【数据库学习】数据库平台:Postgres(PG)与PostgreSQL
1,概念
2,安装配置与常见命令
1)安装与配置
#安装
yum install https:....rpm
1>安装目录
bin目录:二进制可执行文件目录,此目录下有postgres、psql等可执行程序;pg_ctl工具在此目录,可以通过pg_ctl --help查看具体使用。
conf目录:
empty
include:头文件目录
lib:动态库目录,如libpq.so
share:存放文档和配置模板文件,一些扩展包的sql文件在子目录extension下。
2>数据目录
/var/lib/pgsql/<verson>/data。

i>pg_hba.conf(认证配置文件)
用于配置数据库的远程连接,通过加入以下命令行,运行任何用户远程连接本数据库,连接时需要提供密码。
host replication all 127.0.0.1/32 md5
host replication all 10.99.99.99 md5 # ip为10.99.99.99机器可访问
host all all 0.0.0.0/0 md5 # navicat可访问。md5表示要求客户端提供一个 MD5 加密的口令进行认证。如果改为trust表示无条件地允许联接。
ii>postgresql.conf(主配置文件)
所有配置信息在系统视图pg_settings中可查看,通过context可知修改相关配置后是否需要重启。
- internal 只读参数,初始化实例时写死的。
- postmaster 改变后需要重启。
- sighup/backend 不需要重启,需要向postmaster主进程发送SIGHUP信号,让其重启装配配置新的参数。运行pg_ctl reload命令重新装配。
- superuser 超级用户使用set命令改变。
- user 普通用户使用set命令改变。
## 连接配置项
listen_addresses = '*' # 默认为localhost,这会导致远程主机无法登录数据库。写具体网络ip表示让特定机器登录,*表示所有地址都可监听。
port = 5432 # pg默认端口为5432。多个pg实例可以设置不同端口。
max_connections #允许数据库连接的最大并发连接数,默认100,修改后需要重启。通过sql:show max_connections;也可以查看
superuser_reserved_connections #超级用户连接数。默认为3,为防止普通用户消费连接数过多导致超级用户无法连接pg。
## 日志配置项
logging_collector = on #开启日志收集。pgSQL10已经默认开启
log_directory = 'log' #日志目录。日志切换与覆盖有多种方案,可配。一是每天生成一个新的日志文件;二是日志写满到一定大小开启新文件;三是只保留最近7天日志,循环覆盖(pgSQL10默认模式)。
## 内存配置项
shared_buffers = 4096MB # min 128kB 共享内存大小,主要用于共享数据块。默认值为32MB,尽量设置大一些。具体说明见后文讲解。
work_mem = 4MB # min 64kB 单个SQL执行、排序、Hash Join时使用的内存,执行完毕后释放。设置大一些会提高排序操作效率。具体说明见后文讲解。
max_stack_depth #服务器执行堆栈的最大安全深度,默认为2M。如果发现不能运行复杂的函数时,可以调高此配置,但一个正在运行的递归函数可能会导致pg后台服务进程崩溃,慎重设置。
iii>其它文件
| 文件/目录 | 作用 | 备注 |
|---|---|---|
| PG_VERSION | pg版本号 | |
| postmaster.opts | 记录服务器上次启动的命令行参数 | |
| base | 默认表空间的目录 | 下面子目录以对应数据库的OID命名,对应OID子目录下存放着这个数据库的表、索引等数据文件。OID通过select oid,datname from pg_database;查询。 |
| global | 一些共享系统表的目录 | |
| log | 程序日志目录 | pg10版本之前未pg_log目录 |
| pg_commit_ts | 视图提交的时间戳数据 | pg9.5之后 |
| pg_wal | WAL日志的目录,在pg10之前此目录是pg_clog |
oid(objectID,行对象标识符)
该系统字段只有在创建表时使用了with oids或配置参数default_with_oids的值为真时出现。字段类型也是oid,是4字节无符号整数,不能提供大数据范围内的唯一性保证,因此pg官方不推荐在用户表中使用oid字段。
2)psql命令行操作
# 数据库连接: psql命令在postgresql/bin目录下。
# 添加参数-E可以在执行psql快捷命令时同时输出对应sql。也可以通过命令\set ECHO_HIDDEN on|off控制
psql "host=127.0.0.1 port=5432 user=postgres password=123456 dbname=postgres"
psql -U postgres -d DB_NAME -h localhost -c 'select * from user_info'
# 数据导出-pg_dump命令
pg_dump "host=XX.XX.XX.XX port=5432 user=XXXX password=XXXX dbname=XXXXX" -t table_name -f table_name.sql
# 数据导出-psql命令
psql "host=XX.XX.XX.XX port=5432 user=XXX password=XXX dbname=XXX" -f table_name.sql
常见psql快捷命令(通过psql连接数据库后,通过“\”开头的快捷命令进行数据库相关操作,tab键可补全命令):
| 说明 | 命令 | 备注 |
|---|---|---|
| 退出命令行模式 | \q | |
| 查看数据库 | \l | 小写L |
| 切换数据库 | \c dbName |
|
| 查询当前登录的数据库和用户 | \c |
You are now connected to database “postgres” as user “postgres” |
| 查看sql语法(help) | \h create user | |
| 查看更多命令 | ? | |
| 查看所有表 | \d | |
| 查看结构 | \d name |
name可以包含通配符*或?,可以是表名、索引、视图、序列、函数。如果使用\d+会显示的更详细 |
| 列出所有schema | \dn | |
| 查看所有表空间 | \db | |
| 查看所有角色和用户 | \du或\dg | pg中用户和角色是不区分的 |
| 查看表权限分配情况 | \dp或\z | |
| 查看执行时间 | \timing on sql语句 | |
| 指定客户端字符编码 | \encoding gbk | utf8 |
| 执行外部文件的sql命令 | \i fileName 或 psql -x -f fileName |
|
| 编辑器 | \e | 类似vi,退出vi后会执行其中输入的内容 |
| 查看或编辑函数 | \ef 函数名 | 不加函数名显示函数模板。退出vi后可\reset来清除命令缓冲区数据,防止误操作。 |
| 查看或编辑视图 | \ev 视图名 | 不加函数名显示视图模板。退出vi后可\reset来清除命令缓冲区数据,防止误操作。 |
3)查看版本信息
| 说明 | 命令 |
|---|---|
| 查看客户端版本 | psql --version |
| 查看服务器版本详细信息 | select version(); |
| 查看服务器版本信息 | show server_version; |
| 查看服务器数字版本信息包括小版号 | SHOW server_version_num; |
4)服务启停及原理
1>服务启动
- 直接运行postgres进程
/lwh/postgresql/bin/postgres -D /lwh/data/postgresql & #-D指定数据目录,&表示后台执行。postgres也可以换成postmaster,一回事。如果权限不够在命令前面添加:su postgres -c
- 使用pg_ctl命令启动
/lwh/postgresql/bin/pg_ctl start -D /lwh/data/postgresql #-D指定数据目录
2>服务停止
- 直接向运行的postgres主进程发送signal信号
| signal信号 | 关机模式 | 描述 |
|---|---|---|
| SIGTERM | Smart Shutdown 智能关机 | 服务器将不允许新连接,等所有连接断开才关闭数据库 |
| SIGINT | Fast Shutdown 快速关机 | 不再允许新连接,并向所有子进程发送 SIGINT 信号,让它们立刻退出,然后等待子进程退出后关闭数据库 |
| SIGQUIT | Immediate Shutdown 立即关闭 | 立即关闭并退出,下次启动时数据库重放WAL日志进行恢复。仅用于紧急情况的关闭。 |
- 使用pg_ctl命令停止数据库
#没有权限需要在最前面添加su postgres -c
pg_ctl stop -D dataDir -m smart #对应Smart Shutdown 模式;fast对应 Fast Shutdown;immediate 对应 Immediate Shutdown.具体说明可通过--help查看。默认模式是哪个?谁知道啊???
