5.1 Python图像处理之图像编码-哈夫曼编码
5.1 Python图像处理之图像编码-哈夫曼编码
文章目录
- 5.1 Python图像处理之图像编码-哈夫曼编码
-
- 1 算法原理
- 2 代码
- 3 效果
1 算法原理
哈夫曼编码是一种根据词频变化的变长二进制编码方式,多用于压缩算法。将信源符号按出现概率从大到小排列,然后选2个最小的结合,依次类推,直到剩下2个符号为止。使用哈夫曼编码,结果不唯一,平均码长相同,接近信源熵,方法容易简单。但是对于接近等概率分布的信源编码效率低。
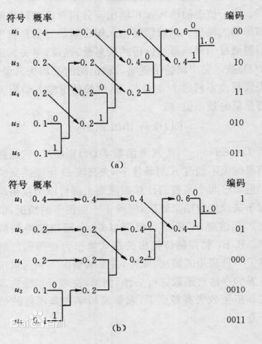
设某信源产生有五种符号u1、u2、u3、u4和u5,对应概率P1=0.4,P2=0.1,P3=P4=0.2,P5=0.1。首先,将符号按照概率由大到小排队,如图所示。编码时,从最小概率的两个符号开始,可选其中一个支路为0,另一支路为1。这里,我们选上支路为0,下支路为1。再将已编码的两支路的概率合并,并重新排队。多次重复使用上述方法直至合并概率归一时为止。从图(a)和(b)可以看出,两者虽平均码长相等,但同一符号可以有不同的码长,即编码方法并不唯一,其原因是两支路概率合并后重新排队时,可能出现几个支路概率相等,造成排队方法不唯一。一般,若将新合并后的支路排到等概率的最上支路,将有利于缩短码长方差,且编出的码更接近于等长码。这里图(a)的编码比(b)好。
2 代码
运行代码说明
1.要改变代码中的图片地址(地址不能有中文)
更改
put(path)函数中的路径put(r'../image/image1.jpg')2.注意最后的
plt.savefig('1.new.jpg')是保存plt图像,如果不使用可以注释掉注意本次代码实验是对图片进行压缩后再解压,显示解压前后的图片是否有变化。
import os
import cv2
from queue import PriorityQueue
import numpy as np
import math
import struct
import matplotlib.pyplot as plt
'''
对图像哈夫曼编码/解码
根据哈夫曼编码灰度图像,保存到文件中;读取哈夫曼编码的文件,解码成图像,与原图像对比。
'''
class HuffmanNode(object):
'''
哈夫曼树的节点类
'''
def __init__(self, value, key=None, symbol='', left_child=None, right_child=None):
'''
初始化哈夫曼树的节点
:param value: 节点的值,i.e. 元素出现的频率
:param key: 节点代表的元素,非叶子节点为None
:param symbol: 节点的哈夫曼编码,初始化必须为空字符串
:param left_child: 左子节点
:param right_child: 右子节点
'''
self.left_child = left_child
self.right_child = right_child
self.value = value
self.key = key
assert symbol == ''
self.symbol = symbol
def __eq__(self, other):
'''
用于比较两个HuffmanNode的大小,等于号,根据value的值比较
:param other:
:return:
'''
return self.value == other.value
def __gt__(self, other):
'''
用于比较两个HuffmanNode的大小,大于号,根据value的值比较
:param other:
:return:
'''
return self.value > other.value
def __lt__(self, other):
'''
用于比较两个HuffmanNode的大小,小于号,根据value的值比较
:param other:
:return:
'''
return self.value < other.value
def createTree(hist_dict: dict) -> HuffmanNode:
'''
构造哈夫曼树
可以写一个HuffmanTree的类
:param hist_dict: 图像的直方图,dict = {pixel_value: count}
:return: HuffmanNode, 哈夫曼树的根节点
'''
# 借助优先级队列实现直方图频率的排序,取出和插入元素很方便
q = PriorityQueue()
# 根据传入的像素值和频率字典构造哈夫曼节点并放入队列中
for k, v in hist_dict.items():
# 这里放入的都是之后哈夫曼树的叶子节点,key都是各自的元素
q.put(HuffmanNode(value=v, key=k))
# 判断条件,直到队列中只剩下一个根节点
while q.qsize() > 1:
# 取出两个最小的哈夫曼节点,队列中这两个节点就不在了
l_freq, r_freq = q.get(), q.get()
# 增加他们的父节点,父节点值为这两个哈夫曼节点的和,但是没有key值;左子节点是较小的,右子节点是较大的
node = HuffmanNode(value=l_freq.value + r_freq.value, left_child=l_freq, right_child=r_freq)
# 把构造的父节点放在队列中,继续排序和取放、构造其他的节点
q.put(node)
# 队列中只剩下根节点了,返回根节点
return q.get()
def walkTree_VLR(root_node: HuffmanNode, symbol=''):
'''
前序遍历一个哈夫曼树,同时得到每个元素(叶子节点)的编码,保存到全局的Huffman_encode_dict
:param root_node: 哈夫曼树的根节点
:param symbol: 用于对哈夫曼树上的节点进行编码,递归的时候用到,为'0'或'1'
:return: None
'''
# 为了不增加变量复制的成本,直接使用一个dict类型的全局变量保存每个元素对应的哈夫曼编码
global Huffman_encode_dict
# 判断节点是不是HuffmanNode,因为叶子节点的子节点是None
if isinstance(root_node, HuffmanNode):
# 编码操作,改变每个子树的根节点的哈夫曼编码,根据遍历过程是逐渐增加编码长度到完整的
root_node.symbol += symbol
