2021中国高校大数据挑战赛A题复盘+解题思路
引言
由于个人安排的原因,没有时间参加微信大数据挑战赛,倒是参加了2021年中国高校大数据挑战赛。这次比赛做的是中国电信提供数据集的A题,是一个异常检测的题目,一个人做的本科组二等奖,觉得还是不错的。(B题是华为提供的基于深度学习的目标检测的题目,这个没啥意思纯写算法)A题数据量还好,虽然是大数据竞赛,但个人觉得和2021山西省数学建模竞赛B题的数据量比起来还是差点。
题目回顾
异常检测(异常诊断/发现)、异常预测、趋势预测,是智能运维中首当其冲 需要解决的问题。这类问题是通过业务、系统、产品直接关联的 KPI 业务指标 进行分析诊断,指标主要包括用户感知类(如页面打开延时)、服务性能(如用 户点击量)、服务器硬件健康状况(如 CPU 利用率、内存使用率)等关键性能指 标。 不同场景的运维,分析的指标种类差异较大,但都具备时序性特点,不同场 景的 KPI 指标,以毫秒、秒、分钟、小时、天为时间间隔的数据序列都会出现, 有些复杂场景的业务,往往会混合多个时间间隔的数据,但均为随时间变化而变 化的时序数据。
以小区内的平均用户数、小区PCDP流量以及平均激活用户数三个指标为主要研究对象,完成以下问题:
问题 1 异常检测:利用附件的指标数据,对所有小区在上述三个关键指标上 检测出这 29 天内共有多少个异常数值,其中异常数值包含以下两种情况:异常 孤立点、异常周期。
问题 2 异常预测:针对问题 1 检测出的异常数值,通过该异常数值前的数据 建立预测模型,预测未来是否会发生异常数值。异常预测模型除了考虑模型准确 率以外,还需要考虑两点:1)模型输入的时间跨度,输入数据的时间跨度越长, 即输入数据量越多,模型越复杂,会增加计算成本和模型鲁棒性,降低泛化能力; 2)模型输出时间跨度,即预测的时长,如果只能精准预测下一个时刻是否发生 异常,在时效性上则只能提前一个小时,时效性上较弱。
问题 3 趋势预测:利用 2021 年 8 月 28 日 0 时至 9 月 25 日 23 时已有的数据, 预测未来三天(即 9 月 26 日 0 时-9 月 28 日 23 时)上述三个指标的取值。并完整填写附件
本题目我使用到的计算机工具和语言:Python,R,MATLAB
我的解题思路:
问题一:
问题一的话其实是非常有趣的一个题,有很大的开放性和创造性。也是个人觉得整个赛题最重要的一问,直接决定后面两问解题的思路和整个作品的思想的高度。
首先我认为这道题难点在于如何去判别异常点(异常周期后面再说),显然地,使用基于传统统计方法的判别方法进行是不可行的,如拉以达准则、分箱法。当然,如果你想更好地进行算法设计和建立模型,在文章中进行描述性统计的时候,可以用箱线图进行数据分布程度的考察。
那么为什么不能用传统的统计学方法进行异常点的剔除呢?
首先,我们要知道拉以达准则、分箱法只依据样本数据的大小和总体数据之间的关系进行异常点的判定。举个例子:如果一堆数据里面98%的数据大小都在95至100,剩下2%的数据都在30至35之间,传统的统计方法必定会把那2%数据进行剔除,可是你们有没有想过一个问题,**就是如果这个数据集是有周期性、季节性的、那么这群少数且大小和样本总体差异较大的数据就不是异常值,反而是一种数据特征的体现。**就拿这道题来说,如平均用户数,一般都是晚上较少,因为大部分人们都已经休息了,而傍晚6,7点小区内用户数会达到一个最多或是一个峰值,这一定程度上体现了居民的生活作息。