3>服务检测是否启动
ps aux | grep /lwh/data/postgresql | grep -v grep | wc -l #返回值不为0表示服务存在
ps aux | grep /lwh/data/postgresql | grep -v grep | awk '{print $2}' #返回具体的pid表示服务存在
或者:
netstat -ntlp | grep 5432 #5432为pg默认端口
5)备份与还原
分为逻辑备份和物理备份。
1>pg_dump/pg_dumpall命令
pg_dumpall是将一个pg集群全部转存到另一个脚本文件(sql脚本、归档文件)中,而pg_dump命令可以选择一个数据库或部份表进行备份。pg_dump结合pg_restore使用,能灵活备份和恢复。
2>冷备份
最简单的物理备份就是冷备份,即:停止pg,然后拷贝pg的data目录。
3>热备份
即不停止数据库进行备份,常见的方法有:PITR方法、使用文件系统或块设备级别的快照功能完成备份。Linux下最简单的备份方式是使用LVM的快照功能。
6)时间相关命令
| 说明 | 命令 | 备注 |
|---|---|---|
| 查看数据库启动时间 | select pg_postmaster_start_time() | |
| 查看最后load配置文件的时间 | select pg_conf_load_time() | pg_ctl reload后改变这个时间 |
| 显示当前数据库时区 | show timezone | 时区不一样的情况下,数据库时间和操作系统时间不一致。;PRC: People’s Republic of China |
| 查看当前时间 | select now() | |
| 设置时区 | set time zone ‘GMT’ | PRC为北京时区 |
| 查看所有时区的名字 | SELECT * FROM pg_timezone_names |
7)其它常用命令
| 说明 | 命令 | 备注 |
|---|---|---|
| 当前连接数据库 | select current_catalog, current_database(); | 两者结果一样 |
| 查看pg是否正在做基础备份 | select pg_is_in_backup(),pg_backup_start_time(); | |
| 查看数据库大小 | select pg_database_size('ngsoc'), pg_size_pretty(pg_database_size('ngsoc')); |
pg_size_pretty会转换成MB\GB等格式展示 |
3,数据类型
类型转换:
select '5'::int, '2014-09-09'::date;
select int '5', date '2014-09-09';
常见操作符:
# + - * / %
3 ^ 3 # 幂
|/36.0 #平方根
||/8.0 #立方根
5! 或 !!5 #阶乘,结果都是120
@-5.0 #绝对值
# & (and) |(or) #(XOR) ~(not) << >>
1)布尔(boolean)
值:true\false\NULL
表示方法很多,如下:
create table lwh(id int, a boolean, b boolean);
insert into lwh values (1,true,faLSE);
insert into lwh values (2,'true','false');
insert into lwh values (3,'t','f');
insert into lwh values (4,'y','no');
insert into lwh values (5,'1','0');
select * from lwh;
常用操作符:is、and、or、not
2)数值
1>int
smallint(int2)、int(int4)、bigint(int8);
2>decimal(numeric,精确类型的小数)
decimal精度可达1000,适用于货币金额等要求精度的场合。
会影响运算速度。
3>float
real(非精确类型的浮点小数,float4)、double(非精确类型的浮点小数,float8);
- 浮点数(float)特殊值:Infinity(正无穷大)、-Infinity、NaN(不是一个数字),sql操作:
update table set x='Infinity' #不区分大小写
另外两个浮点数值做相等性比较时可能不符合预期。
4>money(8字节,货币类型)
完全保证精度,不同国家其输出格式不同。
show lc_monetary; #en_US.UTF-8输出就是$1.22
select '1.22' :: money;
set lc_monetary = 'zh_CN.UTF-8'; #通过这个修改,可输出¥1.22
5>serial
serial(自动递增整数,serial4)、bigserial(大的自动递增整数,serial8)。
pg中的自增字段,通过序列(sequence)来实现的。
create table t (
id serial
);
等价于:
create sequence t_id_seq;
create table t(
id integer not null default nextval('t_id_seq')
);
alter sequence t_id_seq owned by t.id;
3)字符( varchar(n)、char(n)、text )
- varchar(n)最大存储1GB,在mysql中最大是64kb; 长度为
(2^n)-1。
(2^n)-1是好的磁盘或内存块对齐,对齐块更快。今天“块”的大小更大,内存和磁盘足够快,可以忽略对齐。 - char(n):定长不足补空白,最大存储1GB,存储空间为4+n。
- text:变长。
在大多数数据库中,定长char(n)有一定的性能优势;但在pg中,定长变长无区别。建议使用varchar(n)、text。
1>常见操作符和函数
| 描述 | 示例 | 结果 | 备注 |
|---|---|---|---|
| 字符串连接 | `‘Post’ | ‘greSQL’` | |
| 字符串拼接 | select CONCAT(‘Post’,‘gre’,‘SQL’) | PostgreSQL | |
| 换为小写 | lower('TOm') |
tom | 做大小写无关的比较时使用 |
| 转换为大写 | upper('TOm') |
TOM | |
| 字符串截取 | substring(str, 1,2) | 第二个参数为起始位置,第三个参数为截取长度(可不填) | |
| 字符index获取 | position(',',str) |
||
| 字符长度获取 | length(str) |
||
| 字符串反转 | reverse(str) |
4)二进制(bytea)
适用于存储图片等信息。
5)位串( bit(n)、bit varying(n) )
是一串由1和0组成的字符串。相比二进制类型,在位操作方面更方便。
- bit(n),必须存储n位。
- bit varying(n),存储最长为n位。
6)日期和时间(date、time、timestamp)
time、timestamp根据是否包括时区又分为两种类型。interval 表示时间间隔。
- pg中世纪可以精确到毫秒。
1>日期函数
--按照当前事务开始的时间返回数据。在整个事务中值不变。
select current_time; --带时区。current_date,current_time, current_timestamp, current_time,current_timestamp(precision)
select localtime; -- 10:13:42.334327,不带时区。localTimestamp, localTime(precision)...
select now(); --2021-01-20 10:14:37.50845+08 包括时区,秒也保留到了6位小数
select now()::timestamp(0)without time zone; --2021-01-20 10:22:41
select transaction_timestamp(); --当前事务开始的时间戳
--返回实时时间,不受事务影响:
statement_timestamp() --当前语句开始时的时间戳
clock_timestamp() --实时时间戳,同一条sql中也可能不同
timeofday() --类似clock_timestamp,但返回值为text字符串
select age(timestamp '2011-05-02', timestamp '1980-05-01') ;--31 years 1 day
select age(timestamp '2011-05-02') ;--9 years 8 mons 18 days, 相当于age(current_date, timestamp '2011-05-02')
| 函数 | 函数说明 | 举例 | 备注 |
|---|---|---|---|
| to_char | 日期转为格式化字符串 | to_char(time,'YYYY-MM-DD hh24:mi:ss') as time1 |
|
| to_date | |||
| to_timestamp |
2>日期运算
- 比较:date、timestamp、long可以通过>=、between and来比较
- 计算
WHERE
create_time BETWEEN (
CURRENT_TIMESTAMP - INTERVAL '3 hour' --日期计算,可以是+或者-
)
AND CURRENT_TIMESTAMP
select date'2020-04-02' + integer'7'; --2020-04-09 date
select date'2020-04-02' + interval'1 hour'; --2020-04-02 01:00:00 timestamp
select date'2020-04-02' + time'3:00'; --2020-04-02 03:00:00 timestamp
select time'3:00' + interval'1 hour'; --04:00:00 time
select -interval'1 hour'; ---01:00:00 interval
select date'2020-04-02' - date'2020-04-01'; --1
--overlaps 两个时间戳重叠为true
select (date '2020-04-02', date '2021-04-02') overlaps
(date '2020-06-02', date '2022-04-02'); --true
3>日期特殊值
| 字符串 | 使用类型 | 描述 |
|---|---|---|
| epoch | date, timestamp | 1970-01-01 00:00:00+00(UNIX系统零时) |
| infinity | timestamp | 时间戳最大值,比任何时间都晚 |
| -infinity | timestamp | 时间戳min |
| now | date, time, timestamp | 当前事务开始时间 |
| today | date, timestamp | 今日午夜 |
| tomorrow | date, timestamp | 明日午夜 |
| yesterday | date, timestamp | 昨日午夜 |
7)枚举
mysql也有枚举类型,用法稍微不同。
create type week as enum ('sun','mon','wed');
create table lwh_duty(person text, weekday week);
insert into lwh_duty values ('mary','sun');
insert into lwh_duty values ('mary','Sun'); --报错,字符串不在枚举类型内。区分大小写。
