c# Winform中使用NHibernate的配置
NHibernate知识要点记录
- 1、NHibernate的引用
-
- 1.1、关于NHibernate学习可以参考的几个网址
- 1.2、在winform项目中引用NHibername
- 2、NHibernate的项目配置
-
- 2.1、在app.config(或web.config)中配置NHibernate的数据库连接信息
- 2.2、获取单例模式的ISessionFactory
- 2.3、单例工厂模式的NHibernateHelper类
- 3、持久化类及映射文件配置
-
- 3.1、持久化类及映射文件的配置
- 3.2、实现数据库中数据的CRUD小例子
- 3.3、persistent 类的三种状态
- 3.4、实现NHibernate编写XML配置文件的智能提示
- 3.5、Mapping 文件(hbm.xml)说明
-
- 3.5.1、 hibernate-mapping元素
- 3.5.2、class 元素(对应一个数据表)
- 3.5.3、id子元素(对应主键列)
- 3.5.4 、generator子元素
- 3.5.5、discriminator子元素(对应数据表中一列)
- 3.5.6、version (optional)元素(对应版本号列)
- 3.5.7、property元素(对应数据表中一列)
- 3.5.8、many-to-one
- 3.5.9、one-to-one
- 3.5.10、subclass元素
- 3.5.11、key元素
- 3.6、持久化类中集合定义
-
- 3.6.1、持久化类中集合的定义
- 3.6.2、持久化类中集合的映射
- 4、Hibernate的继承映射策略
-
- 4.1、单表继承
- 4.2、类表映射
- 4.3、具体表映射
- 4.4、隐式多态
- 5、NHibernate查询语言(HQL)
-
- 5.1、from子句
-
- 5.1.1、简单用法
- 5.1.2、使用别名
- 5.1.3、笛卡尔积
- 5.2、select子句
-
- 5.2.1、简单用法
- 5.2.2、数组
- 5.2.3、统计函数
- 5.2.4、.Distinct用法
- 5.3、where子句
- 5.4、order by子句
- 5.5、group by子句
- 5.6、实例分析
- 6、常用数据表关联关系的mapping配置及CURD实现例子
-
- 6.1、一对多及多对一的例子
- 7、一些问题记录
-
- 7.1、产生no persister for:×××.×× 错误三种常见的原因。
- 7.2、设置一个持久化类的一个只读属性
- 7.3、一对多实现主从表级联插入时设置
- 7.4、性能调优之Lazy与Fetch
1、NHibernate的引用
1.1、关于NHibernate学习可以参考的几个网址
NHibernate的快速上手指引:https://nhibernate.info/doc/nhibernate-reference/quickstart.html
NHibernate开源项目:https://sourceforge.net/projects/nhibernate/files/NHibernate/
1.2、在winform项目中引用NHibername
新建winform项目后,右击项目中的引用选择管理NuGet程序包,搜索NHibernate,然后安装即可。
这里需要注意一点,如果使用的是MS SqlServer 是不需要安装数据库驱动的系统自带了,如果是其他类型数据库需要安装数据库的驱动引用。
2、NHibernate的项目配置
2.1、在app.config(或web.config)中配置NHibernate的数据库连接信息
<configuration>
<configSections>
<section name="hibernate-configuration" type="NHibernate.Cfg.ConfigurationSectionHandler, NHibernate"/>
configSections>
<hibernate-configuration xmlns="urn:nhibernate-configuration-2.2">
<reflection-optimizer use="false" />
<session-factory name="sqlserver">
<property name="connection.provider">NHibernate.Connection.DriverConnectionProviderproperty>
<property name="connection.driver_class">NHibernate.Driver.Sql2008ClientDriverproperty>
<property name="dialect">NHibernate.Dialect.MsSql2008Dialectproperty>
<property name="connection.connection_string">
Data Source=192.168.1.31;Initial Catalog=SaleNew;User ID=sa;Password=7048461
property>
<property name="connection.isolation">ReadCommittedproperty>
<property name="default_schema">dboproperty>
<property name="use_outer_join">trueproperty>
<property name="hbm2ddl.auto">noneproperty>
<property name="show_sql">trueproperty>
<mapping assembly="TestNHibernate" />
session-factory>
hibernate-configuration>
configuration>
关于ISessionFactory配置这里给一个参考说明传送门
并发控制
更多参考
- NHibernate配置所支持的属性
| 属性名 | 用途 |
|---|---|
| dialect | 设置NHibernate的Dialect类名 - 允许NHibernate针对特定的关系数据库生成优化的SQL 可用值: full.classname.of.Dialect, assembly |
| default_schema | 在生成的SQL中, 将给定的schema/tablespace附加于非全限定名的表名上. 可用值: SCHEMA_NAME |
| use_outer_join | 允许外连接抓取,已弃用,请使用max_fetch_depth 可用值: true 、false |
| max_fetch_depth | 为单向关联(一对一, 多对一)的外连接抓取(outer join fetch)树设置最大深度. 值为0意味着将关闭默认的外连接抓取 可用值:建议在0 到3之间取值。 |
| use_reflection_optimizer | 开启运行时代码动态生成来替代运行时反射机制(系统级属性). 使用这种方式的话程序在启动会耗费一定的性能,但是在程序运行期性能会有更好的提升. 注意即使关闭这个优化, Hibernate还是需要CGLIB. 你不能在hibernate.cfg.xml中设置此属性. 这个属性不能在hibernate.cfg.xml或者是应用程序配置文件hibernate-configuration 配置节中设置。 可用值: true、 false |
| bytecode.provider | 指定字节码provider用于优化NHibernate反射性能。 null代表完全关闭性能优化, lcg用于轻量级的代码动态生成,codedom基于CodeDOM代码动态生成。 可用值: null 、 lcg 、codedom |
| show_sql | 输出所有SQL语句到控制台. 可用值: true、 false |
| hbm2ddl.auto | 在ISessionFactory创建时,自动检查数据库结构,或者将数据库schema的DDL导出到数据库. 使用 create-drop时,在显式关闭ISessionFactory时,将drop掉数据库schema. 可用值: create、 create-drop |
详细的属性配置可以参考这个文章。
2.2、获取单例模式的ISessionFactory
数据库的ISessionFactory比较昂贵,单例模式获取一个就可以,下面给出三种常用获取ISessionFactory的方式。
- 这种配置方法将会到应用程序配置文件(App.Config,Web.Config)中查找NHibernate的配置信息,NHibernate的配置节必须符合应用程序配置文件个格式
var configuration = new Configuration();
//加载映射文件,它们用来把POCOs映射到持久化数据库对象
//加载指定程序集内的持久话类和映射文件
configuration.AddAssembly(typeof(Location).Assembly);
//创建会话工厂
ISessionFactory _sessionFactory = configuration.BuildSessionFactory();
- 这种配置方法将会在应用的相同目录查找名为”hibernate.cfg.xml”的标准Hibernate配置
var configuration = new Configuration();
configuration.Configure();
//创建会话工厂
ISessionFactory _sessionFactory = configuration.BuildSessionFactory();
可以将App.config删除,新建hibernate.cfg.xml文件
<hibernate-configuration xmlns="urn:nhibernate-configuration-2.0" >
<session-factory name="MySessionFactory">
<property name="connection.provider">NHibernate.Connection.DriverConnectionProviderproperty>
<property name="connection.driver_class">NHibernate.Driver.SqlClientDriverproperty>
<property name="connection.connection_string">Server=.;initial catalog=NHB;User id=sa;password=1234;property>
<property name="show_sql">falseproperty>
<property name="dialect">NHibernate.Dialect.MsSql2000Dialectproperty>
<mapping assembly="NHB" />
session-factory>
hibernate-configuration>
如果自定义名为Users.cfg.xml配置文件,则需要用下面的语句:
var configuration = new Configuration();
configuration.Configure("Users.cfg.xml");
//添加指定mapping文件
configuration.AddXmlFile("Users.hbm.xml");
//创建会话工厂
ISessionFactory _sessionFactory = configuration.BuildSessionFactory();
将hibernate.cfg.xml,Users.cfg.xml的属性"复制到输出目录"改为"始终复制"
- 这种配置方法将查找指定的Hibernate标准配置文件,可以是绝对路径或者相对路径
Configuration cfg = new Configuration().Configure("hibernate.cfg.xml");
如果一个项目加载多个数据库,则就可以使用上面配置程序进行多数据库会话工厂的生成
2.3、单例工厂模式的NHibernateHelper类
/// 3、持久化类及映射文件配置
3.1、持久化类及映射文件的配置
- 先定义一个持久化的类
public class Location
{
public virtual int id { get; set; }
public virtual int EmpId { get; set; }
public virtual DateTime Date { get; set; }
public virtual string Content { get; set; }
}
注意属性都是virtual的定义的。
- 配置一个mapping文件,这个文件的命名规则是
类名.hbm.xml,如上面Location类的配置文件名称就是Location.hbm.xml
Location.hbm.xml内容如下:
<hibernate-mapping xmlns="urn:nhibernate-mapping-2.2" assembly="TestNHibernate" namespace="TestNHibernate.mapping.pojo">
<class name="Location" table="Log" lazy="true">
<id name="id" column="FInterID">
<generator class="identity">generator>
id>
<property name="EmpId" type="int" column="FEmpID" not-null="true">property>
<property name="Date" type="DateTime" column="FDate" not-null="true">property>
<property name="Content" type="string" column="FContent" length="100" not-null="true">property>
class>
hibernate-mapping>
在这个配置文件中 name、type属性对应的是类或字段的名字及类型,table、column对应的是类或字段在数据库中对应的名称。
3.2、实现数据库中数据的CRUD小例子
向数据库保存一条记录。
Location l = new Location() {EmpId=1,Date=DateTime.Now, Content="测试1"};
using (var session = SessionFactory.OpenSession())
{
using (ITransaction tx = session.BeginTransaction())
{
session.Save(l);
tx.Commit();
}
}
下面的代码替换到上面例子中事务提交前实现删除和更新。
//删除
session.Delete(t);
//更新
session.Update(t);
3.3、persistent 类的三种状态
在程序运行过程中,使用对象的方式操作数据库的同时,必然会产生一系列的持久化对象。这些对象可能是刚刚创建并准备进行存储的,也有可能是从数据库进行查询得到的,为了区别这些对象,根据对象和当前Session的关联状态,可以将对象分为三种:
- transient
瞬时对象,对象刚刚建立,该对象没有在数据库中进行存储,也没有在ISession的缓存中。如果该对象的主键是自动创建的,则此时对象的标识符为空 - persistent
持久化对象,对象已经通过Nhibernate进行了持久化,数据库中已经存在了该对象的记录。如果该对象自动创建主键,则此时对象的标识符已被赋值,对于这种状态的修改会直接改变缓存及数据库中数据 - detached
托管对象,该对象已经通过NHIbernate保存或者从数据库中查询取出的,但与此对象关联的ISession已经关闭。虽然它存在对象标识符,且在数据库中也有对应的记录,但已经不被Nhibernate管理的
下面给出几个例子理解一下
- 创建瞬时态(Transient)
对象刚刚创建,还没有来及和ISession关联的状态。这时瞬时对象不会被持久化到数据库中,也不会被赋上标识符。如果不使用则被GC销毁。ISession接口可以将其转换为持久状态。
例如:刚刚创建一个Customer对象,就是一个瞬时态的对象。
//瞬时态对象,只建立了没有向数据库中插入
var customer = new Customer()
{
ID = Guid.NewGuid(),
Name Address = new Name()
{
Address="北京",
Name="wolfy"
},
Orders=null,
Version=1
};
- 瞬时态转持久态
ISession session = NHibernateHelper.GetSession();
if (!session.Contains(customer))
{
//关联ISession保存到数据库中
session.Save(customer);
}
//变为持久态,由于表中Id字段自动增长的(如果是自动增长主键),保存数据库,Id字段自动加一
//经过NHibernate类型转换后返回Id属性值,保证数据库与实例对象同步
if (session.Contains(customer))
{
}
- 持久态转托管态
//得到session
ISession session = NHibernateHelper.GetSession();
//根据id得到customer对象
var customer = session.Get("Customer", new Guid("DDF637501-33071-4611B-B96A1-7FF356540CB81"));
//如果包含customer对象则删除
if (session.Contains(customer))
{
session.Evict(customer);
}
或ISession.Close():关闭当前ISession后持久态对象自动变成托管态。
- 脱管态转换为持久态
//得到session
ISession session = NHibernateHelper.GetSession();
//根据id得到customer对象
Customer customer = session.Get("Customer", new Guid("DDF637501-33071-4611B-B96A1-7FF356540CB81")) as Customer;
//重新设置ISession
NHibernateHelper.ResetSession();
//脱管态对象
//在脱管态下可继续被修改
if (session.Contains(customer))
{
customer.NameAddress = new Name() { CustomerAddress="上海", CustomerName="wolfy"};
//转变为持久态对象
session.Update(customer);
}
通过上面的例子可以看出:在托管时期的修改会被持久化到数据库中;
注意:NHibernate如何知道重新关联的对象是不是“脏的(修改过的)”?如果是新的ISession,ISession就不能与对象初值来比较这个对象是不是“脏的”,我们在映射文件中定义元素和元素的unsaved-value属性,NHibernate就可以自己判断了。
如果加上一个锁:如果在托管时期没有修改,就不执行更新语句,只转换为持久态,下面的例子如果在托管时期修改对象,执行更新语句。
//得到session
ISession session = NHibernateHelper.GetSession();
//根据id得到customer对象
Customer customer = session.Get("Customer", new Guid("DDF637501-33071-4611B-B96A1-7FF356540CB81")) as Customer;
if (session.Contains(customer))
{
NHibernateHelper.ResetSession();
}
//锁
session.Lock(customer, NHibernate.LockMode.None);
//如果在托管时期没有修改,就不执行更新语句,只转换为持久态
session.Update(customer);
需注意Lock锁的使用,需要保证customer对象不为null,这里为了测试方便就没加上判断。如果为null会有异常(attempt to lock null)。
方法二:ISession.Merge():合并指定实例。不必考虑ISession状态,ISession中存在相同标识的持久化对象时,NHibernate便会根据用户给出的对象状态覆盖原有的持久化实例状态。
方法三:ISession.SaveOrUpdate():分配新标识保存瞬时态对象;更新/重新关联脱管态对象。
3.4、实现NHibernate编写XML配置文件的智能提示
实现智能提示有两个方法,第一种是使用NuGet安装NHibernate的形式
- 在项目解决方案的根目录中打开packages\NHibernate.X.X.X路径,然后将nhibernate-configuration.xsd和nhibernate-mapping.xsd文件复制到VS IDE的安装路径下的Xml目录下的Schemas目录中。
我安装的是2022社区版,安装路径如下:
C:\Program Files\Microsoft Visual Studio\2022\Community\Xml\Schemas
另一种是
- 手动下载NHibernate压缩包后,解压缩将Required_Bins目录中的nhibernate-configuration.xsd和nhibernate-mapping.xsd文件复制到VS IDE的安装路径下的Xml目录下的Schemas目录中。
- nhibernate的下载地址是https://nhibernate.info/
这里强调一下无论是手动下载还是NuGet方式安装的NHibernate,在它的目录中都存在一个ConfigurationTemplates文件夹,这里面有所有数据库链接配置模板,可以自己复制出来直接使用
3.5、Mapping 文件(hbm.xml)说明
本小结针对实体类映射文件(xxx.hbm.xml)各个元素在这里插入代码片进行讲解,由于之前已经写完但是保存的时候没保存上,这里就只摘抄原文不进行讲解记录了
3.5.1、 hibernate-mapping元素
-mapping
schema="schemaName" (1)
catalog="catalogName" (2)
default-cascade="none|save-update..." (3)
auto-import="true|false" (4)
assembly="Eg" (5)
namespace="Eg" (6)
default-access="field|property|field.camelcase..."(7)
default-lazy="true|false" (8)
/>
- (1) schema (可选的): 数据库 schem名.
- (2) catalog (可选的l): 数据库 catalog名.
- (3) default-cascade (可选的 - 默认值 none): 默认级联类型.
- (4) auto-import (可选的 - 默认值 true): 指定是否可以在查询语言的此映射中使用类的非限定类名,如果是false则需要在查询中使用全限定类名(程序集.命名空间.类名)
如果有两个具有相同(非限定)名称的持久性类,则应设置 auto-import=‘false’。如果尝试将两个类分配给相同的’导入’名称,则 NHibernate 将引发异常 - (5)(6) assembly and namespace (可选的): 指定当前持久化类的所属程序集及命名空间
如果不使用程序集和命名空间属性,则必须在name属性中指定完全限定的类名,包括在其中声明类的程序集的名称 - (7) default-access (可选的 - 默认值 property): NHibernate 应用于访问属性值的策略。它可以是 IPropertyAccessor 的自定义实现.
- (8) default-lazy (可选的 - 默认值 true): 默认开启lazy加载模式.
hibernate-mapping元素允许您嵌套多个持久性
3.5.2、class 元素(对应一个数据表)
-value="discriminatorValue" (3)
mutable="true|false" (4)
schema="owner" (5)
catalog="catalog" (6)
proxy="proxyInterface" (7)
dynamic-update="true|false" (8)
dynamic-insert="true|false" (9)
select-before-update="true|false" (10)
polymorphism="implicit|explicit" (11)
where="arbitrary sql where condition" (12)
persister="persisterClass" (13)
batch-size="N" (14)
optimistic-lock="none|version|dirty|all" (15)
lazy="true|false" (16)
abstract="true|false" (17)
entity-name="entityName" (18)
check="arbitrary sql check condition" (19)
subselect="SQL expression" (20)
schema-action="none|drop|update|export|validate|all|commaSeparatedValues" (21)
rowid="unused" (22)
node="unused" (23)
/>
- (1) name: 持久化类名或接口名称,如果hibernate-mapping元素中auto-import设置为false,则这个名称需要填写全限定名(程序集.命名空间.类名(接口名)).