中北大学理学院的侯强教授说过:统计学是从数据中找信息。
这道题我们需要结合中国电信公司具体运营环境中去思考对异常点的判别准则。
如果通过机器学习的方法和思路来做,这也是十分困难的。因为这个用人工智能的行话来说,这是一个无监督学习问题,没有可训练和测试的数据和数据标签。常见的异常检测算法如kaggle算法、孤立森林算法其实实施效果都不显著。
那么,为了规避以数据大小为依据的异常点检测的方法,我认为其中一个简单的思路是比对3项关键KPI的增减趋势(从基站和计算机网络的角度来看,三项KPI之间应该是存在一定相关关系的),当某项KPI的增减趋势与其他两项完全不同或是差异较大时,该时间节点的KPI的数据就是异常孤立点。(最好不要单项指标观察,如果是单项指标,后期PCA算法很难达到好的结果)
但是要注意的是,在进行比对的时候,需要对数据进行平滑处理,对数据进行去躁。平滑算法依据自己水平高低来决定,一般的话简单的指数平滑就能达到很好的效果。如下:(多好看)
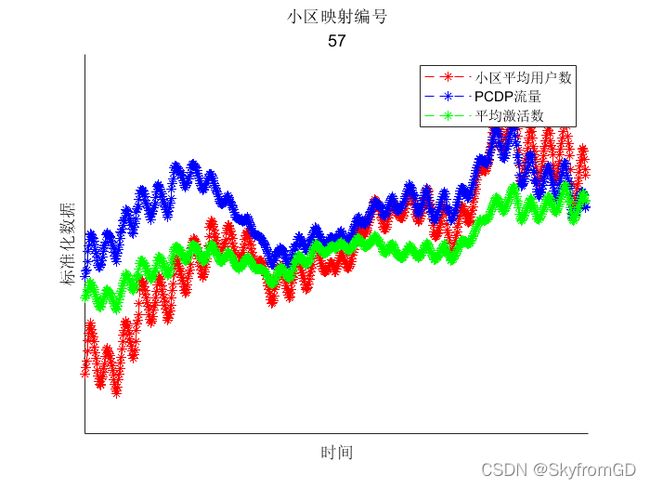
当然你也可以不用平滑,设计一个算法:可以将三项KPI进行数据降维处理,映射到另一个空间去,然后使用三维空间聚类,这里需要清楚的是:因为三项KPI都是有时序性的,那么需要设定周期把数据进行分组,分完组后再进行以下空间聚类算法的运算。我使用的是以24小时为时间周期进行分组。因为居民的生活周期一般是24小时,设定24小时也是较为科学合理的当然,这个聚类算法原理和KMEANS聚类是大同小异的,但是在设计上需要作出修改:比如你需要不断地更改点到簇的距离。这里推荐使用MATLAB。当然,这个聚类需要多次运算才能达到很好的异常检测效果,单次运算的结果可能不为准确的。
然后在检测出异常孤立点后,求异常周期就简单了,变成了一个数学建模题,这里常用的方法是使用傅里叶变换和混沌序列算法。鉴于数据量较大,我使用的是傅里叶变换,算力也是足够的。
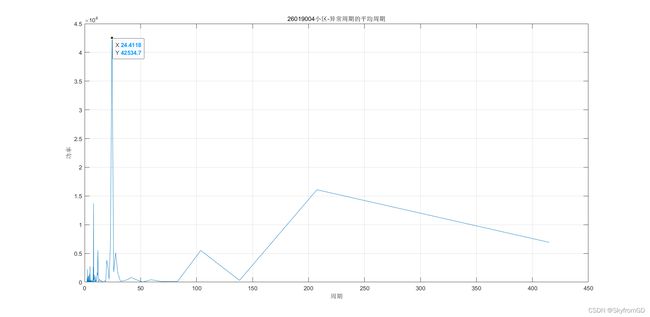

第一题就搞定了。
问题二:
这一题比较常规,主要是看你第一问是怎么做的,如果是单独一项KPI来看,有单独的预测做法,如果和我一样认为三项KPI之间有相关性的话,就可以这样做:
当然,这一道题的算法和模型我觉得取决于你第一问检测出的异常点的分布和异常周期的数量、跨度和分布。
总的来说,我不同情况下的预测模型如下:
1.针对单KPI检测出单异常孤立点的,使用时间序列中的ARIMA模型进行预测。(数模人狂喜)
2.针对多KPI检测出单异常孤立点的,使用时间序列中的ARIMAX模型进行预测。(这个涉及到KPI的相关性,需要根据第一问的求解结果而定)
3.针对单KPI检测出多异常孤立点的时间序列的BP神经网络模型进行预测。(这个的话如果异常孤立点检测出的数量较少,推荐以剩下的指标辅助建模达到很好的预测结果。这里我使用的是较为常见的双层BP神经网络)
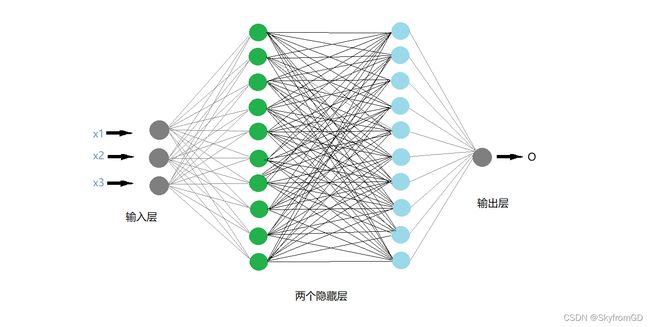
问题三:
这个问题就更简单了,完全就是第二问的扩展,可根据第二问的思路来做,使用R语言编写预测算法提交表格就行。
反思:
此次比赛我觉得最大的不足就是特征选择建模上没有一个更好地量化方法去选择特征,导致BP神经网络模型的分类效果欠佳,对第三问的思考还是不够深入。