pytorch入门笔记
此文为本人近期自学pytorch的笔记,根据pytorch基础入门所学内容做的笔记,如有误或者理解有偏差的,请多多指正。此教学视频的感受和体会在文章最后。如果你喜欢的话,可以关注公众号:你我的青春,一部分学习体验与推荐会分享在公众号上,公众号二维码已放在文章最后。希望我们在2022中加油前进!
CUDA NVIDIA进行硬件加速
深度学习核心:梯度下降算法
x‘(下一次的数值)=x-rate(步长)*x’(x倒数)
衍生出来的梯度下降有:Adam,sgd,rmsprop,nag,adadelta,adagrad,momentum
Closed Form Solution近似解
Logistic Regression压缩函数,压缩到0-1
Linear Regression 线性
Python与Pytorch数据类型区别

a=torch.randn(2,3)
print(a.type())#可以查看具体数据类型
#输出为'torch.FloatTensor'
print(type(a))#查看基本数据类型,不常用
#torch.Tensor
print(isinstance(a,torch.FloatTensor))#匹配数据类型
#输出为True
#同一个Tensor,部署在GPU与CPU上,是不一样的
``
### Dimension0/rank0(标量)
torch.tensor(1.)
#输出为tensor(1.)
torch.tensor(1.3)
#输出tensor(1.300)
#可以用来表示loss
向量在Pytorch中,统称为张量,
Dim0,标量
Dim1:Bias Linear Input
Dim2:Linear Input batch
Dim3:RNN input Batch
Dim4:CNN:[b,c,h,w]
tensor:输入现成数据
FloatTensor输入维度(不常用)
不推荐使用list
数据集的路径导入
import os
from torch.utils.data import Dataset
from PIL import Image
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir, img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label
def __len__(self): # 长度
return len(self.img_path)
root_dir = "dataset/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)
train_dataset = ants_dataset + bees_dataset # 数据集拼接,有时候数据不够,可以将多个类似数据集拼接
TensorBoard的使用(一个数据)
需要tensor数据类型才能展示,所以使用前需要进行格式转换

from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("logs")
for i in range(100):
writer.add_scalar("y=x",i,i)#标签,y轴,x轴
# writer.add_image()
# writer.add_scalar()#数
writer.close()
打开方式:
在终端输入:
tensorboard --logdir=logs
当多人使用时,可能会出现端口占用,修改端口如下
tensorboard --logdir=logs --port=6007
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs")
image_path = "dataset/train/ants/0013035.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL) # 转为np类型,这样才能匹配writer.add_image()的输入参数
print(type(img_array))
print(img_array.shape)#由(512, 768, 3)已知,通道在后面,所以需要其他函数将其转化
writer.add_image("test",img_array,1,dataformats='HWC')#显示图片,并进行格式转化了,将格式转为HWC,把通道放后面了,通过这种方法可以看到每个步骤执行的输出结果
for i in range(100):
writer.add_scalar("y=10", i, i) # 标签,y轴,x轴
writer.close()
transform进行图片的变换

import cv2
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
# python的用法-》tensor的数据类型
# 通过transform.ToTensor去看两个问题
# 1、transform该如何使用(Python)
# 2、为什么需要Tensor数据类型
# 需要相对路径,因为是斜杆,绝对路径是反斜杠
img_path = "dataset/train/ants/0013035.jpg"
img = Image.open(img_path)
writer=SummaryWriter("logs")
# 1、transform该如何使用(Python)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
#使用cv2引入图片
cv_img=cv2.imread(img_path)
writer.add_image("Tensor_img",tensor_img)
writer.close()
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("dataset/train/ants/0013035.jpg")
print(img)
# ToTensor
trans_totensor = transforms.ToTensor() # 将此方法赋给trans_totensor
img_tensor = trans_totensor(img) # 然后使用此方法后将结果赋值给img_tensor
