深度学习框架-Backbone汇总-附参考文献ris格式
参考文献Ris下载链接:https://download.csdn.net/download/xiaohuilang6/15542962
1. LeNet5:(1998)
https://ieeexplore.ieee.org/document/726791
| Name |
Output |
Kernel-Size |
Padding |
Stride |
Channel |
| Input |
32*32 |
/ |
/ |
/ |
1 |
| Conv |
28*28 |
5*5 |
0 |
1*1 |
6 |
| Pool-ave |
14*14 |
2*2 |
0 |
2*2 |
6 |
| Conv |
10*10 |
5*5 |
0 |
1*1 |
16 |
| Pool-ave |
5*5 |
2*2 |
0 |
2*2 |
16 |
| Conv |
1*1 |
5*5 |
0 |
1*1 |
120 |
| FC |
/ |
/ |
/ |
/ |
84 |
| Output |
/ |
/ |
/ |
/ |
N |

2. AlexNet:(2012)
https://dl.acm.org/doi/10.1145/3065386
提出Relu,dropout,LRN,解决了Sigmoid在网络深时梯度弥散问题;重叠最大池化避免了平均池化的模糊问题。
| Name |
Output |
Kernel-Size |
Padding |
Stride |
Channel |
| Input |
224*224 |
/ |
/ |
/ |
3 |
| Conv |
55*55 |
11*11 |
0 |
4*4 |
96 |
| LRN |
55*55 |
5 |
/ |
/ |
96 |
| Pool-max |
27*27 |
3*3 |
0 |
2*2 |
96 |
| Conv |
27*27 |
5*5 |
2*2(SAME) |
1*1 |
256 |
| LRN |
27*27 |
5 |
/ |
/ |
256 |
| Pool-max |
13*13 |
3*3 |
0 |
2*2 |
256 |
| Conv |
13*13 |
3*3 |
1*1(SAME) |
1*1 |
384 |
| Conv |
13*13 |
3*3 |
1*1(SAME) |
1*1 |
384 |
| Conv |
13*13 |
3*3 |
1*1(SAME) |
1*1 |
256 |
| Pool-max |
6*6 |
3*3 |
0 |
2*2 |
256 |
| FC+Dropout |
/ |
/ |
/ |
/ |
4096 |
| FC+Dropout |
/ |
/ |
/ |
/ |
4096 |
| Output |
/ |
/ |
/ |
/ |
N |

3. VGG:(2014)
https://arxiv.org/abs/1409.1556v1
牛津大学视觉组/Google DeepMind——全部使用3*3卷积核和2*2的池化核
2个3*3的卷积层相当于1个5*5的卷积层,使得一个像素和5个像素产生关联;
3个3*3的卷积层相当于1个7*7的卷积层;
3*3的卷积层具有更少的参数,更多的非线性变换,因为每层后都有Relu激活函数,学习能力更强!
VGG-19相对于VGG-16参数增加很少,参数主要在全连接层;
可以先训练复杂度小的网络,再将训练好的参数作为复杂网络的初始化参数,可以更快收敛!
在预测时:采用Multi-Scale策略,图像放缩至S,在最后一个卷积层,通过滑动窗口方法,分别获得各个窗口内特征的分类,再将所有分类求平均;
在训练时:采用数据增强方法:缩放至不同尺度(Multi-Scale),随机裁剪(Multi-Crop)为224*224,增加数据量,防止过拟合;