select * from lwh_duty where weekday = 'Sun'; --报错
--查看枚举类型的定义
select * from pg_enum;
--常见函数
select enum_first('wed'::week);--sun,返回第一个枚举类型。wed可以是任意枚举值即可。同理还有enum_last
select enum_range('wed'::week); --{sun,mon,wed},wed可以是任意枚举值即可。以有序数组的形式返回所有枚举类型
--删除枚举 删除之前要清除所有依赖
drop type enum_lwh_test;
--枚举创建 表字段类型为枚举名即可
create type enum_lwh_test as enum ('confirmed','unconfirmed');
--枚举重命名 会一并修改相关依赖
alter type enum_lwh_test rename to enum_lwh;
--插入新值
ALTER TYPE enum_lwh ADD VALUE 'orange' AFTER 'unconfirmed';
8)几何(pg特有类型)
包括类型:点(point)、直线(line)、线段(lseg)、路径(path)、多边形(polygon)、圆(cycle)。
9)网络地址(cidr、inet、macaddr,pg特有类型)
| 类型名称 | 存储空间 | 描述 |
|---|---|---|
| cidr | 7或19字节 | ipv4或ipv6的网络地址 (总是显示掩码) |
| inet | 7或19字节 | ipv4或ipv6的网络地址或主机地址 |
| macaddr | 6字节 | mac地址 |
--macaddr支持多种格式
select '00e005664477'::macaddr;
select '00E005:664477'::macaddr;--不区分大小写
select '00-E0-05-66-44-77'::macaddr;
select '00E005-664477'::macaddr;
select '00E0.0566.4477'::macaddr;
--运算
select inet'192.0.0.1' < inet '192.0.0.2';-- true。大于等于、不等于<>
select inet'192.0.0.3' << inet '192.0.0.0/24';-- true。包含于<<、包含>>
select ~inet'0.0.0.255'; --255.255.255.0 位非
select inet'0.0.0.255' & inet'0.0.0.255'; --0.0.0.255 位与&,位或|
select inet'192.0.0.50' + 1; --192.0.0.51 + -
select inet'192.0.0.50' - inet'192.0.0.0'; --50
--其它函数……
host(inet) --取主机地址
hostmask(inet) --主机掩码地址
netmask(inet) --子网掩码
10)数组(pg特有类型)
数组的类型可以是数据库内建的类型、用户自定义的类型、枚举或者组合类型。
1>定义
--数组可以定义长度、也可以不给。也可以定义多维数组。但定义长度和多维数组在实际使用中是无效的。如下面两种定义是等价的。
create table lwh01(id int, col1 int[], col2 text[][]);
create table lwh01(id int, col1 int[10], col2 text[]);
2>插入
--插入
--数组通过单引号+大括号来表示,具体分隔符通过以下sql来查询,大部分情况下使用的是逗号分隔(box通过分号分隔,其它用逗号)。
select typname, typdelim from pg_type where typname in ('int4','box');
insert into lwh01 values(1, '{1,2,3}', '{1,2,3}');
insert into lwh01 values(2, '{{1,2,3},{1,2,3}}', NULL);
--通过ARRAY关键字使用数组构造器也可以输入数组
insert into lwh01 values(3, ARRAY[1,2,3], ARRAY['1','2','3']);
--二维数组 array输入
insert into lwh01 values(4, ARRAY[[1,2],[2,3]], NULL);
--数组下标输入。默认从1开始,可以手动指定以0开始输入。
insert into lwh01 values(5, '[0:2]={1,2,3}', NUll);
3>查询
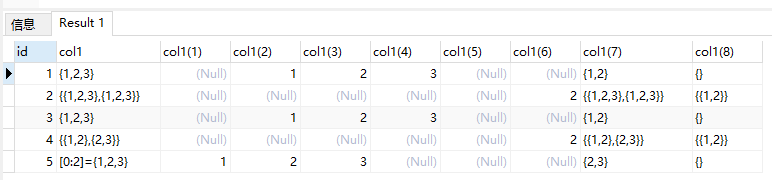
--pg数组下标从1开始(也可以指定下标开始值)
select id, col1, col1[0],col1[1],col1[2],col1[3],col1[4], col1[1][2], col1[1:2], col1[1][1:2] from lwh01;
4>常用操作符
| 操作 | 操作符 | 说明 | 备注 |
|---|---|---|---|
| 等于 | = <> | 两个数组维度、元素个数及值和顺序完全一致为真 | |
| 大于小于 | > < | 按BTree比较函数逐个元素比较 | |
| 包含 | @> | 同理有<@,表示 被包含 |
ARRAY[1,2,3] @> ARRAY[1,2] 结果t |
| 重叠 | && | 是否有共同元素。可跨纬度计算。 | ARRAY[1,2,3] && ARRAY[3,4] 结果为t |
| 连接 | ` | ` |
在jpa中,两个数组取交集,即&&运算这样使用:
select ids && '{1}' :: int[] from book_info; --jpa中,sql的::
5>常用函数
功能| 操作 |备注
–|–|–|–
数组末尾追加 |array_append(ARRAY[2,3], 3); --{1,2,3}
数组连接 | array_cat(ARRAY[2,3],ARRAY[2,3]); --{2,3,2,3}
数组中移除特定值 | array_remove(ARRAY[2,3], 2); --{3} | 只支持一维数组
数组中替换某个值| array_replace(ARRAY[2,3],3,5);--{2,5} | 针对所有维度的数据
array2string | array_to_string(ARRAY[2,3],','); --2,3
string2array| string_to_array('1,2,3', ','); --{1,2,3}
聚合函数array_agg:
select id, col3 from lwh01;--int, int
id col3
1 1
2 2
2 3
1 4
2 5
select id, array_agg(col3) from lwh01 group by id; --int array
id array_agg
2 {2,3,5}
1 {1,4}
11)复合类型(用户自定义类型)
类似于C的结构体,
12)xml类型
可以存储xml类型,自动校验是否合法。
13)json/jsonb
postgresql支持两种json数据类型:json和jsonb。与text不同,会自动校验格式是否合法。
1>概念
主要区别在于效率:json类型存储快,使用慢;jsonb类型存储稍慢,使用较快。
json是对输入的完整拷贝,使用时再去解析,所以它会保留输入的空格,重复键以及顺序等。
jsonb是解析输入后保存的二进制,它在解析时会删除不必要的空格和重复的键,顺序和输入可能也不相同。使用时不用再次解析。
json类型和pg类型映射:
| json类型 | pg类型 | 备注 |
|---|---|---|
| string | text | |
| number | numeric | json中没有pg的“NAN”和“infinity”值 |
| boolean | boolean | json仅支持小写的true false |
| null | (none) | sql中NULL表示的意思不同 |
2>常用函数和操作符
json和jsonb的操作与函数基本通用。
①数组操作
json和jsonb通用:
--如果用操作符->>,取出数据会自动转换为text
select '[{"a":"foo"},{"b":"bar"},{"c":"baz"}]'::json->2; --{"c":"baz"} 索引从0开始,从数组中取出index=2的对象
select '["a", "b"]'::jsonb ?& array['a', 'b']; --true array中是否包含某些键(top-level keys,这些键是一个数组)
select '["a", "b"]'::jsonb || '["c", "d"]'::jsonb; --["a", "b", "c", "d"] 两个数组求并集
select '["a", "b"]'::jsonb || '["c", "d"]'::jsonb; --两个数组求并集
select (ARRAY[11] || (select type from field where label = '名称') )
select '["a", "b"]'::jsonb - 1; --["a"] 数组去除某个索引
select '["a", {"b":1}]'::jsonb #- '{1,b}'; --["a", {}] 数组去除某个路径的键
--各种格式生成array
select json_build_array(1,2,'3',4,5); --[1, 2, "3", 4, 5]
select array_to_json('{{1,5},{99,100}}'::int[]); --[[1,5],[99,100]]
select json_array_length('[1,2,3,{"f1":1,"f2":[5,6]},4]'); --5 数组长度
select * from json_array_elements('[1,true, [2,false]]');--取出数组中所有元素 json_array_elements_text返回text
②map操作
json和jsonb通用:
--如果用操作符->>,取出数据会自动转换为text
select '{"a": {"b":"foo"}}'::json->'a'; --{"b":"foo"} 从map中取出key为a的值
--如果用操作符#>>,取出数据会自动转换为text
select '{"a": {"b":"foo"}}'::json #>'{a,b}'; --"foo" map输出特定路径对象
select '{"a":1, "b":2}'::jsonb @> '{"b":2}'::jsonb; --true map中是否包含某个键值对 同理还有<@
select '{"a":1, "b":2}'::jsonb ? 'b'; --true map是否包含某个键(top-level keys)
select '{"a":1, "b":2, "c":3}'::jsonb ?| array['b', 'c']; --true map中是否包含某些键(这些键是一个数组)
select '{"a": "b"}'::jsonb - 'a'; --{} map剔除某个键
select '{"a": "b", "c": "d"}'::jsonb - '{a,c}'::text[]; --{} map剔除某些键
--各种格式生成map
select row_to_json(row(1,'foo','1')); --{"f1":1,"f2":"foo","f3":"1"}
select json_build_object('foo',1,'bar',2); --{"foo" : 1, "bar" : 2}
select json_object('{a, 1, b, "def", c, 3.5}'); --{"a" : "1", "b" : "def", "c" : "3.5"}
select json_object('{{a, 1},{b, "def"},{c, 3.5}}');
