 R d \mathbb{R}^d Rd 上(用粗体表示嵌入向量,普通字母表示原KG中的实体或关系),使三元组为真时 h + r ≈ t \mathbf{h}+\mathbf{r}\approx\mathbf{t} h+r≈t,反之 h + r ≠ t \mathbf{h}+\mathbf{r}\neq\mathbf{t} h+r=t
scoring function: f r ( h , t ) = − ∣ ∣ h + r − t ∣ ∣ f_r(h,t)=-||\mathbf{h}+\mathbf{r}-\mathbf{t}|| fr(h,t)=−∣∣h+r−t∣∣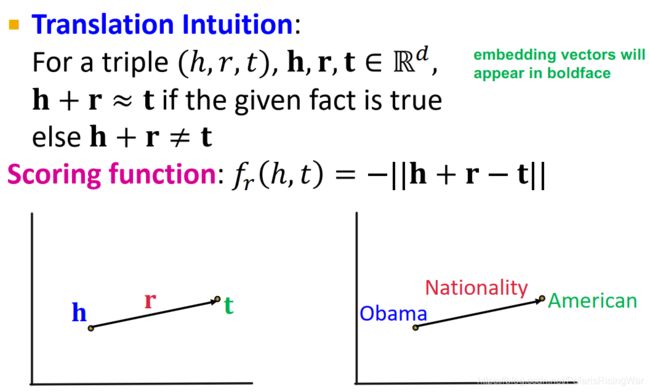
-
TransE的算法
简单来说,我没看懂。大致来讲过程是这样的:
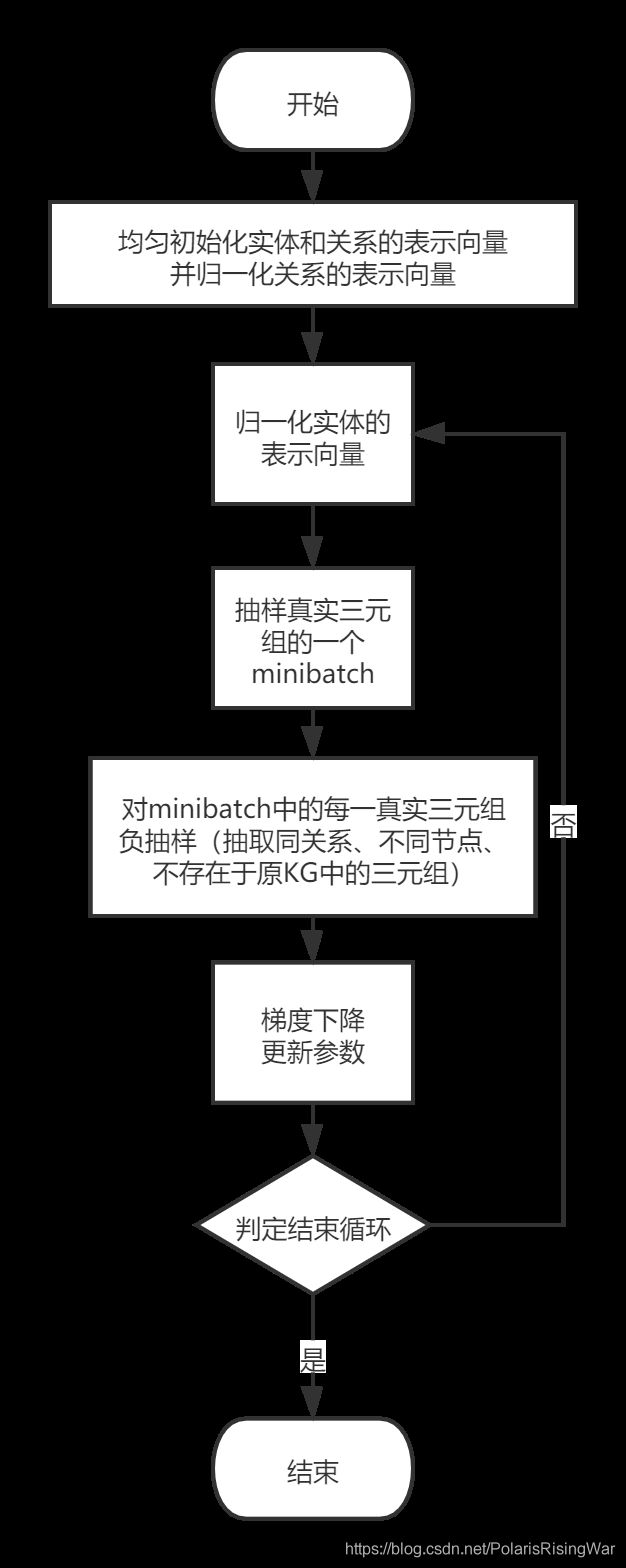
初始化部分我没看懂,以后再研究。
更新参数时使用的是 contrastive loss,总之大意就是最小化真三元组的距离(也就是最大化真三元组的score或相似性)、最大化假三元组的距离
-
KG中关系的模式 Connectivity Patterns in KG
在KG中,关系可能有多种属性,我们接下来就要探讨KG嵌入方法(如TransE等)能否建模、区分开这些关系模式:- symmetric relations(如室友关系)
r ( h , t ) ⇒ r ( t , h ) r(h,t)\Rightarrow r(t,h) r(h,t)⇒r(t,h) - antisymmetric relations(如上位词关系)
r ( h , t ) ⇒ ¬ r ( t , h ) r(h,t)\Rightarrow\neg r(t,h) r(h,t)⇒¬r(t,h) - inverse relations(如导师-学生关系)
r 2 ( h , t ) ⇒ r 1 ( t , h ) r_2(h,t)\Rightarrow r_1(t,h) r2(h,t)⇒r1(t,h) - composition (transitive) relations(如母亲-姐姐-姨母关系)
r 1 ( x , y ) ∧ r 2 ( y , z ) ⇒ r 3 ( x , z ) r_1(x,y)\wedge r_2(y,z)\Rightarrow r_3(x,z) r1(x,y)∧r2(y,z)⇒r3(x,z) - 1-to-N relations(如 的学生 关系)
r ( h , t 1 ) , r ( h , t 2 ) , . . . , r ( h , t n ) r(h,t_1),r(h,t_2),...,r(h,t_n) r(h,t1),r(h,t2),...,r(h,tn) 同时为真

- symmetric relations(如室友关系)
-
TransE:Antisymmetric Relations ✓ \checkmark ✓
