【语音信号处理】自适应滤波方法——LMS算法
LMS 算法(最小均方算法)
滤波器——改变信号频谱
模拟滤波器: 由R、L、C构成的模拟电路。
数字滤波器: 由数字加法器、乘法器、延时器构成,基于数字信号运算实现。
自适应滤波器: 一种能够根据输入信号自动调整自身参数的数字滤波器。
非自适应滤波器: 具有静态滤波器系数的数字滤波器,这些静态系数构成滤波器的传递函数。
自适应滤波器的应用
对于一些应用(如系统辨识、预测、噪声消除等),我们无法事先知道需要进行操作的参数,必须使用自适应的系数进行处理,这种情况下通常使用自适应滤波器。
自适应滤波器处理语音信号时,不需要事先知道输入信号和噪声的统计特性,滤波器自身能够在工作过程中学习或估计信号的统计特性,并以此为依据调整自身参数,已达到某种准则/代价函数下的最优滤波效果。
一旦信号统计特性发生变化,还可以跟踪这种变化,重新调节参数,使滤波性能重新达到最优。因此,自适应滤波是处理非平稳信号的一种有效手段。
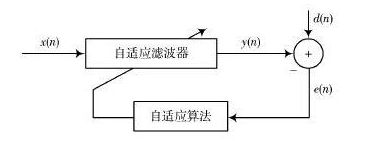
LMS 算法
Wiener 滤波
我们从一个N阶线性系统出发,设计一个N阶滤波器,它的参数为 W ( n ) W(n) W(n) ,则滤波器输出为:
y ( n ) − ∑ i = 0 N − 1 w i ( n ) x ( n − 1 ) = W T ( n ) X ( n ) = X T ( n ) W ( n ) y(n)-\sum_{i=0}^{N-1}w_i(n)x(n-1)=W^T(n)X(n)=X^T(n)W(n) y(n)−i=0∑N−1wi(n)x(n−1)=WT(n)X(n)=XT(n)W(n)
上式中:
X ( n ) = [ x ( n ) , x ( n − 1 ) , . . . x ( n − N + 1 ) ] T W ( n ) = [ w 0 ( n ) , w 1 ( n ) , . . . w N − 1 ( n ) ] T X(n)=[x(n),x(n-1),...x(n-N+1)]^T \\ W(n)=[w_0(n),w_1(n),...w_{N-1}(n)]^T X(n)=[x(n),x(n−1),...x(n−N+1)]TW(n)=[w0(n),w1(n),...wN−1(n)]T
期望输出为 d ( n ) d(n) d(n),定义误差信号:
e ( n ) = d ( n ) − y ( n ) = d ( n ) − W T ( n ) X ( n ) e(n)=d(n)-y(n)=d(n)-W^T(n)X(n) e(n)=d(n)−y(n)=d(n)−WT(n)X(n)
根据最小均方误差(MMSE)准则,最小化目标函数: J ( W ) J(W) J(W)
J ( W ) = E { ∣ e ( n ) ∣ 2 } = E { ∣ d ( n ) − W T ( n ) X ( n ) ∣ 2 } J(W)=E\{|e(n)|^2\}=E\{|d(n)-W^T(n)X(n)|^2\} J(W)=E{∣e(n)∣2}=E{∣d(n)−WT(n)X(n)∣2}
为了最小化均方误差函数,需计算 J ( W ) J(W) J(W)对 W W W的导数,令导数为零:
E { X ( n ) X T ( n ) } W ( n ) − E { X ( n ) d ( n ) } = R W − r = 0 E\{X(n)X^T(n)\}W(n)-E\{X(n)d(n)\}=RW-r=0 E{X(n)XT(n)}W(n)−E{X(n)d(n)}=RW−r=0
可以得到:
W o p t = R − 1 r W_{opt}=R^{-1}r Wopt=R−1r
上式定义的滤波器称为Wiener滤波器。Wiener滤波器是均方误差最小意义上的统计最优滤波器。
Wiener滤波在理论上有很高的价值,但是在实用阶段存在缺陷:不适用于非平稳信号。因为在求解的过程中需要求数学期望,也就是需要全部的历史数据和当前数据来估计当前信号的统计值。而一旦下一时刻来了一个新的采样点,就需要重新求解,一来很不划算,二来对于非平稳信号这种求法是不准的,因为统计特性随时变化,但是我们使用了全局的值来估计统计值。因此Wiener滤波虽然具有很高的理论价值,但是一般不会显式的用这样的公式来求解维纳滤波系数,而是用自适应的方式一步步迭代,迭代出的解我们希望逼近理论最优值,这个解就是维纳解。
