MIT6.824_2021_学习总结 分布式常见知识点
目录
- 知识点
- 分布式系统原则
-
- CAP
- BASE
-
- ACID和BASE的区别与联系
- 分布式一致性
-
- 线性一致性
- 顺序一致性
- 因果一致性
- FIFO 一致性
- 最终一致性
- 分布式共识算法
-
- Paxos:
-
- Raft:
-
- 和 Paxos 的区别
- ZAB
-
- Zab 与 Raft的不同
- CRAQ 链式复制(Chain Replication)
-
- CRAQ 与 Raft 区别
- 事务
-
- ACID
- 单机事务
-
- 2PL(两阶段锁)
- C2PL
- S2PL(Strict 2PL)
- SS2PL( Strong 2PL)
- 分布式事务
-
- 2PC(两阶段提交)
- 3PC(**三阶段提交**)
- 分布式系统
-
- 数据流式处理框架
-
- Mapreduce
-
- 一、MapReduce是什么
- 二、MapReduce做什么
- Spark
-
- 什么是spark
- Spark与Hadoop
- 为什么使用Spark?
- Spark的特点: 快, 易用, 通用,兼容性
- 分布式文件系统
-
- GFS
-
- 是什么?
- 为什么要用GFS?
- HDFS
- 分布式协调系统
-
- Zookeeper
- etcd
- 分布式存储
-
- Bigtable
- Spanner
- Memcache_Facebook
- COPS
- FaRM
-
- 硬件要求:
- 系统架构
- 乐观并发控制
- 三个步骤与RDMA
- 故障和恢复
- 拜占庭
- Fork Consistency
-
- Blockstack:使用区块链实现分布式互联网
- 比特币:proof-of-work
- 中间人攻击
- 参考
知识点
学完 MIT6.824 2021,感觉自己对分布式系统有了一个初步的认知,打开了新世界的大门,作为分布式系统的入门课,无疑是王牌课程;
但是确实是感觉学到了很多知识,但又没有一个总体的框架,感觉知识点都很零散;
在此,给出自己的知识总结的脉络;学完了 MIT6.824,我学到了:
分布式系统原则
CAP
CAP即:
- Consistency(一致性)
- Availability(可用性)
- Partition tolerance(分区容忍性)
这三个性质对应了分布式系统的三个指标:
而CAP理论说的就是:一个分布式系统,不可能同时做到这三点。如下图:

①一致性:对于客户端的每次读操作,要么读到的是最新的数据,要么读取失败。换句话说,一致性是站在分布式系统的角度,对访问本系统的客户端的一种承诺:要么我给您返回一个错误,要么我给你返回绝对一致的最新数据,不难看出,其强调的是数据正确。
②可用性:任何客户端的请求都能得到响应数据,不会出现响应错误。换句话说,可用性是站在分布式系统的角度,对访问本系统的客户的另一种承诺:我一定会给您返回数据,不会给你返回错误,但不保证数据最新,强调的是不出错。
③分区容忍性:由于分布式系统通过网络进行通信,网络是不可靠的。当任意数量的消息丢失或延迟到达时,系统仍会继续提供服务,不会挂掉。换句话说,分区容忍性是站在分布式系统的角度,对访问本系统的客户端的再一种承诺:我会一直运行,不管我的内部出现何种数据同步问题,强调的是不挂掉。
BASE
BASE 是基本可用(Basically Available)、软状态(Soft State)和最终一致性(Eventually Consistent)三个短语的缩写。
BASE 理论是对 CAP 中一致性和可用性权衡的结果,它的理论的核心思想是:即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。
- BA:Basically Available,基本可用
系统出现了不可预知的故障,但还是能用,相比较正常的系统而言会有响应时间上的损失和功能上的损失。
- S:Soft State,软状态,状态可以有一段时间不同步
什么是软状态呢?相对于原子性而言,要求多个节点的数据副本都是一致的,这是一种“硬状态”。
软状态指的是:允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据延时。
- E:Eventually Consistent,最终一致,最终数据是一致的就可以了,而不是时时保持强一致。
上面说软状态,然后不可能一直是软状态,必须有个时间期限。在期限过后,应当保证所有副本保持数据一致性,从而达到数据的最终一致性。这个时间期限取决于网络延时、系统负载、数据复制方案设计等等因素。
ACID和BASE的区别与联系
ACID是传统数据库常用的设计理念,追求强一致性模型。
BASE支持的是大型分布式系统,提出通过牺牲强一致性获得高可用性。
ACID和BASE代表了两种截然相反的设计哲学,在分布式系统设计的场景中,系统组件对一致性要求是不同的,因此ACID和BASE又会结合使用。