- (2) table(可选的- 默认值 非限定类名): 对应的数据库表名.
- (3) discriminator-value (可选的,默认值 类名): 区分各个子类的值,用于多态行为。可接受的值包括null和非空值.
- (4) mutable (可选的 - 默认值 true): 指定实例类是否可变.
- (5) schema (optional): 重写根元素
- (6) catalog (optional):重写 根元素
- (7) proxy (optional): 指定用于lazy初始化代理的接口。您可以指定类本身的名称.
- (8) dynamic-update (optional - defaults to false): 指定在运行时生成 UPDATE SQL语句,且只包含值已更改的列.
如果启用动态更新,则可以选择乐观锁定策略:
version检查版本/时间戳列
all 检查所有列
dirty 检查已更改的列
none不使用乐观锁定 - (9) dynamic-insert (optional - defaults to false): 指定在运行时生成 INSERT SQL语句,且仅包含值不为 null 的列.
- (10) select-before-update (optional - defaults to false): 在持久化对象值被修改情况下才执行 SQL UPDATE语句,这意味着 NHibernate 将执行额外的 SQL SELECT 来确定是否确实需要 UPDATE.
- (11) polymorphism (optional - defaults to implicit): 确定是使用隐式(implicit)查询多态性还是显式(explicit)查询多态性.
- (12) where (optional) :指定在检索此类的对象时要使用的 SQL WHERE 条件.
- (13) persister (optional): 指定自定义 IClassPersister.
- (14) batch-size (optional - defaults to 1):指定每次通过标识符批量获取此类的 “batch size” 容量.
- (15) optimistic-lock (optional - defaults to version): 确定乐观锁定策略.
version检查版本/时间戳列
all 检查所有列
dirty 检查已更改的列
none不使用乐观锁定
从NHibernate 1.2.0开始,version以 1 开始,而不是像以前版本那样以 0 开头 - (16) lazy (optional - defaults to true): 可以通过设置 lazy=‘false’ 来禁用延迟加载模式.
- (17) abstract (optional - defaults to false):用于标记
- (18) entity-name (optional - defaults to the class name): NHibernate 允许将一个类映射多次,可能映射到不同的表.
- (19) check (optional): 用于为自动架构生成生成多行检查约束的 SQL 表达式.
- (20) subselect (optional): 将不可变的只读实体映射到数据库子选择。如果要使用视图而不是基表,这将非常有用
将类映射到表或视图列的替代方法是映射查询。为此,我们使用
>
<![CDATA[
SELECT cat.ID, cat.NAME, cat.SEX, cat.MATE FROM cat
]]>
>
通常,在使用 subselect 映射查询时,您需要将类标记为不可可变(mutable=‘false’),除非您指定自定义 SQL 来执行 UPDATE、DELETE 和 INSERT 操作
- (21) schema-action (optional):指定架构导出工具应为类表生成哪些架构操作。有效值为none, drop, update, export, validate, all以及它们的任何组合,以逗号 (,) 分隔.
- (22)(23) rowid and node (optional): 这些属性在NHibernate中没有用法.
命名的持久化类作为接口是完全可以接受的。然后,您将使用
这里注意一下,下面要将讲解到的元素好多属性都是可以覆盖class元素中属性值的,还有一部分属性值得意义和class元素中相同,下面表述中重复的属性名就不翻译了
3.5.3、id子元素(对应主键列)
-value="any|none|null|undefined|idValue" (5)
access="field|property|nosetter|className" (6)
generator="generatorClass"> (7)
>
>
- (1) name (optional): 持久化类主键标识属性名称.
如果缺少 name 属性,则假定该类没有标识符属性 - (2) type (optional): 数据表中主键对应持久化类属性的类型.
- (3) length (optional): 长度.
- (4) column (optional - defaults to the property name): 数据表中主键列名.
- (5) unsaved-value (optional - defaults to a “sensible” value): 一个标识符属性值,指示实例是新实例化(unsaved)的,将其与在上一个会话中保存或加载的暂时性实例区分开来.
- (6) access (optional - defaults to property): The strategy NHibernate should use for accessing the property value.
- (7) generator: 用于为持久性类的实例生成唯一标识符的生成器类的名称.
如果同时指定了generator属性,然后又在id元素中指定了generator元素,那么属性优先级高于元素中设置值。
使用
3.5.4 、generator子元素
可以使用元素传递这些参数
>
>
>uid_table>
>next_hi_value_column>
>
>
如果不需要任何参数,则可以直接在
>
下面罗列了一些常用的主键生成方式:
(1) assigned
主键由外部程序负责生成,无需NHibernate参与。
(2) hilo
通过hi/lo 算法实现的主键生成机制,需要额外的数据库表保存主
键生成 历史状态。
(3) seqhilo
与hilo 类似,通过hi/lo 算法实现的主键生成机制,只是主键历史
状态保存在Sequence中,适用于支持Sequence的数据库,如Oracle。
(4) increment
主 键按数值顺序递增。此方式的实现机制为在当前应用实例中维持
一个变量,以保存着当前的最大值,之后每次需要生成主键的时候
将此值加1作为 主键。
这种方式可能产生的问题是:如果当前有多个实例访问同一个数据
库,那么由于各个实例各自维护主键状态,不同实例可能生成同样
的 主键,从而造成主键重复异常。因此,如果同一数据库有多个实
例访问,此方式必须避免使用。
(5) identity
采用数据库提供的主键生成机制。如DB2、SQL Server、MySQL
中的主键 生成机制。
(6) sequence
采用数据库提供的sequence 机制生成主键。如Oralce 中的
Sequence。
(7) native
由 NHibernate根据底层数据库自行判断采用identity、hilo、sequence
其中一种作为主键生成方式。) uuid.hex
由 Hibernate基于128 位唯一值产生算法生成16 进制数值(编码后
以长度32 的字符串表示)作为主键。
(8) foreign
使用外部表的字段作为主键。
关于更详细的主键生成策略,可以参见https://nhibernate.info/doc/nhibernate-reference/mapping.html#google_vignette
3.5.5、discriminator子元素(对应数据表中一列)
假设一个灵长动物表,这个表存储所有灵长动物数据,其中有一列用来区分是哪种动物的,比如值M代表猴子,P代表人,那么这个区分列就是一个discriminator元素的映射列。
我们在
-null="true|false" (4)
force="true|false" (5)
insert="true|false" (6)
formula="arbitrary SQL expression" (7)
/>
- (1) column (optional - defaults to class): 对应的数据表中列名.
- (2) type (optional - defaults to String): 持久化类中对应字段的类型,只能是String, Char, Int32, Byte, Short, Boolean, YesNo, TrueFalse
- (3) length (optional):长度.
- (4) not-null (optional - defaults to true):数据列是否可为null.
- (5) force (optional - defaults to false): 是否强制约束检查.
仅当表包含具有未映射到持久性类的’额外’鉴别器(区分)值的行时,force 属性才有用 - (6) insert (optional - defaults to true):是否可以插入值,如果鉴别器列也是映射的复合标识符的一部分,则将其设置为 false.
- (7) formula (optional):设置sql表达式返回区分值
, 'b', 'c') then 0 else 1 end"
type="Int32"/>
3.5.6、version (optional)元素(对应版本号列)
|property|nosetter|className" (4)
unsaved-value="null|negative|undefined|value" (5)
generated="never|always" (6)
insert="false|true" (7)
/>
- (1) column (optional - defaults to the property name): 数据表version列名.
- (2) name: 持久化类中版本号列对应的属性名.
- (3) type (optional - defaults to Int32): Int64、 Int32、 Int16、 Ticks、 Timestamp、 TimeSpan、 datetimeoffset, …(或 .NET 2.0 及更高版本中的可为空对应项)。任何实现 IVersionType 的类型都可以用作版本.
- (4) access (optional - defaults to property): The strategy NHibernate should use for accessing the property value.
- (5) unsaved-value (optional - defaults to a “sensible” value): A version property value that indicates that an instance is newly instantiated (unsaved), distinguishing it from transient instances that were saved or loaded in a previous session. undefined specifies that nothing should be assumed from the version property. The identifier check on its own unsaved-value will take precedence, unless its own value is undefined.
