DSRL:简单好用的框架——提高网络精度的同时不引入额外的计算量
作者 | Z 编辑 | 3D视觉开发者社区
导读
深度学习网络模型的性能和网络的大小有着密切的关系,大型网络在性能上一般比小型网络模型更好,显而易见,大型网络推理运行时消耗的算力要求比较高,而算力代表“金钱”!本文提出DSRL框架,引入了超分辨率作为辅助支路,来帮助网络保持高分辨率特征信息,并且在推理阶段将其从网络中删除,从而降低了算力(金钱)的消耗。

论文:
https://openaccess.thecvf.com/content_CVPR_2020/papers/Wang_Dual_Super-Resolution_Learning_for_Semantic_Segmentation_CVPR_2020_paper.pdf
语义分割是场景理解的一项基本任务,它在自动驾驶,机器人感应等领域中具有多种潜在应用。对于大多数此类应用,保持高效的推理速度和出色的性能 是一个挑战。
目前语义分割通常用高分辨率的输入去提高模型性能,这种方法使得计算量增加很多。我们提出了灵活而简单的双支路网络框架(DSRL) ,可以有效提高网络精度的同时不引入额外的计算量。具体的来说,我们的方法分为三部分:
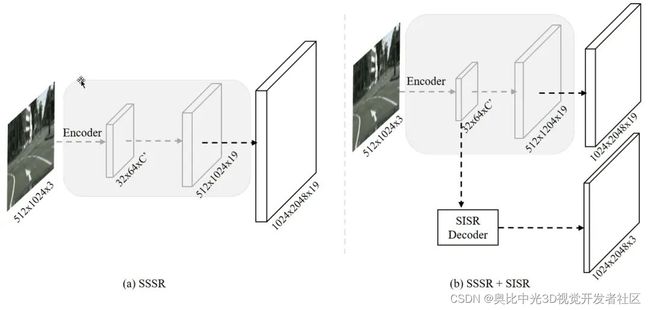
- 1.超分辨率分割(SSSR)
- 2.单张图像超分辨率(SISR)
- 3.特征关联(FA)模块
可以在低分辨率的输入的情况下保持高分辨率,同时减少计算量。这种方法还可以很简单的应用到其他任务上如人体姿态估计。我们的方法在人体姿态估计与Cityscaps 的分割任务上提高了2%的精确度的同时保持Flops不变 。
双支路网络框架(Dual Super-Resolution Learning)
DSRL框架的整体结构,如图[1]所示。
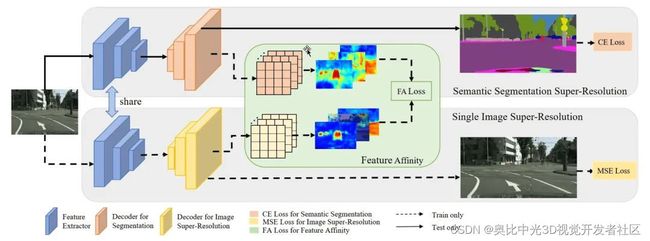
图[2]概述了提出的DSRL框架,包括三个部分:语义分割超分辨率(SSSR)分支,单幅图像超分辨率(SISR)分支和特征关联(FA)模块。编码器在SSSR分支之间共享和SISR分支 。该体系结构将通过三个方面进行优化:SISR分支的MSE损失、FA损失和特定于任务的损失 ,例如,语义分割的交叉熵损失。
