Learning Normal Dynamics in Videos with Meta Prototype Network源码详解
1.数据集下载
网址: index of /dataset/ - OneIndex

数据集为经过分帧为图片的数据集,如果使用自己的数据集,需要分帧

2.数据集配置和读取
随机取出一段长度的图片序列,假设length=5,取出5个连续的图片帧,前四帧为训练数据,最后一帧为预测标签。当进行元训练时,task=1,进行元测试时,task_size>1,同时,此时可能是为了保证取出图片序列的连续性,不完全随机的去取,而是先将视频进行分段处理,先随机取出一段,从这段视频中选择一帧图像作为起点,连续取出5帧图像。
代码如下:
def __getitem__(self, index):
video_name = self.video_names[index] # 对应视频
length = self.videos[video_name]['length']-4 # 保证有4个标签
#-------------------------------------------------------------------------------------#
# 随机取出一段长度的图片序列,假设length=5,取出5个连续的图片帧,前四帧为训练数据,最后一帧为预测标签,
# 同时,假设task_size=4,可能是为了保证取出图片序列的连续性,不完全随机的去取,而是先将视频进行分段处理,
# 先随机取出一段,从这段视频中选择一帧图像作为起点,连续取出5帧图像。值得注意的是,task_size>1仅应用于
# 元测试阶段
#-------------------------------------------------------------------------------------#
seg_ind = random.sample(range(0, self.num_segs), 1)
frame_ind = random.sample(range(0, length//self.num_segs), self.task_size)
batch = []
for j in range(self.task_size):
couple = []
frame_name = seg_ind[0]*(length//self.num_segs)+frame_ind[j]
for i in range(self._time_step+self._num_pred):
image = np_load_frame(self.videos[video_name]['frame'][frame_name+i], self._resize_height, self._resize_width)
# print(self.videos[video_name]['frame'][frame_name+i])
if self.transform is not None:
couple.append(self.transform(image)) # 仅仅转换为tensor格式,不进行数据增强操作
print(image.shape)
batch.append(np.expand_dims(np.concatenate(couple, axis=0), axis=0))
print(np.concatenate(batch, axis=0).shape)
# import pdb;pdb.set_trace()
return np.concatenate(batch, axis=0)3.模型的编码和解码
首先需要说明的是,在进行前向传播时,需要对batch进行分割,例如:假设batch_size=4,则两个图片序列用于训练,另外两个用于元学习。
模型的编码层和解码层类似于图像分割(如:u-net),模型的任务是根据前面的图像,对后一帧图像进行预测。因此,编码层进行特征提取,特征图不断缩小,而解码层进行预测,特征图不断增大,并进行特征融合。
模型的编码层由连续的卷积层和池化层组成,并保留中间结果。
Encoder(
(moduleConv1): Sequential(
(0): Conv2d(12, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
)
(modulePool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(moduleConv2): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
)
(modulePool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(moduleConv3): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
)
(modulePool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(moduleConv4): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)编码模块代码如下:
class Encoder(torch.nn.Module):
def __init__(self, t_length = 5, n_channel =3):
super(Encoder, self).__init__()
def Basic(intInput, intOutput):
return torch.nn.Sequential(
torch.nn.Conv2d(in_channels=intInput, out_channels=intOutput, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(inplace=False),
torch.nn.Conv2d(in_channels=intOutput, out_channels=intOutput, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(inplace=False)
)
def Basic_(intInput, intOutput):
return torch.nn.Sequential(
torch.nn.Conv2d(in_channels=intInput, out_channels=intOutput, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(inplace=False),
torch.nn.Conv2d(in_channels=intOutput, out_channels=intOutput, kernel_size=3, stride=1, padding=1),
)
self.moduleConv1 = Basic(n_channel*(t_length-1), 64)
self.modulePool1 = torch.nn.MaxPool2d(kernel_size=2, stride=2)
self.moduleConv2 = Basic(64, 128)