- (6) generated (optional - defaults to never): never表示给定的属性值不会在数据库中生成、insert 表示给定的属性值在插入时生成,但在后续更新时不会重新生成。像创建日期这样的东西就属于这一类。请注意,即使版本和时间戳属性可以标记为已生成,此选项也不适用于它们、always 声明属性值在插入和更新时生成.
- (7) insert (optional - defaults to false): 此属性在 NHibernate 中没有用法.
3.5.7、property元素(对应数据表中一列)
|false" (4)
insert="true|false" (4)
formula="arbitrary SQL expression" (5)
access="field|property|className" (6)
optimistic-lock="true|false" (7)
generated="never|insert|always" (8)
lazy="true|false" (9)
lazy-group="groupName" (10)
not-null="true|false" (11)
unique="true|false" (12)
unique-key="uniqueKeyName" (13)
index="indexName" (14)
length="L" (15)
precision="P" (16)
scale="S" (17)
/>
- (1) name: 持久化类中属性名.
- (2) column (optional - defaults to the property name):数据表中列名.
- (3) type (optional):持久化列中属性对应的类型,可以是以下范围:
NHibernate基本类型的名称(例如。Int32, String, Char, DateTime, Timestamp, Single, Byte[], Object, …)、具有默认基本类型的 .NET 类型的名称(例如。System.Int16, System.Single, System.Char, System.String, System.DateTime, System.Byte[], …)以及自定义的一些类型.请注意,您必须为除基本类型之外的所有类型指定完整的程序集限定名称(除非您设置了 - (4) update, insert (optional - defaults to true): 指定映射的列应包含在 SQL UPDATE 和 INSERT 语句中。将两者都设置为 false 则这个列的值只能是其他列初始化时生成的.
- (5) formula (optional): 使用sql表达式计算属性值.计算属性没有自己的列映射
*p.price) FROM LineItem li, Product p
WHERE li.productId = p.productId
AND li.customerId = customerId
AND li.orderNumber = orderNumber )"/>
-
(6) access (optional - defaults to property): the strategy NHibernate should use for accessing the property value.
-
(7) optimistic-lock (optional - defaults to true): 指定对此属性的更新是否需要获取乐观锁。.
-
(8) generated (optional - defaults to never): never表示给定的属性值不会在数据库中生成、insert 表示给定的属性值在插入时生成,但在后续更新时不会重新生成。像创建日期这样的东西就属于这一类。请注意,即使版本和时间戳属性可以标记为已生成,此选项也不适用于它们、always 声明属性值在插入和更新时生成.
-
(9) lazy (optional - defaults to false): 指定此属性是lazy的。最初加载对象时,不会加载lazy属性,除非在特定查询中重写了读取模式。延迟属性的值按lazy-group加载.
-
(10) lazy-group (optional - defaults to DEFAULT): if the property is lazy, its lazy-loading group. When a lazy property is accessed, the other lazy properties of the lazy group are also loaded with it.
-
(11) not-null (optional - defaults to false): 数据表该列是否可为null.
-
(12) unique (optional - defaults to false): 该列是否唯一.
-
(13) unique-key (optional): 用于 DDL 生成的unique index的逻辑名称.
-
(14) index (optional): 用于 DDL 生成的索引的逻辑名称。该列将与共享相同索引逻辑名称的其他列一起包含在索引中.
-
(15) length (optional):指定长度.
-
(16) precision (optional):指定精度.
-
(17) scale (optional): 指定刻度.
3.5.8、many-to-one
与另一个持久类的普通关联是使用多对一元素声明的。关系模型是多对一关联
-to-one
name="propertyName" (1)
column="columnName" (2)
class="className" (3)
cascade="all|none|save-update|delete|delete-orphan|all-(4)delete-orphan"
fetch="join|select" (5)
lazy="proxy|no-proxy|false" (6)
update="true|false" (7)
insert="true|false" (7)
property-ref="propertyNameFromAssociatedClass" (8)
access="field|property|nosetter|className" (9)
optimistic-lock="true|false" (10)
not-found="ignore|exception" (11)
entity-name="entityName" (12)
formula="arbitrary SQL expression" (13)
not-null="true|false" (14)
unique="true|false" (15)
unique-key="uniqueKeyName" (16)
index="indexName" (17)
foreign-key="foreignKeyName" (18)
outer-join="auto|true|false" (19)
/>
- (1) name: 持久化类属性名.
- (2) column (optional): 映射的数据列名.
- (3) class (optional - defaults to 通过反射获取的类型: 关联类的名称.
- (4) cascade (optional): 指明哪些操作会从父对象级联到关联的对象。可选all、save-update、delete、none值。除none之外其它将使指定的操作延伸到关联的(子)对象.
****************
Cascade表示级联取值,决定是否把对对象的改动反映到数据库中,所以Cascade对所有的关联关系都起作用, Cascade是操作上的连锁反映,Cascade取值可能是以下:
all-delete-orphan 在关联对象失去宿主(解除父子关系)时,自动删除不属于父对象的子对象, 也支持级联删除和级联保存更新.
delete-orphan 删除所有和当前对象解除关联关系的对象
All 级联删除, 级联更新,但解除父子关系时不会自动删除子对象.
Delete 级联删除, 但不具备级联保存和更新
None 所有操作均不进行级联操作
save-update 级联保存(load以后如果子对象发生了更新,也会级联更新). 在执行save/update/saveOrUpdate时进行关联操作,它不会级联删除
***************
要保存或更新关联对象关系图中的所有对象,您必须
Save()、SaveOrUpdate() 或 Update() 每个单独的对象或
使用 cascade=‘all’ 或 cascade=‘save-update’ 映射关联的对象。
同样,要删除图形中的所有对象,请
delete() 每个单独的对象或
使用 cascade=‘all’、cascade=‘all-delete-orphan’ 或 cascade='delete’映射关联的对象。
建议:
如果子对象的生存期受父对象的生存期限制,则通过指定级联='all’将其设为生命周期对象。否则,请从应用程序代码中显式保存()和删除()。如果你真的想为自己节省一些额外的输入,请使用cascade='save-update’和显式Delete()。
cascade=‘all’ 父对象的操作会关联到子对象,保存/更新/删除父项会导致保存/更新/删除子项。
cascade=‘all-delete-orphan’ 或 cascade='delete-orphan’时如果保存了父项,则所有子项都将传递到 SaveOrUpdate()
如果将父级传递给 Update() 或 SaveOrUpdate(),则所有子级都将传递给 SaveOrUpdate()
如果暂时性子级被永久父级引用,则会将其传递给 SaveOrUpdate()
如果删除了父级,则所有子级都将传递给 Delete()
- (5) fetch (optional - defaults to select): 可选select和join值,select:用单独的查询抓取关联;join:总是用外连接抓取关联.
- (6) lazy (optional - defaults to proxy): 可选false和proxy值。是否延迟,不延迟还是使用代理延迟.
- (7) update, insert (optional - defaults to true):指定对应的字段是否包含在用于UPDATE或INSERT 的SQL语句中。如果二者都是false,则这是一个纯粹的 “外源性(derived)”关联,它的值是通过映射到同一个(或多个)字段的某些其他特性得到或者通过触发器其他程序得到.
- (8) property-ref (optional):指定关联类的一个属性名称,这个属性会和外键相对应。如果没有指定,会使用对方关联类的主键。这个属性通常在遗留的数据库系统使用,可能有外键指向对方关联表的某个非主键字段(但是应该是一个唯一关键字)的情况下,是非常不好的关系模型。比如说,假设Customer类有唯一的CustomerId,它并不是主键。这一点在NHibernate源码中有了充分的体验.
- (9) access (optional - defaults to property): 可选field、property、nosetter、ClassName值。NHibernate访问属性的策略.
- (10) optimistic-lock (optional - defaults to true): 指定对此属性的更新是否需要获取乐观锁。换言之,确定当此属性为脏属性时是否应发生版本增量.
- (11) not-found (optional - defaults to exception): 可选ignore和exception值。找不到忽略或者抛出异常.
- (12) entity-name (optional): 关联类的实体名称.
- (13) formula (optional): 定义计算外键值的 SQL 表达式.
- (14) not-null (optional - defaults to false): 数据列是否可为null.
- (15) unique (optional - defaults to false): 为外键列启用唯一约束的 DDL 生成.
- (16) unique-key (optional): 用于生成 DDL 的唯一索引的逻辑名称。该列将与共享相同唯一键逻辑名称的其他列一起包含在索引中。实际索引名称取决于方言.
- (17) index (optional): 用于 DDL 生成的索引的逻辑名称。该列将与共享相同索引逻辑名称的其他列一起包含在索引中。实际索引名称取决于方言.
- (18) foreign-key (optional): 指定用于 DDL 生成的外键约束的名称.
- (19) outer-join (optional): 此属性已过时.