writer.add_image("Totensor", img_tensor) # 然后显示在write上
# Normalize归一化
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 因为RGB是三层的,需要提供三个标准差
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm)
#Resize
print(img.size)
trans_resize=transforms.Resize((512,512))
img_resize=trans_resize(img)
print(img_resize)
#Compose - resize -2
trans_resize_2=transforms.Resize(512)
#PIL-PIL->tensor
trans_compose=transforms([trans_resize_2,trans_totensor])
img_resize_2=trans_compose(img)
writer.add_image("Resize",img_resize_2,1)#后面的1为将输出放在第一位显示出来
#RandomCrop
trans_random=transforms.RandomCrop(512)
trans_compose_2=transforms.Compose([trans_random,trans_totensor])#前面表示随机裁剪,后面为转为tensor数据类型
for i in range(10):
img_crop=trans_compose_2(img)
writer.add_image("RandonCrop",img_crop,i)
writer.close()
一些方式方法的总结:
- 首先关注输入输出以及类型,需要什么参数(可用print或者官方文档查看)
- 多看官方文档
torchvision统一管理处理数据集
import ssl
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
ssl._create_default_https_context = ssl._create_unverified_context
train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True)#将会在./dataset创建一个文件,并且保存数据
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)
# print(test_set[0])
# print(test_set.classes)
# img,target=test_set[0]
# print(img)
writer=SummaryWriter("p10")
for i in range(10):
img,target=test_set[i]
writer.add_image("test_set",img,i)
writer.close()
dataload(从数据集加载部分数据)
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False)#后面的设为false,表示不足64时,不舍去
# 测试数据集中第一张样本及target
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
step = 0
for epoch in range(2):#验证两次抓取是否一样
# 随机抓取
for data in test_loader:
imgs, targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("Epoch:{}".format(epoch), imgs, step)
step = step + 1
writer.close()
nn.Module神经网络基本骨架
import torch
from torch import nn
class Tudui(nn.Module):
def __init__(self):
super().__init__()
def forward(self,input):#前向输出
output=input+1
return output
tudui=Tudui()
x=torch.tensor(1.0)
output=tudui(x)
print(output)
调试
先运行对应的py,然后调试,主要使用F7,进行调试查看,注意断点的选择
卷积使用
torch.nn相当于把torch.nn.function封装好了,如果需要更了解,则了解function即可。
输入图像:5x5
| 1 | 2 | 0 | 3 | 1 |
|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 1 |
| 1 | 2 | 1 | 0 | 0 |
| 5 | 2 | 3 | 1 | 1 |
| 2 | 1 | 0 | 1 | 1 |
卷积核3x3
| 1 | 2 | 1 |
|---|---|---|
| 0 | 1 | 0 |
| 2 | 1 | 0 |
结果为:
| 10 | 12 | 12 |
|---|---|---|
| 18 | 16 | 16 |
| 13 | 9 | 3 |
输入图像与卷积核(Strive=1)对应相乘再相加
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1], [0, 1, 2, 3, 1],
[1, 2, 1, 0, 0], [5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
#进行格式转换
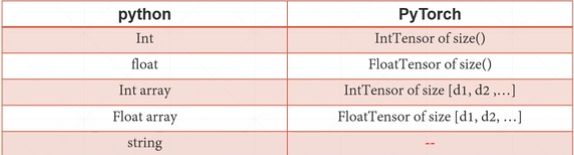
input = torch.reshape(input, (1, 1, 5, 5)) # size为1,5x5
kernel = torch.reshape(kernel, (1, 1, 3, 3))
print(input.shape)
print(kernel.shape) # 查看尺寸,得知只有高和宽,不满足需要4个数组,则需要变换