h + r = t \mathbf{h}+\mathbf{r}=\mathbf{t} h+r=t,但 t + r ≠ h \mathbf{t}+\mathbf{r}\neq\mathbf{h} t+r=h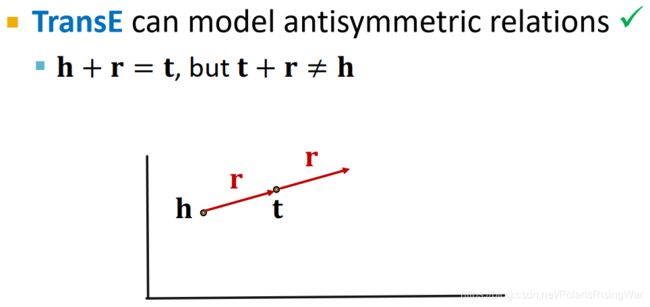
-
TransE:Inverse Relations ✓ \checkmark ✓
h + r 2 = t \mathbf{h}+\mathbf{r_2}=\mathbf{t} h+r2=t,设置 r 2 = − r 1 \mathbf{r_2}=-\mathbf{r_1} r2=−r1 即可实现 t + r 1 = h \mathbf{t}+\mathbf{r_1}=\mathbf{h} t+r1=h
-
TransE:Composition ✓ \checkmark ✓
已知 x + r 1 = y \mathbf{x}+\mathbf{r_1}=\mathbf{y} x+r1=y ①, y + r 2 = z \mathbf{y}+\mathbf{r_2}=\mathbf{z} y+r2=z ②
则若 r 3 = r 1 + r 2 \mathbf{r_3}=\mathbf{r_1}+\mathbf{r_2} r3=r1+r2,将①②相加,消项后就能得到 x + r 3 = z \mathbf{x}+\mathbf{r_3}=\mathbf{z} x+r3=z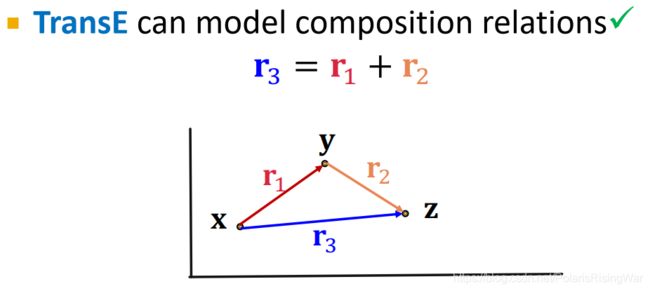
-
TransE:Symmetric Relations ✖ ✖ ✖
欲使 ∣ ∣ h + r − t ∣ ∣ = 0 ||\mathbf{h}+\mathbf{r}-\mathbf{t}||=0 ∣∣h+r−t∣∣=0 和 ∣ ∣ t + r − h ∣ ∣ = 0 ||\mathbf{t}+\mathbf{r}-\mathbf{h}||=0 ∣∣t+r−h∣∣=0 同时成立,需 r = 0 \mathbf{r}=0 r=0 且 h = t \mathbf{h}=\mathbf{t} h=t,但这样把两个实体嵌入到同一点上就没有意义了,所以是不行的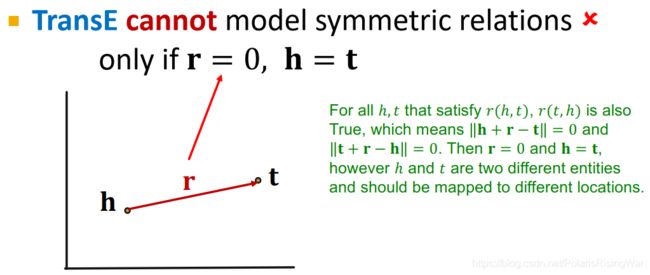
-
TransE:1-to-N Relations ✖ ✖ ✖
欲使 ∣ ∣ h + r − t 1 ∣ ∣ = 0 ||\mathbf{h}+\mathbf{r}-\mathbf{t_1}||=0 ∣∣h+r−t1∣∣=0 和 ∣ ∣ h + r − t 2 ∣ ∣ = 0 ||\mathbf{h}+\mathbf{r}-\mathbf{t_2}||=0 ∣∣h+r−t2∣∣=0 同时成立,需 t 1 = t 2 \mathbf{t_1}=\mathbf{t_2} t1=t2,但这样把两个实体嵌入到同一点上就没有意义了,所以是不行的
-
TransR14
将实体映射为实体空间 R d \mathbb{R}^d Rd 上的向量,关系映射为关系空间上的向量 r ∈ R k \mathbf{r}\in\mathbb{R}^k r∈Rk,且有 relation-specific 的 projection matrix M r ∈ R k × d \mathbf{M}_r\in\mathbb{R}^{k\times d} Mr∈Rk×d