3.5.9、one-to-one
-to-one
name="propertyName" (1)
class="className" (2)
cascade="all|none|save-update|delete|delete-orphan|all-(3)delete-orphan"
constrained="true|false" (4)
fetch="join|select" (5)
lazy="proxy|no-proxy|false" (6)
property-ref="propertyNameFromAssociatedClass" (7)
access="field|property|nosetter|className" (8)
formula="any SQL expression" (9)
entity-name="entityName" (10)
foreign-key="foreignKeyName" (11)
/>
- (1) name: 持久化类属性名称.
- (2) class (optional - defaults to 由反射确定的属性类型):关联类的名称.
- (3) cascade (optional): 指定应从父对象级联到关联对象的操作.
- (4) constrained (optional - default to false): 指定映射表的主键上的外键约束引用关联类的表。此选项会影响 Save() 和 Delete() 级联的顺序.
- (5) fetch (optional - defaults to select):在 outer-join提取或顺序选择提取之间进行选择.
- (6) lazy (optional - defaults to proxy): By default, single point associations are proxied. lazy=“no-proxy” specifies that the property should be fetched lazily when the instance property is first accessed. It works similarly to lazy properties, and causes the entity owning the association to be proxied instead of the association. lazy=“false” specifies that the association will be eagerly fetched. Note that if constrained=“false”, proxying the association is impossible and NHibernate will eagerly fetch the association.
- (7) property-ref: (optional):联接到此类的主键(或此关联的公式)的关联类的属性的名称。如果未指定,则使用关联类的主键.
- (8) access (optional - defaults to property): The strategy NHibernate should use for accessing the property value.
- (9) formula (optional): 几乎所有的一对一关联都映射到所属实体的主键。如果不是这种情况,则可以指定另一个列或表达式,以便在使用 SQL 公式时联接。这也可以由嵌套的
- (10) entity-name (optional): 关联类的实体名称.
- (11) foreign-key (optional): 指定用于 DDL 生成的外键约束的名称.
一对一关联有两种类型:
- 主键关联
主键关联不需要额外的表列;如果两行通过关联相关,则两个表行共享相同的主键值。因此,如果您希望两个对象通过主键关联来关联,则必须确保为它们分配相同的标识符值! - 唯一的外键关联
给个例子,假设现在有员工表和人员表两个表,所有人员都必须来自员工表。也就是说人员表的主键上有外键约束,必须来自员工表。
-to-one name="Person" class="Person"/>
-to-one name="Employee" class="Employee" constrained="true"/>
现在,我们必须确保 PERSON 和 EMPLOYEE 表中相关行的主键相等。我们使用一种称为外来的特殊 NHibernate 标识符生成策略:
>
>
>
>Employee>
>
>
...
-to-one name="Employee"
class="Employee"
constrained="true"/>
>
或者,具有唯一约束(从员工到人员)的外键可以表示为::
-to-one name="Person" class="Person" column="PERSON_ID" unique="true"/>
-to-one name="Employee" class="Employee" property-ref="Person"/>
并且可以通过将以下内容添加到人员映射中来进行双向关联。
3.5.10、subclass元素
多态持久性需要声明在持久性超类中声明子类。前面说过的那个灵长类动物区分,就需要
对于(推荐的)每类表层次结构映射策略,使用
-value="discriminatorValue" (2)
extends="superclassName" (3)
...> (4)
... />
... />
...
>
- (1) name: 子类的完全限定的 .NET 类名,包括其程序集名.
- (2) discriminator-value (optional - defaults to the class name): 区分各个子类的值.
- (3) extends (optional if the
- (4)
3.5.11、key元素
加入一个订单类含有一个订单详情的集合,那么在定义这个集合表与订单表连接是定义外键的。
-delete="noaction|cascade" (2)
property-ref="propertyName" (3)
not-null="true|false" (4)
update="true|false" (5)
unique="true|false" (6)
foreign-key="foreignKeyName" (7)
/>
- (1) column:外键列的名称。这也可以由嵌套
- (2) on-delete (optional - defaults to noaction): 指定外键约束是否启用了数据库级联删除.
- (3) property-ref (optional): 指定外键引用不是原始表的主键的列。它是为遗留数据提供的.
- (4) not-null (optional):指定外键列不可为空。每当外键也是主键的一部分时,就会暗示这一点.
- (5) update (optional): 指定永远不应更新外键。每当外键也是主键的一部分时,就会暗示这一点.
- (6) unique (optional): 指定外键应具有唯一约束。每当外键也是主键时,就会暗示这一点.
- (7) foreign-key (optional): 指定用于 DDL 生成的外键约束的名称.
3.6、持久化类中集合定义
3.6.1、持久化类中集合的定义
NHibernate 要求将持久性集合值字段声明为泛型接口类型,例如:
public class Product
{
public virtual ISet> Parts { get; set; } = new HashSet>();
public virtual string SerialNumber { get; set; }
}
实际的接口可能是
System.Collections.Generic.ICollection, System.Collections.Generic.IList, System.Collections.Generic.IDictionary, System.Collections.Generic.ISet
或自定义NHibernate.UserType.IUserCollectionType的实现。
请注意我们如何使用 HashSet 实例初始化实例变量。这是初始化新实例化(非持久性)实例的集合值属性的最佳方法。例如,当您通过调用 Save() 使实例持久化时,NHibernate 实际上会将 HashSet替换为 NHibernate 自己的ISet 实现的实例。注意此类错误
Cat cat = new DomesticCat();
Cat kitten = new DomesticCat();
...
ISet<Cat> kittens = new HashSet<Cat>();
kittens.Add(kitten);
cat.Kittens = kittens;
session.Save(cat);
//保存成功后cat.Kittens是NHibernate自己实现的ISet集合,已经不是HashSet类型
kittens = cat.Kittens; //Okay, kittens collection is an ISet
//报错NHibernate的ISet无法类型转换成HashSet
HashSet<Cat> hs = (HashSet<Cat>) cat.Kittens;
3.6.2、持久化类中集合的映射
用于映射集合的 NHibernate 映射元素取决于接口的类型。例如,
>
>
>
-null="true"/>
-to-many class="Part"/>
>
>
除了,
元素具有代表性:
- (1) name: 持久化类集合属性名.
- (2) table (optional - defaults to property name): 集合对应的表名称,不能用于一对多的关联.
- (3) schema (optional): overrides the schema name specified by the root
- (4) catalog (optional): overrides the catalog name specified by the root
- (5) lazy (optional - defaults to true): may be used to disable lazy fetching and specify that the association is always eagerly fetched. Using extra fetches only the elements that are needed - see Section 21.1, “Fetching strategies” for more information.
- (6) inverse (optional - defaults to false): 标记双向关联的控制权是否交给另一端.
关联的控制方向:
inverse=“false”(默认)父实体负责维护关联关系。
inverse=“true”子实体负责维护关联关系。 - (7) cascade (optional - defaults to none): 使操作能够级联到子实体.
- (8) sort (optional): 设置排序规则或设置自定义排序类.
- (9) order-by (optional):指定一个(或多个)表列按照 asc or desc排序.
- (10) where (optional): 指定在检索或删除集合时要使用的任意 SQL WHERE 条件。如果集合应仅包含可用数据的子集,则此功能非常有用.
- (11) fetch (optional, defaults to select): 在外连接提取、按顺序选择获取和按顺序子选择提取之间进行选择.
- (12) batch-size (optional, defaults to 1): specifies a “batch size” for lazily fetching instances of this collection. See Section 21.1.5, “Using batch fetching”.
- (13) access (optional - defaults to property): the strategy NHibernate should use for accessing the property value.
- (14) optimistic-lock (optional - defaults to true): 指定对集合状态的更改会导致所属实体的版本递增。对于一对多关联,您可能需要禁用此设置.
- (15) mutable (optional - defaults to true): 值 false 指定集合的元素永不更改。这允许在某些情况下进行次要的性能优化.
- (16) subselect (optional): 将不可变的只读集合映射到数据库子选择。如果要使用视图而不是基表,这将非常有用。它不用于一对多关联.
- (17) check (optional): 一个 SQL 表达式,用于为自动架构生成多行检查约束。它不用于一对多关联.
- (18) persister (optional>): specifies a custom ICollectionPersister.
- (19) collection-type (optional): 实现 IUserCollectionType 的类的完全限定类型名称.
- (20) outer-join (optional): 此属性已过时.
- (21) generic (optional, defaults according to the reflected property type): 如果为 false,则 NHibernate 会将集合元素键入为对象。否则,NHibernate 将使用反射来确定要使用的元素类型.