SISR可以在低分辨率输入下有效地重建图像的结构细节信息,这对于语义分割十分有帮助。为了更好地理解,我们将图[2]中的SSSR和SISR的特征可视化。通过比较图[3]中的(b)和(c),我们可以轻松地发现SISR包含对象的更完整结构。尽管这些结构没有明确暗示类别,但是可以通过像素与像素或区域与区域之间的关系有效地对它们进行分组。众所周知,这些关系可以隐式传递语义信息,从而有利于语义分割的任务。因此,我们应用从SISR中恢复的高分辨率特征信息 来辅助网络学习,并且这些细节可以通过内部像素之间的相关性或关系来建模。
注:(a) 语义分割超分辨率(SSSR)分支; (b) 扩展(a)与单个图像的超分辨率(SISR)分“编码器”表示共享特征提取器。

分辨率与性能
最近,紧凑的分割网络已经出现由于其在资源受限设备中的应用优势,也引起了广泛关注。然而,它们的性能远远不如最先进的方法。为了缩小精度差距,这些方法通常是结合高分辨率输入(例如1024×2048或512×1024),这也带来了显著的计算代价。一旦限制了输入大小,不管什么规模网络,它们的性能会下降,图[4]显示了两个具有代表性的分段网络的性能:ESPNetv2[24]和DeepLabv3+[4],具有不同的输入分辨率。我们可以观察到当输入分辨率从512×1024降低时到256×512,两种网络的精度都降低了超过10%。
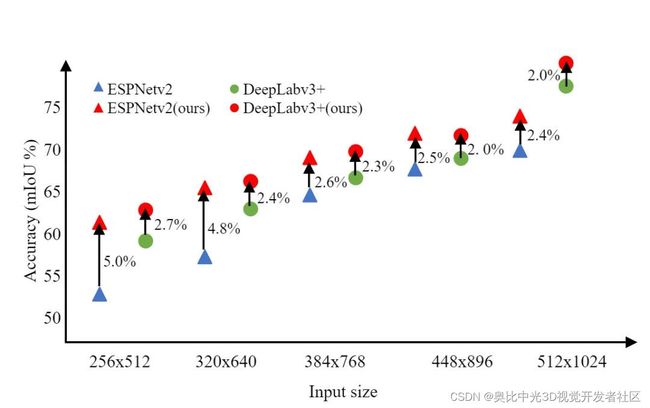
注:绿点表示不同输入大小(256×512, 320×640, 384×768, 448×896, 512×1024和1024×2048)的DeepLabv3+的结果。蓝色三角形标记ESPNetv2的结果。红色代表我们的方法基于DeepLabv3+和ESPNetv2。
实验对比
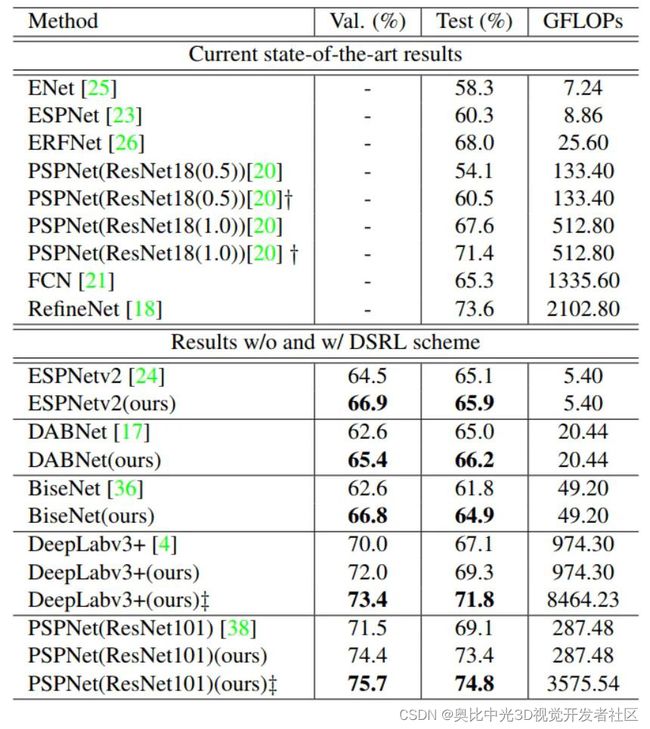
为了进一步验证我们方法的有效性,我们将双重超分辨率学习方法应用于其他一些架构 ,例如,以ResNet101为背景的PSPNet,以及为实时应用而设计的几个紧凑型网络,例如, 基于ResNet的DABNet和BiseNet18。 可以看到,我们的方法可以改善不同复杂性网络上的结果:ESPNetv2,BiseNet,DABNet,PSPNet和DeepLabv3 +。对于使用解码器(例如PSPNet)的网络,测试集的改进幅度为4.3%,而baseline为69.3%。与蒸馏方法相比,我们提供了另一条有效的支路,以在相同的FLOPs下获得更高的性能。
