【数据库】02——关系模型是什么东东

前 言
作者简介:半旧518,长跑型选手,立志坚持写10年博客,专注于java后端
☕专栏简介:相当硬核,黑皮书《数据库系统概念》读书笔记,讲解:
1.数据库系统的基本概念(数据库设计过程、关系型数据库理论、数据库应用的设计与开发…)
2.大数据分析(大数据存储系统,键值存储,Nosql系统,MapReduce,Apache Spark,流数据和图数据库等…)
3.数据库系统的实现技术(数据存储结构,缓冲区管理,索引结构,查询执行算法,查询优化算法,事务的原子性、一致性、隔离型、持久性等基本概念,并发控制与故障恢复技术…)
4.并行和分布式数据库(集中式、客户-服务器、并行和分布式,基于云系统的计算机体系结构…)
5.更多数据库高级主题(LSM树及其变种、位图索引、空间索引、动态散列等索引结构的拓展,高级应用开发中的性能调整,应用程序移植和标准化,数据库与区块链等…)
文章简介:关系模型依旧是现代商用数据处理应用的主要数据模型,它半个多世纪不断融合各种新特点和功能,一直沿用至今。学习关系模型有利于后续我们进行关系数据库设计模式的学习。
文章目录
-
- 1关系数据库的结构
- 2 数据库模式
- 3 码
- 4 模式图
- 5 关系查询语言
- 6 关系代数
-
- 6.1 选择运算
- 6.2 投影运算
- 6.3 笛卡尔积运算
- 6.4 连接运算
- 6.5 集合运算
- 6.6 赋值运算
- 6.7 更名运算
- 6.8 等价查询
- 6.9 其他关系运算
1关系数据库的结构
关系数据库由表的集合构成。

表中的一行数据就代表了一组值之间存在某种联系,这和数学上关系概念有着密切的联系,这也正是关系数据模型名称的由来。在数学中,一组值被看做一个元组。n个值之间的一种联系在数学上用这些值得一个n元组表示。在数据库中元组被用来代指行,属性则被用来代指列。用关系实例这个术语来指代一个关系的特定实例。也就是说,关系实例包含一组特定的行。关系的每个属性都存在一个允许取值的集合,称为该属性的域。
空值是一个特殊的值,它表示值未知或者并不存在。以后我们将看到,空值会在我们访问和更新数据库时带来许多困难,因此尽量避免使用空值。
我们可以看到,关系型数据结构在存储和处理时固定了数据的格式,这种严格的结构适用于定义明确并且相对静态的应用,但是不太适用于数据本身甚至数据类型这些结构都随着时间而变化的应用,现代企业要平衡好二者。
2 数据库模式
数据库模式是数据库的逻辑设计,而数据库实例是给定时刻数据库中数据的一个快照。比如下面就是一个关系模式:
department(dept_Id,dept_name, building, budget)
3 码
我们必须要能够区分不同元组。超码可以允许我们在一个关系中唯一的标识一个元组。比如上面dept_Id就是一个超码。
能够唯一确定元组且其任何真子集都不是超码的超码称为候选码,比如dept_Id和dept_name的组合是一个超码,但是dept_name是无关紧要的,不是候选码。只要能够唯一确定元组且其任何真子集都不是超码,它就可以被称之为候选码。比如如果dept_name和building组成的元组可满足上列条件,他也是候选码。
我们用主码(primary key)来表示数据库设计者中选择作为一个关系中区分不同元组的主要方式的候选码。主码也被称作主码约束。习惯将主码列于其他属性之前,并加下划线。
department(dept_Id,dept_name, building, budget)
外码约束(foreign-key constarint)表示,在任何数据库实例中,r1的每个元组对A的取值必须也是r2中某个元组对B的取值。也就是表A中的该属性的值一定可以在表B中找到。r1关系在这里称为引用关系,r2关系在这里被称为被引用关系。
注意在外码约束中,被引用属性必须书被引用关系的主码。
更广泛的约束被称为引用完整性约束(referential integrity constraint),它放宽了被引用属性构成被引用关系主码的要求。
4 模式图
一个带有主码和外码的数据库模式可以用模式图来表示。
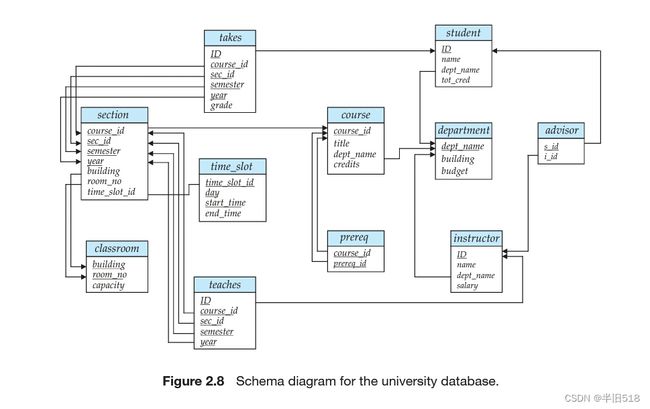
主码用下划线表示,外码约束从引用关系指向被引用关系。双头箭头表示引用完整性约束。注意实体-联系(E-R)图与模式图不是同一个东西,不要混淆。
5 关系查询语言
查询语言是用户从数据库中请求获取信息的语言。分为三种。
- 命令式查询语言。用户指导系统在数据库上执行特定的运算序列以计算得出结果,这类语言通常有一个状态变量的概念,状态变量会在计算过程中被更新。
- 函数式查询语言。计算被表示为对函数的求职,函数将在数据库数据或者其它函数给出的结果上运行,但是没有附带作用,不会更新程序的状态。
- 声明式查询语言。用户只需要描述所需信息,并不需要给出获取该信息的具体步骤序列或者函数调用。获取信息的方式是数据库系统的工作。
关系代数式函数式查询语言,它构成了SQL查询语言的基础。元组关系演算和域关系演算是声明式的,后面文章我们将进一步介绍。
常用的查询语言比如SQL同时包含命令式、函数式和声明式的方法元素。
6 关系代数
关系代数由一组运算组成,这组运算接受一个或者两个关系作为输出,并且输出一个新的关系作为他们的结果。
其中一些运算只在一个关系上进行,比如选择、投影、改名,这被称为一元运算。
同理,并,笛卡尔积和集差等被称为二元运算。
6.1 选择运算
我们用sigma(σ)来代表选择。比如选择物理系老师,可以表示为:

还可以有=,≠,<,≤,>,≥等用于比较,使用and(∧),or(∨)和not(¬)。
选择谓词可以包含两个属性之间的比较,比如系名与其所在教学楼名字相同的所有系。

6.2 投影运算
如果我们希望列出所有教师的ID,name和salary,就可以使用投影运算。由于关系是一个集合,任何重复的行都会被删除。使用大写的pi(π)表示。
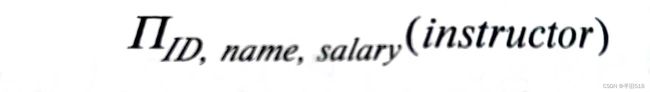
投影运算的基础版本在列表中只许出现属性,在其泛化版本中则允许出现属性的表达式。
另外,关系运算可以复合使用。
6.3 笛卡尔积运算
笛卡尔积运算使用叉号(×)表示,它允许我们结合来自任意两个关系的信息。比如r1×r2。数据库的笛卡尔积与集合中的笛卡尔积略有不同,它不是表示由r1和r2生成的元组对(t1,t2),而是将其拼接为单个元组。假设r1有n1个元组,r2有n2个元组,r中就有n1 x n2个元组。

由于同一个属性名可能出现在多个不同的关系中,我们需要加以区分,比如teacher.ID。考虑一个问题,一个关系与自己做笛卡尔积,要如何处理?
答案是对关系更名运算来避免。
6.4 连接运算
查询所有教师及他们所教授的课,可以进行如下运算。

注意不教授任何课程的教师不会出现在这个结果中。注意,上面的表达式会导致教师ID重复的出现,可以通过投影去除teacher.ID解决。
连接运算使我们将笛卡尔积和选择运算被合并到单个运算中。

6.5 集合运算
如果想要查找2017年秋季学期、2018年春季学期开设的所有课程的集合,可以使用集合语言中的并完成。注意,由于关系是集合,所以重复的值只会出现一次。运算如下。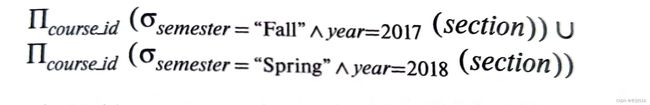
为了使并运算有意义,需注意:
1.必须确保输入并运算的两个关系具有相同数量的属性,一个关系的属性数量被称为它的元数。
2两个关系的属性类型必须依次对应。
这样的关系被称为相容关系。
交运算用∩表示。可以用它找到同时出现在两个输入关系中的元组。交运算也需要在相容关系里进行。
集差(set-difference)运算用-来表示。他可以找到在一个关系里,但是不在另外一个关系里的元组。比如r-s所产生的关系包含在r中但是不包含在s中的那些元组。集差运算也需要在相容关系里进行。
6.6 赋值运算
赋值概念与其他高级语言是一致的,有时将某个表达式的一部分赋值给临时的关系变量,可以更加方便地编写该表达式。赋值用←表示。比如之前查找2017秋季,2018年春季都开设的课程可以表示为。
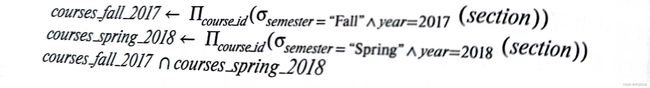
请注意,对于关系代数查询,必须始终赋值给临时的关系变量,向永久的关系代数赋值会造成数据库的修改。
6.7 更名运算
更名运算使用小写希腊字母rhoρ表示 ,给关系E重命名为x
还可以给属性重命名。
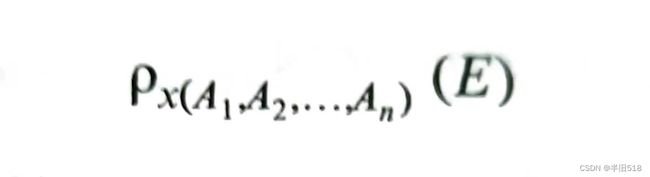
6.8 等价查询
同一个查询的关系代数编写方式通常不止一种。比如下面这个栗子。

数据库的优化器会帮我们选择最高效的方式,而不是严格按照查询步骤进行。
6.9 其他关系运算
聚集运算可以对查询返回的值集进行函数计算,这些函数包括求平均值,最大值,求和等。后续文章会详细介绍。
自然连接是一种特殊的关系代数运算,要求两个连接关系需要具有相同的属性,后续会详细介绍。
外连接允许通过空值表示缺失的值,会在结果中保留这些查询不到完整信息的元组。后续详细介绍。