分布式一致性
线性一致性
线性一致性(Linearizability),或称原子一致性、强一致性、严格一致性指的是程序在执行的历史中在存在可线性化点P的执行模型,这意味着一个操作将在程序的调用和返回之间的某个点P起作用。这里“起作用”的意思是被系统中并发运行的所有其他线程所感知。
顺序一致性
顺序一致性的定义可以理解为,系统无论如何运行,执行的结果像是:
- 所有处理器上的操作按照一定顺序排列执行
- 每个处理器内部执行顺序与程序定义一致
例如:Zookeeper 中的顺序一致性便是:客户端发送的更新命令,服务端会按它们发送的顺序执行
因果一致性
因果一致性往往发生在分区(也称为分片)的分布式数据库中。
分区后,每个节点并不包含全部数据。不同的节点独立运行,因此不存在全局写入顺序。
如果用户A提交一个问题,用户B提交了回答。问题写入了节点A,回答写入了节点B。因为同步延迟,发起查询的用户可能会先看到回答,再看到问题。
为了防止这种异常,需要另一种类型的保证:因果一致性。 即如果一系列写入按某个逻辑顺序发生,那么任何人读取这些写入时,会看见它们以正确的逻辑顺序出现。
FIFO 一致性
FIFO一致性(FIFO Consistency)是最弱的一致性,它仅仅要求:对于同一个进程执行的读写序列,对于任何一个变量x的读操作read(x),读到的值都是在此读操作之前最后一次此进程发出的写操作write(x)更新的值。而对于不同节点发出的写序列,其他节点的读操作可以按任意顺序返回值。
最终一致性
最终一致性是分布式计算里的一种内存一致性模型,它指对于已改变写的数据的读取,最终都能取得已更新的数据,但不完全保证能立即取得已更新的数据。这种模型通常可以实现较高的可用性。
分布式共识算法
https://cloud.tencent.com/developer/article/1528466
Paxos:
具体看这里,下面是概述
在一个Paxos算法系统中, 所有节点分为3类:** Propersor提议者, Accepter接受者, Learner学习者**
- Proposer: 提出提案 (Proposal)。Proposal信息包括提案编号 (Proposal ID) 和提议的值 (Value)。
- Acceptor:参与决策,回应Proposers的提案。收到Proposal后可以接受提案,若Proposal获得多数Acceptors的接受,则称该Proposal被批准。
- Learner:不参与决策,从Proposers/Acceptors学习最新达成一致的提案(Value)。
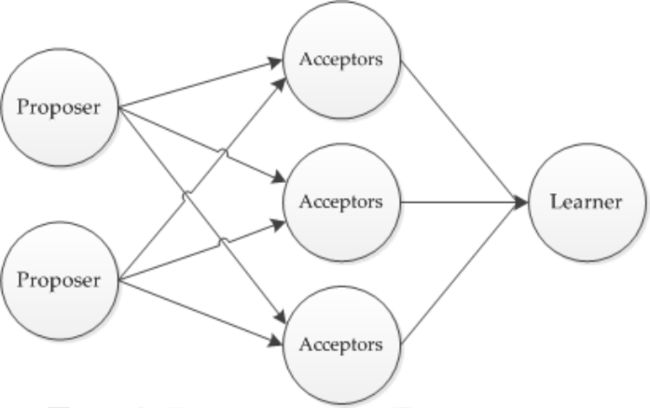
一个完整的Paxos算法分为3个阶段:
- Prepare 准备阶段
Proposer 向 Acceptors 发出 Prepare 请求,Acceptors 针对收到的 Prepare 请求进行 Promise 承诺。
- Accept 阶段
Proposer 收到多数 Acceptors 承诺的 Promise 后,向 Acceptors 发出 Propose 请求,Acceptors 针对收到的 Propose 请求进 行Accept 处理。
-
Learn阶段
Proposer 在收到多数 Acceptors 的 Accept 之后,标志着本次 Accept 成功,决议形成,将形成的决议发送给所有 Learners 。
Paxos算法流程中的每条消息描述如下:
- Prepare: Proposer 生成全局唯一且递增的 Proposal ID (可使用时间戳加 Server ID ),向所有 Acceptors 发送 Prepare 请求,这里无需携带提案内容,只携带 Proposal ID 即可。
- Promise: Acceptors 收到 Prepare 请求后,做出“两个承诺,一个应答”。
两个承诺:
- 不再接受 Proposal ID 小于等于(注意:这里是<= )当前请求的 **Prepare **请求。
- 不再接受 Proposal ID 小于(注意:这里是< )当前请求的 **Propose **请求。
一个应答:
不违背以前作出的承诺下,回复已经 Accept 过的提案中 Proposal ID 最大的那个提案的 Value 和 Proposal ID,没有则返回空值。
Raft:
Mit-6.824讲的挺多了的。文章可以看看这个
https://zhuanlan.zhihu.com/p/383555591
以下只是概述:
Raft 算法就是保证一个集群的多台机器协同工作,在遇到请求时,数据能够保持一致。即使遇到机器宕机,整个系统仍然能够对外保持服务的可用性。
Raft 将共识问题分解三个子问题:
- Leader election 领导选举:有且仅有一个 leader 节点,如果 leader 宕机,通过选举机制选出新的 leader;