output = F.conv2d(input, kernel, stride=1)#二维的卷积
print(output)
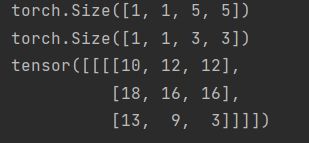
padding=1:即填充一格
| 1 | 2 | 0 | 3 | 1 | ||
| 0 | 1 | 2 | 3 | 1 | ||
| 1 | 2 | 1 | 0 | 0 | ||
| 5 | 2 | 3 | 1 | 1 | ||
| 2 | 1 | 0 | 1 | 1 | ||
out_channels=2表示两个通道,用两个卷积核去比对同一个输入图像,得到两个数组,然后输出结果,其实很多算法就是在增加Chanel数
池化
maxpool最大池化也叫下采样
maxunpool最大池化也叫上采样
dilation – a parameter that controls the stride of elements in the window空洞卷积,与普通卷积不用,空洞卷积有空隙
ceil_mode – when True, will use ceil instead of floor to compute the output shape
celling的用法,向上取整(即保留)
最大池化(输出最大值)
输入图像:
| 1 | 2 | 0 | 3 | 1 |
|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 1 |
| 1 | 2 | 1 | 0 | 0 |
| 5 | 2 | 3 | 1 | 1 |
| 2 | 1 | 0 | 1 | 1 |
池化核(3x3),kernel_size=3
Ceil_model=True
输出结果为
| 2 | 3 |
|---|---|
| 5 | 1 |
Ceil_model=false
输出结果为2
最大池化作用:保留输入的最大特征,减少数据量
很多网络当中,经过一层卷积之后,再来一层池化,然后再非线性激活
非线性激活函数

inplace即为占用与不占用的区别
非线性变换主要是引入一些非线性特征,非线性越多才越好符合各种曲线或者各种特征的模型
正则化
作用:可以加快训练的速度
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset,batch_size=64)
class Yjh(nn.Module):
def __init__(self):
super().__init__()
self.linear1=Linear(196608,10)
def forward(self,input):
output=self.linear1(input)
return output
yjh=Yjh()
for data in dataloader:
imgs,targets=data
output=torch.reshape(imgs,(1,1,1,-1))
print(output.shape)
output=yjh(output)
print(output.shape)
输出结果为:
torch.Size([1, 1, 1, 10])
torch.Size([1, 1, 1, 196608])
torch.Size([1, 1, 1, 10])
torch.Size([1, 1, 1, 196608])
torch.Size([1, 1, 1, 10])
torch.Size([1, 1, 1, 196608])
torch.Size([1, 1, 1, 10])
torch.Size([1, 1, 1, 196608])
torch.Size([1, 1, 1, 10])
torch.Size([1, 1, 1, 196608])
torch.Size([1, 1, 1, 10])
torch.Size([1, 1, 1, 196608])
torch.Size([1, 1, 1, 10])
torch.Size([1, 1, 1, 196608])
torch.Size([1, 1, 1, 10])
torch.Size([1, 1, 1, 196608])
torch.Size([1, 1, 1, 10])
torch.Size([1, 1, 1, 196608])
torch.Size([1, 1, 1, 10])
torch.Size([1, 1, 1, 196608])
torch.Size([1, 1, 1, 10])
torch.Size([1, 1, 1, 196608])
torch.Size([1, 1, 1, 10])
torch.Size([1, 1, 1, 196608])
torch.Size([1, 1, 1, 10])
torch.Size([1, 1, 1, 49152])
..........................
..........................
明显看到数据量大大减少
将数据变成一行
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset,batch_size=64)
class Yjh(nn.Module):
def __init__(self):
super().__init__()
self.linear1=Linear(196608,10)
def forward(self,input):
output=self.linear1(input)
return output
yjh=Yjh()
for data in dataloader:
imgs,targets=data
output=torch.flatten(imgs)
print(output.shape)
output=yjh(output)
print(output.shape)
# 输出为
torch.Size([196608])
torch.Size([10])
torch.Size([196608])
torch.Size([10])
torch.Size([196608])
torch.Size([10])
torch.Size([196608])
torch.Size([10])
torch.Size([196608])
torch.Size([10])
torch.Size([196608])
torch.Size([10])
................
...............