关于集合映射设置内容很多,可以自行参考这个页面https://nhibernate.info/doc/nhibernate-reference/collections.html
4、Hibernate的继承映射策略
在NHibernate的映射中,关于继承的映射策略有3种方式:
- 单表继承
- 类表继承
- 具体表继承
另外还有一种比较特别的多态映射
- 隐式多态
下面分别来阐述NHibernate继承映射的各种策略要点。
4.1、单表继承
单表继承的方式是,所有的字段都放在一个表中,用一个字段来区分子类。使用配置节点
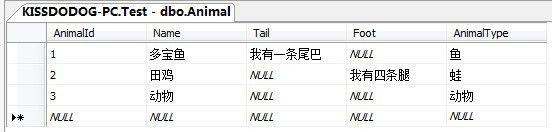
首先新建一张Animal表如下:
 映射文件:Animal.hbm.xml:
映射文件:Animal.hbm.xml:
<hibernate-mapping xmlns="urn:nhibernate-mapping-2.2">
<class name="Model.AnimalModel" table="Animal" discriminator-value="动物">
<id name="AnimalId" column="AnimalId" type="Int32">
<generator class="native"/>
id>
<discriminator column="AnimalType" type="String" />
<property name="Name" column="Name" type="String"/>
<subclass extends="Model.AnimalModel" name="Model.FrogModel" discriminator-value="蛙">
<property name="Foot" column="Foot" type="String"/>
subclass>
class>
hibernate-mapping>
子类也可以单写映射文件:Fish.hbm.xml
<hibernate-mapping xmlns="urn:nhibernate-mapping-2.2" default-lazy="false">
<subclass extends="Model.AnimalModel" name="Model.FishModel" discriminator-value="鱼">
<property name="Tail" column="Tail" type="String"/>
subclass>
hibernate-mapping>
Model类:
namespace Model
{
public class AnimalModel
{
public virtual int AnimalId { get; set; }
public virtual string Name { get; set; }
}
public class FishModel : AnimalModel
{
public virtual string Tail { get; set; }
}
public class FrogModel : AnimalModel
{
public virtual string Foot { get; set; }
}
}
执行操作:
static void Main(string[] args)
{
ISessionFactory sessionFactory = new Configuration().Configure().BuildSessionFactory();
using (ISession session = sessionFactory.OpenSession())
{
FishModel Fish = session.Get<FishModel>(1);
Console.WriteLine(Fish.AnimalId + " : " + Fish.Name + " : " + Fish.Tail);
FrogModel Frog = session.Get<FrogModel>(2);
Console.WriteLine(Frog.AnimalId + " : " + Frog.Name + " : " + Frog.Foot);
}
Console.ReadKey();
}
输出结果如下:
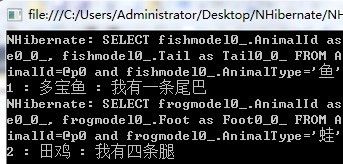
我们看看SQL Server Profiler监控到执行的过程:
exec sp_executesql N'SELECT frogmodel0_.AnimalId as AnimalId0_0_, frogmodel0_.Name as Name0_0_, frogmodel0_.Foot as Foot0_0_ FROM Animal frogmodel0_ WHERE frogmodel0_.AnimalId=@p0 and frogmodel0_.AnimalType=''蛙''',N'@p0 int',@p0=2
我们看到NHibernate,会利用我们设置的discriminator-value的值去过滤数据。使用单表继承,特别需要注意的就是,由子类定义的字段,不能有非空约束(not-null)。为什么?因为,如上面的Foot与Tail。青蛙则尾巴字段为空,鱼则肯定腿字段为空。
4.2、类表映射
类表映射,故名思议就是一个子类一个表,其子类表通过外键关联到主表。然后一个子类对应一张表。配置节点为:
首先我们将上面的表结构改为:

映射文件的改动如下,Animal.hbm.xml:
<hibernate-mapping xmlns="urn:nhibernate-mapping-2.2">
<class name="Model.AnimalModel,Model" table="Animal">
<id name="AnimalId" column="AnimalId" type="Int32">
<generator class="native"/>
id>
<property name="Name" column="Name" type="String"/>
<joined-subclass extends="Model.AnimalModel" name="Model.FrogModel" table="Frog">
<key column="Id"/>
<property name="Foot" column="Foot" type="String"/>
joined-subclass>
class>
hibernate-mapping>
Fish.hbm.xml
<hibernate-mapping xmlns="urn:nhibernate-mapping-2.2" default-lazy="false">
<joined-subclass extends="Model.AnimalModel, Model" name="Model.FishModel, Model" table="Fish">
<key column="Id"/>
<property name="Tail" column="Tail" type="String"/>
joined-subclass>
hibernate-mapping>
Fish和Frog类需要时Animal的子类。
我们来看看SQL Server Profiler监控到执行了什么语句:
exec sp_executesql N'SELECT frogmodel0_.Id as AnimalId0_0_, frogmodel0_1_.Name as Name0_0_, frogmodel0_.Foot as Foot1_0_ FROM Frog frogmodel0_ inner join Animal frogmodel0_1_ on frogmodel0_.Id=frogmodel0_1_.AnimalId WHERE frogmodel0_.Id=@p0',N'@p0 int',@p0=2
一个简单的inner join实现的。可以看到,使用这种方式的表比较多,关系模型实际是一对一关联。
类表映射使用Discriminator
类表映射还可以加上个辨别字段,只是它除了用外键关联之外,还有个辨别字段。配置节点为
现在,我们为上面的表结构再添加会一个辨别字段:
 映射文件Animal.hbm.xml:
映射文件Animal.hbm.xml:
<hibernate-mapping xmlns="urn:nhibernate-mapping-2.2">
<class name="Model.AnimalModel,Model" table="Animal" discriminator-value="动物">
<id name="AnimalId" column="AnimalId" type="Int32">
<generator class="native"/>
id>
<discriminator column="Type" type="String" />
<property name="Name" column="Name" type="String"/>
<subclass extends="Model.AnimalModel, Model" name="Model.FrogModel, Model" discriminator-value="蛙">
<join table="Frog">
<key column="Id"/>
<property name="Foot" column="Foot" type="String"/>
join>
subclass>
class>
hibernate-mapping>
Fish.hbm.xml
<hibernate-mapping xmlns="urn:nhibernate-mapping-2.2" default-lazy="false">
<subclass extends="Model.AnimalModel, Model" name="Model.FishModel, Model" discriminator-value="鱼">
<join table="Fish">
<key column="Id"/>
<property name="Tail" column="Tail" type="String"/>
join>
subclass>
hibernate-mapping>
我们来看看生成的SQL语句:
exec sp_executesql N'SELECT frogmodel0_.AnimalId as AnimalId0_0_, frogmodel0_.Name as Name0_0_, frogmodel0_1_.Foot as Foot1_0_ FROM Animal frogmodel0_ inner join Frog frogmodel0_1_ on frogmodel0_.AnimalId=frogmodel0_1_.Id WHERE frogmodel0_.AnimalId=@p0 and frogmodel0_.Type=''蛙''',N'@p0 int',@p0=2
另外,在映射文件里,可以混合使用单表映射与类表映射,例如
<hibernate-mapping xmlns="urn:nhibernate-mapping-2.2">
<class name="Model.AnimalModel,Model" table="Animal" discriminator-value="动物">
<id name="AnimalId" column="AnimalId" type="Int32">
<generator class="native"/>
id>
<discriminator column="Type" type="String" />
<property name="Name" column="Name" type="String"/>
<subclass extends="Model.AnimalModel, Model" name="Model.FishModel, Model" discriminator-value="鱼">
<join table="Fish">
<key column="Id"/>
<property name="Tail" column="Tail" type="String"/>
join>
subclass>
<joined-subclass extends="Model.AnimalModel, Model" name="Model.FrogModel, Model" table="Frog">
<key column="Id"/>
<property name="Foot" column="Foot" type="String"/>
joined-subclass>
class>
hibernate-mapping>
4.3、具体表映射
这种方法实在太烂。不光表多,重复字段也多,子类表中,每张表为对应类的所有属性(包括从超类继承的属性)定义相应字段。重复列太多,再加上每个类都一张表,估计第一范式都达不到有兴趣自己看吧。
4.4、隐式多态
有一个缺点,无法生成有union的SQL语句。有兴趣自己看吧。
5、NHibernate查询语言(HQL)
在NHibernate中提供了很多查询方式给我们选择,这里列举了3种方式:
- NHibernate查询语言(HQL,NHibernate Query Language)
- 条件查询(Criteria API,Query By Example(QBE)是Criteria API的一种特殊情况)
- 原生SQL(Literal SQL,T-SQL、PL/SQL)。
这一节我们介绍NHibernate查询语言(HQL,NHibernate Query Language)。
看一个例句:
select c.Firstname from Customer c
如果是SQL语句:Customer是数据库表,Firstname是列;而对于HQL:Customer是一个对象,Firstname是Customer对象的属性。相比之下SQL语句非常灵活,但是没有编译时语法验证支持,但是可以实现跨数据库平台的支持,无需考虑具体数据库SQL方言。
注意:HQL关键字不区分大小写。
5.1、from子句
顾名思义,同SQL语句类似:
5.1.1、简单用法
返回表中所有数据。
public IList<Customer> From()
{
//返回所有Customer类的实例
return _session.CreateQuery("from Customer")
.List<Customer>();
}
5.1.2、使用别名
使用as来赋予表的别名,as可以省略。
public IList<Customer> FromAlias()
{
//返回所有Customer类的实例,Customer赋予了别名customer
return _session.CreateQuery("from Customer as customer")
.List<Customer>();
}
5.1.3、笛卡尔积
出现多个类,或者分别使用别名,返回笛卡尔积或者称为“交叉”连接。
5.2、select子句
5.2.1、简单用法
在结果集中返回指定的对象和属性。
public IList<int> Select()
{
//返回所有Customer的CustomerId
return _session.CreateQuery("select c.CustomerId from Customer c")
.List<int>();
}
5.2.2、数组
用Object[]的数组返回多个对象和/或多个属性,或者使用特殊的elements功能,注意一般要结合group by使用。注意,这里是Object[]的数组,我们可以定义DTO对象集合返回,即使用类型安全的.NET对象。
public IList<object[]> SelectObject()
{
return _session.CreateQuery("select c.Firstname, count(c.Firstname) from Customer c group by c.Firstname")
.List<object[]>();
}
5.2.3、统计函数
用Object[]的数组返回属性的统计函数的结果,注意统计函数的变量也可以是集合count( elements(c.CustomerId) ) 。注意,这里是Object[]的数组,我们可以定义DTO对象集合返回。
public IList<object[]> AggregateFunction()
{
return _session.CreateQuery("select avg(c.CustomerId),sum(c.CustomerId),count(c) from Customer c")
.List<object[]>();
}
5.2.4、.Distinct用法
distinct和all关键字的用法和语义与SQL相同。
实例:获取不同Customer的FirstName
public IList<string> Distinct()
{
return _session.CreateQuery("select distinct c.Firstname from Customer c")
.List<string>();
}
5.3、where子句
where子句让你缩小你要返回的实例的列表范围。
public IList<Customer> Where()
{
return _session.CreateQuery("from Customer c where c.Firstname='YJing'")
.List<Customer>();
}
where子句允许出现的表达式包括了在SQL中的大多数情况:
数学操作符:+, -, *, /
真假比较操作符:=, >=, <=, <>, !=, like
逻辑操作符:and, or, not
字符串连接操作符:||
SQL标量函数:upper(),lower()
没有前缀的( ):表示分组
in, between, is null
位置参数:?