4. Inception-v1(GoogleNet): (2015)
https://arxiv.org/abs/1409.4842
Inception控制了计算量和参数量的同时,获得了很好的性能,top-5错误率6.67%,只有约500万的参数量,Alexnet有6000万的参数。
模型更深,表达能力更强:
卷积层增加表达能力主要靠增加输出通道数,计算量大。每个输出通道对应一个滤波器,同一滤波器共享参数,只能提一类特征,因此一个输出通道只做一种特征处理。NIN中NLPConv有更强大能力,允许通道间组合信息,效果明显,MLPConv等效于卷积层后连接1*1卷积层,并Relu激活。
Inception Module结构中4个分支都用了1*1的卷积,可跨通道组织信息,提高了网络的表达能力,同时可对输出通道进行升维或降维,进行跨通道特征变换,性价比高,用很小的计算量能增加一层特征变换和非线性化。
可以让网络宽度和深度有效扩充,提升准确率并不至于过拟合。
人类神经元是稀疏的,因此,大型网络的合理连接方式也是稀疏的。
可以减轻过拟合,并降低参数量;
Inception Net目的就是找到最优的稀疏结构。Hebbian原理:神经反射活动的持续与重复会导致神经元连接的稳定性提升。
Provable Bounds for Learning Some Deep Representations一文中指出,如果数据集的概率分布可以用一个很大的很稀疏的网络所表达,那么构筑这个网络的方法是逐层构造:将上一层的节点聚类,并将聚类出的每个小簇连接在一起。这个相关性高的节点应连接在一起的结论,从神经网络角度对Hebbian原理的有效证明。
好的稀疏结构应符合Hebbian原理,我们应把相关性高的节点连接在一起,普通数据集中,可能要对神经元节点进行聚类,图片中,天然的就是邻近区域的像素相关性高,因此相邻的像素被卷积操作连接在一起。我们可能有多个卷积核,同一空间位置但不同通道的数据相关性高,因此1*1的卷积可以很自然的将同一空间位置、不同通道的特征连接在一起。这就是为什么1*1卷积可以频繁应用在Inception Net中的原因。1*1的卷积所连接的节点相关性是最高的,稍大一点的尺寸,如3*3或5*5卷积所连接的节点相关性也很高,可适当用一些大尺寸的卷积增加多样性,构造符合Hebbian原理的稀疏结构。
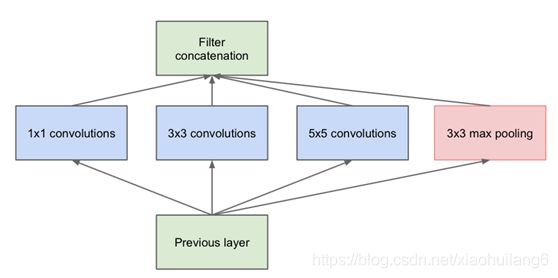
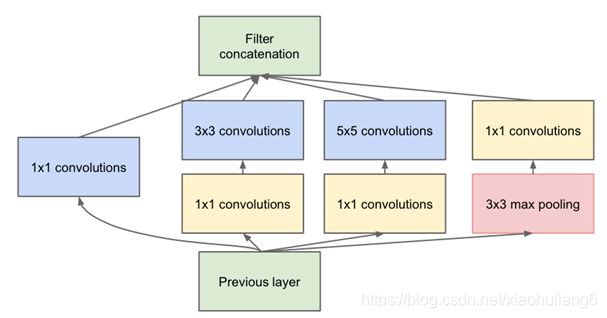

Inception Module中,1*1的卷积比例最高,3*3和5*5的卷积比例稍低,整个网络会有多个Inception Module。我们希望靠后的Inception Module可捕捉更高阶的抽象特征,因此靠后的Inception Module的卷积的空间集中度应该降低,这样可捕获大面积的特征。靠后的Inception Module中,3*3和5*5的占比更多
5. Inception-v2:(2015)
https://arxiv.org/abs/1502.03167 https://arxiv.org/abs/1512.00567
用2个3*3代替5*5,提出了Batch Normalization层。
BN层是一个非常有效的正则化方法,可让卷积网络的训练速度加快很多倍,同时,收敛后的分类准确率大幅提高。传统的神经网络训练时每一层的输入的分布都在变化,导致训练变得困难,只能用很小的学习率解决。BN可以有效解决该问题,学习速率增大很多倍,训练时间大幅缩减,还起到了正则化作用,可以减少或取消Dropout,简化网络结构。
单纯的BN获得的增益还不明显,还要一些调整:增大学习率并加快学习衰减速率,以适应BN规范化后的数据;去除Dropout并减轻L2正则;去除LRN;更彻底的对样本进行Shuffle,减少数据增强过程中对数据的光学畸变(BN训练更快,每个样本训练次数更少,真实样本更有帮助),V2比V1快了14倍,准确率上限更高。