Sequential使用
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
class Yjh(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv2d(3, 32, 5, 1, padding=2)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32, 32, 5, 1, padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32, 64, 5, padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.linear1 = Linear(1024, 64)#若不知道第一个参数,则用Flatten函数展平看看
self.linear2 = Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
yjh = Yjh()
print(yjh)
input = torch.ones((64, 3, 32, 32))
output = yjh(input)
print(output.shape)
输出结果:
(conv1): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv3): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear1): Linear(in_features=1024, out_features=64, bias=True)
(linear2): Linear(in_features=64, out_features=10, bias=True)
)
torch.Size([64, 10])
用Sequential
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class Yjh(nn.Module):
def __init__(self):
super().__init__()
self.model1=Sequential(
Conv2d(3, 32, 5, 1, padding=2),#注意需要用逗号分隔
MaxPool2d(2),
Conv2d(32, 32, 5, 1, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x=self.model1(x)
return x
yjh = Yjh()
print(yjh)
input = torch.ones((64, 3, 32, 32))
output = yjh(input)
print(output.shape)
writer=SummaryWriter("./logs_seq")
writer.add_graph(yjh,input)#输出图表
writer.close()
输出结果:
Yjh(
(model1): Sequential(
#前面是序号
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
torch.Size([64, 10])
tensorboard显示结果
双击张开


损失函数Loss
- 计算误差
- 反向传播,优化参数
import torch
from torch import nn
from torch.nn import L1Loss
input = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(input, (1, 1, 1, 3)) # batch_size,1channel,1行3列
targets = torch.reshape(targets, (1, 1, 1, 3), )
loss = L1Loss()#默认是求平均,可以是求和
result = loss(inputs, targets)
print(result)#|((1-1)+(1-1)+(5-3))/3|=0.667
loss = L1Loss(reduction="sum")
result = loss(inputs, targets)
print(result)
loss_mes=nn.MSELoss()#平方差
result_mse=loss_mes(inputs,targets)
print(result_mse)#(0+0+2)**2/3
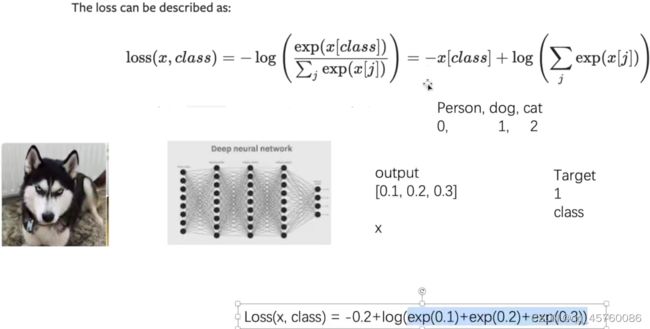
x=torch.tensor([0.1,0.2,0.3])
y=torch.tensor([1])
x=torch.reshape(x,(1,3))#batch_size=1,3类
loss_cross=nn.CrossEntropyLoss()#交叉熵
result_cross=loss_cross(x,y)#loss(x,class)=-0.2+ln(exp(0.1)+exp(0.2)+exp(0.3))
print(result_cross)
输出结果:
tensor(0.6667)
tensor(2.)