select json_object('{a, b}', '{1,2}'); --{"a" : "1", "b" : "2"}
select * from json_each('{"a":"foo", "b":"bar"}'); --把jsonMap转换为键值对 json_each_text返回text
--通过键路径获取值 json_extract_path_text返回text
select json_extract_path('{"f2":{"f3":1},"f4":{"f5":99,"f6":"foo"}}','f4'); --{"f5":99,"f6":"foo"}
select json_extract_path('{"f2":{"f3":1},"f4":{"f5":99,"f6":"foo"}}','f4','f6');--"foo"
③常用函数
select to_json('Fred said "Hi."'::text); --"Fred said \"Hi.\"" string2json
select json_typeof('-123.4'); --number
--修改jsonb jsonb_set
jsonb_set('[{"f1":1,"f2":null},2,null,3]', '{0,f1}','[2,3,4]', false)
-- attributes为jsonb类型字段(对象转成的json)
-- 第一个参数表示jsonb对象,第二个参数表示路径text[],第三个参数表示value(jsonb对象),第四个值表示无此值是否新建(默认为true)
原值:{"a":"1"}
update user_test set attributes = jsonb_set(attributes,'{a}','"0"'::jsonb, false) where id = '8888';
执行后:{"a":"0"}
3>索引
json类型没办法直接建索引,但是可以建函数索引。
jsonb类型的列上可以建索引,GIN索引可以高效的从jsonb内部的key/value对中搜索数据。(BTree索引效率较低)
GIN索引创建方式:
--使用默认的操作符jsonb_ops创建GIN索引:
--每个key和value都作为一个单独的索引项
--如:{“foo”:{“bar”:“baz”}},会创建3个索引项:“foo” “bar” “baz”
create index idx_name on table_name using gin(index_col);
--使用jsonb_path_ops操作符建GIN索引:(推荐)
--为每个value创建一个索引项
--如:{“foo”:{“bar”:“baz”}},会创建1个索引项:“foo” “bar” “baz”组合成一个Hash值作为索引项。因为索引相对较小,带来性能的提升。
create index idx_name on table_name using gin(index_col jsonb_path_ops);
14)range(范围类型,pg特有类型)
主要用于范围快速搜索。
直接通过库里的开始值和结束值进行范围搜索效率较低,而使用range类型,通过创建空间索引的方式来执行范围搜索会大大提高效率。
15)对象标识符
16)伪类型
不能作为pg的字段,主要用于声明函数的参数和结果类型。
17)其他类型
| 类型 | 描述 | 备注 |
|---|---|---|
| UUID | 128字节的数字。 | pg核心库没有提供生成UUID的函数 |
| pg_lsn | pg9.4以上版本支持。用于表示LSN的数据类型,64位大整数。 | LSN表示WAL日志的位置 |
4,SQL语法
1)库操作
创建、修改、删除、使用与常规sql语法一致。
查询当前数据库:
select current_database();
查询当前用户:
select user; 或者:select current_user;
2)模式
创建、修改、删除、使用与常规sql语法一致。
默认模式位public。
3)表操作
创建、修改、删除、使用与常规sql语法一致。。
pg表也支持TOAST(跨页存储的大字段,需要将行外数据存储到TOAST表)。
--获取数据库中所有表
select * from pg_tables where schemaname='public';
1>更新插入一体
当主键或者unique key发生冲突时,什么都不做(同时也适用于多个字段的唯一性约束):
INSERT INTO test.upsert_test(id, "name")
VALUES(1, 'm'),(2, 'n'),(4, 'c')
ON conflict(id) DO NOTHING;
upsert方法,冲突则更新,否则插入:
insert into "public"."user"
(id, name)
values(1,'a')
ON conflict(id)
DO UPDATE SET
name = 'b';
2>查询
表查询没有指定查询顺序时,按插入顺序进行排序。
--查询一个表是否存在
select count(*) from pg_class where relname = 'tablename';
--查询所有的表
SELECT * FROM pg_tables;
--查询所有的视图
SELECT * FROM pg_views;
--查询表结构
SELECT a.attnum,a.attname AS field,t.typname AS type,a.attlen AS length,a.atttypmod AS lengthvar,a.attnotnull AS notnull,b.description AS comment FROM pg_class c,pg_attribute a LEFT OUTER JOIN pg_description b ON a.attrelid=b.objoid AND a.attnum = b.objsubid,pg_type t WHERE c.relname = 'person_wechat_label' and a.attnum > 0 and a.attrelid = c.oid and a.atttypid = t.oid ORDER BY a.attnum;
--从数据库中导出数据到文件
\copy (select * from "user") to '/tmp/1.txt';
a)similar to(pg特色)
类似like的用法,在like的基础上又增加了与POSIX正则表达式相同的模式匹配元字符。
select label FROM classify where label similar to '(36)+%' ;--检索以36开头或3636……开头的数据
select label FROM classify where label like '(36)+%' ; --检索(36)+开头的数据
| 元字符 | 功能 |
|---|---|
() |
表示独立逻辑项目 |
| ` | ` |
* |
重复前面的项0次或更多次 |
+ |
重复前面的项一次或更多次 |
? |
重复前面的项0次或1次 |
{m} |
重复前面的项m次 |
{m, } |
重复前面的项m次或更多次 |
{m,n} |
重复前面的项至少m次,不超过n次 |
[…] |
b)POSIX 正则表达式
pg中有两种正则表达式:
| 区别 | SQL正则表达式 | POSIX 正则表达式 |
|---|---|---|
| 概念 | 遵循sql语句中like、similar to语法 | 脚本语言中的标准正则表达式 |
| 任意一个字符 | _ |
. |
| 任意个字符 | % |
.* |
POSIX 正则表达式:
| 模式匹配操作符 | 功能 |
|---|---|
~ |
匹配正则表达式,区分大小写 |
~* |
匹配正则表达式,不区分大小写 |
!~ |
不匹配正则表达式,区分大小写 |
!~* |
- |
--下面两种语句功能一致:
select 'osdba' ~'a'; --t
select 'osdba' similar to '%a%'; --t
select 'osdba' ~'b|a';--t
c) substring函数(pg特色)
这个函数功能强大,可以使用正则表达式。
3>表继承
表继承是pg特有的。
create table persons_lwh(
name text,
age int,
sex boolean
);
create table students_lwh(
class_no int
)INHERITS(persons_lwh); --继承。
--父表的检查约束、非空约束会被子表继承,但唯一、主键、外键约束子表不会继承。
--一个子表可以继承多个父表,多个相同字段必须类型一致,融合后在子表中只有一个字段。
insert into students_lwh values('Mary',15,true,1); --向子表插入数据,父子表都有数据
insert into persons_lwh values('Bob',15,true);--向父表插入数据,只有父表有数据
select * from persons_lwh;
select * from students_lwh;
select * from only persons_lwh; --添加only,只获取直接插入父表的数据
4>表空间
pg中的表空间就是为表一指定个存储目录,主要用于把表存放到不同的存储目录。
4)表分区
1>概念
表分区是逻辑上把大表分割成物理上几块,如按时区分、按类型分等。
优点
- 删除更快。如按时间分区,删除历史数据直接删除对应分区表。
- 查询更快。如按时间分区,较早时间的表几乎很少查询,各个分区表有各自的索引,使用频率高的分区表的索引就可以完全缓存到内存中。
- 修改更快。访问具体分区表,而不是全表扫描。
- 节省资源。根据访问频率把不常访问的数据存储到不同的物理介质上。
2>表继承分区
--表继承
create table sales_detail(...sale_date...);--父表,不存数据
create table sales_detail_y2014m01 (
check (sale_date >= DATE'2014-01-01' and sale < DATE'2014-02-01') --check约束
)INHERITS(sales_detail); --子表继承父表
--在各个分区表的分区键上建立索引
create index sales_detail_y2014m01_sale_date on sales_detail_y2014m01 (sale_date);
--建立规则或触发器,把对主表的数据插入重定向到具体分表。
create RULE sales_detail_insert_y2014m01 AS
ON insert to sales_detail where
(sale_date >= DATE'2014-01-01' and sale < DATE'2014-02-01')
DO INSTEAD
insett into sales_detail_y2014m01 values(NEW.*);
分表通过规则或触发器优缺点对比:
- 相比触发器,规则开销很大。批量插入的情况下,规则效率更高。
- copy插入数据不会触发规则,但会触发触发器。
- 分表之外的数据,再次插入父表时,触发器会报错,但规则会把这些规则之外的数据插入主表。
3>声明式分区
pg内部通过表继承来实现分区表。pg10.x通过声明式分区直接创建分区表,但其内部原理依然是表继承。
相比表继承分区,不需要在父表创建各种触发器(降低维护成本),对父表的DML操作会自动路由到相应分区。
目前仅支持范围分区和列表分区。
--范围分区
--创建主表
1. 创建全局主键必须携带分区字段
2. 不允许全局创建索引,可以在分表上创建索引。
3. 删除主表不会删除子表,通过级联删除可以一起删除。
4. 查询主表时若在where条件中携带分区字段(如日期),可直接去分区表检索,提高检索速度。注意:这个字段不包含运算,否则失效。
create table sales_detail(
...
sale_date date not null,
...