命名参数::name, :start_date, :x1
SQL文字:'foo', 69, '1970-01-01 10:00:01.0'
枚举值或常量:Color.Tabby
5.4、order by子句
按照任何返回的类或者组件的属性排序:asc升序、desc降序。
public IList<Customer> Orderby()
{
return _session.CreateQuery("from Customer c order by c.Firstname asc,c.Lastname desc")
.List<Customer>();
}
5.5、group by子句
按照任何返回的类或者组件的属性进行分组。
public IList<object[]> Groupby()
{
return _session.CreateQuery("select c.Firstname, count(c.Firstname) from Customer c group by c.Firstname")
.List<object[]>();
}
5.6、实例分析
好的,以上基本的查询的确非常简单,我们还是参考一下实例,分析一下我们如何写HQL查询吧!
实例1:按照FirstName查询顾客:
public IList<Customer> GetCustomersByFirstname(string firstname)
{
//写法1
//return _session.CreateQuery("from Customer c where c.Firstname='" + firstname + "'")
// .List();
//写法2:位置型参数
//return _session.CreateQuery("from Customer c where c.Firstname=?")
// .SetString(0, firstname)
// .List();
//写法3:命名型参数(推荐)
return _session.CreateQuery("from Customer c where c.Firstname=:fn")
.SetString("fn", firstname)
.List<Customer>();
}
书写HQL参数有四种写法:
写法1:可能会引起SQL注入,不要使用。
写法2:ADO.NET风格的?参数,NHibernate的参数从0开始计数。
写法3:命名参数用:name的形式在查询字符串中表示,这时IQuery接口把实际参数绑定到命名参数。
使用命名参数有一些好处:命名参数不依赖于它们在查询字符串中出现的顺序;在同一个查询中可以使用多次;它们的可读性好。所以在书写HQL使用参数的时候推荐命名型参数形式。
测试一下这个方法吧:看看数据库中Firstname为“YJingLee”的记录个数是否是1条,并可以判断查询出来的数据的FirstName属性是不是“YJingLee”。
[Test]
public void GetCustomerByFirstnameTest()
{
IList<Customer> customers = _queryHQL.GetCustomersByFirstname("YJingLee");
Assert.AreEqual(1, customers.Count);
foreach (var c in customers)
{
Assert.AreEqual("YJingLee", c.Firstname);
}
}
实例2:获取顾客ID大于CustomerId的顾客:
public IList<Customer> GetCustomersWithCustomerIdGreaterThan(int customerId)
{
return _session.CreateQuery("from Customer c where c.CustomerId > :cid")
.SetInt32("cid", customerId)
.List<Customer>();
}
6、常用数据表关联关系的mapping配置及CURD实现例子
6.1、一对多及多对一的例子
现有三张表:职员表(employee)、订单表(order)及订单明细表(orderentity)
三张表的主键都是自增类型,职员表与订单表是外键关联,订单表中每行记录都对应一个操作职员,职员表中每行记录都对应多个订单表中的记录,所以职员表与订单表就是主从关系或者父子关系。
订单表与订单明细表也是主从关系,订单表的主键对应订单明细表中的外键。
下面给出三个表的对应实体类:
namespace TestNHibernate.mapping.mysql.poco
{
//订单类
public class Order
{
public virtual Int64 Id{ get; set;}
public virtual DateTime CreateTime{ get; set; }
public virtual char Category { get; set; }
public virtual string Receiver { get; set; }
public virtual Employee Employee { get; set; }
public virtual ISet<OrderDetails> OrderDetails { get; set; }
}
//职员类
public class Employee
{
public virtual Int64 Id { get; set; }
public virtual string Name { get; set; }
public virtual string DepName { get; set; }
//public virtual ISet Orders { get; set; }
}
//订单详情类
public class OrderDetails
{
public virtual Int64 Id { get; set; }
public virtual Int64 ProductId { get; set; }
public virtual int Qty { get; set; }
public virtual decimal Price { get; set; }
public virtual decimal TotalAmount { get; set; }
public virtual int EntrtyId { get; set; }
public virtual Int64? OrderId { get; set; }
}
}
Order.hbm.xml文件
<hibernate-mapping xmlns="urn:nhibernate-mapping-2.2" assembly="TestNHibernate" namespace="TestNHibernate.mapping.mysql.poco">
<class name="Order" table="`order`" >
<id name="Id" column="sysid">
<generator class="identity">generator>
id>
<property name="CreateTime" type="DateTime" column="createtime">property>
<property name="Category" type="char" column="category" >property>
<many-to-one name="Employee" unique="true" column="empid" cascade ="all" />
<property name="Receiver" type="string" column="receiver" length="100">property>
<set name="OrderDetails" table="orderentity" order-by="EntrtyId desc" generic="true" inverse="false" lazy = "false" cascade="save-update" >
<key column="orderid" />
<one-to-many class="OrderDetails" />
set>
class>
hibernate-mapping>
Employee.hbm.xml文件
<hibernate-mapping xmlns="urn:nhibernate-mapping-2.2" assembly="TestNHibernate" namespace="TestNHibernate.mapping.mysql.poco">
<class name="Employee" table="employee" lazy="true">
<id name="Id" column="sysid">
<generator class="identity">generator>
id>
<property name="Name" type="string" column="name" length="50" not-null="true">property>
<property name="DepName" type="string" length="50" column="depname" not-null="true">property>
class>
hibernate-mapping>
OrderDetails.hbm.xml文件
<hibernate-mapping xmlns="urn:nhibernate-mapping-2.2" assembly="TestNHibernate" namespace="TestNHibernate.mapping.mysql.poco">
<class name="OrderDetails" table="`orderentity`" >
<id name="Id" column="sysid">
<generator class="identity">generator>
id>
<property name="ProductId" type="Int64" column="productid" >property>
<property name="Qty" type="int" column="qty" >property>
<property name="Price" type="decimal" column="`price`" >property>
<property name="TotalAmount" type="decimal" column="totalamount" >property>
<property name="EntrtyId" type="int" column="entrtyid" >property>
<property name="OrderId" type="Int64" column="orderid" >property>
class>
hibernate-mapping>
实现同步插入
现在要实现的需求是,增加一个Order类,然后将Employee及OrderDetails属性进行配置,保存Order实体时,同步将保存的订单明细插入数据库,如果职员信息存在则直接外键关联,不存在则插入职员信息.
