自然语言处理学习笔记-李宏毅-01-SpeechRecognition01
输入:声音信号,一个向量序列,长度 T T T,维度 d d d
输出:文本,一个token序列,长度 N N N, V V V个不同的token
Token
- Phoneme:发音的基本单位,可以看做音标,需要词典
lexicon:词典,单词到phoneme的映射,这个映射是明确的,但是lexicon的获取比较困难 - Grapheme:书写的基本单位,例如26个英文字母以及空白符标点符号等,这种方法不需要词典的参与
- Word:词来当token,但是对于某些语言,词汇的数量很大
- Morpheme:比词小,但是比Grapheme大,最小的有意义的单位,例如将unbreakable拆成un,break,able
- Byte:
输入Acoustic Feature
取一个时间window,例如25ms,里面有400个采样点(16KHz),或使用MFCC转成39维的向量,或通过filter bank output得到80维的向量,之后移动窗口,连续的窗口之间有重叠
首先一个声音信号进来,经过DFT得到spectrogram(可以作为特征),之后将其经过filter bank和取log之后,经过DCT得到MFCC
一些语音资源:TIMIT(4h),WSJ(80h),Switchboard(300h),Librispeech(960h,免费),Fisher(2000h)
seq-seq
Listen, Attend, and Spell(LAS) NIPS’15
encoder
输入: { x 1 , x 2 , ⋯ , x T } \{x^1,x^2,\cdots,x^T\} {x1,x2,⋯,xT}acoustic feature
输出: { h 1 , h 2 , ⋯ , h T } \{h^1,h^2,\cdots,h^T\} {h1,h2,⋯,hT}高层次的表示
输入和输出长度是一样的,encoder可以使用RNN,1-D CNN,常见的是结合使用
在encoder的过程中会进行down sampling,有一些工作Pyramid RNN,每一层都减少一些输出尺寸,Pooling over time也是一个工作,time-delay DNN,truncated self-attention
attention
有一个vector z 0 z_0 z0关键字,分别和 h h h例如 h 1 h^1 h1通过match操作得到一个常量 α 0 1 \alpha_0^1 α01,这个match操作有dot-product attention和additive attention,前一种是将 h , z h,z h,z分别经过 W h , W z W^h,W^z Wh,Wz变换之后的结果点乘得到常量 α \alpha α,后一种方式是将 h , z h,z h,z分别经过 W h , W z W^h,W^z Wh,Wz变换之后的结果加起来,得到的结果经过tanh和线性函数输出 α \alpha α,这样之后每个 h h h都有 α \alpha α,将这些 α \alpha α经过一个softmax得到 α ′ \alpha' α′使加和为1,之后将 α ′ \alpha' α′作为权重将 h h h加和得到 c 0 c^0 c0,这个 c 0 c^0 c0常被称为context vector,是decoder的输入
decoder
c 0 c^0 c0作为输入,输入一个token的分布,每个token一个几率,所以输出的尺寸是token的数量,此时有隐层状态 z 1 z^1 z1,之后 z 1 z^1 z1又到encoder得到 c 1 c^1 c1,经过decoder输出下一个token,如此不断循环,token序列的生成使用了beam search,动态规划的思想,每次只保留固定数目的最好的几条路径,使用到了teacher forcing的思想,也就是使用上一时刻的gt作为下一时刻的输入
思考:是否需要attention机制,因为这个最早用在翻译中,因为翻译的顺序和原顺序不是对应的,现在翻译的词可能是很早之前的词,但是语音识别里面这个问题很小
LAS的缺点:不能一边听一边识别,现在的是在听完一句话之后才能进行encoder
