lucene.net学习三——与索引优化相关的几个参数
在许多应用程序中,程序性能的瓶颈经常出现在磁盘的I/O过程中,当新的Document加入索引中时,他们最初被缓存在内存中,而不是立即写入磁盘里。
lucene.net中提供了几个参数用来控制缓存的大小和Document写入磁盘的频率。
先看第一个参数:合并因子mergeFactor
在源码中的定义如下: public const int DEFAULT_MERGE_FACTOR = 10;默认值为10,表示每当加入10个Document时就会产生一个新的segment,当第10个这个segment产生时会合并这些segement形成一个含有100个Document的segment,当第10个这个segment产生时,会被合并成一个具有1000个Document的segment 依次类推下去....
下面写一段代码验证
static void Main(string[] args)
{
//构造索引存放的路径
Lucene.Net.Store.Directory indexDir = FSDirectory.Open(new DirectoryInfo(@"F:\lucene_index"));
//构造一个索引写操作的类,第一个参数为索引存放的路径,第二个参数为对输入的数据源进行分词等处理类实例,
//第三个参数为true表示会删掉原有的索引,从新建索引,第四个参数表示某个域对于不的数据源分词后最大的词条数目
IndexWriter IW = new IndexWriter(indexDir, new StandardAnalyzer(Lucene.Net.Util.Version.LUCENE_29), false,new IndexWriter.MaxFieldLength(10000));
Field bookname = new Field("bookmname", "倚天屠龙记", Field.Store.YES, Field.Index.ANALYZED);
for (int i = 0; i < 10; i++)
{
Document doc = new Document();
doc.Add(bookname);//向文档中添加域
IW.AddDocument(doc);
}
//关闭索引写入,一定要记得,否则会写不进去
IW.Close();
}
注意代码中构造IndexWriter时第三个参数,当第一次运行此程序时,可以设置为true,它会自动的生成索引的目录,索引目录建立后可以设置为false,否则第一次运行时就设为false会出现找到不到索引目录的异常,当然也可以先建立好索引目录,一开始就设为false,第三个参数设为false表示新加入的索引会在原来的基础上增加,也就是一种增量索引的方式。避免了每次加入索引的时候,将原来的索引删除掉。
首次运行上面的代码,得到结果如下图:

当连续运行上面的程序9次后,得到的结果如下图;
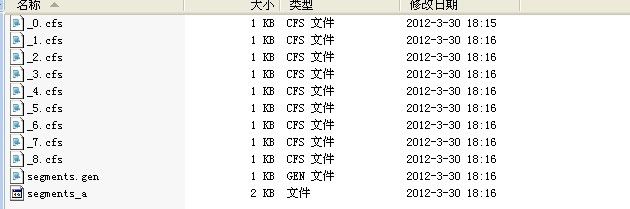
可以看到每次加入10个Document时就会产生一个索引.cfs的文件。当运行第10此后结构如下;
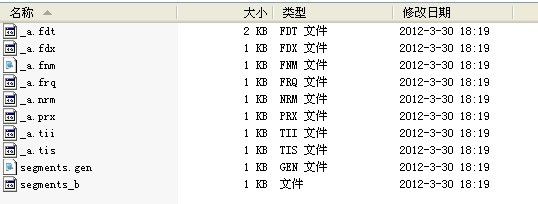
可以看到上面那9个.cfs索引文件一起与第10个,刚好产生了100个Document,因此被和并了。更多的合并可以继续运行下去。。。
第二个参数:maxMergeDocs
在源码中的定义为:public static readonly int DEFAULT_MAX_MERGE_DOCS = System.Int32.MaxValue;
第一个参数看到了合并的因子大小,那如果按照那个规律推段下去,segment中的Document会变得越来越多,显然对有限的计算机资源内存来说是不可能让这样一直下去的,因此lucene.net定义了maxMergeDocs,来限制每个段中文档的数量。源码中这个默认值的大小为System.Int32.MaxValue
分析第一个参数和第二个参数可以得知,较小的mergeFactor使用的内存较小,但会使索引的跟新的频率增加,较大的maxMergeDocs更适合批量索引的情况。
较大的mergeFactor意味着较低频率的合并,但这样会导致单个索引segment中文件数量增多,虽然这对索引影响较小,但是对搜索的时後又影响,因为lucene.net需要打开、读取
、处理更多的的索引文件。
第三个参数是:maxBufferedDocs 以前版本中是minMergeDocs
这个参数限制了索引时Ram使用的大小。
在实际的搜索引擎中,需要索引的文档Document可能含有多个Filed,并且有些Filed中对应的源数据数据量也较大,如果mergeFactor和maxBufferedDocs设置较大,虽然可以减少I/O次数,加快索引的速度,但是这样需要机器拥有较大的内存,而且较大的mergeFactor对于用户的检索性能有所影响,因此对于一个实际的系统应该充分考虑机器的内存和检索的时间,来设置合适的参数值。