LMS 算法
由于涉及数学期望,在实际应用中,绝大多数情况下我们无法获得信号真实的自相关矩阵,以及输入信号与期望之间的互相关向量,因此,实际应用中,我们用瞬时梯度代替 J ( W ) J(W) J(W) 的数学期望:
∇ ( n ) = − 2 e ( n ) X ( n ) \nabla(n)=-2e(n)X(n) ∇(n)=−2e(n)X(n)
于是,我们得到标准时域LMS算法的更新公式:
W ( n + 1 ) = W ( n ) + 2 μ X ( n ) e ( n ) W(n+1)=W(n)+2\mu{X(n)e(n)} W(n+1)=W(n)+2μX(n)e(n)
上式是逐点更新,也就是每当给定一个新的 x ( n ) x(n) x(n) 和 d ( n ) d(n) d(n) ,滤波器系数就更新一次, μ \mu μ 表示更新步长。
标准LMS算法的执行流程:
1)滤波器初始化: W ( 0 ) W(0) W(0)、 X ( 0 ) X(0) X(0)
2)对每一个新的输入采样 x ( n ) x(n) x(n),计算输出信号 y ( n ) y(n) y(n)
3)利用期望输出 d ( n ) d(n) d(n),计算误差信号 e ( n ) e(n) e(n),得到梯度 ∇ \nabla ∇
4)利用LMS更新公式更新滤波器系数: W ( n ) W(n) W(n)
5)返回步骤2),直至结束,可以得到输出序列和误差序列
LMS 算法的基本思想: 梯度下降
LMS 算法的优缺点:
- 优点:算法简单,容易实现
- 缺点:收敛速度慢
LMS 算法改进思路: block LMS
block可以看做机器学习中的batch,每L点更新一次,用kL作为新的时间索引代替n:
W ( k + 1 ) = W ( k ) + 2 ∑ m = 0 L − 1 X ( k L + m ) e ( k L + m ) W(k+1)=W(k)+2{\sum_{m=0}^{L-1}}X(kL+m)e(kL+m) W(k+1)=W(k)+2m=0∑L−1X(kL+m)e(kL+m)
block LMS 的两个核心运算:
输入向量与滤波器系数向量的线性卷积:
y ( n + m ) = X T ( n + m ) W ( n ) y(n+m)=X^T(n+m)W(n) y(n+m)=XT(n+m)W(n)
误差信号与输入向量的线性相关:
∇ ( k ) = − 2 ∑ m = 0 L − 1 X ( k L + m ) e ( k L + m ) \nabla(k)=-2{\sum_{m=0}^{L-1}}X(kL+m)e(kL+m) ∇(k)=−2m=0∑L−1X(kL+m)e(kL+m)
频域 LMS 算法
- 计算线性卷积:
y ( n + m ) = X T ( n + m ) W ( n ) y(n+m)=X^T(n+m)W(n) y(n+m)=XT(n+m)W(n)
利用FFT计算线性卷积的方法:overlap-save (下面使用的方法) 和 overlap-add
为了得到 N 点的(线性卷积后的)输出信号:
y ( n + m ) = X T ( n + m ) W ( n ) y(n+m)=X^T(n+m)W(n) y(n+m)=XT(n+m)W(n)
要保证至少有 N 个点的线性卷积和圆周卷积的结果相同:
N 1 − N 2 + 1 − N N_1-N_2+1-N N1−N2+1−N
由于 N 2 = N N_2=N N2=N(滤波器阶数为N)因此 N 1 N_1 N1 至少为 2 N − 1 2N-1 2N−1 ,为了计算 FFT 方便,取 N 1 = 2 N N_1=2N N1=2N。则FFT的长度为2N。
线性卷积与圆周卷积关系可以参考数字信号及其基本运算
如何构造长度为 2N 数据:

分别计算输入信号与滤波器系数向量的傅里叶变换: X ( k ) 、 W ( k ) X(k)、W(k) X(k)、W(k) ,频域相乘:
Y ( k ) = X ( k ) W ( k ) Y(k)=X(k)W(k) Y(k)=X(k)W(k)
则,N点线性卷积输出信号 y ( k ) y(k) y(k) 就等于 Y ( k ) Y(k) Y(k)的傅里叶逆变换的后 N 个点。