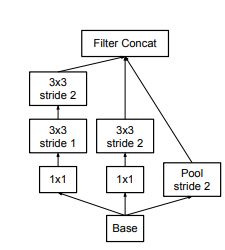


6. Inception-v3:(2016)
https://arxiv.org/pdf/1512.00567.pdf
1. 引入Factorization into small convolutions思想:将一个较大的二维卷积拆成两个较小的一维卷积,7*7拆为1*7和7*1,一方面节约了参数,加速运算并减轻过拟合,同时增加了一层非线性扩展模型表达能力。这种非对称的卷积结构比对称拆分为几个相同小卷积效果更明显,可处理更多更丰富空间特征,增加特征多样性。
2. 优化了Inception Module结构,有35*35,17*17和8*8三种不同结构。只在网络后部出现,还使用了分支中的分支(8*8结构)
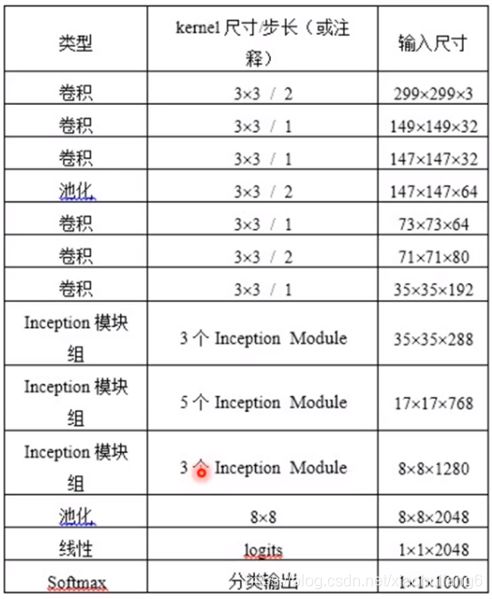


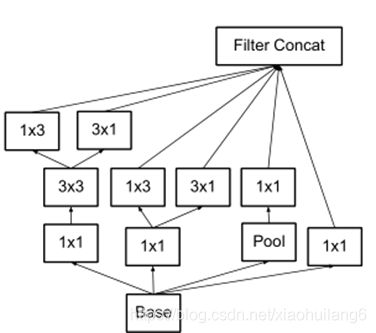
7. Resnet: (2016)
https://ieeexplore.ieee.org/document/7780459
网络越深,越难训练,这是因为存在梯度消失和梯度爆炸问题
残差连接时,先加法运算,再激活
随着网络层数的增加,网络发生了退化(degradation)的现象:随着网络层数的增多,训练集loss逐渐下降,然后趋于饱和,当你再增加网络深度的话,训练集loss反而会增大。注意这并不是过拟合,因为在过拟合中训练loss是一直减小的。
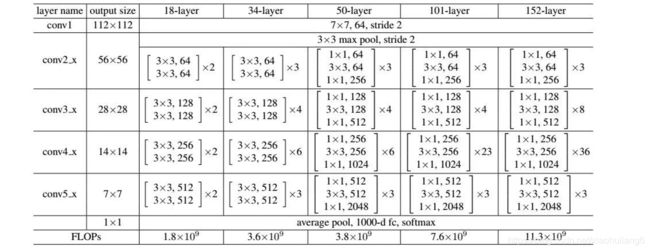

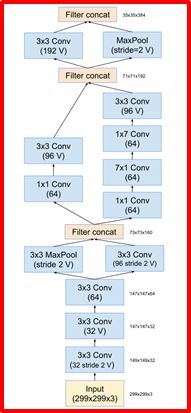
8.1 Inception-v4: (2017)
https://arxiv.org/abs/1602.07261





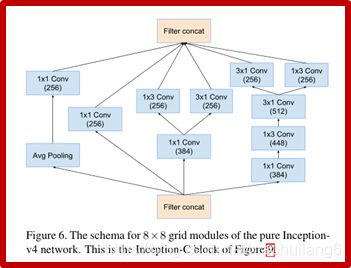
8.2 Inception-resnet-v2: (2017)
https://arxiv.org/abs/1602.07261