) PARTITION BY RANGE(sale_date); --通过PARTITION BY来支持分区。不能给没有分区表的分区插入数据。
--创建分区表(分区表需要手动进行创建,可以用定时任务一次创建多个)
create table sales_detail_y2014m01 PARTITION OF sales_detail --通过PARTITION OF指定分区表分区。
FOR VALUES FROM ('2014-01-01') TO ('2014-02-01');
--查看所有的分区表
select relname from pg_catalog.pg_class where relispartition = 't';
--列表分区
create table test_list_part(id int, state boolean) PARTITION BY list(state);
create table test_list_part_t partition of test_list_part for values in ('t');
create table test_list_part_f partition of test_list_part for values in ('f');
insert into test_list_part values ('1','t');
insert into test_list_part values ('1','f');
create index on test_list_part_f (state);
create index on test_list_part_t (state);
④优化
1.打开约束排除(postgresql.conf中的constraint_exclusion设置为on)。
sql查询中,where语句的过滤条件与分区表的check条件进行对比,直接跳过不需要扫描的分区表。
注意:分区字段的where语句如果包含计算,可能会扫描全表,需要解释执行确认。
select count(*) from sales_detail where sale_date >= DATE'2014-12-01';--同各个分区表上的check条件进行对比,可知只需要扫描主表和分表sales_detail_y2014m12。
⑤主键
可能我的navicat版本太低了看不见主键,通过以下sql可以查询到主键。
SELECT
pg_attribute.attname AS colname,
pg_type.typname AS typename,
pg_constraint.conname AS pk_name
FROM
pg_constraint
INNER JOIN pg_class ON pg_constraint.conrelid = pg_class.oid
INNER JOIN pg_attribute ON pg_attribute.attrelid = pg_class.oid
AND pg_attribute.attnum = pg_constraint.conkey [ 2 ]
INNER JOIN pg_type ON pg_type.oid = pg_attribute.atttypid
WHERE
pg_class.relname = 'tbl_alarm_judge_conclusion'
AND pg_constraint.contype = 'p';
--pg_constraint.contype : c = 检查约束, f = 外键约束, p = 主键约束, u = 唯一约束 t = 约束触发器 x = 排斥约束
5)序列
序列对象(也叫序列生成器)就是用CREATE SEQUENCE 创建的特殊的单行表。一个序列对象通常用于为行或者表生成唯一的标识符。通常用于表的主键自增。
mysql中的序列有以下两个限制,但pg中的序列没有。
- 自增长只能用于表中的一个字段;
- 自增长只能被分配给固定表的固定的某一个字段,不能被多个表使用。
①创建
1> serial
将id类型设置为:serial,pg会自动创建一个序列,同时将列设置为INT,默认值设置为nextval(‘序列’)。serial8会将列设置为int8(long)
2> sequence(序列)
--[TEMPORARY | TEMP] 临时序列,在会话结束时自动删除;除非用模式修饰,否则同一个会话中同名的非临时序列是不可见的。
create [TEMPORARY | TEMP] sequence seq_name;
--nextval('seq_name') 表示递增序列seq_name并返回新值。字符串会自动转换为regclass类型
--setval('seq_name', bigint) 设置序列当前数值
create table test (id int default nextval('seq_name'), info text);
CREATE SEQUENCE
IF NOT EXISTS PUBLIC .role_id_seq --序列名
START WITH 1 --指定序列的起点,缺省初始值对于递增序列为minvalue, 对于递减序列为maxvalue。
INCREMENT BY 1 --递增量,缺省为1;递减为负数
NO MINVALUE --指定序列的最小值, 如:minvalue 1
NO MAXVALUE --指定序列的最大值,递减序列最大值为-1
CACHE 1 --为快速访问而在内存里预先存储多少个序列号,缺省值为1,表示一次只能生成一个值,也就是说没有缓存。
OWNED BY {table.column | NONE} --将序列关联到一个特定的表字段上,在删除该字段或其所在的表时将自动删除绑定的序列;NONE表示无关联。
CYCLE --默认不添加cycle选项,创建出来的序列满时会报错;添加cycle时,序列会从开始值重新开始。
;
② 给已有的字段创建添加自增,并且自增值从最大的id+1开始
--将下一次的自增值设置成最大id+1
select setval('user_info_id_seq',(select max(id)+1 from user_info));
③修改序列
alter sequence serial
increment by 3
restart with 10; --是一个可选选项,它改变序列的当前值
select nextval('serial');
④删除序列
DROP SEQUENCE [ IF EXISTS ] name [, ...] [ CASCADE | RESTRICT ]
--IF EXISTS 如果指定的序列不存在,那么发出一个 notice 而不是抛出一个错误。
--CASCADE 级联删除依赖序列的对象。
--RESTRICT 如果存在任何依赖的对象,则拒绝删除序列。这个是缺省。
drop sequence serial;
⑤序列和事务
事务回滚不会影响序列。
begin;
select netval('seqtest01'); --3
rollback;
select currval('seqtest01'); --3
⑥cache
如果cache大于1,当序列被用于多会话时,每个会话在每次访问序列对象的过程中都会分配并缓存随后的序列值,会话结束时丢失没有使用的数字,从而导致序列出现空洞。
多个会话的情况下,如果cache大于1,那么只能保证nextval值是唯一的,缺不按顺序生成。比如cache=10,会话A保留了1……10并且返回nextval=1,会话B保留了11……20。会话A返回nextval=1之前会话B可能先返回nextval=11。
6)触发器(Trigger)
触发器是一种由事件自动触发执行的特殊的存储过程。主要用于加强数据的完整性约束和业务规则上的约束。
PostgreSQL的触发器是数据库自动执行\指定的数据库事件发生时调用的回调函数。
注意:
- 如果有多个相同类型的触发器定义了相同的事件,他们将被触发名称是按字母顺序排列。
1>创建触发器
语句触发:(修改0行的操作依然会触发。按语句触发,而不管这条语句操作了多少行)
CREATE TRIGGER stu_trigger
AFTER INSERT OR DELETE OR UPDATE ON stu_info --AFTER 可以换成BEFORE,在语句执行前触发。行级别的AFTER触发器在任何语句级别的AFTER触发器之前触发。
FOR STATEMENT EXECUTE PROCEDURE stu_trigger_function ();
针对字段触发:
CREATE TRIGGER stu_trigger
AFTER INSERT OR UPDATE OF birthday OR DELETE ON stu_info
FOR EACH ROW EXECUTE PROCEDURE stu_trigger_function (); --stu_trigger_function 为触发函数
行触发:(如果执行的语句没有更新实际的行,那么不会+触发)
CREATE TRIGGER example_trigger
AFTER INSERT OR DELETE OR UPDATE ON COMPANY
FOR EACH ROW EXECUTE PROCEDURE auditlogfunc();
2>删除
触发器删除不会删除对应的触发函数;但删除表时,表上的触发器会一并删除。
DROP TRIGGER if exists stu_trigger ON stu_info [CASCADE | RESTRRICT]; --中括号中的可省略。CASCADE 级联删除依赖此触发器的对象;RESTRRICT是默认值,有依赖对象存在就拒绝删除。
3>触发函数
触发函数有返回值。
对于BEFORE和INSTEAD OF这类行级触发器来说:
- 返回NULL,表示忽略当前行的操作。也不会触发其它触发器。
- 返回非NULL:对于INSERT和UPDATE操作来说,返回的行将成为被插入的行或者将要更新的行。
- 每个触发器返回的行将成为下一个触发器的输入。
对于AFTER这类行级触发器:返回值会被忽略。
触发函数常用特殊变量:
NEW:
1. INSERT/UPDATE 行级触发器中新的数据行,数据类型是RECORD;
2. 语句级别触发器、DELETE操作触发器 中此变量未分配。
OLD:
3. UPDATE/DELETE 行级触发器中原有的数据行,数据类型是RECORD;
4. 语句级别触发器、INSERT操作触发器 中此变量未分配。
TG_NAME: 触发器名。数据类型:name。
TG_WHEN: 是 BEFORE/AFTER 触发器。
TG_LEVEL:是 ROW/STATEMENT 触发器。
TG_OP:是 INSERT/UPDATE/DELETE/TRUNCATE 之一的字符串,表示DML语句类型。
TG_TABLE_NAME:触发器所在表的名称。同理有TG_TABLE_SCHEMA(模式)。
CREATE
OR REPLACE FUNCTION stu_trigger_function () RETURNS TRIGGER AS
$BODY$
DECLARE
_birthday TIMESTAMP;
_id int;
BEGIN
IF TG_OP = 'INSERT' THEN
SELECT birthday INTO _birthday FROM stu_info WHERE name= NEW .name AND class_id= NEW .class_id;
IF _birthday is NULL THEN
INSERT INTO stu_info ( ID, name, birthday , class_id) VALUES ( NEW . ID, NEW .name, NEW .first_occur_time, NEW .class_id) ;
ELSE IF NEW .birthday < _birthday THEN
UPDATE stu_info SET ID = NEW . ID, birthday = NEW .birthday ;
END IF ;
END IF ;
ELSE IF TG_OP = 'DELETE' THEN
DELETE FROM stu_info A WHERE A . ID = OLD . ID ; RETURN OLD ;
ELSE IF TG_OP = 'UPDATE' THEN
if UPDATE(birthday ) THEN
SELECT ID,birthday INTO _id, _birthday FROM stu_info WHERE class_id= OLD .class_id AND name= OLD .name;
IF ( _id != 0 AND _birthday > OLD .birthday ) THEN
UPDATE stu_info SET ID = _id, birthday = _birthday ;
END IF ;
END IF;
END IF ;
END IF ;
END IF ;
RETURN NEW; --语句级触发函数可以显示的写:RETURN NULL
END ;
$BODY$
LANGUAGE plpgsql;
--删除触发函数
drop FUNCTION add_stu_trigger();
4>事件触发器
pg9.3开始支持Event Trigger,主要用于弥补pg以前版本不支持DDL触发器的不足。
7)函数
1>创建
CREATE [OR REPLACE] FUNCTION function_name (arguments)
RETURNS return_datatype AS $variable_name$
DECLARE
declaration;
[...]
BEGIN
< function_body >
[...]