用 projection matrix 将实体从实体域投影到空间域上: h ⊥ = M r h \mathbf{h_\bot}=\mathbf{M}_r\mathbf{h} h⊥=Mrh, t ⊥ = M r t \mathbf{t_\bot}=\mathbf{M}_r\mathbf{t} t⊥=Mrt
scoring function: f r ( h , t ) = − ∣ ∣ h ⊥ + r − t ⊥ ∣ ∣ f_r(h,t)=-||\mathbf{h_\bot}+\mathbf{r}-\mathbf{t_\bot}|| fr(h,t)=−∣∣h⊥+r−t⊥∣∣

-
TransR:Symmetric Relations ✓ \checkmark ✓
使 r = 0 \mathbf{r}=0 r=0, h ⊥ = M r h = M r t = t ⊥ \mathbf{h}_\bot=\mathbf{M}_r\mathbf{h}=\mathbf{M}_r\mathbf{t}=\mathbf{t}_\bot h⊥=Mrh=Mrt=t⊥,即可以使在实体域上不同的 h h h 和 t t t 可以在 r r r 的关系域上相同。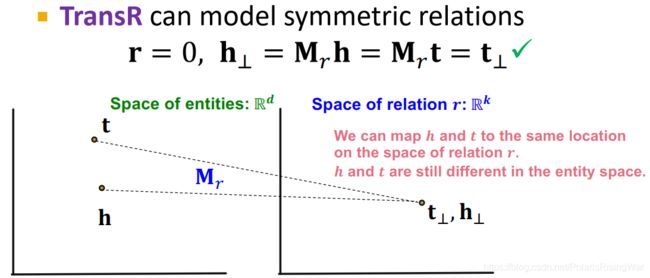
-
TransR:Antisymmetric Relations ✓ \checkmark ✓
r ≠ 0 \mathbf{r}\neq 0 r=0, M r h + r = M r t \mathbf{M}_r\mathbf{h}+\mathbf{r}=\mathbf{M}_r\mathbf{t} Mrh+r=Mrt,则 M r t + r ≠ M r h \mathbf{M}_r\mathbf{t}+\mathbf{r}\not=\mathbf{M}_r\mathbf{h} Mrt+r=Mrh,自然实现要求
-
TransR:1-to-N Relations ✓ \checkmark ✓
可以通过学习合适的 M r \mathbf{M}_r Mr 使 t ⊥ = M r t 1 = M r t 2 \mathbf{t}_\bot=\mathbf{M}_r\mathbf{t}_1=\mathbf{M}_r\mathbf{t}_2 t⊥=Mrt1=Mrt2,即在实体域中不同的 t 1 t_1 t1 和 t 2 t_2 t2 可以在 r r r 的关系域上相同
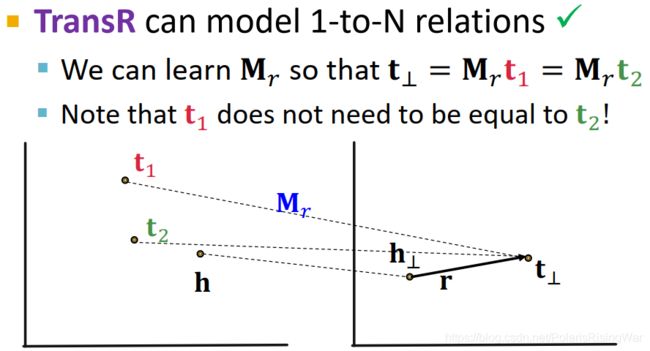
-
TransR:Inverse Relations ✓ \checkmark ✓
使 r 2 = − r 1 \mathbf{r}_2=-\mathbf{r}_1 r2=−r1, M r 1 = M r 2 \mathbf{M}_{r_1}=\mathbf{M}_{r_2} Mr1=Mr2