9. DenseNet: (2017)
https://arxiv.org/pdf/1608.06993.pdf
https://github.com/liuzhuang13/DenseNet
1、减轻了vanishing-gradient(梯度消失)
2、加强了feature的传递
3、更有效地利用了feature
4、一定程度上较少了参数数量
每个卷积层的输出feature map的数量都很小(小于100),而不是像其他网络一样动不动就几百上千的宽度。同时这种连接方式使得特征和梯度的传递更加有效,网络也就更加容易训练
Each layer has direct access to the gradients from the loss function and the original input signal, leading to an implicit deep supervision.
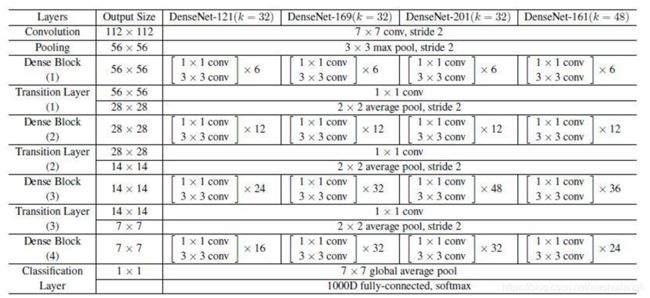




10. ResNeXt:(2017)
https://ieeexplore.ieee.org/document/8100117
传统的要提高模型的准确率,都是加深或加宽网络,但是随着超参数数量的增加(比如channels数,filter size等等),网络设计的难度和计算开销也会增加。因此本文提出的 ResNeXt 结构可以在不增加参数复杂度的前提下提高准确率,同时还减少了超参数的数量(得益于子模块的拓扑结构一样)。
Inception 系列网络,简单讲就是 split-transform-merge 的策略,但是 Inception 系列网络有个问题:网络的超参数设定的针对性比较强,当应用在别的数据集上时需要修改许多参数,因此可扩展性一般。
同时采用 VGG 堆叠的思想和 Inception 的 split-transform-merge 思想,但是可扩展性比较强,可以认为是在增加准确率的同时基本不改变或降低模型的复杂度。这里提到一个名词cardinality,原文的解释是the size of the set of transformations,如下图 Fig1 右边是 cardinality=32 的样子,这里注意每个被聚合的拓扑结构都是一样的(这也是和 Inception 的差别,减轻设计负担)
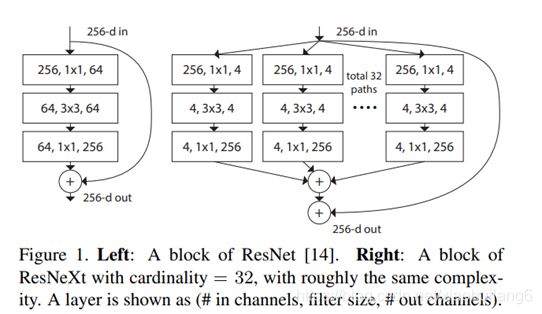

11. DPNet:(2017)
https://arxiv.org/abs/1707.01629
DPN算法简单讲就是将ResNeXt和DenseNet融合成一个网络

12. NasNet:(2018)
https://arxiv.org/pdf/1707.07012.pdf
Neural Architecture Search (NAS) framework:模型结构搜索网络
核心一:延续NAS论文的核心机制使得能够自动产生网络结构;
核心二:采用resnet和Inception重复使用block结构思想;
核心三:利用迁移学习将生成的网络迁移到大数据集上提出一个new search space。
假设:如果一个神经网络能在结构相似的小规模数据集上得到更好的成绩,那么它在更大更复杂的数据集上同样能表现得更好。
控制器依次搜索隐藏状态,隐藏状态,何种操作,何种操作,何种组合方法,这5个方法和操作的组合。其中,每种方法,每种操作都对应于一个softmax损失。这样重复B次,得到一个最终block模块。最终的损失函数就有5B个。实验中最优的B=5。
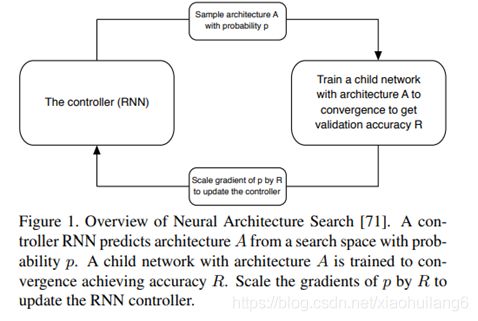