overlap-save方法不仅适用于频域自适应滤波,对于滤波器系数固定不变的情况依然适用。例如语音加混响,其实就是计算纯净语音信号,与固定系数的房间冲击响应之间的线性卷积,可以使用overlap-save方法实现。
- 计算线性相关:
∇ ( k ) = − 2 ∑ m = 0 L − 1 X ( k L + m ) e ( k L + m ) \nabla(k)=-2{\sum_{m=0}^{L-1}}X(kL+m)e(kL+m) ∇(k)=−2m=0∑L−1X(kL+m)e(kL+m)
与对卷积的操作类似,为了计算输入向量与误差信号之间的线性相关,仍是想办法变换到频域计算,计算输入信号的共轭谱与误差信号谱的乘积。
首先也将误差向量 e ( k ) e(k) e(k) 也扩展到2N长度:
计算卷积时,将滤波器系数向量后面补N个零,计算相关的时候,则在误差向量前面补N个零。
卷积与相关的计算特性可以参考数字信号与其基本运算
则频域中:
∇ ( k ) = X H ( k ) E ( k ) \nabla(k)=X^H(k)E(k) ∇(k)=XH(k)E(k)
,则时域中 ∇ ( k ) \nabla(k) ∇(k),就等于频域中傅里叶逆变换后的前N个点。
- 滤波器系数更新:
W ( k + 1 ) = W ( k ) + 2 μ F [ ∇ ( k ) , 0 , 0 , . . . 0 ] T W(k+1)=W(k)+2\mu{F}[\nabla(k), 0,0,...0]^T W(k+1)=W(k)+2μF[∇(k),0,0,...0]T
注意:
- 滤波器系数直接在频域更新,所以需要将梯度向量再次变换到频域;
- 由于滤波器系数向量后面补N个零,为了保证结果正确性,梯度向量也需要在后面补N个零。
频域自适应算法(frequency-domain adaptive filtering, FDAF)框架:

关于 LMS 算法的几点讨论
-
LMS算法对输入信号有何要求?
LMS要求不同时刻的输入向量线性无关——LMS的独立性假设。如果输入信号存在相关性,会导致前一次迭代产生的梯度噪声传播到下一代迭代,造成误差的反复传播,收敛速度变慢,跟踪性能变差。所以理论上,LMS算法对白噪声的效果最好。
-
何为归一化LMS(NLMS)、功率归一化LMS?
W ( n + 1 ) = W ( n ) + 2 μ X T ( n ) X ( n ) X ( n ) e ( n ) W(n+1)=W(n)+2\mu{\frac{X^T(n)X(n)}{X(n)}e(n)} W(n+1)=W(n)+2μX(n)XT(n)X(n)e(n)
上式为归一化LMS(NLMS)算法的更新公式,与标准LMS相比,梯度项中增加了一个归一化项: X T ( n ) X ( n ) X^T(n)X(n) XT(n)X(n)归一化的作用:对于较大的输入,会导致梯度噪声的放大,因此需要用输入向量的平方范数进行归一化。
μ ( n ) = α β + X T ( n ) X ( n ) , 0 < α < 2 , β ≥ 0 \mu(n)=\frac\alpha{\beta+X^T(n)X(n)},0<\alpha<2,\beta\ge0 μ(n)=β+XT(n)X(n)α,0<α<2,β≥0
上式为功率归一化(PNLMS),是利用归一化项调整学习速率,数值稳定性好于NLMS。当 α = 1 \alpha=1 α=1 时,PNLMS退化为NLMS。 -
学习速率如何选取?
在上述推导过程中,为了简化问题,将每一个 frequency bin 上的学习率均设为常数 μ \mu μ。
在实际工程应用中,用的更多的一种方法是,对第m个frequency bin,利用输入信号在这个频点的功率 P m ( k ) P_m(k) Pm(k) 对学习速率进行归一化:
μ m ( k ) = μ P m ( k ) \mu_m(k)=\frac\mu{P_m(k)} μm(k)=Pm(k)μ
频点功率 P m ( k ) P_m(k) Pm(k) 通常采用迭代方式求得:
P m ( k ) = λ P m ( k − 1 ) + ( 1 − λ ) ∣ X m ( k ) ∣ 2 P_m(k)=\lambda{P_m(k-1)+(1-\lambda)}|X_m(k)|^2 Pm(k)=λPm(k−1)+(1−λ)∣Xm(k)∣2