tensor(1.3333)
tensor(1.1019)
交叉熵的计算公式(计算过程详解)
import torchvision
from torch import nn
from torch.nn import Linear, Flatten, MaxPool2d, Conv2d, Sequential
from torch.utils.data import DataLoader
dataset=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
dataloader=DataLoader(dataset,batch_size=64,shuffle=True)
class Yjh(nn.Module):
def __init__(self):
super().__init__()
self.model1=Sequential(
Conv2d(3, 32, 5, 1, padding=2),#注意需要用逗号分隔
MaxPool2d(2),
Conv2d(32, 32, 5, 1, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x=self.model1(x)
return x
loss=nn.CrossEntropyLoss()
yjh=Yjh()
for data in dataloader:
imgs,targets=data
outputs=yjh(imgs)
result_loss=loss(outputs,targets)
print(result_loss)
输出结果:
以下的数就是神经网络的输出和真实输出的误差
tensor(2.3062, grad_fn=<NllLossBackward0>)
tensor(2.2851, grad_fn=<NllLossBackward0>)
tensor(2.2950, grad_fn=<NllLossBackward0>)
tensor(2.3109, grad_fn=<NllLossBackward0>)
tensor(2.3065, grad_fn=<NllLossBackward0>)
tensor(2.3187, grad_fn=<NllLossBackward0>)
tensor(2.3177, grad_fn=<NllLossBackward0>)
tensor(2.3050, grad_fn=<NllLossBackward0>)
tensor(2.2990, grad_fn=<NllLossBackward0>)
tensor(2.3180, grad_fn=<NllLossBackward0>)
tensor(2.2940, grad_fn=<NllLossBackward0>)
tensor(2.3002, grad_fn=<NllLossBackward0>)
tensor(2.2984, grad_fn=<NllLossBackward0>)
优化器
进入调试后,在yjh/Protected Attributes/_modules/model1//Protected Attributes/_modules/‘0’/weight下的grad即为梯度
import torch
import torchvision
from torch import nn
from torch.nn import Linear, Flatten, MaxPool2d, Conv2d, Sequential
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64, shuffle=True)
class Yjh(nn.Module):
def __init__(self):
super().__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, 1, padding=2), # 注意需要用逗号分隔
MaxPool2d(2),
Conv2d(32, 32, 5, 1, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
yjh = Yjh()
optim = torch.optim.SGD(yjh.parameters(), lr=0.01) # 学习速率不要设置得太大
for epoch in range(20):#全部学习20遍,一般都是成百上千的
running_loss=0.0
for data in dataloader:
imgs, targets = data
outputs = yjh(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad() # 梯度清零
result_loss.backward()
optim.step()
running_loss=running_loss+result_loss
print(running_loss)#整体上的误差
输出结果:
tensor(360.1394, grad_fn=)
tensor(354.0514, grad_fn=)
tensor(330.8956, grad_fn=)
tensor(314.3040, grad_fn=)
tensor(303.5132, grad_fn=)
tensor(295.3024, grad_fn=)
tensor(287.8922, grad_fn=)
tensor(279.0746, grad_fn=)
tensor(273.7878, grad_fn=)
tensor(267.6326, grad_fn=)
tensor(261.7827, grad_fn=)
tensor(256.1693, grad_fn=)
tensor(251.1363, grad_fn=)
tensor(247.0008, grad_fn=)
tensor(242.6788, grad_fn=)
tensor(238.7857, grad_fn=)
tensor(234.5486, grad_fn=)
tensor(231.1932, grad_fn=)
tensor(227.9656, grad_fn=)
tensor(224.6279, grad_fn=)
VGG模型
一般作为前置的一个网络,然后后面再添加其他网络模型
查看网络结构
import torchvision
from torch import nn
vgg16_false=torchvision.models.vgg16(pretrained=False)#pretrained=False是未进行训练的,progress显示进度条