就能使 M r 1 t + r 1 = M r 1 h \mathbf{M}_{r_1}\mathbf{t}+\mathbf{r}_1=\mathbf{M}_{r_1}\mathbf{h} Mr1t+r1=Mr1h 且 M r 2 h + r 2 = M r 2 t \mathbf{M}_{r_2}\mathbf{h}+\mathbf{r}_2=\mathbf{M}_{r_2}\mathbf{t} Mr2h+r2=Mr2t
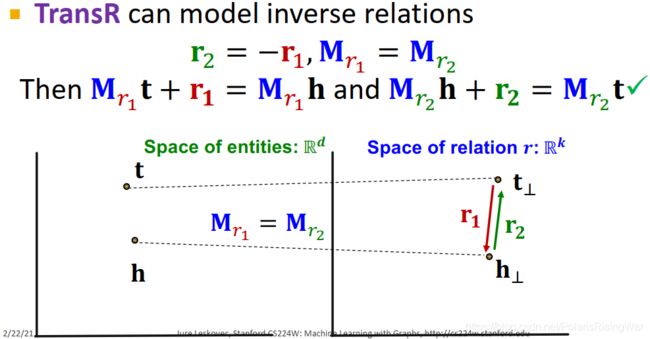
-
TransR:Composition Relations ✖ ✖ ✖
每个关系都有独立的空间域,不能直接自然组合15
-
New Idea: Bilinear Modeling16
在至今学习过的TransE和TransR中,scoring function f r ( h , t ) f_r(h,t) fr(h,t) 都是L1或L2距离的相反数。另一种做法是选用 bilinear modeling16。
DistMult17:实体和关系都表示为 R k \mathbb{R}^k Rk 的向量(在这一点上有点像TransE)
score function: f r ( h , t ) = < h , r , t > = ∑ i h i ⋅ r i ⋅ t i f_r(h,t)=<\mathbf{h},\mathbf{r},\mathbf{t}>=\sum_i\mathbf{h}_i\cdot\mathbf{r}_i\cdot\mathbf{t}_i fr(h,t)=<h,r,t>=∑ihi⋅ri⋅ti(点积)
-
DistMult
score function 可以直觉地被视作 h ⋅ r \mathbf{h}\cdot\mathbf{r} h⋅r 和 t \mathbf{t} t 之间的 cosine similarity18
即,使 h ⋅ r \mathbf{h}\cdot\mathbf{r} h⋅r 和 t \mathbf{t} t 同侧、靠近时,score 较高。
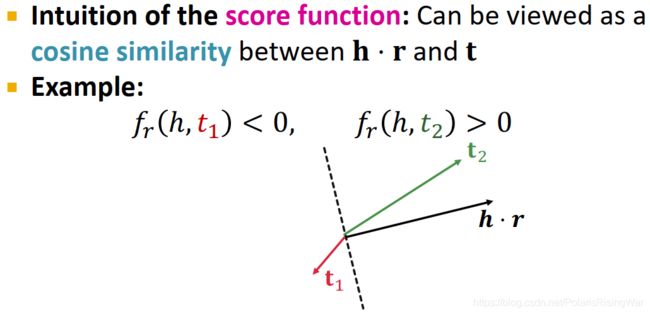
-
DistMult:1-to-N Relations ✓ \checkmark ✓
当知识图谱中存在 ( h , r , t 1 ) (h,r,t_1) (h,r,t1) 和 ( h , r , t 2 ) (h,r,t_2) (h,r,t2) 时,如图所示,DistMult可以建模使 t 1 \mathbf{t}_1 t1 和 t 2 \mathbf{t}_2 t2 在 h ⋅ r \mathbf{h}\cdot\mathbf{r} h⋅r 上的投影等长,即使二者与 h ⋅ r \mathbf{h}\cdot\mathbf{r} h⋅r 的点积相等,即 < h , r , t 1 > = < h , r , t 2 > <\mathbf{h},\mathbf{r},\mathbf{t}_1>=<\mathbf{h},\mathbf{r},\mathbf{t}_2> <h,r,t1>=<h,r,t2>,符合要求