- Log replication 日志复制:leader 从客户端接收数据更新/删除请求,然后日志复制到 follower 节点,从而保证集群数据的一致性;
- Safety 安全性:通过安全性原则来处理一些特殊 case,保证 Raft 算法的完备性;
所以,Raft 算法核心流程可以归纳为:
- 首先选出 leader,leader 节点负责接收外部的数据更新/删除请求;
- 然后日志复制到其他 follower 节点,同时通过安全性的准则来保证整个日志复制的一致性;
- 如果遇到 leader 故障,followers 会重新发起选举出新的 leader;
这里先介绍一下日志同步的概念:服务器接收客户的数据更新/删除请求,这些请求会落地为命令日志。只要输入状态机的日志命令相同,状态机的执行结果就相同。所以 Raft 的核心就是 leader 发出日志同步请求,follower 接收并同步日志,最终保证整个集群的日志一致性。
和 Paxos 的区别
详细
paxos共识协议是后面所有一致性协议的基础。
Raft协议比paxos的优点是 容易理解,容易实现。它强化了leader的地位,把整个协议可以清楚的分割成两个部分,并利用日志的连续性做了一些简化:
- Leader在时。由Leader向Follower同步日志
- Leader挂掉了,选一个新Leader,Leader选举算法。
但是本质上来说,它容易的地方在于流程清晰,描述更清晰,关键之处都给出了伪代码级别的描述,可以直接用于实现,而paxos最初的描述是针对非常理论的一致性问题,真正能应用于工程实现的mulit-paxos,Lamport老爷爷就提了个大概,之后也有人尝试对multi-paxos做出更为完整详细的描述,但是每个人描述的都不大一样。
ZAB
详细看这里,下面是概述
Zab协议 的全称是 Zookeeper Atomic Broadcast (Zookeeper 原子广播)。
Zookeeper 是通过 Zab 协议来保证分布式事务的最终一致性。
Zab 协议实现的作用
-
使用一个单一的主进程(Leader)来接收并处理客户端的事务请求(也就是写请求),并采用了Zab的原子广播协议,将服务器数据的状态变更以 事务proposal (事务提议)的形式广播到所有的副本(Follower)进程上去。
-
保证一个全局的变更序列被顺序引用。
Zookeeper是一个树形结构,很多操作都要先检查才能确定是否可以执行,比如P1的事务t1可能是创建节点"/a",t2可能是创建节点"/a/bb",只有先创建了父节点"/a",才能创建子节点"/a/b"。
为了保证这一点,Zab要保证同一个Leader发起的事务要按顺序被apply,同时还要保证只有先前 Leader的事务被apply之后,新选举出来的Leader才能再次发起事务。
- 当主进程出现异常的时候,整个zk集群依旧能正常工作。
Zab 与 Raft的不同
- 投票机制不同
- Raft 中的每个节点在某个 term 轮次内只能投一次票,哪个 Candidate 先请求投票谁就可能先获得投票,这样就可能造成分区,即各个 Candidate 都没有收到过半的投票,Raft 通过 Candidate 设置不同的超时时间,来快速解决这个问题,使得先超时的Candidate(在其他人还未超时时)优先请求来获得过半投票。
- ZooKeeper 中的每个节点,在某个 electionEpoch 轮次内,可以投多次票,只要遇到更大的票就更新,然后分发新的投票给所有人。这种情况下不存在分区现象,同时有利于选出含有更新更多的日志的 Server,但是选举时间理论上相对 Raft 要花费的多。
- Leader 选举的触发的不同
- Raft:目前只是 Follower 在检测。如过 Follower 在倒计时时间内未收到 Leader 的心跳信息,则 Follower 转变成 Candidate,自增 term 发起新一轮的投票。
- ZooKeeper:Leader 和 Follower 都有各自的检测超时方式,Leader 是检测是否过半 Follower 心跳回复了,Follower 检测 Leader 是否发送心跳了。一旦 Leader 检测失败,则 Leader 进入 Looking 状态,其他 Follower 过一段时间因收不到 Leader 心跳也会进入 Looking 状态,从而出发新的 Leader 选举。一旦 Follower 检测失败了,则该 Follower 进入 Looking 状态,此时 Leader 和其他 Follower 仍然保持良好,则该 Follower 仍然是去学习上述 Leader 的投票,而不是触发新一轮的 Leader 选举。
CRAQ 链式复制(Chain Replication)
在Chain Replication中,有一些服务器按照链排列。第一个服务器称为HEAD,最后一个被称为TAIL。
当客户端想要发送一个写请求,写请求总是发送给HEAD。
HEAD根据写请求更新本地数据,我们假设现在是一个支持PUT/GET的key-value数据库。所有的服务器本地数据都从A开始。
