安全帽监测——yolov5+tensorrt加速
这个项目是进行工地安全帽监测,整个项目用yolov5进行训练和监测。
先用yolov5训练出安全帽监测的模型pt,再转换成wts文件,最后再放到tensorrt中转成engine文件。
这个博客记录了从数据集的获取,数据集划分,yolov5训练,转换wts和engine,再放到项目里进行测试。
假设我的工作目录为 /test
步骤1:数据集获取
数据集来源:安全帽检测数据集 (Helmet Detection)
我是先将数据集下载到win也就是本机中,再将数据集发送到虚拟机的/test目录下
下载后的文件目录如下:
dataset/
├── annotations/
├── images/
由于在下一步中我们要对数据集格式进行转换并且要划分训练集和测试集,而我找的转换代码对数据集的格式有要求,所以要将数据集格式进行转换。
转换成如下
VOCdevkit/
├── VOC2007/
├── Annotations/
├── JPGEImages/
步骤2:数据集格式进行转换及数据集划分
这一步是参考了:目标检测—数据集格式转化及训练集和验证集划分
这个博客讲了为什么要进行格式转换,并且提供了转换代码,讲得很详细,可以仔细看看。
将它提供的代码复制到/test 文件夹下,我把文件命名为 x2t.py ,并更改第九行的classes为xml里面已经标注好的类。
对于上面所下载的数据集即改为如下:

之后在 /test 目录下执行:
python x2t.py
等待执行完成后就生成如下目录格式的文件

步骤3:yolov5模型训练
下载yolov5 v5.0 版的代码(因为后面要用tensorrt转换,所以yolov5的版本要和tensorrt的yolov5版本对应)
在/test目录下执行:
sudo git clone -b v5.0 https://github.com/ultralytics/yolov5.git
并把我们上一步生成的数据集复制到yolov5中
cp /test/VOCdevkit /test/yolov5
这里/test/VOCdevkit和/test/yolov5都要填你自己的数据集和yolov5下载的位置,我这里只是一个例子。
训练模型的整个过程参考了:目标检测—教你利用yolov5训练自己的目标检测模型
由于我采用的公司的GPU,环境的安装和依赖的安装已经配置好了,所以这里不记录环境配置,如果要进行环境配置的话,参考上面的链接。
获得预训练权重
在/yolov5/weights下执行:
wget https://github.com/ultralytics/yolov5/releases/download/v5.0/yolov5s.pt
接下来就根据上面的博客一步步执行:
训练模型’
训练目标检测模型需要修改两个yaml文件中的参数。一个是data目录下的相应的yaml文件,一个是model目录文件下的相应的yaml文件。
修改数据配置文件
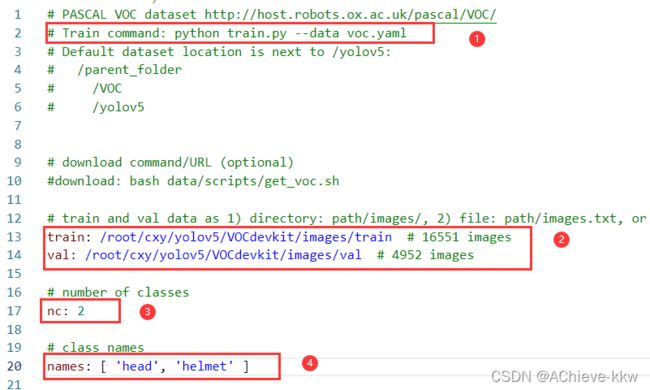
修改data目录下的相应的yaml文件。找到目录下的voc.yaml文件,将该文件复制一份,将复制的文件重命名,最好和项目相关,这样方便后面操作。我这里修改为helmet.yaml。该项目是对安全帽的识别。
打开这个文件夹修改其中的参数,
- 将1中的那一行代码注释掉(我已经注释掉了),如果不注释这行代码训练的时候会报错;
- 将2中训练和测试的数据集的路径填上(最好要填绝对路径,有时候由目录结构的问题会莫名奇妙的报错);
- 3中需要检测的类别数,我这里是识别安全帽和人,所以这里填写2;
- 4中填写需要识别的类别的名字(必须是英文,否则会乱码识别不出来)。到这里和data目录下的yaml文件就修改好了。
修改模型配置文件
由于该项目使用的是yolov5s.pt这个预训练权重,所以要使用models目录下的yolov5s.yaml文件中的相应参数(因为不同的预训练权重对应着不同的网络层数,所以用错预训练权重会报错)。同上修改data目录下的yaml文件一样,我们最好将yolov5s.yaml文件复制一份,然后将其重命名,我将其重命名为yolov5_hat.yaml。