# 判断是否走到了叶子节点,叶子节点的key!=None
if root_node.key != None:
# 记录叶子节点的编码到全局的dict中
Huffman_encode_dict[root_node.key] = root_node.symbol
# 访问左子树,左子树在此根节点基础上赋值'0'
walkTree_VLR(root_node.left_child, symbol=root_node.symbol + '0')
# 访问右子树,右子树在此根节点基础上赋值'1'
walkTree_VLR(root_node.right_child, symbol=root_node.symbol + '1')
return
def encodeImage(src_img: np.ndarray, encode_dict: dict):
'''
用已知的编码字典对图像进行编码
:param src_img: 原始图像数据,必须是一个向量
:param encode_dict: 编码字典,dict={element:code}
:return: 图像编码后的字符串,字符串中只包含'0'和'1'
'''
img_encode = ""
assert len(src_img.shape) == 1, '`src_img` must be a vector'
for pixel in src_img:
img_encode += encode_dict[pixel]
return img_encode
def writeBinImage(img_encode: str, huffman_file: str):
'''
把编码后的二进制图像数据写入到文件中
:param img_encode: 图像编码字符串,只包含'0'和'1'
:param huffman_file: 要写入的图像编码数据文件的路径
:return:
'''
# 文件要以二进制打开
with open(huffman_file, 'wb') as f:
# 每8个bit组成一个byte
for i in range(0, len(img_encode), 8):
# 把这一个字节的数据根据二进制翻译为十进制的数字
img_encode_dec = int(img_encode[i:i + 8], 2)
# 把这一个字节的十进制数据打包为一个unsigned char,大端(可省略)
img_encode_bin = struct.pack('>B', img_encode_dec)
# 写入这一个字节数据
f.write(img_encode_bin)
def readBinImage(huffman_file: str, img_encode_len: int):
'''
从二进制的编码文件读取数据,得到原来的编码信息,为只包含'0'和'1'的字符串
:param huffman_file: 保存的编码文件
:param img_encode_len: 原始编码的长度,必须要给出,否则最后一个字节对不上
:return: str,只包含'0'和'1'的编码字符串
'''
code_bin_str = ""
with open(huffman_file, 'rb') as f:
# 从文件读取二进制数据
content = f.read()
# 从二进制数据解包到十进制数据,所有数据组成的是tuple
code_dec_tuple = struct.unpack('>' + 'B' * len(content), content)
for code_dec in code_dec_tuple:
# 通过bin把解压的十进制数据翻译为二进制的字符串,并填充为8位,否则会丢失高位的0
# 0 -> bin() -> '0b0' -> [2:] -> '0' -> zfill(8) -> '00000000'
code_bin_str += bin(code_dec)[2:].zfill(8)
# 由于原始的编码最后可能不足8位,保存到一个字节的时候会在高位自动填充0,读取的时候需要去掉填充的0,否则读取出的编码会比原来的编码长
# 计算读取的编码字符串与原始编码字符串长度的差,差出现在读取的编码字符串的最后一个字节,去掉高位的相应数量的0就可以
len_diff = len(code_bin_str) - img_encode_len
# 在读取的编码字符串最后8位去掉高位的多余的0
code_bin_str = code_bin_str[:-8] + code_bin_str[-(8 - len_diff):]
return code_bin_str
def decodeHuffman(img_encode: str, huffman_tree_root: HuffmanNode):
'''
根据哈夫曼树对编码数据进行解码
:param img_encode: 哈夫曼编码数据,只包含'0'和'1'的字符串
:param huffman_tree_root: 对应的哈夫曼树,根节点
:return: 原始图像数据展开的向量
'''
img_src_val_list = []
# 从根节点开始访问
root_node = huffman_tree_root
# 每次访问都要使用一位编码
for code in img_encode:
# 如果编码是'0',说明应该走到左子树
if code == '0':
root_node = root_node.left_child
# 如果编码是'1',说明应该走到右子树
elif code == '1':
root_node = root_node.right_child
# 只有叶子节点的key才不是None,判断当前走到的节点是不是叶子节点
if root_node.key != None:
# 如果是叶子节点,则记录这个节点的key,也就是哪个原始数据的元素
img_src_val_list.append(root_node.key)
# 访问到叶子节点之后,下一次应该从整个数的根节点开始访问了
root_node = huffman_tree_root
return np.asarray(img_src_val_list)
def decodeHuffmanByDict(img_encode: str, encode_dict: dict):
'''
另外一种解码策略是先遍历一遍哈夫曼树得到所有叶子节点编码对应的元素,可以保存在字典中,再对字符串的子串逐个与字典的键进行比对,就得到相应的元素是什么。
用C语言也可以这么做。
这里不再对哈夫曼树重新遍历了,因为之前已经遍历过,所以直接使用之前记录的编码字典就可以。
