AI加速(六)| 异构编程——性能不够,“外挂“来凑?
这是通俗易懂的入门级AI加速科普文章,第 6 篇。这篇简单介绍一个概念——异构编程。
上一篇AI加速(五)| 一个例子看懂流水——从指令到算法用一个生活中的小例子,介绍了流水这一概念。在计算资源有限的情况下,我们可以通过软件的流水技术来提升程序性能。
但如果你是土豪,不想耗费太多精力去做软件优化,就想砸钱来提升程序性能,有办法么?
当然有,性能不够,芯片来凑。正所谓“众人拾柴火焰高”,只要芯片足够多,性能就能飙到顶。
异构芯片编程就是这样的一种方式。
异构编程
所谓异构编程,就是将不同厂家、不同架构的芯片放在一个统一的计算机系统中,通过软件的调度,来实现AI计算的一种方式。
比如将x86的CPU和英伟达的GPU放在一起进行编程。
人工智能的发展催生了异构编程的火热。主要是因为神经网络中有大量的稠密计算,如果用传统的CPU从头到尾训练一个神经网络,需要耗费大量的算力才能计算出来,就算把CPU累死,估计都算不出来。
在神经网络中,矩阵和卷积运算这两种稠密运算,几乎占据了大部分神经网络90%的耗时。
因此,有很多公司开发专用的AI芯片(也称ASIC 芯片,Application Specific Integrated Circuit,专用集成电路),专门围绕着卷积运算或者矩阵运算设计硬件单元,来完成运算加速。
这就像,给CPU搞了个外挂。
英伟达的GPU,谷歌的NPU,寒武纪的MLU等都是类似的ASIC芯片。它们通过PCIe总线和主机相连,从而作为协处理单元完成AI的加速。
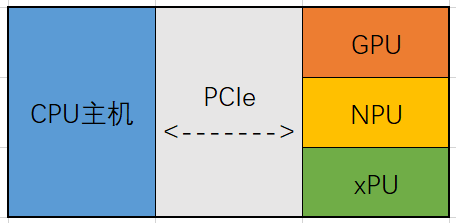
这和我们扩展电脑内存一个道理。
-
内存不够了,买个内存条插上,内存就够了。
-
算力不够了,买个显卡插上去,算力就够了。
正是因为人工智能对于算力的需求,才出现了越来越多的AI芯片公司,并且使得异构编程这一技术越来越为人所知。
其中,英伟达的 CUDA 编程就是最广为人知的一种异构编程方式。
异构编程难么
不熟悉的同学这时候可能会有些疑问,异构编程难么?
首先说,不难。
因为大部分做ASIC芯片的厂家都会提供异构编程所需要的驱动或者计算库。
如英伟达有 cuDriver 库用来驱动显卡,有 cuDNN 库用来加速常见的深度学习算法,cuFFT 库用来就是FFT相关运算(里面都把算法写好了,我们自己调用即可),还有 TensorRT 专门用来做神经网络推理的优化和网络融合等等。
再不济,如果你的神经网络中有个不常见的算法,像英伟达还提供了CUDA编程,这是一种类C语言的编程语言,只需要学会某些简单的标识符和核函数(kernel)的编写,就能写出远超CPU性能的代码。
关于CUDA编程的资料网上有很多,感兴趣的同学可以自行去查找。
除了英伟达,其他厂家也基本都是这个套路。对外提供提供加速库和驱动来辅助完成异构编程,从而实现AI的计算加速。
一次与异构编程相关的面试
记得有一次去某公司面试,面试官告诉我,他们公司是基于视觉做智能交通的解决方案的。所谓的解决方案,就是给他们的客户提供一整套的软件+硬件的产品,打包卖给他们。
我当时比较好奇,你们也自己做芯片么?
面试官说,我们自己不做,但我们会买。国内做AI芯片的企业开发的芯片产品我们都会买,当然GPU也会买,然后做二次开发,在这些硬件上部署我们自己的算法。
那你们的解决方案中,卖给用户的硬件,是只有一家的产品,还是会多家混用?
面试官:有可能多家的都有,看谁家的性能好用谁家的。
...
这家做解决方案的公司,会用到不同厂家的芯片,但核心的AI算法是自己的。
这是一种典型的异构编程场景:在服务器主机上通过PCIe总线连接多张AI加速卡,实现AI算法计算加速,在云端实现交通场景下路人和车辆的识别。

总结
异构编程可以认为是一种使用专用芯片对神经网络进行加速的外挂方式。通过这种专用的加速卡,来完成神经网络中相关算法的加速运算。
其实,异构编程并不是一个很新的概念。
据一个从事手机开发的朋友讲,他们很早之前做手机,手机系统中会有很多不同的芯片,主处理器和协处理之间都会有通信,某些算法在主处理器上跑,某些算法在协处理器上跑,最终完成一个整体运算。
这就是一种异构编程,只不过当时他们认为这是理所当然的。而随着人工智能的热潮,异构编程这一概念才越来越多的被人所熟知。
从而也成为了AI加速中一个不可或缺的编程方式。
好啦,异构编程就简单说到这。欢迎点击专栏查看全部文章。