当HEAD收到了写请求,将本地数据更新成了B,之后会再将写请求通过链向下一个服务器传递。
下一个服务器执行完写请求之后,再将写请求向下一个服务器传递,以此类推,所有的服务器都可以看到写请求
当写请求到达TAIL时,TAIL将回复发送给客户端,表明写请求已经完成了。这是处理写请求的过程。
对于读请求,如果一个客户端想要读数据,它将读请求发往TAIL,TAIL直接根据自己的当前状态来回复读请求。所以,如果当前状态是B,那么TAIL直接返回B。读请求处理的非常的简单。

如果HEAD出现故障,作为最接近的服务器,下一个节点可以接手成为新的HEAD,并不需要做任何其他的操作。对于还在处理中的请求,可以分为三种情况:
- 对于任何已经发送到了第二个节点的写请求,不会因为 HEAD 故障而停止转发,它会持续转发直到 commit 。
- 如果写请求发送到 HEAD ,在 HEAD 转发这个写请求之前 HEAD 就故障了,那么这个写请求必然没有 commit ,也必然没有人知道这个写请求,因为写请求必然没能送到 TAIL 。所以,我们不必做任何事情。或许客户端会重发这个写请求。
- 如果TAIL出现故障,处理流程也非常相似,TAIL 的前一个节点可以接手成为新的 TAIL 。所有 TAIL 知道的信息,TAIL 的前一个节点必然都知道,因为TAIL的所有信息都是其前一个节点告知的。
CRAQ 与 Raft 区别
-
从性能上看,对于Raft,如果我们有一个 Leader 和一些 Follower 。Leader需要直接将数据发送给所有的Follower。然而在 Chain Replication 中,HEAD只需要将写请求发送到一个其他节点。所以 Raft Leader 的负担会比 Chain Replication中 HEAD 的负担更高。当客户端请求变多时,Raft Leader会到达一个瓶颈,而不能在单位时间内处理更多的请求。而同等条件以下,Chain Replication的HEAD可以在单位时间处理更多的请求,瓶颈会来的更晚一些。
-
另一个与 Raft 相比的有趣的差别是, Raft 中读请求同样也需要在 Raft Leader 中处理,所以 Raft Leader 可以看到所有的请求。而在 Chain Replication 中,每一个节点都可以看到写请求,但是只有 TAIL 可以看到读请求。所以负载在一定程度上,在 HEAD 和 TAIL 之间分担了,而不是集中在单个 Leader 节点。
-
Chain Replication并不能抵御网络分区,也不能抵御脑裂。在实际场景中,这意味它不能单独使用。Chain Replication是一个有用的方案,但是它不是一个完整的复制方案。它在很多场景都有使用,但是会以一种特殊的方式来使用。总是会有一个外部的权威(External Authority)来决定谁是活的,谁挂了,并确保所有参与者都认可由哪些节点组成一条链,这样在链的组成上就不会有分歧。这个外部的权威通常称为Configuration Manager。
事务
ACID
ACID是数据库事务正常执行的四个原则,分别指原子性、一致性、独立性及持久性。
-
A(Atomicity)—— 原子性 原子性很容易理解,也就是说事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失 败,整个事务就失败,需要回滚。 例如银行转账,从A账户转100元至B账户,分为两个步骤:①从A账户取 100元;②存入100元至B账户。 这两步要么一起完成,要么一起不完成,如果只完成第一步,第二步失 败,钱会莫名其妙少了100元。
-
C(Consistency)—— 一致性 一致性也比较容易理解,也就是说数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。 例如现有完整性约束a + b = 10,如果一个事务改变了a,那么必须得改变 b,使得事务结束后依然满足a + b = 10,否则事务失败。
-
I(Isolation)—— 独立性 所谓的独立性是指并发的事务之间不会互相影响,如果一个事务要访问 的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问 的数据就不受未提交事务的影响。 例如交易是从A账户转100元至B账户,在这个交易还未完成的情况下,如 果此时B查询自己的账户,是看不到新增加的100元的。
-
D(Durability)—— 持久性 持久性是指一旦事务提交后,它所做的修改将会永久保存在数据库上, 即使出现宕机也不会丢失。 这些原则解决了数据的一致性、系统的可靠性等关键问题,为关系数据 库技术的成熟以及在不同领域的大规模应用创造了必要的条件。
BASE 和 ACID 代表两种截然相反的设计理念,ACID 注重一致性,是传统关系型数据库(MySQL)的设计思路,BASE 关注高可用,大多数分布式事务适合 BASE .