:param img_encode: 哈夫曼编码数据,只包含'0'和'1'的字符串
:param encode_dict: 编码字典dict={element:code}
:return: 原始图像数据展开的向量
'''
img_src_val_list = []
decode_dict = {}
# 构造一个key-value互换的字典,i.e. dict={code:element},后边方便使用
for k, v in encode_dict.items():
decode_dict[v] = k
# s用来记录当前字符串的访问位置,相当于一个指针
s = 0
# 只要没有访问到最后
while len(img_encode) > s + 1:
# 遍历字典中每一个键code
for k in decode_dict.keys():
# 如果当前的code字符串与编码字符串前k个字符相同,k表示code字符串的长度,那么就可以确定这k个编码对应的元素是什么
if k == img_encode[s:s + len(k)]:
img_src_val_list.append(decode_dict[k])
# 指针移动k个单位
s += len(k)
# 如果已经找到了相应的编码了,就可以找下一个了
break
return np.asarray(img_src_val_list)
def put(path):
# 即使原图像是灰度图,也需要加入GRAYSCALE标志
src_img = cv2.imread(path, cv2.IMREAD_GRAYSCALE)
# 记录原始图像的尺寸,后续还原图像要用到
src_img_w, src_img_h = src_img.shape[:2]
# 把图像展开成一个行向量
src_img_ravel = src_img.ravel()
# {pixel_value:count},保存原始图像每个像素对应出现的次数,也就是直方图
hist_dict = {}
# 得到原始图像的直方图,出现次数为0的元素(像素值)没有加入
for p in src_img_ravel:
if p not in hist_dict:
hist_dict[p] = 1
else:
hist_dict[p] += 1
# 构造哈夫曼树
huffman_root_node = createTree(hist_dict)
# 遍历哈夫曼树,并得到每个元素的编码,保存到Huffman_encode_dict,这是全局变量
walkTree_VLR(huffman_root_node)
global Huffman_encode_dict
print('哈夫曼编码字典:', Huffman_encode_dict)
# 根据编码字典编码原始图像得到二进制编码数据字符串
img_encode = encodeImage(src_img_ravel, Huffman_encode_dict)
# 把二进制编码数据字符串写入到文件中,后缀为bin
writeBinImage(img_encode, 'huffman_bin_img_file.bin')
# 读取编码的文件,得到二进制编码数据字符串
img_read_code = readBinImage('huffman_bin_img_file.bin', len(img_encode))
# 解码二进制编码数据字符串,得到原始图像展开的向量
# 这是根据哈夫曼树进行解码的方式
img_src_val_array = decodeHuffman(img_read_code, huffman_root_node)
# 这是根据编码字典进行解码的方式,更慢一些
# img_src_val_array = decodeHuffmanByDict(img_read_code, Huffman_encode_dict)
# 确保解码的数据与原始数据大小一致
assert len(img_src_val_array) == src_img_w * src_img_h
# 恢复原始二维图像
img_decode = np.reshape(img_src_val_array, [src_img_w, src_img_h])
# 计算平均编码长度和编码效率
total_code_len = 0
total_code_num = sum(hist_dict.values())
avg_code_len = 0
I_entropy = 0
for key in hist_dict.keys():
count = hist_dict[key]
code_len = len(Huffman_encode_dict[key])
prob = count / total_code_num
avg_code_len += prob * code_len
I_entropy += -(prob * math.log2(prob))
S_eff = I_entropy / avg_code_len
print("平均编码长度为:{:.3f}".format(avg_code_len))
print("编码效率为:{:.6f}".format(S_eff))
# 压缩率
ori_size = src_img_w*src_img_h*8/ (1024*8)
comp_size = len(img_encode)/(1024*8)
comp_rate = 1 - comp_size/ori_size
print('原图灰度图大小', ori_size, 'KB 压缩后大小', comp_size, 'KB 压缩率',comp_rate, '%')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.subplot(121), plt.imshow(src_img, plt.cm.gray), plt.title('原图灰度图像'), plt.axis('off')
plt.subplot(122), plt.imshow(img_decode, plt.cm.gray), plt.title('解压后'), plt.axis('off')
# plt.savefig('1.1new.jpg')
plt.show()
if __name__ == '__main__':
# 哈夫曼编码字典{pixel_value:code},在函数中作为全局变量用到了
Huffman_encode_dict = {}
# 图像处理函数,要传入路径
put(r'../image/image3.jpg')
3 效果


本文使用的压缩率是 1- 压缩后大小/压缩前大小
而且不是使用文件格式对比,而是比较图片像素占用的bit