RETURN { variable_name | value }
END; LANGUAGE plpgsql;
function_name:指定函数的名称。
arguments: 函数参数
[OR REPLACE]:是可选的,它允许修改/替换现有函数。
DECLARE:定义参数(参数名写在前面 类型写在后面)。
BEGIN~END: 在中间写方法主体。
RETURN:指定要从函数返回的数据类型(它可以是基础,复合或域类型,或者也可以引用表列的类型)。
LANGUAGE:它指定实现该函数的语言的名称。 可以是SQL,PL/pgSQL,C, Python等。
2>函数的参数说明
| 参数 | 说明 |
|---|---|
| IN | 可以将 IN 参数传递给函数,但无法从返回结果里再获取到。 |
| OUT | OUT 参数经常用于一个函数需要返回多个值,所以不需要 RETURN 语句。 |
| INOUT | INOUT 参数是 IN 和 OUT 参数的组合。这意味着调用者可以将值传递给函数,函数然后改变参数并且将该值作为结果的一部分传递回去。 |
| VARIADIC | PostgreSQL 函数可以接受可变数量的参数,其中一个条件是所有参数具有相同的数据类型。参数作为数组传递给函数。 |
参数使用例子:
CREATE OR REPLACE FUNCTION hi_lo(
IN a NUMERIC,
IN b NUMERIC,
OUT c NUMERIC,
OUT hi NUMERIC,
INOUT lo NUMERIC)
AS $$
BEGIN
c:= GREATEST(a,b);
hi:= LEAST(a,b);
lo:=GREATEST(a,b);
END; $$
LANGUAGE plpgsql;
3>函数重载
与 Java 等编程语言相同,PostgreSQL 允许多个函数具有相同的名称,只要参数不同即可。如果多个函数具有相同的名称,那么我们说这些函数是重载的。当一个函数被调用时,PostgreSQL 根据输入参数调用确切的函数。
4>块结构
一个 PostgreSQL 函数由块(block)进行组织。
[ DECLARE
声明 ] --可以没有
BEGIN
主体; --必需
...
END;
--声明部分中的每个语句都以分号(;)结尾。 主体部分中的每个语句也以分号(;)结尾。
8)视图
--获取数据库中所有view
select * from pg_views where schemaname='public';
9)索引
10)用户及权限管理
pg中角色和用户没区别。超级用户为postgres。
11)事务、并发和锁
- 保存点(savePoint):在一个大的事务中,可以把操作过程分成几个部分,第一个部分执行成功后可以建一个保存点,若后面的部分执行失败,则回滚到此保存点,而不必回滚整个事务。
- 咨询锁(Advisory Lock):session级别和事务级别。pg数据库提供一种与具体表数据无关的锁,pg将变成一个锁服务提供中心。主要场景:多个进程访问同一个数据库、分布式系统中类似Zookeeper的锁服务。
12)规则(Rule)
规则系统更准确地说是查询重写规则系统,使用时也可以被函数和触发器替代,但原理和使用场景不同(这在上文讲分表的时候就提到过)。对于批量操作,规则比触发器效率更高。
1>SELECT规则
create RULE "_RETURN" as on select to myview Do instead select * from mytable;
#相当于create table myview (same column list as mytab);
2>更新规则
create [or replace] RULE name as on event #event 值为SELECT/INSERT/UPDATE/DELETE
to tableName [where condition]
do [also | instead] {nothing | command} # also表示执行原操作后还执行一些附加操作 如:also insert into mytab_log...; instead表示把原操作替换为后面的command操作
3>权限
规则从属于表和视图
5,执行计划
explain sql语句; #查看执行计划。也可以使用navicat的解释功能查看。
1)多表连接查询
①Nest Loop Join(嵌套循环连接)
1>场景
适合两个表的数据量都比较少的情况(最简单的 table join 方式)。
- 外表为小表,且过滤后的数据量较少。
- 内表的关联列上有高效索引(主键或者唯一性索引)。
2>举例
# 内表(t4)被外表(t5)驱动。外表返回的每一行都要在内表中检索找到与它匹配的行,因此整个查询返回的结果集不能太大(大于1 万不适合)
select t4.*,t5.*
from tmp_t4 t4,
tmp_t5 t5
where 1=1
and t4.id = t5.id
and t4.id = 1;
相当于for循环:
for(t4.data in tmp_t4)
{
t5.data in tmp_t5 on t5.data = t4.data
}
②Hash JOIN(哈希、散列连接)
1>场景
针对那些没有索引或者其中任一个有索引的大表。
哈希连接只能应用于等值连接(如WHERE A.COL3 = B.COL4)、非等值连接(WHERE A.COL3 > B.COL4)、外连接(WHERE A.COL3 = B.COL4(+))。
2>操作步骤
优化器使用两个表中较小的表(或数据源)利用连接键在内存中建立散列表,然后扫描较大的表并探测散列表,找出与散列表匹配的行。
这种方式适用于较小的表完全可以放于内存中的情况,这样总成本就是访问两个表的成本之和。但是在表很大的情况下并不能完全放入内存,这时优化器会将它分割成若干不同的分区,不能放入内存的部分就把该分区写入磁盘的临时段,此时要有较大的临时段从而尽量提高I/O 的性能。
③Sort Merge JOIN
1>场景
通常Hash JOIN的性能都优于Merge JOIN,对于那些连接列上有索引的表(已排好序)Merge JOIN性能会优于Hash JOIN。
2>操作步骤
mrege join的性能开销几乎都在前两步。
- 对连接的每个表做全表扫描(table access full);
- 对table access full的结果进行排序。
- 进行merge join对排序结果进行合并。
在全表扫描比索引范围扫描再通过rowid进行表访问更可取的情况下,merge join会比nested loops性能更佳。当表特别小或特别巨大的时候,实行全表访问可能会比索引范围扫描更有效。
6,数据库优化
1)SQL优化
对于重复的代码逻辑,sql执行速度远远大于代码逻辑。
但是,由于sql难以测试、难以复用、难以加工变量,对于复杂的逻辑不建议用在sql中。代码可以分成模块、逻辑独立、方便测试。
sql优化的思路有两种:一是:
The fastest way to do something is don’t do it
即去掉无用的步骤;二是优化算法,如让sql走更优的执行计划上。
①基于规则优化(RBO)和基于代价优化(CBO)
RBO和CBO是两种数据库引擎在执行sql语句时的优化策略。
基于规则的优化(Rule Based Optimizer)
这是一种比较老的技术,简单说基于规则的优化就是当数据库执行一条query语句的时候必须遵循预先定义好的一系列规则(比如oracle的15条规则,排名越靠前的执行引擎认为效率越高)来确定执行过程,它不关心访问表的数据分布情况,仅仅凭借规则经验来确定,所以说是一种比较粗放的优化策略。
基于代价的优化(Cost Based Optimizer)
基于代价的优化的产生就是为了解决上面RBO的弊端,让执行引擎依据预先存储到数据库中表的一些实时更新的统计信息来选择出最优代价最小的执行计划来执行query语句,CBO会根据统计信息来生成一组可能被使用到的执行计划,进而估算出每个计划的代价,从而选择出代价最小的交给执行器去执行,其中表的统计信息一般会有表大小,行数,单行长度,单列数据分布情况,索引情况等等。
总结:
基于规则的优化器更像是一个经验丰富熟知各条路段的老司机,大部分情况可以根据自己的经验来判断走哪条路可以更快的到达目的地,而基于代价的优化更像手机里面的地图,它可以选择出许多不同的路径根据实时的路况信息综合考虑路程长度,交通状况来挑出最优的路径。
2)配置优化
pg中与内存有关的配置参数:
1>shared_buffers(共享缓存区)
i>工作原理
shared_buffers是一个8KB的数组,postgres在从磁盘中查询数据前,会先查找shared_buffers的页,如果命中,就直接返回,避免从磁盘查询。
多个进程通过共享内存技术来共享缓存中的数据。
-
shared_buffers存储什么?
表数据;
索引,索引也存储在8K块中;
执行计划,存储基于会话的执行计划,会话结束,缓存的计划也就被丢弃。 -
什么时候加载shared_buffers?