单机事务
2PL(两阶段锁)
参考https://www.jdon.com/53461
在我们开始讨论2PL算法实现之前,解释读和写锁的工作方式非常重要。
- 读锁:读取或共享锁定可防止在并发读取的同时写入。
- 写锁:写锁或排他锁不允许对给定资源进行读和写操作。
仅锁是不足以防止冲突。并发控制策略必须定义如何获取和释放锁,因为这也会影响事务交织。
为此,2PL协议定义了一种锁定管理策略,以确保严格的可序列化性。
2PL协议将事务分为两部分:
- 扩展阶段(获取锁,并且不允许释放锁)
- 收缩阶段(释放所有锁,并且无法进一步获取其他锁)。
对于数据库事务,扩展阶段意味着允许从事务开始到结束为止获取锁,而收缩阶段由提交或回滚阶段表示,就像在事务结束时一样,所有已获取的锁锁被释放。
对于遵守两段协议的事务,其交叉并发操作的执行结果一定是正确的。值得注意的是,上述定理是充分条件,不是必要条件。一个可串行化的并发调度的所有事务并不一定都符合两段锁协议,存在不全是2PL的事务的可串行化的并发调度。
同时我们必须指出,遵循两段锁协议的事务有可能发生死锁:事务T1 、T2同时处于扩展阶段,两个事务都坚持请求加锁对方已经占有的数据,导致死锁。
C2PL
在事物开始时对所有需要访问的数据获取锁。不存在死锁问题,要么事务等待不能开始,要么就已经得到了全部所需的锁
S2PL(Strict 2PL)
在2PL的基础上,写锁保持到事务结束或事务回滚
SS2PL( Strong 2PL)
在2PL的基础上,读写锁都保持到事务结束或事务回滚
分布式事务
参考 https://zhuanlan.zhihu.com/p/267920059
2PC(两阶段提交)
两个阶段过程:
- 准备阶段(Prepare phase):事务管理器给每个参与者发送Prepare消息,每个数据库参与者在本地执行事务,并写本地的Undo/Redo日志,此时事务没有提交。 (Undo日志是记录修改前的数据,用于数据库回滚,Redo日志是记录修改后的数据,用于提交事务后写入数据文件)
- 提交阶段(commit phase):如果事务管理器收到了参与者的执行失败或者超时消息时,直接给每个参与者发送回滚(Rollback)消息;否则,发送提交(Commit)消息;参与者根据事务管理器的指令执行提交或者回滚操作,并释放事务处理过程中使用的锁资源。注意:必须在最后阶段释放锁资源。
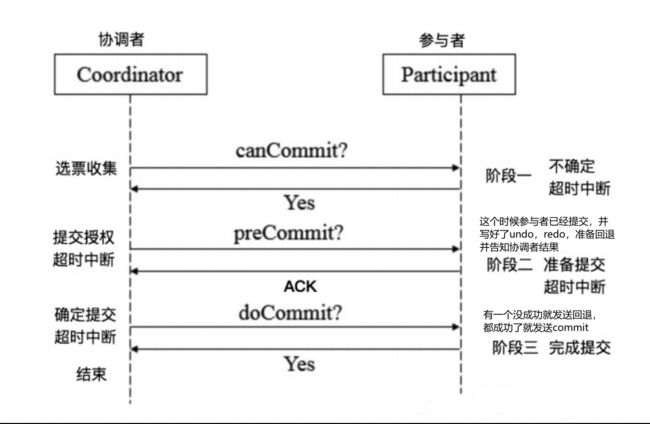
3PC(三阶段提交)
3PC,全称 “three phase commit”,是 2PC 的改进版,将 2PC 的 “提交事务请求” 过程一分为二,共形成了由CanCommit、PreCommit和doCommit三个阶段组成的事务处理协议。
分布式系统
不能撇开业务场景和设计目标谈系统实现,每种系统的实现都是有其特定的取舍的
数据流式处理框架
Mapreduce
参考:https://zhuanlan.zhihu.com/p/62135686
一、MapReduce是什么
- MapReduce是一种分布式计算框架 ,以一种可靠的,具有容错能力的方式并行地处理上TB级别的海量数据集。主要用于搜索领域,解决海量数据的计算问题。
- MR有两个阶段组成:Map和Reduce,用户只需实现map()和reduce()两个函数,即可实现分布式计算。
二、MapReduce做什么
- MapReduce框架由Map和Reduce组成。
- Map()负责把一个大的block块进行切片并计算。
- Reduce() 负责把Map()切片的数据进行汇总、计算。
一个比较形象的语言解释MapReduce:
我们要数图书馆中的所有书。你数1号书架,我数2号书架。这就是“Map”。我们人越多,数书就更快。
现在我们到一起,把所有人的统计数加在一起。这就是“Reduce”。
Spark
参考:https://www.cnblogs.com/janlle/p/10084212.html
什么是spark
Spark是一种快速、通用、可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache顶级项目。目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib等子项目,Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。
Spark与Hadoop
Spark是一个计算框架,而 Hadoop 中包含计算框架 MapReduce 和分布式文件系统 HDFS , Hadoop 更广泛地说还包括在其生态系统上的其他系统.
为什么使用Spark?