因为需要关联操作所以需要分别在Order的mapping文件上的
Order order=new Order();
order.Category = 'D';
order.CreateTime = DateTime.Now;
order.Receiver = "测试";
order.Employee = new Employee { Name = "收件人", DepName = "营销" };
OrderDetails od=new OrderDetails();
od.EntrtyId = 1;
od.ProductId = 12;
od.Qty = 1;
od.Price = 10m;
od.TotalAmount = 10m;
OrderDetails od1 = new OrderDetails();
od1.EntrtyId = 2;
od1.ProductId = 121;
od1.Qty = 1;
od1.Price = 100m;
od1.TotalAmount = 100m;
ISet<OrderDetails> details=new HashSet<OrderDetails>();
details.Add(od);
details.Add(od1);
order.OrderDetails = details;
EntrityRepositoryImpl<Order> impl = new EntrityRepositoryImpl<Order>(DataBaseCategory.MySql);
impl.Add(order);
查看数据表中,所有信息都被同步插入了。
加入现在在增加一个记录,而订单中的职员信息是配置的已有职员,那么插入后职员信息还会继续新增还是使用已有记录?
Order order=new Order();
order.Category = 'D';
order.CreateTime = DateTime.Now;
order.Receiver = "测试";
//order.Employee = new Employee { Name = "收件人", DepName = "营销" };
EntrityRepositoryImpl<Employee> impls = new EntrityRepositoryImpl<Employee>(DataBaseCategory.MySql);
// impls.SaveOrUpdate(order.Employee);
order.Employee = impls.GetById(18L);
OrderDetails od=new OrderDetails();
od.EntrtyId = 1;
od.ProductId = 12;
od.Qty = 1;
od.Price = 10m;
od.TotalAmount = 10m;
OrderDetails od1 = new OrderDetails();
od1.EntrtyId = 2;
od1.ProductId = 121;
od1.Qty = 1;
od1.Price = 100m;
od1.TotalAmount = 100m;
ISet<OrderDetails> details=new HashSet<OrderDetails>();
details.Add(od);
details.Add(od1);
order.OrderDetails = details;
EntrityRepositoryImpl<Order> impl = new EntrityRepositoryImpl<Order>(DataBaseCategory.MySql);
impl.Add(order);
测试后发现NHibernate会自动维护职员表与订单表中外键关系,只要是职员属性是非transient状态的就会自动维护。
实现关联查询
现在需求是,通过查询订单可以同步将订单所属职员及订单明细数据一同查出来,由于存在select N+1问题(参加7.4章节),我需要使用一条连接语句查询出来。
Func<ISession, IQuery> f = t =>
{
IQuery query = t.CreateQuery("from Order c inner join fetch c.OrderDetails s inner join fetch c.Employee where c.Id=:id");
query.SetInt64("id", 23);
return query;
};
EntrityRepositoryImpl<Order> impls = new EntrityRepositoryImpl<Order>(DataBaseCategory.MySql);
Order o = impls.GetByHQL(f);
注意语句中使用了fetch关键词,直接将关联的订单明细及职员信息查询出来了。这里还需要强调一点,如果在Order的配置文件中在在
7、一些问题记录
7.1、产生no persister for:×××.×× 错误三种常见的原因。
-
是映射文件或配置文件命名错误,eg:News_T.hbm.xml和NHibernate.cfg.xml就是正确的,而New_T.xml和NHibernate.xml就是错误的。
-
是配置文件里面缺少 语句。
-
xml文件属性生成操作一定要设置为“嵌入的资源”
7.2、设置一个持久化类的一个只读属性
如果你只需要一个只读集合,你可以尝试以下方法:
<property name="BankHolidays" type="DateTime[]" formula="(SELECT Date FROM BankHolidays)" update="false" insert="false" />
7.3、一对多实现主从表级联插入时设置
当从父类中保存数据时,因为nhibernate先插入父表数据,然后插入外键为null的子表数据,然后在生成更新子表的update语句。所以外键必须能够为null,否则将报错。
当父端inverse="true"时将只生成插入语句,不会生成更新外键的update语句,所以必须inverse=“false”
数据库中外键允许为null,持久化类中属性要可为null。如int ? fid;
7.4、性能调优之Lazy与Fetch
NHibernate框架使用是否得当将直接影响到我们的程序的效率,其中的两个概念:
- lazy懒加载
- select N+1问题
用懒加载时,由于关联对象要到需要的时候才查询,所以sql会被拆分成两次查询,这就产生了select N+1问题。
- lazy的设置只是决定了关联信息的加载时间
一开始就加载还是需要时加载。 - 否使用关联查询是由fetch属性决定
下面就让我们看一下lazy与fetch两个属性组合使用的效果。使用两个实体WallParam(参数)与WallParamGroup(参数组),其中关系为多对一。
CASE 1:将lazy设为proxy
< many-to-one name = " paramGroup " column = " group_id " not-null = " true " class = " Model.WallParamGroup,Model " lazy = " proxy " />
当查询WallParam信息时,lazy配置起作用了,执行的sql如下(没有同时查出WallParamGroup, 该信息被延后了):
然而当执行查询并同时获取关联的WallParamGroup信息时,nhibernate先后执行两句sql来进行查询:
结论:lazy的配置确实延后了关联信息的加载,关联信息只有被用的时候才会去数据库查询。因此查询语句也自然是拆分的sql。
CASE 2:此时已经将lazy设为false
< many-to-one name = " paramGroup " column = " group_id " not-null = " true " class = " Model.WallParamGroup,Model " lazy = " false " />
当查询WallParam信息时,WallParamGroup的信息会同时加载出来。但是令人意外的是,执行的sql并不像我们认为的是一句关联查询。而是任然执行了两个拆分的sql,如下:
结论:lazy能延后关联对象的数据加载,却不能决定关联数据的获取方式(关联查询/拆分查询)。因此仅仅使用lazy属性并不能解决Select N+1问题。
CASE 3:保持lazy设为false,同时将fetch设置为join(fetch默认是“select”)
< many-to-one name = " paramGroup " column = " group_id " not-null = " true " class = " Model.WallParamGroup,Model " lazy = " false " fetch = " join " />
当查询WallParam信息时,WallParamGroup的信息会同时加载出来。并且从生成的sql语句看,确实使用了关联查询,一句sql就取出了所有信息:
结论:设置fetch=“join”改变了查询行为,使得关联对象能够通过join查询得到,从而解决了Select N+1问题。
CASE 4:那么fetch设置为join时,将lazy设为proxy又会有什么结果呢
< many-to-one name = " paramGroup " column = " group_id " not-null = " true " class = " Model.WallParamGroup,Model " lazy = " false " fetch = " join " />
当查询WallParam信息时,WallParamGroup的信息会同时加载出来(这是因为fetch指定了关联查询,所以关联的WallParamGroup 信息已经被查询出来,导致lazy失效)。并且从生成的sql语句看,确实使用了关联查询,一句sql就取出了所有信息:
结论:一旦设置fetch=“join”改变了查询行为(使用了关联查询),lazy懒加载就失去作用了(因为关联数据已经通过join查询查出)。
总结:
- lazy设置仅仅指明了关联对象信息的加载时机(是一开始就加载,还是需要时加载)。
- lazy加载只有在fetch=“select”(默认设置)时才有效。
- fetch设置能够改变关联对象信息查询的行为(通过关联查询还是拆分查询)。
- 解决Select N+1问题需要使用fetch=“join”。
fetch 和 lazy 配置用于数据的查询
lazy 参数值常见有 false 和 true,Hibernate3 映射文件中默认lazy = true ;
fetch 指定了关联对象抓取的方式,参数值常见是select和join,默认是select, select方式先查询主对象,再根据关联外键,每一个对象发一个select查询,获取关联的对象,形成了n+1次查询;而join方式,是left outer join查询,主对象和关联对象用一句外键关联的sql同时查询出来,不会形成多次查询。
在映射文件中,不同的组合会使用不同的查询:
-
lazy=“true” fetch = “select” ,使用延迟策略,开始只查询出主对象,关联对象不会查询,只有当用到的时候才会发出sql语句去查询 ;
-
lazy=“false” fetch = “select” ,没有用延迟策略,同时查询出主对象和关联对象,产生1+n条sql.
-
lazy="true"或lazy=“false” fetch = “join”,延迟都不会作用,因为采用的是外连接查询,同时把主对象和关联对象都查询出来了.
另外,在hql查询中,配置文件中设置的join方式是不起作用的,而在其他查询方式如get、criteria等是有效的,使用 select方式;除非在hql中指定join fetch某个关联对象。fetch策略用于get/load一个对象时,如何获取非lazy的对象/集合。 这些参数在Query中无效。