训练自己的模型
/yolov5/train.py 是我们训练模型的函数
然后找到主函数的入口,这里面有模型的主要参数。

训练自己的模型需要修改如下几个参数就可以训练了。首先将weights权重的路径填写到对应的参数里面,然后将修好好的models模型的yolov5s_helmet.yaml文件路径填写到相应的参数里面,最后将data数据的helmet.yaml文件路径填写到相对于的参数里面。这几个参数就必须要修改的参数。
parser.add_argument('--weights', type=str, default='weights/yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='models/yolov5s_helmet.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/helmet.yaml', help='data.yaml path')
由于是在GPU上进行训练,而公司的GPU是公用的,所以最好修改
parser.add_argument('--batch-size', type=int, default=2, help='total batch size for all GPUs')
parser.add_argument('--workers', type=int, default=2, help='maximum number of dataloader workers')
我这里是都修改成2了,这里可根据自己实际情况进行修改,越大速度越快
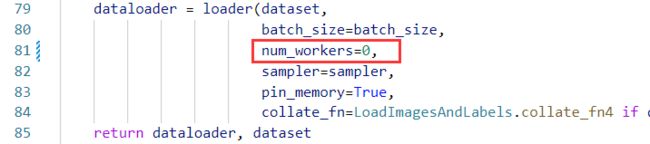
最后将/yolov5/utils/datasets.py中num_workers修改为0。
至此就能训练自己的模型了。
遇到的问题:
问题1:指定在gpu上训练
python运行程序设置指定GPU(查看GPU使用情况)
在训练时可以先查看gpu的空闲情况,再指定空闲的gpu训练
用nvidia-smi查看gpu使用情况
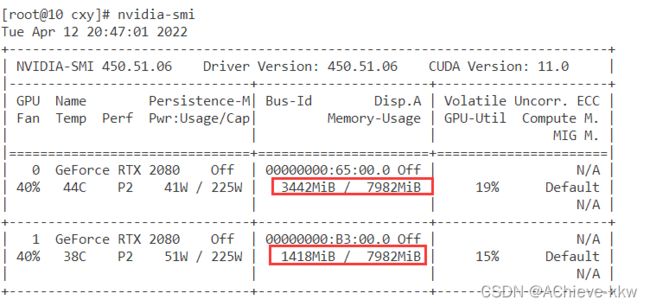
gpu1比较空闲,可采用
CUDA_VISIBLE_DEVICES=1 python3 train.py
来训练。
问题2:使用tensorboard可视化
参考:yolov5中使用tensorboard可视化
先将yolov5中yolo.py中有关于tensorboard的注释消掉
/yolov5/models/yolo.py

第二点就是
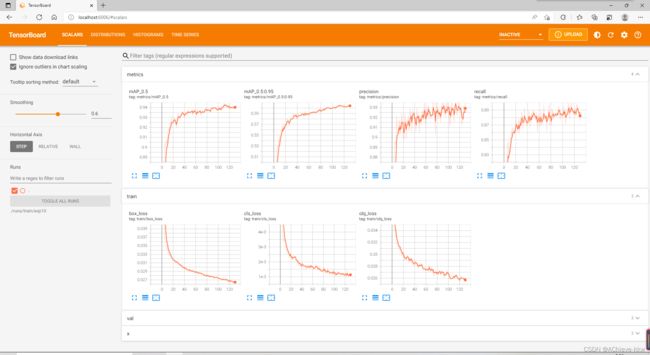
在训练的过程中会在/yolov5目录下生成/runs/train/exp文件夹,而tensorboard 的日志文件就在这个目录下

红框就是日志文件。
要想在tensorboard看到训练的可视化结果,日志文件的地址不能写错。
在/yolov5目录下执行
tensorboard --logdir ./runs/train/exp
然后在http://localhost:6006/就能看到训练过程。

问题3:在后台训练
由于训练模型通常很耗时,我在前两次训练的时候总是因为各种各样的原因训练中断了,后来才知道可以后台训练,这样就算我们登出训练都不会暂停。
参考:在后台运行Python脚本服务
执行
nohup python3 train.py &
nohup CUDA_VISIBLE_DEVICES=1 python3 train.py &
使用 nohup命令,可以忽略登出的信号:,&代表在后台运行
查看后台运行的Python——pid
ps -ef |grep python3

这样训练好之后就会在/yolov5/runs/train/exp/weights

生成两个pt文件,其中best.pt就是我们需要的。
步骤4:转换成wts,engine放到项目里运行
下载tensorrtx,注意yolov5的版本要和上面下载的版本对应:
sudo git clone -b yolov5-v5.0 https://github.com/wang-xinyu/tensorrtx.git
将tensorrtx下的get_wts.py文件拷贝到yolov5文件夹下,然后将下载好的或者训练好的best.pt模型转换为wts模型
cp tensorrtx/yolov5/gen_wts.py yolov5/
然后进入yolov5文件夹执行gen_wts.py将.pt文件转换成.wts文件。
即在yolov5/文件夹下执行指令:
我将生成的wts文件命名为:helmet.wts
python3 gen_wts.py -w runs/train/exp2/weights/best.pt -o ./weights/helmet.wts
5.编译tensorrtx/yolov5项目并获取tensorrt engine file
进入/tensorrtx/yolov5文件夹执行指令
我们在将自己训练的模型文件用tensorrtx转换成engine时,一定要将yololayer.h 文件中的CLASS_NUM改成自己的分类数,不然转换会报错。

先修改这个文件,再build和cmke、make
mkdir build
创建build文件夹
进入build文件夹执行指令,将.wts文件复制到build文件夹中:
cp /yolov5/weights/helmet.wts /tensorrtx/yolov5/build/
进入build文件夹:
cd build
cmake ..
make
// 获得helmet.engine文件
sudo ./yolov5 -s helmet.wts helmet.engine s
这样就在build文件夹下生成了engine文件
我采用的是一个博主写好的安全帽监测项目,只需将转换好的engine文件放到项目中就可以完成测试。
项目地址:https://github.com/RichardoMrMu/yolov5-helmet-detection
下载项目:
git clone :https://github.com/RichardoMrMu/yolov5-helmet-detection.git
下载好之后,将engine文件放入项目:
cp /tensorrtx/yolov5/build/helmet.engine /yolov5-helmet-detection/resources
只需修改/src/main中的

改为自己的engine存放位置
/src/manager
修改结果保存的目录

mkdir build && cd build
cmake ..
make
./yolohelmet
这样就能在结果目录中看到识别好的视频文件。