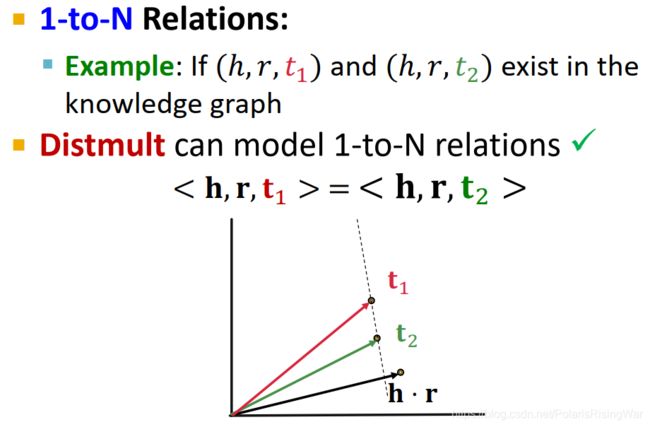
-
DistMult:Symmetric Relations ✓ \checkmark ✓
DistMult天然建模symmetric relations: f r ( h , t ) = < h , r , t > = ∑ i h i ⋅ r i ⋅ t i = < t , r , h > = f r ( t , h ) f_r(h,t)=<\mathbf{h},\mathbf{r},\mathbf{t}>=\sum\limits_i\mathbf{h}_i\cdot\mathbf{r}_i\cdot\mathbf{t}_i=<\mathbf{t},\mathbf{r},\mathbf{h}>=f_r(t,h) fr(h,t)=<h,r,t>=i∑hi⋅ri⋅ti=<t,r,h>=fr(t,h)(乘法交换律)
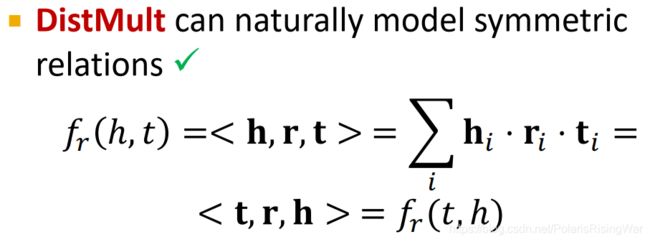
-
DistMult:Antisymmetric Relations ✖ ✖ ✖
f r ( h , t ) = < h , r , t > = < t , r , h > = f r ( t , h ) f_r(h,t)=<\mathbf{h},\mathbf{r},\mathbf{t}>=<\mathbf{t},\mathbf{r},\mathbf{h}>=f_r(t,h) fr(h,t)=<h,r,t>=<t,r,h>=fr(t,h) 永远成立,不符要求

-
DistMult:Inverse Relations ✖ ✖ ✖
如果要建模inverse relations,即使: f r 2 ( h , t ) = < h , r 2 , t > = < t , r 1 , h > = f r 2 ( t , h ) f_{r_2}(h,t)=<\mathbf{h},\mathbf{r_2},\mathbf{t}>=<\mathbf{t},\mathbf{r_1},\mathbf{h}>=f_{r_2}(t,h) fr2(h,t)=<h,r2,t>=<t,r1,h>=fr2(t,h)
必须使 r 2 = r 1 \mathbf{r}_2=\mathbf{r_1} r2=r1,这显然是没有意义的

-
DistMult:Composition Relations ✖ ✖ ✖
DistMult对每个 (head,relation) 定义了一个超平面,对多跳关系产生的超平面的联合(如 ( r 1 , r 2 ) (r_1,r_2) (r1,r2))无法用单一超平面( r 3 r_3 r3)来表示。19

-
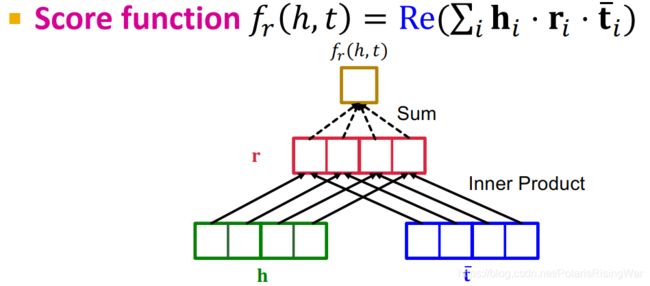
ComplEx20
基于DistMult,ComplEx在 复数向量域complex vector space C k \mathbb{C}^k Ck 中表示实体和关系。