self.modulePool2 = torch.nn.MaxPool2d(kernel_size=2, stride=2)
self.moduleConv3 = Basic(128, 256)
self.modulePool3 = torch.nn.MaxPool2d(kernel_size=2, stride=2)
self.moduleConv4 = Basic_(256, 512)
#---------------------------------------------------------------------------#
# 编码层类似于u-net,不断进行卷积和池化,特征图不断缩小,进行特征提取,另外由于需要在解码层
# 进行特征融合,需要保留中间结果
# ---------------------------------------------------------------------------#
def forward(self, x):
print(x.shape)
print('fewafawef')
tensorConv1 = self.moduleConv1(x)
print(tensorConv1.shape)
tensorPool1 = self.modulePool1(tensorConv1)
print(tensorPool1.shape)
tensorConv2 = self.moduleConv2(tensorPool1)
tensorPool2 = self.modulePool2(tensorConv2)
tensorConv3 = self.moduleConv3(tensorPool2)
tensorPool3 = self.modulePool3(tensorConv3)
tensorConv4 = self.moduleConv4(tensorPool3)
print(tensorConv4.shape)
return tensorConv4, tensorConv1, tensorConv2, tensorConv3decoder:类似于图像分割(u-net),进行上采样操作,并且与同一级的ecoder的特征图进行拼接
代码如下:
class Decoder_new(torch.nn.Module):
def __init__(self, t_length = 5, n_channel =3):
super(Decoder_new, self).__init__()
def Basic(intInput, intOutput):
return torch.nn.Sequential(
torch.nn.Conv2d(in_channels=intInput, out_channels=intOutput, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(inplace=False),
torch.nn.Conv2d(in_channels=intOutput, out_channels=intOutput, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(inplace=False)
)
def Upsample(nc, intOutput):
return torch.nn.Sequential(
torch.nn.ConvTranspose2d(in_channels = nc, out_channels=intOutput, kernel_size = 3, stride = 2, padding = 1, output_padding = 1),
torch.nn.ReLU(inplace=False)
)
self.moduleConv = Basic(512, 512)
self.moduleUpsample4 = Upsample(512, 256)
self.moduleDeconv3 = Basic(512, 256)
self.moduleUpsample3 = Upsample(256, 128)
self.moduleDeconv2 = Basic(256, 128)
self.moduleUpsample2 = Upsample(128, 64)
#-------------------------------------------------#
# decoder:类似于图像分割(u-net),进行上采样操作,并且与同一级
# 的ecoder的特征图进行拼接
#--------------------------------------------------#
def forward(self, x, skip1, skip2, skip3):
print(x.shape)
print(skip1.shape)
print(skip2.shape)
print(skip3.shape)
tensorConv = self.moduleConv(x)
print(tensorConv.shape)
tensorUpsample4 = self.moduleUpsample4(tensorConv)
print(tensorUpsample4.shape)
cat4 = torch.cat((skip3, tensorUpsample4), dim = 1)
print(cat4.shape)
tensorDeconv3 = self.moduleDeconv3(cat4)
print(tensorDeconv3.shape)
tensorUpsample3 = self.moduleUpsample3(tensorDeconv3)
print(tensorUpsample3.shape)
cat3 = torch.cat((skip2, tensorUpsample3), dim = 1)
print(cat3.shape)
tensorDeconv2 = self.moduleDeconv2(cat3)
print(tensorDeconv2.shape)
tensorUpsample2 = self.moduleUpsample2(tensorDeconv2)
print(tensorUpsample2.shape)
cat2 = torch.cat((skip1, tensorUpsample2), dim = 1)
print(cat2.shape)
return cat24.注意力机制模块打造
通俗的讲,论文中的注意力机制模块就是说,如果说是单个权重,就比较的绝对,现在就有10个权重,每个权重可能关注不同的区域,这样就能够大大提升对异常行为进行决策的可能性了。 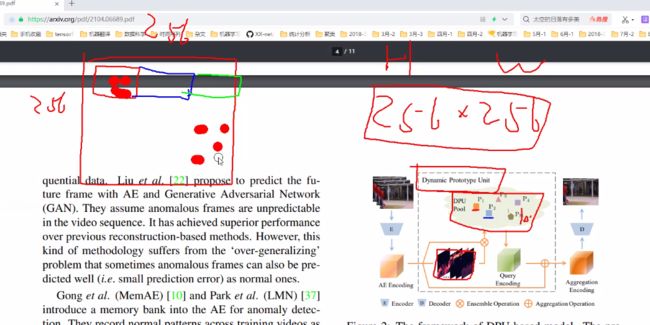
损失函数解读:
损失函数对注意力机制做出了限制。 的含义是与特征图最相关的那个prototype需要和特征图最像,最能反映出特征图的特征。而
的含义是与特征图最相关的那个prototype需要和特征图最像,最能反映出特征图的特征。而![]() 的限制是这10个prototype不能相同,即想让这10个prototype关注特征图的不同区域,相同的话就失去了意义。
的限制是这10个prototype不能相同,即想让这10个prototype关注特征图的不同区域,相同的话就失去了意义。

代码流程:
输入: key, query都是输入的特征图,但是keys用于进行生成item p_t,query用于计算损失并根据p_t进行特征重构。