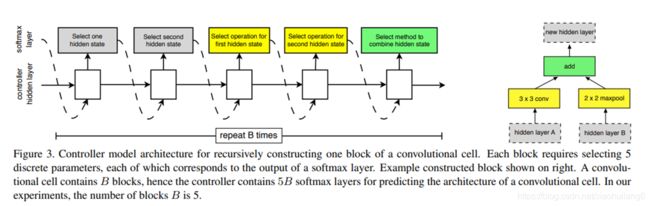
Scheduled Drop Path
在优化类似于Inception的多分支结构时,以一定概率随机丢弃掉部分分支是避免过拟合的一种非常有效的策略,例如DropPath[4]。但是DropPath对NASNet不是非常有效。在NASNet的Scheduled Drop Path中,丢弃的概率会随着训练时间的增加线性增加。这么做的动机很好理解:训练的次数越多,模型越容易过拟合,DropPath的避免过拟合的作用才能发挥的越有效。

13. SENet:(2019)
https://arxiv.org/abs/1709.01507
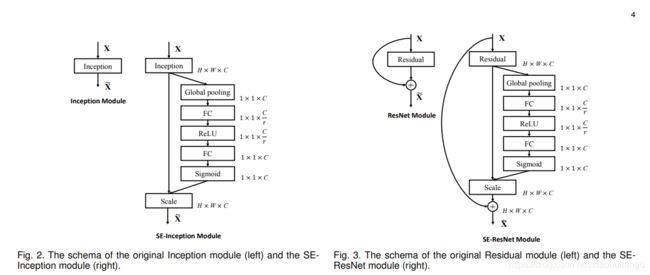
SENet网络的创新点在于关注channel之间的关系,希望模型可以自动学习到不同channel特征的重要程度。为此,SENet提出了Squeeze-and-Excitation (SE)模块,
SE模块首先对卷积得到的特征图进行Squeeze操作,得到channel级的全局特征,然后对全局特征进行Excitation操作,学习各个channel间的关系,也得到不同channel的权重,最后乘以原来的特征图得到最终特征。本质上,SE模块是在channel维度上做attention或者gating操作,这种注意力机制让模型可以更加关注信息量最大的channel特征,而抑制那些不重要的channel特征。另外一点是SE模块是通用的,这意味着其可以嵌入到现有的网络架构中。

Squeeze操作


Excitation操作

为了降低模型复杂度以及提升泛化能力,这里采用包含两个全连接层的bottleneck结构,其中第一个FC层起到降维的作用,降维系数为r是个超参数,然后采用ReLU激活。最后的FC层恢复原始的维度。
最后将学习到的各个channel的激活值(sigmoid激活,值0~1)乘以U上的原始特征:
14. EfficentNet:(2019)
https://arxiv.org/abs/1905.11946
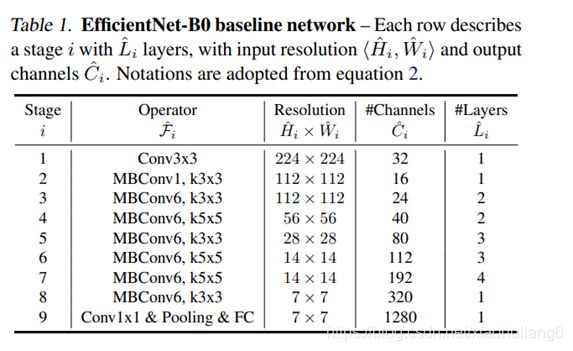
卷积神经网络(ConvNets)通常是在固定的资源预算下发展起来的,如果有更多的资源可用的话,则会扩大规模以获得更好的精度,比如可以提高网络深度(depth)、网络宽度(width)和输入图像分辨率 (resolution)大小。但是通过人工去调整 depth, width, resolution 的放大或缩小的很困难的,在计算量受限时有放大哪个缩小哪个,这些都是很难去确定的,换句话说,这样的组合空间太大,人力无法穷举。基于上述背景,该论文提出了一种新的模型缩放方法,它使用一个简单而高效的复合系数来从depth, width, resolution 三个维度放大网络,不会像传统的方法那样任意缩放网络的维度,基于神经结构搜索技术可以获得最优的一组参数(复合系数)
Observation 1:对网络深度、宽度和分辨率中的任何温度进行缩放都可以提高精度,但是当模型足够大时,这种放大的收益会减弱。
Observation 2:为了追去更好的精度和效率,在缩放时平衡网络所有维度至关重要

STEP 1:我们首先固定ϕ = 1 ,假设有相比于原来多了2倍的资源,我们基于等式(2)和(3)先做了一个小范围的搜索,最后发现对于EfficientNet-B0来说最后的值为α = 1.2 , β = 1.1 , γ = 1.15 ,在α ⋅ β 2 ⋅ γ 2 ≈ 2 的约束下;
STEP 2:接着我们固定α,β,γ作为约束,然后利用不同取值的ϕ 网络做放大,来获得Efficient-B1到B7;