u = a + b i \mathbf{u}=\mathbf{a}+\mathbf{b}\ i u=a+b i(其中 u ∈ C k \mathbf{u}\in\mathbb{C}^k u∈Ck,实部re a ∈ R k \mathbf{a}\in\mathbb{R}^k a∈Rk,虚部im b ∈ R k \mathbf{b}\in\mathbb{R}^k b∈Rk)
u ‾ = a − b i \overline\mathbf{u}=\mathbf{a}-\mathbf{b}\ i u=a−b i(共轭)
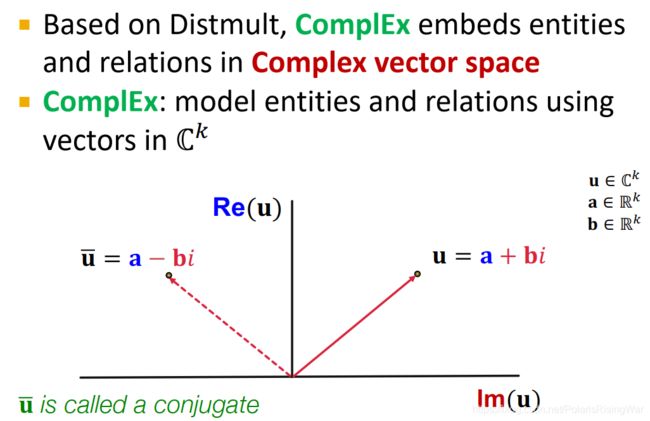
score function: f r ( h , t ) = Re ( ∑ i h i ⋅ r i ⋅ t ‾ i ) f_r(h,t)=\text{Re}(\sum_i\mathbf{h}_i\cdot\mathbf{r}_i\cdot\overline\mathbf{t}_i) fr(h,t)=Re(∑ihi⋅ri⋅ti)21
-
ComplEx:Antisymmetric Relations ✓ \checkmark ✓
ComplEx可以建模使 f r ( h , t ) = Re ( ∑ i h i ⋅ r i ⋅ t ‾ i ) f_r(h,t)=\text{Re}(\sum_i\mathbf{h}_i\cdot\mathbf{r}_i\cdot\overline\mathbf{t}_i) fr(h,t)=Re(∑ihi⋅ri⋅ti) 与 f r ( t , h ) = Re ( ∑ i t i ⋅ r i ⋅ h ‾ i ) f_r(t,h)=\text{Re}(\sum_i\mathbf{t}_i\cdot\mathbf{r}_i\cdot\overline\mathbf{h}_i) fr(t,h)=Re(∑iti⋅ri⋅hi) 不同,因为这一不对称建模使用的是复数共轭。

-
ComplEx:Symmetric Relations ✓ \checkmark ✓
当 Im ( r ) = 0 \text{Im}(\mathbf{r})=0 Im(r)=0 时, f r ( h , t ) = Re ( ∑ i h i ⋅ r i ⋅ t ‾ i ) = ∑ i Re ( r i ⋅ h i ⋅ t ‾ i ) = ∑ i r i ⋅ Re ( h i ⋅ t ‾ i ) = ∑ i r i ⋅ Re ( h ‾ i ⋅ t i ) = ∑ i Re ( r i ⋅ h ‾ i ⋅ t i ) = f r ( t , h ) f_r(h,t)=\text{Re}(\sum_i\mathbf{h}_i\cdot\mathbf{r}_i\cdot\overline\mathbf{t}_i)=\sum_i\text{Re}(\mathbf{r}_i\cdot\mathbf{h}_i\cdot\overline\mathbf{t}_i)=\sum_i\mathbf{r}_i\cdot\text{Re}(\mathbf{h}_i\cdot\overline\mathbf{t}_i)=\sum_i\mathbf{r}_