Connectionist Temporal Classification(CTC) ICML’06
可以做到online recognition,只需要encoder得到 h h h,然后每个 h h h经过classification得到token,也就是假如输入 T T T个acoustic Feature,输出 T T T个token,因为每个Feature很短,所以token的空间增加一个 ∅ \emptyset ∅表示,之后对得到的token序列进行后处理,merge相同的token,丢掉 ∅ \emptyset ∅,此时的gt构建比较困难,因为输出中有重复token和 ∅ \emptyset ∅,需要alignment来人为构建,CTC类似于每次只选择一个 h h h vector作为decoder的输入
RNN Transducer(RNN-T) ICML’12
在介绍RNN-T之前介绍RNA这个工作,之前的CTC的decoder可以看做每一个输出只和一个输入的 h h h有关,和其上下文无关,那么RNA就增强了不同时刻之间的联系
现在都是一个音对应一个输出,那么假如要一个音对应多个输出的token呢,例如 t h th th这个组合只有一个发音,RNN-T可以解决这个问题,对于每一个输入的 h h h都可以输出多个token,直到没有什么好输出的了就输出 ∅ \emptyset ∅之后再输入下一个 h h h,此时还是存在alignment的问题,需要在token之间插入 ∅ \emptyset ∅,有几个输入就要插入多少个 ∅ \emptyset ∅,此时会穷举所有的alignment
Neural Transducer NIPS’16
之前的CTC,RNA和RNN-T每次都只输入一个 h h h,而Neural Transducer每次输入 w w w个 h h h,也就是存在一个window,然后经过attetion得到一个输出,这个输出和RNN-T里面的输入 h h h的位置差不多
Monotonic Chunkwise Attention(MoChA) ICLR’18
之前在Neural Transducer里面的window每次都是移动固定的距离,此时是自动的决定啥时候移动,移动多少
HMM
此时需要比phoneme更细的表示,原因是不能有二义性,还需要alignment,需要语音和文本对齐,有不同的alignment,算出来的acoustic Feature就不同,接下来考虑如何将深度学习运用到HMM里面
Tandem
使用DL来产生较好的acoustic Feature,其他的HMM过程没有变
DNN-HMM Hybrid
使用DNN来得到 p ( a ∣ x ) p(a|x) p(a∣x),其中 a a a表示文本, x x x表示acoustic model,之后通过贝叶斯公式得到 p ( x ∣ a ) p(x|a) p(x∣a)也就是发射矩阵,其他的HMM过程没变
alignment
在LAS中计算给定acoustic feature条件下的文字序列的概率直接将decoder输出的概率相乘即可,但是CTC和RNN-T中计算需要alignment,需要将所有的alignment的情况举出来,然后将不同的情况下的加起来作为那个概率,存在以下问题:
- 如何穷举alignment
- 如何将不同的alignment下的概率加起来
- 如何训练
- 如何测试
首先解决如何穷举alignment这个问题,就是在label中插入 ∅ \emptyset ∅的过程,CTC的alignment假设一个表格,列是输入的长度为 T T T的acoustic feature,行是label每个token两侧加上 ∅ \emptyset ∅,之后寻找一个从左上到右下的路径,RNN-T类似
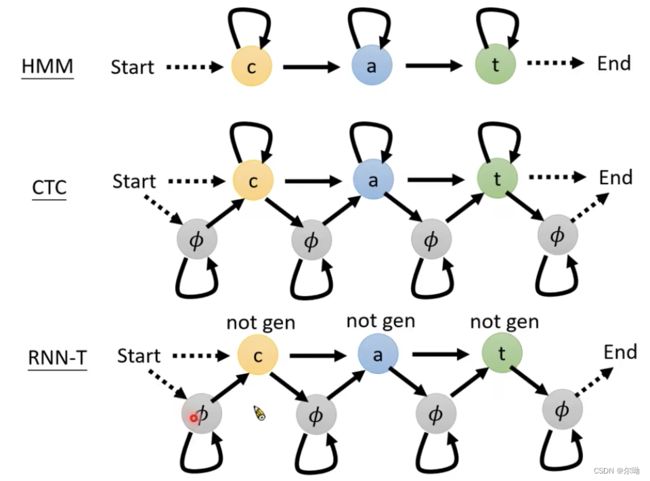
接下来解决如何将不同的alignment下的概率加起来:
假设现在有一个序列 ∅ c ∅ ∅ a ∅ t ∅ ∅ \emptyset c \emptyset \emptyset a \emptyset t \emptyset \emptyset ∅c∅∅a∅t∅∅