P_t的生成:首先,对keys进行线性投影,生成10个权重向量,并进行softmax归一化,于是得到重构后的item protos,即每个特征点都有10个权重进行特征重构,重构后将整个特征图(h*w)求和。如论文公式所示:

完成元学习l_c,l_d损失的计算以及特征的重构:损失函数按照论文中所给出的公式进行,另外需要对特征进行根据x_t和p_t的相关性进行进一步的重构。此过程,在这p_t的维度进行了求和,反映出,10个p_t关注不同的区域。
代码如下:
class Meta_Prototype(nn.Module):
def __init__(self, proto_size, feature_dim, key_dim, temp_update, temp_gather, shrink_thres=0):
super(Meta_Prototype, self).__init__()
# Constants
self.proto_size = proto_size
self.feature_dim = feature_dim
self.key_dim = key_dim
self.temp_update = temp_update
self.temp_gather = temp_gather
#multi-head
self.Mheads = nn.Linear(key_dim, proto_size, bias=False)
# self.Dim_reduction = nn.Linear(key_dim, feature_dim)
# self.softmax = nn.Softmax(dim=1)
self.shrink_thres = shrink_thres
def get_score(self, pro, query):
bs, n, d = query.size()#n=w*h
bs, m, d = pro.size()
# import pdb;pdb.set_trace()
score = torch.bmm(query, pro.permute(0,2,1))# b X h X w X m
score = score.view(bs, n, m)# b X n X m
score_query = F.softmax(score, dim=1)
score_proto = F.softmax(score, dim=2)
return score_query, score_proto
def forward(self, key, query, weights, train=True):
#---------------------------------------#
# key, query都是输入的特征图,但是keys用于进行
# 重构,query用于计算损失
# print(key.shape)
# print(query.shape)
#---------------------------------------#
batch_size, dims, h, w = key.size() # b d h w
key = key.permute(0,2,3,1) # b h w d
# print(key.shape)
_, _, h_, w_ = query.size()
query = query.permute(0,2,3,1) # b h w d
# print(query.shape)
query = query.reshape((batch_size,-1,self.feature_dim))
#train
#-----------------------------------------------------------#
# Attention+Ensemble:首先,重构10个权重向量,并进行softmax归一化,生成prototype权重,
# 即每个特征点都有10个权重进行特征重构,重构后将整个特征图(h*w)求和
#------------------------------------------------------------#
if train:
if weights == None:
multi_heads_weights = self.Mheads(key)
else:
# prototype权重,10个,即每一个特征点有10个权重进行重构
multi_heads_weights = linear(key, weights['prototype.Mheads.weight'])
# print(multi_heads_weights.shape)
multi_heads_weights = multi_heads_weights.view((batch_size, h*w, self.proto_size, 1))
# softmax on weights softmax归一化
multi_heads_weights = F.softmax(multi_heads_weights,dim=1)
key = key.reshape((batch_size,w*h,dims))
# Ensemble重构特征
protos = multi_heads_weights*key.unsqueeze(-2)
protos = protos.sum(1)
# 完成元学习l_c,l_d损失的计算以及特征的重构
updated_query, fea_loss, cst_loss, dis_loss = self.query_loss(query, protos, weights, train)
# skip connection 残差连接
updated_query = updated_query+query
# reshape
updated_query = updated_query.permute(0,2,1) # b X d X n
updated_query = updated_query.view((batch_size, self.feature_dim, h_, w_))
return updated_query, protos, fea_loss, cst_loss, dis_loss
#test
else:
if weights == None:
multi_heads_weights = self.Mheads(key)
else:
multi_heads_weights = linear(key, weights['prototype.Mheads.weight'])
multi_heads_weights = multi_heads_weights.view((batch_size, h*w, self.proto_size, 1))
# softmax on weights
multi_heads_weights = F.softmax(multi_heads_weights,dim=1)
key = key.reshape((batch_size,w*h,dims))
protos = multi_heads_weights*key.unsqueeze(-2)
protos = protos.sum(1)
# loss
updated_query, fea_loss, query = self.query_loss(query, protos, weights, train)
