李宏毅《深度学习语言处理》学习笔记
大四保研,加入实验室提前学习基础知识,持续更新中
L1
1s可以有16,000个采样点,每个采样点有256个可能值

- 语音辨识 (Automatic Speech Recognition - ASR)
- 语音合成
- Speech Separatioon (鸡尾酒会效应) / Voice Conversion
- 语者辨认 / 关键词(唤醒词)辨认
- 文字产生 (Autoregressive / Non-autoregressive)
- Translation / Summarization / Chat-bot / Q&A
L2 - 语音辨识
声音:一串向量(长度:T,高度:d)
文字:一串token(长度:N,V种不同token)
通常来说,T>>N
Phoneme :发音的基本单位,需要语言学知识
Grapheme:书写的基本单位
Word:词汇,无法用于不能穷举词汇的语言
Morpheme:最小表达意义的单位 (“un”,“break”,“able”)
25ms作为一个音框,每次移动10ms,一秒钟的语音产生100个音框。
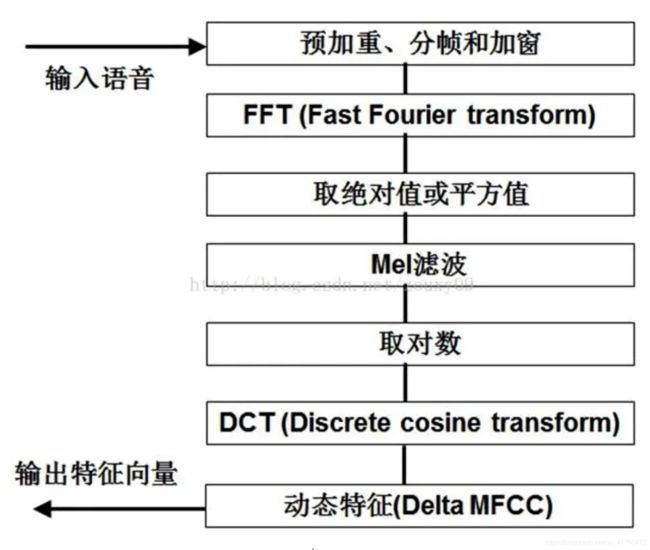
提取Acoustic Feature:
Waveform —(DFT)—> spectrogram —(filter bank)—> —(log)—> —(DCT)—> MFCC
补充知识:
- MFCC(Mel Frequency Cepstral Coefficents)
参见博客:https://www.jianshu.com/p/24044f4c3531
用于提取声音特征,主要步骤如下:
L3 - Listen, Attend and Spell (LAS) (seq2seq model)
listen为一个金字塔形的RNN encoder网络,将声音信号的filter bank特征作为输入,speller为一个基于attention机制的RNN decoder网络,将文字字符作为输出。
补充知识:
- RNN(循环神经网络)
参见博客:https://blog.csdn.net/qq_39422642/article/details/78676567

去掉w则是一个全连接神经网络。
循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。
这个网络在t时刻接收到输入 x t x_t xt之后,隐藏层的值是 s s s ,输出值是 o t o_t ot 。关键一点是, s t s_t st 的值不仅仅取决于 x t x_t xt ,还取决于 s t − 1 s_{t-1} st−1 。我们可以用下面的公式来表示循环神经网络的计算方法:

- Attention模型
参见博客:https://www.cnblogs.com/USTC-ZCC/p/11147825.html,https://www.cnblogs.com/USTC-ZCC/p/11155636.html
首先需要提到Encode-Decoder模型,该模型在文本识别与语音识别中尤为重要。

