YOLO V6系列(一) -- 跑通YOLO V6算法
YOLO V6系列(一) – 跑通YOLO V6算法
近期,看到美团视觉发布了YOLO V6算法,从名字看,感觉上是YOLO系列的一个新的里程碑吧,所以好好研究研究~
其实,简单的看了下内部的track和网络架构,感觉这个更像是YOLOX promax版本。话不多说,直接讲如何跑通YOLO V6算法。
一、简介
项目Github代码:YOLO V6算法
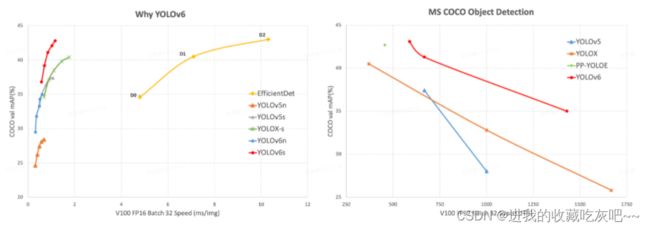
YOLOv6-nano 在 COCO val2017 数据集上达到 35.0 mAP,T4 上使用 TensorRT FP16 进行 bs32 推理,达到 1242 FPS,YOLOv6-s 在 COCO val2017 数据集上达到 43.1 mAP,T4 上使用 TensorRT FP16 进行 bs32 推理,达到 520 FPS。
二、训练步骤
项目文件夹(至少从文件夹就能看出来,比YOLO V5简洁多,v5的代码可读性确实不敢恭维0.0):

1.先安装相关的库
git clone https://github.com/meituan/YOLOv6
cd YOLOv6
pip install -r requirements.txt
2.制作自定义数据集
i. 先用LabelImg标注工具进行人工标注,得到xml文件
ii. 转换为txt格式的标签文件,可以参考我之前写的一篇blog:xml2txt脚本
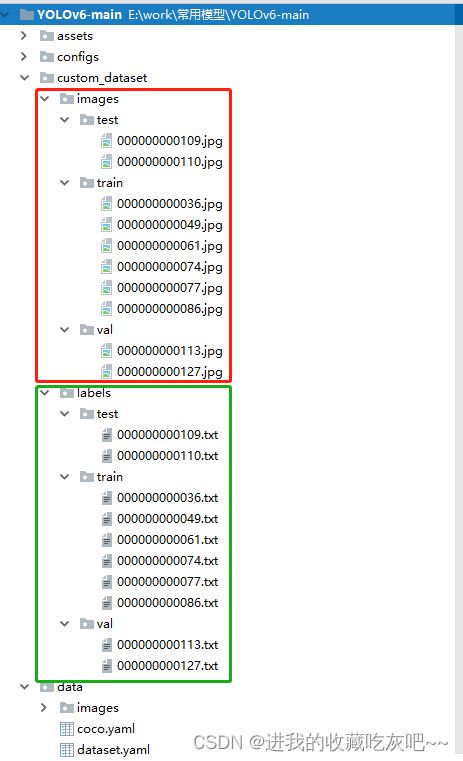
iii. 按照yolo v6指定的数据集存放路径进行存放自定义数据集,如下图所示。我这里为了展示,就随便放了几张示例图。
- 找到
your yolov6 dir/data/dataset.yaml文件,进行修改

这里,如果你使用coco数据集,记得把这个is_coco设置为True,我这里使用的是voc格式的数据集,所以就是False。同时,修改自定义数据集的类别数nc和所有类别名称names。 - 根据需要,选择模型架构,这里官方提供了6种网络结构。这个我选择的是
your yolov6 dir/configs/yolov6s.py。
5.修改train.py相关超参数(我这里是随便写的,具体的参数根据自己的需求进行修改)
parser = argparse.ArgumentParser(description='YOLOv6 PyTorch Training', add_help=add_help)
parser.add_argument('--data-path', default=r'E:\work\常用模型\YOLOv6-main\data\dataset.yaml', type=str, help='path of dataset') #数据yaml文件路径
parser.add_argument('--conf-file', default=r'E:\work\常用模型\YOLOv6-main\configs\yolov6s.py', type=str, help='experiments description file') #选择的网络结构路径
parser.add_argument('--img-size', default=640, type=int, help='train, val image size (pixels)')
parser.add_argument('--batch-size', default=2, type=int, help='total batch size for all GPUs')
parser.add_argument('--epochs', default=3, type=int, help='number of total epochs to run')
parser.add_argument('--workers', default=1, type=int, help='number of data loading workers (default: 8)') #数据加载线程数
parser.add_argument('--device', default='0', type=str, help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--eval-interval', default=1, type=int, help='evaluate at every interval epochs') #设置模型训练多少轮进行一次验证操作
parser.add_argument('--eval-final-only', action='store_true', help='only evaluate at the final epoch') #是否使用最终训练的模型权重来验证
parser.add_argument('--heavy-eval-range', default=50, type=int,
help='evaluating every epoch for last such epochs (can be jointly used with --eval-interval)')
parser.add_argument('--check-images', action='store_true', help='check images when initializing datasets') #图片初始化的时候是否进行检查操作
parser.add_argument('--check-labels', action='store_true', help='check label files when initializing datasets') #标签初始化的时候是否进行检查操作
parser.add_argument('--output-dir', default='../runs/train', type=str, help='path to save outputs')
parser.add_argument('--name', default='exp', type=str, help='experiment name, saved to output_dir/name')
parser.add_argument('--dist_url', default='env://', type=str, help='url used to set up distributed training')
parser.add_argument('--gpu_count', type=int, default=0)
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume the most recent training') #是否进行继续训练
6.python tools/train.py开启训练~
推理步骤
修改tools/infer.py并运行python tools/infer.py --weights output_dir/name/weights/best_ckpt.pt --source img.jpg --device 0(具体参数,自己修改)