15. Res2Net: (2019)
https://ieeexplore.ieee.org/document/8821313
计算负载不增加,特征提取能力更强大
卷积神经网络(CNN) backbone 的最新进展不断展示出更强的多尺度表示能力,从而在广泛的应用中实现一致的性能提升。然而,大多数现有方法以分层方式(layer-wise)表示多尺度特征。
在本文中,研究人员在一个单个残差块内构造分层的残差类连接,为CNN提出了一种新的构建模块,即Res2Net——以更细粒度(granular level)表示多尺度特征,并增加每个网络层的感受野(receptive fields)范围。

参考文献:
- Yann Lecun, Leon Bottou, Yoshua Bengio, Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, Nov, 1998, 86(11): 2278-2324. doi: 10.1109/5.726791.
- Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton. ImageNet Classification with Deep Convolutional Neural Networks. 26th Annual Conference on Neural Information Processing Systems(NIPS), Lake Tahoe, Nevada, United States, Dec 3-6, 2012, pp. 1097-1105. doi: 10.1145/3065386.
- Karen Simonyan, Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. 3rd International Conference on Learning Representations(ICLR), May 7-9, 2015, arXiv:1409.1556.
- Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich. Going deeper with convolutions. IEEE Conference on Computer Vision and Pattern Recognition(CVPR), June 7-12, 2015, pp. 1-9. doi: 10.1109/CVPR.2015.7298594
- Sergey Ioffe, Christian Szegedy. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. 32nd International Conference on Machine Learning(ICML), July 6-11, 2015, pp. 448-456.
- Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, Zbigniew Wojna. Rethinking the Inception Architecture for Computer Vision. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, June 27-30, 2016, pp. 2818-2826. doi: 10.1109/CVPR.2016.308.
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Deep Residual Learning for Image Recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, June 27-30, 2016, pp. 770-778. doi: 10.1109/CVPR.2016.90.
- Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, Feb 04-09, 2017, pp. 4278-4284.
- Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger. Densely Connected Convolutional Networks. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, July 21-26, 2017, pp. 2261-2269. doi: 10.1109/CVPR.2017.243.
- Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, Kaiming He. Aggregated Residual Transformations for Deep Neural Networks. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, July 21-26, 2017, pp. 5987-5995. doi: 10.1109/CVPR.2017.634.
- Yunpeng Chen, Jianan Li, Huaxin Xiao, Xiaojie Jin, Shuicheng Yan, Jiashi Feng. Dual Path Networks. 31st Annual Conference on Neural Information Processing Systems(NIPS), Dec 4-9, 2017, pp. 4468-4476.
- Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le. Learning Transferable Architectures for Scalable Image Recognition. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, June 18-23, 2018, pp. 8697-8710, doi: 10.1109/CVPR.2018.00907.
- Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu. Squeeze-and-Excitation Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2019, 42(8): 2011 – 2023. doi: 10.1109/TPAMI.2019.2913372.
- Mingxing Tan, Quoc V. Le. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. 36th International Conference on Machine Learning (ICML), June 9-15, 2015, pp. 10691-10700.
- Shang-Hua Gao, Ming-Ming Cheng, Kai Zhao, Xin-Yu Zhang, Ming-Hsuan Yang, Philip Torr. Res2Net: A New Multi-Scale Backbone Architecture. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(2): 652-662. doi: 10.1109/TPAMI.2019.2938758.
MobileNet结构:
1. SqueezeNet:(2016)
https://arxiv.org/abs/1602.07360
从LeNet5到DenseNet,反应卷积网络的一个发展方向:提高精度。这里我们开始另外一个方向的介绍:在大幅降低模型精度的前提下,最大程度的提高运算速度。
提高运算所读有两个可以调整的方向:
减少可学习参数的数量;
减少整个网络的计算量。
这个方向带来的效果是非常明显的:
减少模型训练和测试时候的计算量,单个step的速度更快;
减小模型文件的大小,更利于模型的保存和传输;
可学习参数更少,网络占用的显存更小。
SqueezeNet正是诞生在这个环境下的一个精度的网络,它能够在ImageNet数据集上达到AlexNet[2]近似的效果,但是参数比AlexNet少50倍,结合他们的模型压缩技术 Deep Compression[3],模型文件可比AlexNet小510倍。