Hadoop 的 MapReduce 计算模型存在问题:
Hadoop 的 MapReduce 的核心是 Shuffle (洗牌).在整个Shuffle 的过程中,至少产生6次I/O流.基于 MapReduce 计算引擎通常会将结果输出到次盘上,进行存储和容错.另外,当一些查询(如:hive)翻译到 MapReduce 任务是,往往会产生多个 Stage ,而这些 Stage 有依赖底层文件系统来存储每一个 Stage 的输出结果,而 I/O 的效率往往较低,从而影响 MapReduce 的运行速度.
Spark的特点: 快, 易用, 通用,兼容性
- 快:与 Hadoop 的 MapReduce 相比,Spark 基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。 Spark 实现了高效的 DAG 执行引擎,可以通过基于内存来高效处理数据流。
- 易用:Spark 支持 Java 、Python 和 Scala 的 API ,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。
- 通用:Spark提供了统一的解决方案。Spark 可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
- 兼容性:Spark 可以非常方便地与其他的开源产品进行融合。比如,Spark 可以使用Hadoop 的 YARN 和 Apache Mesos 作为它的资源管理和调度器.并且可以处理所有 Hadoop 支持的数据,包括 HDFS、HBase 和 Cassandra 等。这对于已经部署Hadoop 集群的用户特别重要,因为不需要做任何数据迁移就可以使用 Spark 的强大处理能力。Spark 也可以不依赖于第三方的资源管理和调度器,它实现了Standalone 作为其内置的资源管理和调度框架,这样进一步降低了 Spark 的使用门槛,使得所有人都可以非常容易地部署和使用 Spark。此外,Spark 还提供了在EC2 上部Standalone 的 Spark 集群的工具。
目前,大规模的数据处理任务非常常见,早先时候Google提出了MapReduce,让程序员只要写高层的Map/Reduce算子,由背后的系统完成任务分配、计算、存储等相关任务。但是MapReduce的问题就是,它太慢了。对于Iterative和Interactive的计算来说,往往需要经历多个MapReduce阶段才能完成。比如在进行PageRank算法迭代的时候,可能要循环迭代很多轮。导致每一轮的结果都需要被写入GFS中,下一轮开始的时候从GFS中读出来,磁盘IO占据了大量的时间。Spark解决的方式是,把这些能够reuse的数据保存在内存里,在前后的计算中就不需要涉及到文件读写的相关消耗了。由于存在内存,可能出现节点Crash数据丢失的情况,因此Spark也提出了一个粗粒度的fault-tolerant的方式,防止因为数据丢失导致整个Computation需要重来一遍的情况。
分布式文件系统
GFS
参考:https://blog.csdn.net/Yaoman753/article/details/123786807
是什么?
GFS是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,并提供容错功能。它可以给大量的用户提供总体性能较高的服务。
为什么要用GFS?
大量数据的存储会面临很多的难点:
大数据下需要良好的表现就需要分片和容错。在具体操作过程中,涉及到容错一般使用副本来解决,然而副本的使用会面临不一致问题。如果有一致性的要求,就会导致表现降低。
所谓的一致性,就是在集群中表现的像与一台机器或一个副本进行交互那样
因为 GFS 不但是一个理论成熟的框架结构,更是一种通过长期实际使用证明了其优秀性能的分布式架构。GFS 是一种松散一致性模型,这是其具有优越的性能主要原因之一。
松散一致性模型关键:
- 依靠添加而不是重写
- 检查点
- 自我验证(校验和)
- 自我认证记录
HDFS
参考:https://blog.csdn.net/leftfist/article/details/104168141
HDFS基本可以认为是GFS的一个简化版实现,二者因此有很多相似之处。
具体而言
共同点:
- 都采用单一主控机+多台工作机的模式,由一台主控机(Master)存储系统全部元数据,并实现数据的分布、复制、备份决策,主控机还实现了元数据的checkpoint和操作日志记录及回放功能。工作机存储数据,并根据主控机的指令进行数据存储、数据迁移和数据计算等。
- 都通过数据分块和复制(多副本,一般是3)来提供更高的可靠性和更高的性能。当其中一个副本不可用时,系统都提供副本自动复制功能。同时,针对数据读多于写的特点,读服务被分配到多个副本所在机器,提供了系统的整体性能。
- 都提供了一个树结构的文件系统,实现了类似与Linux下的文件复制、改名、移动、创建、删除操作以及简单的权限管理等。
不同点:
- GFS支持多客户端并发Append模型,允许文件被多次或者多个客户端同时打开以追加数据;HDFS文件只允许一次打开并追加数据,客户端先把所有数据写入本地的临时文件中,等到数据量达到一个块的大小(通常为64MB),再一次性写入HDFS文件。
- GFS采用主从模式备份Master的系统元数据,当主Master失效时,可以通过分布式选举备机接替,继续对外提供服务;而HDFS的Master的持久化数据只写入到本机,可能采用磁盘镜像作为预防,出现故障时需要人工介入
- GFS支持数据库快照,而HDFS不支持
- GFS写入数据时,是实时写入到物理块;而HDFS是积攒到一定量,才持久化到磁盘。
分布式协调系统
Zookeeper
参考:https://zhuanlan.zhihu.com/p/62526102
zookeeper,它是一个分布式服务框架,是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
简单来说zookeeper=文件系统+监听通知机制。
etcd
参考:https://zhuanlan.zhihu.com/p/96428375?from_voters_page=true
分布式存储
Bigtable
参考:https://www.cnblogs.com/yizhiweiyan/p/13246558.html
Spanner
参考:https://zhuanlan.zhihu.com/p/85616742
https://zhuanlan.zhihu.com/p/465449343
Memcache_Facebook
参考:https://zhuanlan.zhihu.com/p/471267649
COPS
参考:https://tanxinyu.work/cops-thesis/#%E8%83%8C%E6%99%AF
https://vzhougm.gitee.io/2021/02/15/computer/%E5%88%86%E5%B8%83%E5%BC%8F%EF%BC%9ACOPS/
每个客户端维护一个上下文来表示其操作的顺序。将此上下文视为包含项目的列表。每次操作后,客户端都会向其上下文中添加一个项目。这些项目在列表中的顺序捕获了版本之间的依赖关系。使用此上下文,客户端可以计算版本的依赖关系,发送给服务端,若服务端发现操作 c 依赖的 a b 操作没有被执行,会进行等待,等待 a, b操作执行完,再进行c操作,保障最后的因果一致性。
因果一致性并不对并发操作排序,如果 a不在b之前发生,b也不在a之前发生,那么a 和b是并发的,a和b是两个不相关的操作,那么它们在分布式系统中复制就不必遵循任何顺序了,这样就避免了在它们之间使用因果这种串行化方式。
总之,COPS 通过计算写入的依赖关系来保证因果一致性,并且在集群提交所有依赖关系之前不会在集群中提交写入。
FaRM
参考:https://blog.csdn.net/hohomi77/article/details/102511679
硬件要求:
- RDMA:remote DMA,远程内存直接访问。
- 硬件支持:需要网卡的特殊支持
- 可以远程读/写另一台机器上的内存。
- 特点:应用程序直接与网卡交互,所以绕过本机的OS内核(不用TCP/IP协议栈)。在对方机器上,网卡直接读/写内存,不需要对方CPU的参与。
- 写操作成功能收到对方网卡硬件发来的ACK(确认)。
- 也可以用来实现类似RPC的效果。发送方用RDMA写到远端内存。接收方用poll查询有没有新RPC命令。执行完后,接收方用相同的方法发送回复。
- single-cache-line RDMA reads and writes are atomic. (1条cache行能有多大?FaRM正确性依赖于这条。所以,存储的每个object不能过大。见课程lec 8 FAQ)
- 消除网络瓶颈。
- non-volatile RAM
- 不怕断电的RAM。
- 其实只是普通的RAM,不怕断电是因为接在UPS上。停电后UPS会继续供电,维持一小段时间,内存的东西就写到固态硬盘保存。然后正常关机。等供电恢复,再从固态硬盘读回到内存。
- 固态硬盘平时不用,只在供电故障时用。平时读写的速度就非常快。
- SSD写要100ms,non-volatile RAM写只要几个ms。
- 消除硬盘瓶颈。
系统架构
- 类似GFS
- 一台配置管理器(configuration manager),相当于GFS的master
- 只有1台,没有副本。大概是因为1台崩溃概率不大。而且有non-valatile RAM做保障,不怕断电。
- Primary/Backup 每份数据复制 f + 1 份。1个primary处理读/写,f 个backup执行与Primary一样的写操作(读就不必了)保持数据完全一致。
- f 台挂掉也没事,只有1台活着就行。但是任何1台挂掉,系统都不是立刻可用(immediately available)。而是先恢复到 1 + f 份replicas。
- Primary/Backup与Raft不一样。Raft是多数活着就可以保持可用。但是如果超过半数不能恢复运行,就可能会丢失数据。