vgg16_true=torchvision.models.vgg16(pretrained=True)#progress显示进度条
print(vgg16_false)
train_data=torchvision.datasets.CIFAR10('./dataset',train=True,transform=torchvision.transforms.ToTensor())
vgg16_true.classifier.add_module('add_linear',nn.Linear(1000,10))#可以将线性模型加在classifier的sequential里
print(vgg16_true)
vgg16_false.classifier[6]=nn.Linear(4096,10)#将输出由1000改为10
输出结果:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
(add_linear): Linear(in_features=1000, out_features=10, bias=True)
)
)
模型的保存
import torch
import torchvision.models
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式1 最好保存为pth,不仅保存了网络模型结构,还保存了参数
torch.save(vgg16, "vgg16_methd1.pth")
# 保存方式2 将网络模型中的参数保存为字典形式(官方推荐),空间小
torch.save(vgg16.state_dict(), 'vgg16_methd2.pth')
模型的加载
import torch
#对应保存方式一的加载方式
import torchvision.models
model=torch.load("vgg16_methd1.pth")#如果用自己的网络模型,加载时需要重新定义类
print(model)
#对应保存方式二的加载方式
#复原网络模型结构
vgg16=torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict("vgg16_methd2.pth")
# model2=torch.load("vgg16_methd1.pth")
print(vgg16)
完整的模型训练套路
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import * # 导入另一个文件的所有内容
# 准备训练集
train_data = torchvision.datasets.CIFAR10("./dataset", train=True, download=True,
transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练集的长度为:{}".format(train_data_size))
print("测试集的长度为:{}".format(test_data_size))
# 加载训练集
train_dataloader = DataLoader(train_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
# 创建网络模型
yjh = Yjh()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
learning_rate = 1e-2 # 习惯于将这个参数提取出来
optimizer = torch.optim.SGD(yjh.parameters(), lr=learning_rate, ) # 梯度下降
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数
epoch = 10 # 训练的轮数
# 添加tensorboard
writer = SummaryWriter("./logs_train_1")
for i in range(epoch):
print("-----第{}轮训练开始-----".format(i + 1))
yjh.train()#把网络设置成训练模式,对特定层起作用
for data in train_dataloader:
imgs, targets = data
output = yjh(imgs)
loss = loss_fn(output, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("训练次数:{},Loss={}".format(total_train_step, loss.item())) # 最后加item()会直接输出一个数字,最后也可以直接写为loss
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤
yjh.eval()#把网络设置成验证模式,对特定层起作用
total_accuracy=0#整体的准确率
total_test_loss = 0 # 计算整个数据集的误差
with torch.no_grad():#设置无梯度,不需要对梯度进行改变
for data in test_dataloader:
imgs, targets = data
outputs = yjh(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy=(outputs.argmax(1)==targets).sum()
total_accuracy=total_accuracy+accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的准确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("测试的准确率",total_accuracy/test_data_size,total_test_step)
total_test_step += 1
#保存模型
torch.save(yjh,"yjh_{}.pth".format(i))#保存几轮的训练模型
#torch.save(yjh.state_dict(),"yjh_{}.pth".farmat(1))#官方推荐
print("模型已保存")
writer.close()
模型单独放一个.py
import torch
from torch import nn
from model import *
class Yjh(nn.Module):
def __init__(self) -> None:
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
if __name__ == '__main__':
yjh = Yjh()
input = torch.ones((64, 3, 32, 32))
output = yjh(input)
print(output.shape)
输出结果:
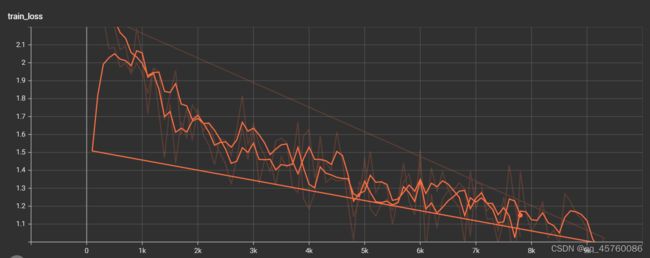
注意:不规则下降曲线是正确的输出
由上图可知,模型训练的越多,模型的损失越低

模型的正确率判断
2xinput
Model(2分类)
output=[0.1,0.2] [0.3,0.4]
通过Argmax得到最大的概率,即Preds=[1] [1]
input target=[0] [1]
Preds==inputs target
[false,true].sum()=1
代码实现:
import torch
outputs = torch.tensor([[0.1, 0.2], [0.3, 0.4]])
print(outputs.argmax(1))#值为1,则横着比,如0.1与0.2相比较,值为0,则竖着比较,如0.1与0.3相比较
preds=outputs.argmax(1)
targets=torch.tensor([0,1])
print((preds==targets).sum())
输出结果:
tensor([1, 1])
tensor(1)
GPU训练(比CPU快很多)
-
方式一:实现以下四个条件
-
网络模型
yjh = Yjh() if torch.cuda.is_available(): yjh=yjh.cuda()#将网络模型转移到cuda上 -
数据(输入、输出)
imgs, targets = data if torch.cuda.is_available(): imgs=imgs.cuda() targets=targets.cuda() -
损失函数
# 损失函数 loss_fn = nn.CrossEntropyLoss() if torch.cuda.is_available():#判断GPU是否可用 loss_fn=loss_fn.cuda() -
.cuda()
-
在GPU训练下的400次所用时间:
训练200的时间的时间为:9.526910781860352
训练次数:200,Loss=2.2695932388305664
训练400的时间的时间为:11.822770833969116
训练次数:400,Loss=2.1631038188934326
未用GPU训练400次所用时间
训练200的时间的时间为:12.44710397720337
训练次数:200,Loss=2.2931666374206543
训练400的时间的时间为:24.154792308807373
训练次数:400,Loss=2.231562852859497
若无硬件GPU,则可以使用Google的colab,新建笔记本,然后在文件里的笔记本设置设置GPU加速,每周30小时免费使用(速度很快)
-
方式二,易统一更改配置
-
先定义一个设备:device=torch.device(“cuda”)
若有多个,也可以指定某一个显卡torch.device(“cuda:1”)
-
与方式一相似,在.cuda()处使用.to(device)
如
if torch.cuda.is_available():#判断GPU是否可用 loss_fn=loss_fn.to(device)
-
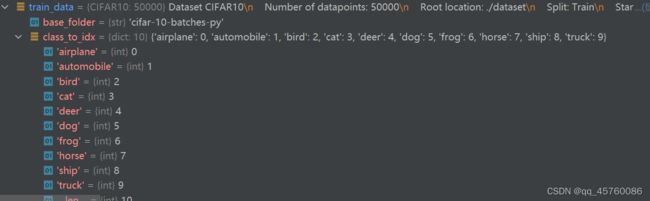
模型验证
通过在数据集添加时添加断点,debug后查看分类索引,可以得到以下图片
import torch
import torchvision.transforms
from PIL import Image
from torch import nn
image_path = "./imgs/img_1.png"
image = Image.open(image_path)
image = image.convert("RGB") # 因为png是四通道的,需要转为三通道
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)), torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
# 创建网络模型
class Yjh(nn.Module):
def __init__(self) -> None:
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
model = torch.load("yjh_0.pth", map_location=torch.device("cpu")) # GPU上训练的模型,在加载时要注意以什么方式运行
print(model)
image=torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad(): # 可用不用管梯度,节约内存,性能
output = model(image)
print(output)
print(output.argmax(1))
输出为:
tensor([[ 1.2021, 0.4194, 0.0154, -0.8249, -0.9728, -0.7813, -1.5403, -0.3458,
1.6731, 1.2716]])
tensor([8])
可知结果并不正确,因为模型只经过了一轮训练
model = torch.load("yjh_49.pth", map_location=torch.device("cpu")) # GPU上训练的模型,在加载时要注意以什么方式运行,加载训练50次的模型
输出结果为
tensor([[ 3.7672, -25.3946, 7.4116, 10.2170, 1.1890, 11.3926, 7.7192,
-0.6535, -4.2947, -10.5369]])
tensor([5])
结果正确

在pytorch入门教学视频中,小土堆做到了保姆级的教学,许多重要的地方也反复提及,教学内容及其方式不枯燥,比起其他我看过的pytorch入门视频,小土堆的视频真正做到了入门教学,而不是劝退教学,跟着小土堆一步步往下走,会发现越来越有趣,一环扣一环,内容完整,安排合理,前列推荐想学pytorch的同学观看。出现error,小土堆会耐心查找,并教会怎么查找并解决error,在学习pytorch的过程中,还学会了许多其他的知识,何乐不为呢!在自己实践中,出现了老师没有出现的error,也不用着急,百度可以轻松解决!