Fire模块

2. MobileNet-v1:(2017)
https://arxiv.org/abs/1704.04861
深度可分离卷积(depthwise separable convolution)。




3. XCeption:(2017)
https://arxiv.org/abs/1610.02357
同一向复杂的Inception系列模型一样,它也引入了Entry/Middle/Exit三个flow,每个flow内部使用不同的重复模块,当然最最核心的属于中间不断分析、过滤特征的Middel flow。
Entry flow主要是用来不断下采样,减小空间维度;中间则是不断学习关联关系,优化特征;最终则是汇总、整理特征,用于交由FC来进行表达。



严格版本:每个通道深度可分离卷积
depthwise separable convolution深度可分离卷积
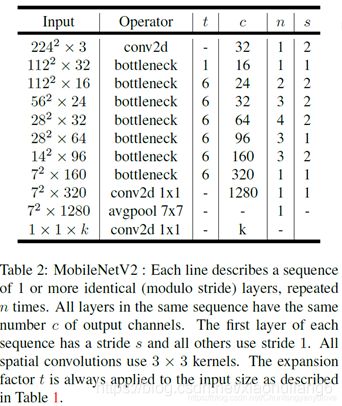
4. MobileNet V2:(2018)
https://openaccess.thecvf.com/content_cvpr_2018/papers/Sandler_MobileNetV2_Inverted_Residuals_CVPR_2018_paper.pdf
在使用V1的时候,发现depthwise部分的卷积核容易费掉,即卷积核大部分为零。作者认为这是ReLU引起的。
当低维信息映射到高维,经过ReLU后再映射回低维时,若映射到的维度相对较高,则信息变换回去的损失较小;若映射到的维度相对较低,则信息变换回去后损失很大,如下图所示。因此,认为对低维度做ReLU运算,很容易造成信息的丢失。而在高维度进行ReLU运算的话,信息的丢失则会很少。另外一种解释是,高维信息变换回低维信息时,相当于做了一次特征压缩,会损失一部分信息,而再进过relu后,损失的部分就更加大了。作者为了这个问题,就将ReLU替换成线性激活函数。
Inverted Residuals

Linear Bottleneck
将最后一层的ReLU替换成线性激活函数,而其他层的激活函数依然是ReLU6。

5. ShuffleNet-v1:(2018)
https://arxiv.org/pdf/1707.01083.pdf
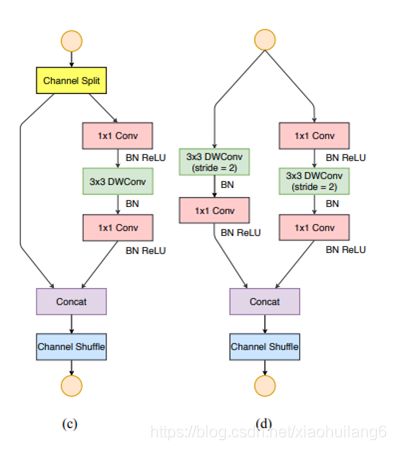
将密集的1x1卷积替换成1x1的group convolution,不过在第一个1x1卷积之后增加了一个channel shuffle操作。值得注意的是3x3卷积后面没有增加channel shuffle,按paper的意思,对于这样一个残差单元,一个channel shuffle操作是足够了。还有就是3x3的depthwise convolution之后没有使用ReLU激活函数。
下图c展示了其他改进,对原输入采用stride=2的3x3 avg pool,在depthwise convolution卷积处取stride=2保证两个通路shape相同,然后将得到特征图与输出进行连接(concat,借鉴了DenseNet?),而不是相加。极致的降低计算量与参数大小。

6. ShuffleNet-v2:(2018)
https://arxiv.org/abs/1807.11164v1
卷积层的输入和输出特征通道数相等时MAC最小,此时模型速度最快
过多的group操作会增大MAC,从而使模型速度变慢
模型中的分支数量越少,模型速度越快
element-wise操作所带来的时间消耗远比在FLOPs上的体现的数值要多,因此要尽可能减少element-wise操作

7. MnasNet:(2019)
https://arxiv.org/pdf/1807.11626v1.pdf
在搜索方法上,作者沿用了NASNet的强化学习方法,利用controller RNN去预测layer的六种搜索对象类型。MnasNet给强化学习的reward不只是验证集的精度Accuracy而已,还增加了latency的约束。reward的目标函数为