- 每个服务器既存放数据,同时也可以作为transaction coordinator (TC)。
- 数据的replicating不是通过primary,而是TC自己直接发给backups。
- ZooKeeper保存当前的1) 配置编号,2) 配置包含了哪些服务器,3) 那台机器是CM。——2台服务器同时想做CM,ZooKeeper负责裁定哪台做CM。网络分区时,防止了裂脑。
乐观并发控制
- Execute Phase
- 读取值和版本号。计算结果暂时写到本地。
- Commit Phase
- 四个步骤:
- LOCK、锁住要写的region
- VALIDATE、 检查读过的region版本号未改变
- COMMIT-BACKUP、将新值直接写入到backup的log
- COMMIT-PRIMARY、叫primary将新值写入
- 四个步骤:
三个步骤与RDMA
- LOCK需要对方CPU参与
- 因为单纯RDMA没有办法实现compare-and-swap。
- 加锁需要CM利用单边RDMA write将加锁请求放到primary的log中,等对方CPU执行一个CAS操作。
- 对方通过LOCK-REPLY消息答复加锁是否成功。
- VALIDATE和COMMIT-BACKUP是RDMA单边读、RDMA单边写
- 完全不用对方cpu参与
- COMMIT-BACKUP和COMMIT-PRIMARY都只等硬件答复ACK。不等对方CPU真正把log应用到数据区Region。
- 这样速度快。log应用到数据区与CM处理事务可以并行。
故障和恢复
- 凡是有节点失效,都要先经历重新配置(reconfiguration),然后恢复事务状态(transaction state recoery)。
- 恢复的时候,是primary先在region内部协调完,replicate完log,然后以region为单位整体投1票。
- 决定整个事务投票结果的是CM。
- 如果看到1个commit-primary票,就决定commit
- 否则等待所有region的票都来,
- 如果至少有1个区域投COMMIT-BACKUP,且其他区域都投COMMIT-BACKUP或者LOCK票,则commit。否则abort。
拜占庭
参考:https://zhuanlan.zhihu.com/p/98790728
拜占庭将军问题是一致性协议(agreement protocal)领域的一个方面,它被 Lamport 以故事的形式,在与Pease和Shostak合著的论文《The Byzantine Generals Problem》中被提出。
该问题假设一个场景:一个将军(General)向他的下属军官(Lieutenants)们下达命令,以决定是进攻还是撤退,共同进攻才能获得胜利,共同撤退也能保存实力,都属于达成共识,获得成功。但如果一部分进攻,一部分撤退,整个军团将全军覆没。在统一共识的目标下,命令的传递过程充满曲折,比如,命令不能到达,命令乱序,更可怕的是,下属军官们中存在叛徒,他们不仅会篡改命令,甚至还会阴奉阳违,声行不一,最最可怕的是,也许将军本人就是那个叛徒,它向不同的军官下发不同的命令,故意使军团覆灭。即,战场上任意一个做决策的人,都可能是叛徒,会任意篡改命令。在这样的外部条件下,是否存在一种算法,使得整个军团可以达成一致的共识,获得成功呢?
Fork Consistency
参考:https://www.jianshu.com/p/e0e310f15626
Blockstack:使用区块链实现分布式互联网
参考:https://zhuanlan.zhihu.com/p/29823215
比特币:proof-of-work
参考:https://www.jianshu.com/p/09a14509aacf
中间人攻击
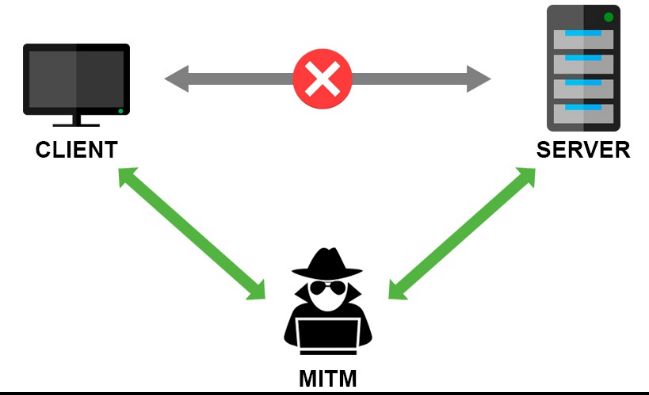
中间人攻击(Man-in-the-MiddleAttack,简称“MITM_攻击_”)是指攻击者与通讯的两端分别创建独立的联系,并交换其所收到的数据,使通讯的两端认为他们正在通过一个私密的连接与对方 直接对话,但事实上整个会话都被攻击者完全控制。在中间人攻 击中,攻击者可以拦截通讯双方的通话并插入新的内容。中间人攻击是一个(缺乏)相互认证的攻击。大多数的加密协议都专门加入了一些特殊的认证方法以阻止中间人攻击。例如,SSL协议可以验证参与通讯的一方或双方使用的证书是否是由权威的受信 任的数字证书认证机构颁发,并且能执行双向身份认证。
中间人攻击过程
- 客户端发送请求到服务端,请求被中间人截获。
- 服务器向客户端发送公钥。
- 中间人截获公钥,保留在自己手上。然后自己生成一个【伪 造的】公钥,发给客户端。
- 客户端收到伪造的公钥后,生成加密hash值发给服务器。
- 中间人获得加密hash值,用自己的私钥解密获得真秘钥。同时生成假的加密hash值,发给服务器。
- 服务器用私钥解密获得假密钥。然后加密数据传输给客户端。
参考
在完成课程的过程中,有参考很多网络的博客和文章,在此对博主们致以诚挚的感谢
其实我很希望我的疑问能得以解答,甚至是若我的笔记中出现错漏,能得以提示和更正