为了更好地理解DSRL,我们可视化baseline ESPNetv2和DSRL之间的最终分割特征。如下图所示,我们的方法能显著增强边界的锐度和清晰度,提高不同类别的完整性,例如道路,汽车等,从而增强了模型对车的最终辨别能力。
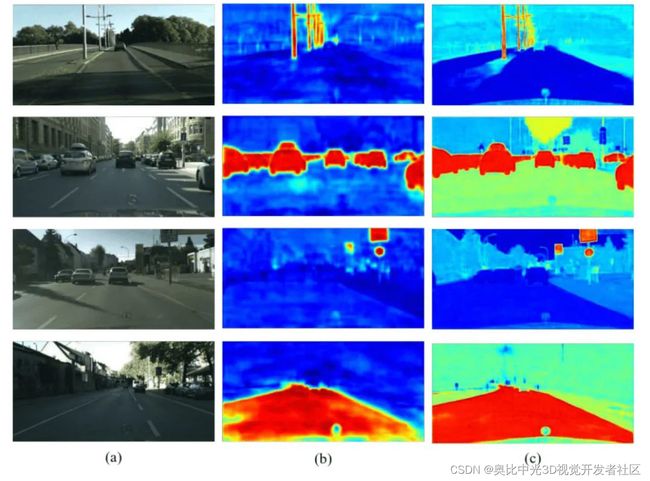
图[6]显示了每个类别的IoU。可以看到,我们的DSRL方案显著地提高了性能,带来性能明显提升的是那些小目标,例如pole和rider。
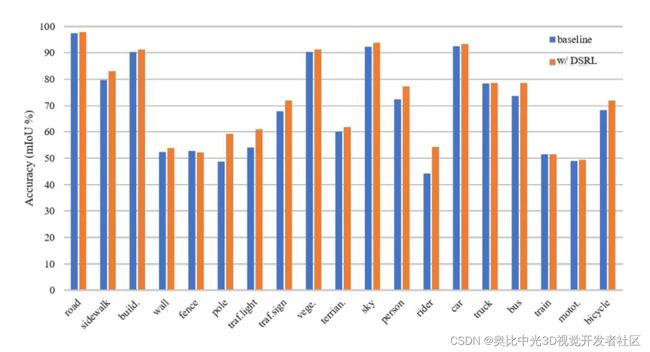
CityScapes验证集下DeepLabv3+网络上的各类IoU分数,我们的DSRL方案显著地提高了性能,带来性能明显提升的是那些小目标,例如pole和traffic light。
另外在人体姿态估计的试验中,不同的分辨率作为输入,我们的方法比HRNet高出1.2%到3.3%,反映出了良好的高分辨的输出对于该任务也是有提升的。反映出了良好的高分辨的输出对于该任务也是有提升的。

总结
本文基于现有语义分割算法,引入了超分辨率恢复的任务,构成DSRL框架 ,DSRL含有SISR和SSSR双个支路,它们共享相同的特征提取器,在训练过程中SISR支路对SSSR支路的特征的进行了优化,然后在推理阶段将SISR支路从网络中删除,实现了更加轻量的推理结构,因此,DSRL框架在算力有限的设备上的有一定的研究意义,并且降低了大规模部署推理服务时的成本。同时,DSRL框架很容易扩展到其他任务,并且通过多个的网络证明了我们的方法对性能提升的有效性,通用性。
版权声明:本文为奥比中光3D视觉开发者社区特约作者授权原创发布,未经授权不得转载,本文仅做学术分享,版权归原作者所有,若涉及侵权内容请联系删文。
3D视觉开发者社区是由奥比中光给所有开发者打造的分享与交流平台,旨在将3D视觉技术开放给开发者。平台为开发者提供3D视觉领域免费课程、奥比中光独家资源与专业技术支持。点击加入[3D视觉开发者社区],和开发者们一起讨论分享吧~
或可微信关注官方公众号 3D视觉开发者社区,获取更多干货知识哦。