i\cdot\text{Re}(\overline\mathbf{h}_i\cdot\mathbf{t}_i)=\sum_i\text{Re}(\mathbf{r}_i\cdot\overline\mathbf{h}_i\cdot\mathbf{t}_i)=f_r(t,h) fr(h,t)=Re(∑ihi⋅ri⋅ti)=∑iRe(ri⋅hi⋅ti)=∑iri⋅Re(hi⋅ti)=∑iri⋅Re(hi⋅ti)=∑iRe(ri⋅hi⋅ti)=fr(t,h)
符合要求

-
ComplEx:Inverse Relations ✓ \checkmark ✓
已知 r 2 = arg max r Re ( < h , r , t ‾ > ) \mathbf{r}_2=\argmax\limits_\mathbf{r}\text{Re}(<\mathbf{h},\mathbf{r},\overline\mathbf{t}>) r2=rargmaxRe(<h,r,t>)
欲知 r 1 = arg max r Re ( < t , r , h ‾ > ) \mathbf{r}_1=\argmax\limits_\mathbf{r}\text{Re}(<\mathbf{t},\mathbf{r},\overline\mathbf{h}>) r1=rargmaxRe(<t,r,h>)
当 r 1 = r ‾ 2 \mathbf{r}_1=\overline\mathbf{r}_2 r1=r2 即 r 2 \mathbf{r}_2 r2 的共轭正是 r 1 \mathbf{r}_1 r1 时,满足要求。

-
ComplEx:Composition Relations ✖ ✖ ✖ 1-to-N Relations ✓ \checkmark ✓
和DistMult一样 -
所有模型的表示能力对比:

-
知识图谱嵌入问题的实践应用22
- 不同知识图谱可能会有很不同的关系模式
- 因此没有适合所有KG的嵌入方法,可用上表来辅助选择
- 可以先试用TransE来迅速获得结果(如果目标KG没有过多symmetric relations的话)
- 然后再用更有表示能力的模型,如ComplEx或RotatE22(复数域的TransE)等

-
总结
- 链接预测或图补全任务是知识图谱领域的重要研究任务
- 介绍了不同嵌入域和不同表示能力的模型
- TransE
- TransR
- DistMult
- ComplEx
Schlichtkrull et al., Modeling Relational Data with Graph Convolutional Networks, ESWC 2018 ↩︎
可参考我写的前几节课的笔记博文 ↩︎
说起来这个RGCN是有自环的啊,但是前几节课我看GCN是没算自环的啊?所以到底要不要自环啊? ↩︎
其实我没太看懂这句话啥意思。
很容易理解的是,就是这样的话,每次使用权重矩阵时,只有相邻嵌入(对角块同一行上非0元素索引对应的嵌入维度)能与权重矩阵的元素进行运算、学习(交互)。所以这又能咋样……这有啥不好之处吗?