按照准确率提升5%,延时变成2倍的tradeoff原则,上面公式可变换为:
 其中,α = β = − 0.07
其中,α = β = − 0.07

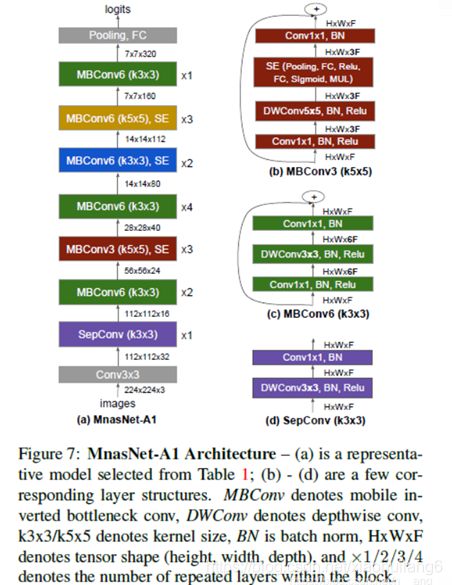
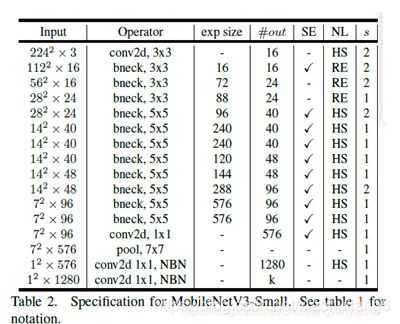
8. MobileNet V3:(2019)
https://ieeexplore.ieee.org/document/9008835/
mobilenet-v3是Google继mobilenet-v2之后的又一力作,作为mobilenet系列的新成员,自然效果会提升,mobilenet-v3提供了两个版本,分别为mobilenet-v3 large 以及mobilenet-v3 small,分别适用于对资源不同要求的情况,论文中提到,mobilenet-v3 small在imagenet分类任务上,较mobilenet-v2,精度提高了大约3.2%,时间却减少了15%,mobilenet-v3 large在imagenet分类任务上,较mobilenet-v2,精度提高了大约4.6%,时间减少了5%,mobilenet-v3 large 与v2相比,在COCO上达到相同的精度,速度快了25%,同时在分割算法上也有一定的提高。本文还有一个亮点在于,网络的设计利用了NAS(network architecture search)算法以及NetAdapt algorithm算法。并且,本文还介绍了一些提升网络效果的trick,这些trick也提升了不少的精度以及速度。
1.mobilenetv2+SE结构

2.修改尾部结构:


3.修改channel数量
参考文献:
- Forrest N. Iandola, Song Han, Matthew W. Moskewicz, Khalid Ashraf, William J. Dally, Kurt Keutzer. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. 2016, arXiv: 1602.07360.
- Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications, 2017, arXiv:1704.04861.
- François Chollet. Xception: Deep Learning with Depthwise Separable Convolutions. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, July 21-26, 2017, pp. 1800-1807. doi: 10.1109/CVPR.2017.195.
- Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen. MobileNetV2: Inverted Residuals and Linear Bottlenecks. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, June 18-23, 2018, pp. 4510-4520. doi: 10.1109/CVPR.2018.00474.
- Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, Jian Sun. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, June 18-23, 2018, pp. 6848-6856. doi: 10.1109/CVPR.2018.00716.
- Ningning Ma, Xiangyu Zhang, Hai-Tao Zheng, Jian Sun. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. 15th European Conference on Computer Vision (ECCV), Sep 8-14, 2018, pp. 122-138. doi: 10.1007/978-3-030-01264-9_8.
- Mingxing Tan, Bo Chen, Ruoming Pang,Vijay Vasudevan, Mark Sandler, Andrew Howard, Quoc V. Le. MnasNet: Platform-Aware Neural Architecture Search for Mobile. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, June 15-20 2019, pp. 2815-2823. doi: 10.1109/CVPR.2019.00293.
- Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, Hartwig Adam. Searching for MobileNetV3. IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea (South), Oct.27- Nov.2 2019, pp. 1314-1324. doi: 10.1109/ICCV.2019.00140.