1)在访问数据时,数据会先加载到os缓存,然后再加载到shared_buffers,这个加载过程可能是一些查询,也可以使用pg_prewarm预热缓存。
2)当然也可能同时存在os和shared_buffers两份一样的缓存(双缓存)。
3)查找到的时候会先在shared_buffers查找是否有缓存,如果没有再到os缓存查找,最后再从磁盘获取。
4)os缓存使用简单的LRU(移除最近最久未使用的缓存),而数据库采用的优化的时钟扫描,即缓存使用频率高的会被保存,低的被移除。
ii>优化策略
提高shared_buffers,增加缓存命中率,提高查询效率。
同时为了避免Double Buffering问题,将shared_buffers设置较小,更多的内存留给文件系统使用。
-
【Double Buffering(双缓存)】问题:
pg的数据文件都存储在文件系统中,os的文件系统也有缓存,这导致pg的数据库副本可能同时存在于共享内存和文件系统中,造成内存利用率低的问题。
Oracle中通过设置Birect I/O避免双缓存问题,但pg不支持。 shared_buffers的大小不应该超过内存的1/4。 -
shared_buffers设置的合理范围
1)windows服务器有用范围是64MB到512MB,默认128MB
2)linux服务器建议设置为25%,亚马逊服务器设置为75%(避免双缓存,数据会存储在os和shared_buffers两份)
os缓存的重要性:数据写入时,从内存到磁盘,这个页面就会被标记为脏页,一旦被标记为脏页,它就会被刷新到os缓存,然后写入磁盘。所以如果os高速缓存大小较小,则它不能重新排序写入并优化io,这对于繁重的写入来说非常致命,因此os的缓存大小也非常重要。给予shared_buffers太大或太小都会损害性能。 -
shared_buffers调整策略
2> work_mem
为每个进程单独分配的内存,主要用于group by, sort, hash agg, hash join 等操作。
注意:work_mem是每次分配的内存,加入有M个并发进程,每个进程有N个HASH操作,那么需要分配的内存为 MNwork_mem。因此work_mem不宜设置太大,通常保持默认的4MB即可,如果设置的太大超过256MB,很容易因为瞬间的大并发操作导致oom。
3>maintenance_work_mem
为每个进程单独分配的内存,主要进行维护操作时需要的内存,如VACUUM、create index、ALTER TABLE ADD FOREIGN KEY等操作需要的内存。
4>autovacuum_work_mem
pg9.4版本新增参数。
9.4之后,AutoVacuum的worker进程分配的内存由参数autovacuum_work_mem控制,手动Vacuum时分配的内存由maintenance_work_mem 控制。9.4之前都用maintenance_work_mem 参数。
默认值为-1,表示与maintenance_work_mem 一样。
vacuum 大小 = autovacuum_max_workers * autovacuum_work_mem
5>temp_buffers(临时表缓存)
为每个不同的进程单独分配的内存,不在共享内存中,默认为8MB。
6>wal_buffers(WAL日志缓存大小)
默认为-1,表示根据shared_buffer的大小自动设置。
7>huge_pages(是否使用大页)
默认值为try,表示尽量使用大页。若os未开启大页,不使用大页内存,不影响数据库正常使用。
8>effective_cache_size(sql执行中的实际磁盘缓存)
与具体内存分配无关
3)sql审计
相关配置:
| 参数调整 | 说明 |
|---|---|
| log_min_duration_statement | sql审计记录的标准,超过该时长的sql将被记录到日志文件。默认为-1,不记录超时sql。 |
| log_statement | none默认,不记录;all-记录所有语句;ddl-记录所有数据定义语句;mod记录所有ddl和数据修改语句; |
| log_min_error_statement | 控制日志中是否记录导致数据库出现错误的SQL语句。默认为error |
4)排查sql
-- 查看表结构
SELECT column_name,data_type FROM information_schema.columns WHERE table_name = '表名';
-- 展示在数据库中当前正在执行多少查询
SELECT datname, count(*) AS open, count(*) FILTER (WHERE state = 'active') AS active, count(*) FILTER (WHERE state = 'idle') AS idle, count(*) FILTER (WHERE state = 'idle in transaction') AS idle_in_trans FROM pg_stat_activity GROUP BY ROLLUP(1)
-- 查看事务已经打开了多久
SELECT pid, xact_start, now() - xact_start AS duration FROM pg_stat_activity WHERE state LIKE '%transaction%' ORDER BY 3 DESC;
-- 检查是否有长查询运行
SELECT now() - query_start AS duration, datname, query FROM pg_stat_activity WHERE state = 'active' ORDER BY 1 DESC;
-- 查看慢查询日志是否开启
SHOW log_min_duration_statement;
-- 设置慢查询日志
ALTER DATABASE test SET log_min_duration_statement TO 10000;
-- 查找经常被扫描的大型表
SELECT schemaname, relname, seq_scan, seq_tup_read, idx_scan, seq_tup_read / seq_scan AS avg FROM pg_stat_user_tables WHERE seq_scan > 0 ORDER BY seq_tup_read DESC LIMIT 20;
-- 跟踪 vacuum 进度
SELECT * FROM pg_stat_progress_vacuum ;
7,内部机制与原理
1)进程架构模型
启动pg,主进程为Postmaster(pg的bin目录下,是一个指向Postgres的链接)。Postmaster是整个数据库实例的总控进程,负责启动和关闭数据库实例,同时fork出一些与数据库实例相关的辅助进程,并对其进行管理。
| 辅助进程 | 作用 | 配置 |
|---|---|---|
| Logger | 系统日志 | 参数logging_collect设置为on时启动该辅助进程 |
每次客户端与数据库建立连接时,pg数据库都会启动一个服务进程来为该连接服务,故而是进程架构模型,而MySQL是线程架构模型。当某个服务进程报错时,Postmaster主进程会自动完成系统恢复,恢复过程中停掉所有的服务进程,然后进行数据的一致性恢复,恢复完成后数据库才能接受新的连接。
--查询服务进程PID: 通过count(*)获取当前连接数
select pid,usename,client_addr,client_port from pg_stat_activity;
2)autovacuum进程
autovacuum 是 postgresql 里非常重要的一个服务端进程,能够自动运行,在一定条件下自动触发对 dead tuples 进行清理并对表进行分析。
在pg中更新、删除行后,数据行并不会马上从数据块中清理掉,而是需要等VACUUM时时清理。为了加快VACUUM速度并降低对系统I/O性能的影响,pg8.4.1之后为每个数据块文件加了一个后缀为“_vm”的文件(可见性映射表文件,VM文件)。这个文件为每个数据块存储了一个标志位,标记数据块中是否存在要清理的tuple。
VACUUM有两种方式:
- Lazy VACUUM :使用VM文件,扫描部分数据块。
- Full VACUUM :全量扫描数据块。
vacuum相关的配置:
| 参数名 | 说明 | 优化思路 |
|---|---|---|
| autovacuum | 默认为on,表示是否开起autovacuum。当需要冻结xid时,尽管此值为off,PG也会进行vacuum。 | |
| autovacuum_naptime | 下一次vacuum的时间,默认1min | 通过缩短实际,调整回收频率,减少每次回收量,可以减小wal压力 |
| log_autovacuum_min_duration | 向日志打印autovacuum的统计信息(以及资源消耗),大于阈值,输出这次autovacuum触发的事件的统计信息 。 “-1”表示不记录。“0”表示每次都记录。 | |
| autovacuum_max_workers | 最大同时运行的worker数量,不包含launcher本身。 | CPU核多、IO优秀时,当DELETE\UPDATE非常频繁时适量调多点。注意最多可能消耗这么多内存: # autovacuum_max_workers * autovacuum mem(autovacuum_work_mem) |
| autovacuum_vacuum_threshold | 默认50。与autovacuum_vacuum_scale_factor(默认值为20%)配合使用。当update,delete的tuples数量超过autovacuum_vacuum_scale_factor*table_size+autovacuum_vacuum_threshold时,进行vacuum。 | 改小可以降低vacuum触发条件,提高vacuum频率 |
| autovacuum_analyze_threshold | 默认50。与autovacuum_analyze_scale_factor(默认10%)配合使用。当update,insert,delete的tuples数量超过autovacuum_analyze_scale_factor*table_size+autovacuum_analyze_threshold时,进行analyze。 | 改小可以降低vacuum触发条件,提高vacuum频率 |
| autovacuum_freeze_max_age和autovacuum_multixact_freeze_max_age | 前者200 million,后者400 million。离下一次进行xid冻结的最大事务数。 如果表的事务ID年龄大于该值, 即使未开启autovacuum也会强制触发FREEZE,并告警Preventing Transaction ID Wraparound Failures。 | 设置较大值,减少因事务id消耗造成全表扫描的频率。(1000million、1200million) |
| autovacuum_vacuum_cost_delay | 如果为-1,取vacuum_cost_delay值。autovacuum触发的vacuum、freeze、analyze的平滑化调度。 | 设置过大,会导致AUTOVACUUM launcher触发的vacuum耗时过长。特别是大表,耗时会非常长,可能导致膨胀等问题。可以调小一点,0. |
| autovacuum_vacuum_cost_limit | 如果为-1,到vacuum_cost_limit的值,这个值是所有worker的累加值。 | |
| vacuum_freeze_table_age | 当表的年龄大于vacuum_freeze_table_age,则自动转换成vacuum freeze | 调高可以降低vacuum freeze的频率 |