# skip connection
updated_query = updated_query+query
# reshape
updated_query = updated_query.permute(0,2,1) # b X d X n
updated_query = updated_query.view((batch_size, self.feature_dim, h_, w_))
return updated_query, protos, query, fea_loss
#-----------------------------------------------------------#
# 完成元学习l_c,l_d损失的计算以及特征的重构
#-----------------------------------------------------------#
def query_loss(self, query, keys, weights, train):
batch_size, n, dims = query.size() # b X n X d, n=w*h
if train:
#------------------------------------------------------------------------#
# Distinction constrain 返回在指定维度上的输入数据input的L-p范数的标准化后的数据。
# https://blog.csdn.net/panbaoran913/article/details/124063821
#------------------------------------------------------------------------#
keys_ = F.normalize(keys, dim=-1)
print(keys_.permute(0,2,1).shape)
# 计算相似性:尚未使用到:torch.bmm是一种矩阵乘法
similarity = torch.bmm(keys_, keys_.permute(0,2,1))
# print(similarity.shape)
# print(keys_.unsqueeze(1).shape)
# print(keys_.unsqueeze(2).shape)
# L_d损失,即期望这重构的10个特征差别较大
dis = 1-distance(keys_.unsqueeze(1), keys_.unsqueeze(2))
mask = dis>0
dis *= mask.float()
dis = torch.triu(dis, diagonal=1) #返回矩阵的上三角部分
# print(dis.sum(1).shape)
# print(dis.sum(1).sum(1).shape)
dis_loss = dis.sum(1).sum(1)*2/(self.proto_size*(self.proto_size-1))
dis_loss = dis_loss.mean()
# maintain the consistance of same attribute vector
# 保持同一属性向量的一致性
# print(keys_[1:].shape)
# print(keys_[:-1].shape)
cst_loss = mean_distance(keys_[1:], keys_[:-1])
#-------------------------------------------------#
# Normal constrain
# L_d损失的限制是这10个prototype不能相同,即想让这10个prototype关注特征图的不同区域,
# 相同的话就失去了意义。
#-------------------------------------------------#
loss_mse = torch.nn.MSELoss()
keys = F.normalize(keys, dim=-1)
print(keys.shape)
_, softmax_score_proto = self.get_score(keys, query)
print(softmax_score_proto.shape)
#-------------------------------------------------#
# new_query:重构特征:X_t,根据相关程度对特征进行重构,
# 此过程可以明确的看出,这10个权重向量p_t关注不同的区域,
# 在这个10个不同特征的维度进行了求和
#-------------------------------------------------#
new_query = softmax_score_proto.unsqueeze(-1)*keys.unsqueeze(1)
print(new_query.shape)
new_query = new_query.sum(2)
print(new_query.shape)
new_query = F.normalize(new_query, dim=-1) # 归一化
print(new_query.shape)
# maintain the distinction among attribute vectors
_, gathering_indices = torch.topk(softmax_score_proto, 2, dim=-1)
print(gathering_indices.shape)
# 1st closest memories
pos = torch.gather(keys,1,gathering_indices[:,:,:1].repeat((1,1,dims)))
print(pos.shape)
fea_loss = loss_mse(query, pos)
return new_query, fea_loss, cst_loss, dis_loss
else:
loss_mse = torch.nn.MSELoss(reduction='none')
keys = F.normalize(keys, dim=-1)
softmax_score_query, softmax_score_proto = self.get_score(keys, query)
new_query = softmax_score_proto.unsqueeze(-1)*keys.unsqueeze(1)
new_query = new_query.sum(2)
new_query = F.normalize(new_query, dim=-1)
_, gathering_indices = torch.topk(softmax_score_proto, 2, dim=-1)
#1st closest memories
pos = torch.gather(keys,1,gathering_indices[:,:,:1].repeat((1,1,dims)))
fea_loss = loss_mse(query, pos)
return new_query, fea_loss, query模型的输出与元学习
模型经过注意力机制的计算后,预测出一张特征图。在元学习上,一个batch为4,两张图片用于训练,两张图片用于元学习,并计算损失。