另外就是,说这个维度是神经元……虽然我想了一下好像按照神经网络的逻辑,就是神经元,但总感觉很奇怪……说起来GNN就是跟传统神经网络好不一样啊,真的可以套用吗? ↩︎可参考我之前写的博文:cs224w(图机器学习)2021冬季课程学习笔记10 Applications of Graph Neural Networks ↩︎
这个 f f f 是 双线性型bilinear form16 ↩︎
这个获得negative edges的方法是必须要改supervision edge来吗,还是别的任意一条在training message edge和training supervision edge中不存在的该关系对应的边都可以?改supervision edge的唯一方法是改destination节点吗?这部分我还没搞懂。
我一开始还在考虑其他关系的边怎么处理,但是看到例子中存在其他关系的边也可以被认为是negative edges,大概就是不管其他关系了吧。
我一开始另外也考虑了是否需要避开validation edge和test edge吗,但是我看例子里面就没管它们,所以应该不影响。 ↩︎交叉熵相关讲解可参考我之前写的博文:cs224w(图机器学习)2021冬季课程学习笔记7 Graph Neural Networks 1: GNN Model
我看了一下这个公式,我能理解优化这个公式能达到所要求的效果,但是为什么就能这样搞?我就没搞懂。 ↩︎但其实就是我不太确定schema是不是就是这个东西 ↩︎
毕竟不是我的学科领域,所以我就简单百度了一下,知道这是个专业术语就完了。欲了解详情可以百度。我给出的参考资料是这篇帖子:题外话——生物学中的pathway - 分子生物 - 生物化学 - 小木虫论坛-学术科研互动平台 ↩︎
slides中给出的参考文献:
①Paulheim, Heiko. “Knowledge graph refinement: A survey of approaches and evaluation methods.” Semantic web 8.3 (2017): 489-508.
这一篇论文我没找到直接的PDF下载地址,就从道客巴巴上下了一个,放在了我自己的GitHub项目上:all-notes-in-one/Knowledge graph refinement.pdf at main · PolarisRisingWar/all-notes-in-one
②Min, Bonan, et al. “Distant supervision for relation extraction with an incomplete knowledge base.” Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2013. ↩︎可参考我之前写的博文:cs224w(图机器学习)2021冬季课程学习笔记3: Node Embeddings ↩︎
Bordes, et al., Translating embeddings for modeling multi-relational data, NeurIPS 2013 ↩︎
Lin, et al., Learning entity and relation embeddings for knowledge graph completion, AAAI 2015
呃……但是这个AAAI的网址,不知道为什么我上不了,是因为墙?但是这个网站有什么好墙的?等我能使用特殊手段再研究吧,反正现在也不需要看这篇论文 ↩︎这个我也没看懂……各个关系向量不在一个空间,这个我就不太理解,它们不都是同一维度( R k \mathbb{R}^k Rk)上的向量吗?只因为投射矩阵M不同吗?
就我能理解对于同一实体来说,不同的关系会将其映射到不同的位置上……但是,所以呢?
slides上说是因为这个在x-y,y-z关系中的y所组成的流形(这又是个什么东西?)集合是高维的,无法用单一关系和关系矩阵来建模……啥意思? ↩︎到底什么他妈的是双线性型?数学怎么就这么难啊? ↩︎ ↩︎ ↩︎
Yang et al, Embedding Entities and Relations for Learning and Inference in Knowledge Bases, ICLR 2015 ↩︎
就很明显是点积嘛。
但我还是没搞懂这为啥就是余弦相似度了?就同质图那边讲相似性问题的时候我就没搞懂,点积和余弦相似度之间不是差个模长吗?模长呢?有说这几个向量的模长都是1吗还是咋整了?
这种细节我寻思可能还是得看看相应的代码,看看相应的实践上的处理方式。假如我能看得懂的话,我再回来写解释。 ↩︎这他妈是什么东西啊,完全没看懂(〃>皿<)
就是,硬要讲这个超平面的话,我能理解,就是与 h e a d ⋅ r e l a t i o n \mathbf{head}\cdot\mathbf{relation} head⋅relation 相正交的那个超平面吧?
然后两个超平面合起来不一定是一个超平面,就,这怎么合啊!
然后我就没搞懂别的在说啥了。 ↩︎Trouillon et al, Complex Embeddings for Simple Link Prediction, ICML 2016 ↩︎
就,大概是囿于我复数知识的严重匮乏吧,ComplEx的自此以下所有公式我都没搞懂。
就,复数的共轭和实部能干这么多事呢???这就是我的感觉。
我看不懂,但我大受震撼。 ↩︎Sun et al, RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space, ICLR 2019 ↩︎ ↩︎