| vacuum_multixact_freeze_table_age | 当表的年龄大于autovacuum_freeze_max_age,也会强制触发vacuum freeze | 调高可以降低vacuum freeze的频率 |
- 如果开启了autovacuum,当垃圾记录数大于 autovacuum_vacuum_threshold + autovacuum_vacuum_scale_factor*reltuples ,autovacuum launcher触发普通的vacuum。
当表的年龄大于vacuum_freeze_table_age,则自动转换成vacuum freeze。 - 如果开启了autovacuum,当新增记录数大于autovacuum_analyze_threshold + autovacuum_analyze_scale_factor*reltuples,autovacuum launcher触发analyze。
- 即使没有开启autovacuum,当表的年龄大于autovacuum_freeze_max_age,也会强制触发vacuum freeze。
3)pg物理存储结构
Relation: 表(table)或索引(Index)。
Tuple:表中的行(其它DB中的ROW)。
Page:磁盘中的数据块 。
Buffer:内存中的数据块。
①数据块结构
数据块大小默认8KB,最大为32KB,一个数据块中存储了多行数据。

- 块头 包括:
a. 块的checksum值;
b. 空闲空间的起始位置和结束位置;
c. 特殊数据的起始位置;
d. 其它信息。 - 行指针:向后顺序排列。是一个32bit的数字,具体结构:
a. 行内容偏移量,15bit;能表示的最大偏移量是215,因此pg中块最大为32kb
b. 指针的标记,2bit;
c. 行内容的长度,15bit。 - 行内容:从块尾向前反向排列。
- 空闲空间:行数据指针和行数据内容之间的空间。
②Tuple结构(数据行)

8,多版本并发控制(Multi-Version Concurrency Control,MVCC)
MVCC是数据库中并发访问数据时保证数据一致性的一种方法。实现MVCC的方法有以下两种:
- 写新数据时,把原数据移到一个单独的位置,如回滚段中,其它用户读数据时,从回滚段中把原数据读出来。(Oracle和Mysql数据库中的InnoDB引擎使用这种方法)
- 写新数据时,原数据不删除,而是把新数据插入进来。(pg使用这种方法)
1)pg MVCC的优缺点
pg在事务提交前,只需要访问原来的数据;提交后,系统更新元组的存储标识,直到Vaccum进程回收为止。
相比InnoDB和Oracle,pg多版本优势在于:
① 事务回滚可以立即完成;
② 数据可以进行很多更新,不必像Oracle和InnoDB那样需要经常保证回滚段不会被用完,也不会像Oracle数据库那样,经常遇到ORA-1555错误的困扰。
劣势在于:
① 旧数据需要Vaccum清理。
② 旧版本数据的存在降低查询速率,需要扫描更多的数据块。
2)事务ID及回卷
1>xmin 表系统字段
插入该行版本的事务ID。
2> xman 表系统字段
删除此行时的事务ID。
第一次插入时,xman=0。如果xman>0,说明删除事务未提交或者被回滚了。
当两个事务同时访问记录时,通过xmin和xman的标记判断记录的版本,根据版本号与自己当前事务标识比较,确定数据权限。
3> cmin 表系统字段
事务内部的插入类操作的命令ID,此标识是从0开始。
4> xman 表系统字段
事务内部的删除类操作的命令ID。如果不是删除命令, xman = 0。
5>事务ID:xid
32bit的数字,从3开始,连续递增。0 1 2是系统预留ID,这三个ID比任何普通xid都要旧:
InvalidTransactionId=0:表示是无效的事务ID;表示还未分配事务ID。
BootstrapTransactionId=1:表示系统表初始化时的事务ID;表示Initdb服务正在初始化系统表。
FrozenTransactionId=2:冻结的事务ID。
6>回卷
xid一直递增达到2^32为最大值,然后继续从头开始,以前的xid比新的xid大,导致比较新旧事务空难,即事务回卷问题。
为了确保事务的可见性需要频繁判断事务之间的新旧关系,如:数据行中已提交的事务比当前事务更早,则这条数据行对当前事务可见。
事务ID的比较新旧的公式如下:diff = (int32) (id1 - id2); 是一个有符号的int32。
事务ID的比较代码:
/*
* TransactionIdPrecedes --- is id1 logically < id2?
*/
bool TransactionIdPrecedes(TransactionId id1, TransactionId id2) // 结果返回一个bool值
{
/*
* If either ID is a permanent XID then we can just do unsigned
* comparison. If both are normal, do a modulo-2^32 comparison.
*/
int32 diff;
if (!TransactionIdIsNormal(id1) || !TransactionIdIsNormal(id2)) //若其中一个是特殊id即id为0 1 2,则另一个id一定较新(较大)
/*验证:
*1)id1=10, id2=2 那么return false,说明id1更新。即普通事务更新
*2)id1=2, id2=10 那么return true,说明id2更新。即普通事务更新
*/
return (id1 < id2);
//两个普通id的比较,转换为int32带符号,第一位为符号位。
/*验证:
* id1=2^31+101, id2=100, id1 - id2= 2^31+1 diff=-1 (大于2^31为负数),return true,id2更新。(事务回卷)
* 那么如果id2确实是很早很早之前的旧事务怎么办呢?根据pg规定的freeze原则,如果id2是很早很早的事务,两事务年龄差又大于2^31,那么id2进行事务冻结。按之前的if逻辑,id1更新。
*/
diff = (int32) (id1 - id2);
return (diff < 0);
}
7>事务冻结(freeze)
pg规定,最早和最新两个事务之间年龄差对多为231。
当超过231时,就把旧的事务换成一个FrozenTransactionId=2的特殊事务,当正常事务ID与冻结事务ID比较时,会认为正常xid比FrozenTransactionId更新。即:xid空间虽然有232,但被一分为二,对某个特定的xid,其后231个xid属于未来,均不可见;其前231个xid属于过去,可见。
i>freeze实现:
pg9.4之前freeze方法:
直接将符合条件的元组的t_xmin设置为2,回收原来的xid。但这样实现的问题是:一)当前可见的数据页需要全部扫描,带来大量的IO扫描;二)符合条件的元组需要更新xmin,造成大量脏页,带来大量IO
pg9.4后对freeze优化:
不直接修改t_xmin,而是:一)只更新元组头结点的t_infomask为HEAP_XMIN_FROZEN,表示该元组已经被冻结过(frozen);二)有些插入操作,也可以直接将记录置为frozen,例如大批量的COPY数据,insert into等;三)如果整个page所有记录已经frozen,则在vm文件中标记为FROZEN,冻结清理会跳过该页,减少了IO扫描。
ii>freeze优化:
freeze是被动触发的,可以调节pg的一些参数优化freeze,更多时候提倡用户进行主动预测需要freeze的时机,选择合适的时间(比如pg负载较低的时间)主动执行vacuum freeze命令。目前已经有很多实现好的开源PostgreSQL vacuum freeze监控管理工具,比如flexible-freeze,能够:确定数据库的高峰和低峰期;在数据库低峰期创建一个cron job执行flexible_freeze.py;flexible_freeze.py会自动对具有最老XID的表进行vacuum freeze。
9,Standby数据库
1)概念
1>主备数据库
高可用:主数据库(Primary db,Master db)失败后,备数据库(Standby db)快速提升为Master db并提供服务。
高可靠性:Master bd和Standby db存在数据同步,从而提高数据的可靠性。通常是一台master db提供读写,然后把数据同步到量一台standby db(只读)。
Hot standby db:同步数据时可以提供只读服务的standby db(pg9.0提供)。反之为Warm standby db。
2>WAL日志文件
pg在数据目录的pg_wal子目录(10版本之前是pg_xlog目录)中始终维护一个WAL文件。
wal文件记录了db数据文件的每次改变,最初设计是为了db异常崩溃后,能够重放最后一次checkpoint之后的日志文件,把数据块推到最终的一致状态,避免数据丢失和不一致。
WAL文件的存在可以让备份数据块存在不一致的数据,通过重放WAL日志文件加以纠正,推到任意一个时间点,即基于时间点备份(PITR,Point-in-Time Recovery)。
对于standby db,只要应用wal日志足够快,就能保持与Master db一致的数据。把WAL日志传送到另一台机器的方法有两种:
- 通过WAL归档日志方法;
standby db会落后master db一个wal文件。具体落后多长时间取决于master db生成一个wal文件的时间。 - 流复制。(pg9.x版本之后)
有两种方式,同步方式,几乎没有延时。异步方式,落后时间取决于网络延迟和standby的i/o能力。
主备同步wal相关配置:
| 参数名 | 说明 | 优化方案 |
|---|---|---|
| synchronous_commit | 如果双节点,设置为ON,如果是多副本,同步模式,建议设置为remote_write。如果磁盘性能很差,并且是OLTP业务。可以考虑设置为off降低COMMIT的RT,提高吞吐(设置为OFF时,可能丢失部分XLOG RECORD) | |
| full_page_writes | 如果文件系统支持COW例如ZFS,则建议设置为OFF。 如果文件系统可以保证datafile block size的原子写,在对齐后也可以设置为OFF。 | |
| wal_writer_delay | wal写的延迟 | 缩短延迟,加快wal写的速度 |
| wal_writer_flush_after | ||
| checkpoint_timeout | 不建议频繁做检查点,否则XLOG会产生很多的FULL PAGE WRITE(when full_page_writes=on) | 提高该值,降低FULL PAGE WRITE,较少XLOG,降低wal压力 |
| max_wal_size | 建议等于SHARED BUFFER,或2倍。 | |
| min_wal_size | 建议是SHARED BUFFER的2分之一 | |
| wal_receiver_status_interval | 反馈给主节点自己已经接受( replies )到数据信息。 | 减小,加快反馈速度 |
| wal_buffers | 基于shared_buffers,shared_buffers/32 | 增大,加快wal落盘速度 |
10,好用工具
1)PgBouncer
为pg提供的一个轻量级连接池工具。
2)Slony-I
基于触发器的两个pg的逻辑同步。
3)Bucardo
双向同步工具,可以实现pg的双(多)master方案。
4)pgpool-II
pg和客户端之间的中间件。
11,Postgres-XC
Postgres-XC是基于pg实现的真正的数据水平拆分的分布式数据库。