传统的Encode-Decoder模型是典型的分心模型,该模型由< x 1 x_1 x1, x 2 x_2 x2, x 3 x_3 x3,…, x n x_n xn>通过encoder产生中间语义 C C C,但是模型里的每个向量对于目标单词的贡献是一样的,如果输入句子比较长,此时所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,可想而知会丢失很多细节信息。
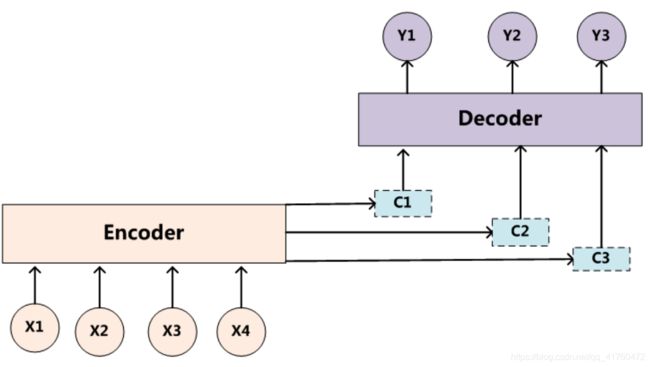
经过改进后的attention模型,由固定的中间语义表示 C C C换成了根据当前输出单词来调整成加入注意力模型的变化的 C i C_i Ci。其中 C i C_i Ci公式表示为:
C i = ∑ j = 1 L X a i j ∗ h j C_i=\sum^{L_X}_{j = 1} a_{ij}*h_j Ci=j=1∑LXaij∗hj
其中:
-
L x L_x Lx代表输入句子Source的长度
-
a i j a_{ij} aij代表在Target输出第i个单词时,Source输入句子中第j个单词的注意力分配系数
-
h j h_j hj是Source输入句子中第j个单词的语义编码
假设 C i C_i Ci下标i就是上面例子所说的“ 汤姆” ,那么 L x L_x Lx就是3,h1=f(“Tom”),h2=f(“Chase”),h3=f(“Jerry”)分别是输入句子每个单词的语义编码,对应的注意力模型权值则分别是0.6,0.2,0.2,所以g函数本质上就是个加权求和函数。
Attention模型是如何计算得到权重的:


例如,此时需要获取 Y i Y_i Yi单词,根据RNN,可以知道隐含层 H i − 1 H_{i-1} Hi−1的值,将 H i − 1 H_{i-1} Hi−1与 h j h_j hj进行对比,即 F ( H j , H i − 1 ) F(H_j,H_{i-1}) F(Hj,Hi−1)函数,可以获取目标单词 Y i Y_i Yi与每个输入单词的对齐可能性。这个 F F F函数在不同论文里可能会采取不同的方法,然后函数F的输出经过 S o f t m a x Softmax Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。
- Beam Search
beam search是对greedy search的一个改进算法。相对greedy search扩大了搜索空间,但远远不及穷举搜索指数级的搜索空间,是二者的一个折中方案。
beam search有一个超参数beam size(束宽),设为 k k k 。第一个时间步长,选取当前条件概率最大的 k k k 个词,当做候选输出序列的第一个词。之后的每个时间步长,基于上个步长的输出序列,挑选出所有组合中条件概率最大的 k k k 个,作为该时间步长下的候选输出序列。始终保持 k k k 个候选。最后从 k k k 个候选中挑出最优的。
beam search不保证全局最优,但是比greedy search搜索空间更大,一般结果比greedy search要好。
greedy search 可以看做是 beam size = 1时的 beam search。
- Teacher-Forcing
它每次不使用上一个state的输出作为下一个state的输入,而是直接使用训练数据的标准答案(ground truth)的对应上一项作为下一个state的输入。
Teacher Forcing工作原理: 在训练过程的 t t t 时刻,使用训练数据集的期望输出或实际输出: y ( t ) y (t) y(t) ,作为下一时间步骤的输入: x ( t + 1 ) x(t+1) x(t+1),而不是使用模型生成的输出 h ( t ) h(t) h(t)。
Teacher Forcing同样存在缺点: 一直靠老师带的孩子是走不远的。
因为依赖标签数据,在训练过程中,模型会有较好的效果,但是在测试的时候因为不能得到ground truth的支持,所以如果目前生成的序列在训练过程中有很大不同,模型就会变得脆弱。
也就是说,这种模型的cross-domain能力会更差,也就是如果测试数据集与训练数据集来自不同的领域,模型的performance就会变差。
减小缺点的方法:
- Beam Search
- Curriculum Learning