独家 | 自动编码器是什么?教你如何使用自动编码器增强模糊图像

作者:PRATEEK JOSHI
翻译:程超
校对:冯羽
本文约2200字,建议阅读9分钟
本文首先介绍了基于神经网络的自动编码器,然后介绍如何使用自动编码器增强模糊图像。
标签:计算机视觉
概述
自动编码器是什么?自动编码器是如何工作的?本文将回答这些问题。
我们将通过一个案例——如何提高模糊图像的分辨率,来探讨自动编码器的概念。
简介
你还记得胶卷相机的时代吗?冲洗照片是一个神秘的过程,只有摄影师和专业人士才能够驾轻就熟。大多数人的印象中只有弥漫着昏暗红光的暗室。简而言之,冲洗照片是一个耗时的过程。
后来数码相机革命开始了,过往的时代一去不复返!我们甚至不想再打印照片了——大多数人的照片存储在智能手机、笔记本电脑或云上。

暗室
即使现在,我们也会遇到(点击鼠标的时候)模糊、像素化和模糊的图片。我对此深表愧疚,很多人都在努力呈现出完美的图片。这正是深度学习和自动编码器的用武之地。
下面将介绍什么是自动编码器,以及工作原理。然后,我们会给一个实际案例——基于Python中的自动编码器提高图像的分辨率。
必备条件:熟悉Keras,基于神经网络和卷积层的图像分类。如果你需要回顾这些概念,可以参考以下:
神经网络概论(免费课程)
https://courses.analyticsvidhya.com/courses/Introduction-to-Neural-Networks?utm_source=blog&utm_medium=what-is-autoencoder-enhance-image-resolution
建立你的第一个图像分类模型
https://www.analyticsvidhya.com/blog/2019/01/build-image-classification-model-10-minutes/?utm_source=blog&utm_medium=what-is-autoencoder-enhance-image-resolution
目录
一、什么是自动编码器
二、关于图像去噪自编码器
三、问题描述-使用自动编码器提高图像分辨率
四、使用Python实现自动编码器
一、什么是自动编码器
Pulkit Sharma在文章中给出了如下定义:
“自动编码器本质上是学习输入数据低维特征表示的神经网络结构。”
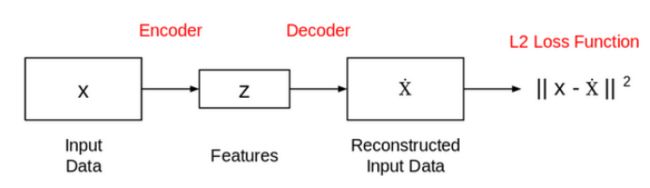
自动编码器由两个相连的网络组成:编码器和解码器。编码器的目的是获取一个输入(x)并产生一个特征映射(z):

这个特征映射(z)的大小或长度通常小于x。为什么是这样呢?
因为我们只希望z捕获可以描述输入数据的有意义的变化因子,因此z的形状通常小于x。
现在,问题是我们如何获得这个特征表示(z)?我们如何训练这个模型?为此,我们可以在提取的特征之上添加一个解码器网络,然后训练模型:
二、关于图像去噪自编码器
我们将在本文中解决的问题与图像去噪自动编码器的功能有关。下面我们详细介绍下如何利用自动编码器消除图像中的噪声。
假设我们有一组手写数字图像,其中一些已经损坏。 以下是一些带有噪点(损坏)的图像:

从图像中去除这种噪声被称为图像去噪问题。所需的输出是干净的图像,其中大部分噪声被去除,如下所示:

但是自动编码器如何从图像中去除这种噪声呢?
正如我们在上一节中已经看到的,自动编码器试图重建输入数据。因此,如果我们把损坏的图像作为输入,自动编码器将尝试重建噪声图像。
那么,我们该怎么办呢?改变结构?答案是否定的!
这里需要的是一个小调整。我们可以通过使用原始图像和重构图像来计算损耗,而不是使用输入和重构输出来计算损耗。下图说明了我的观点:
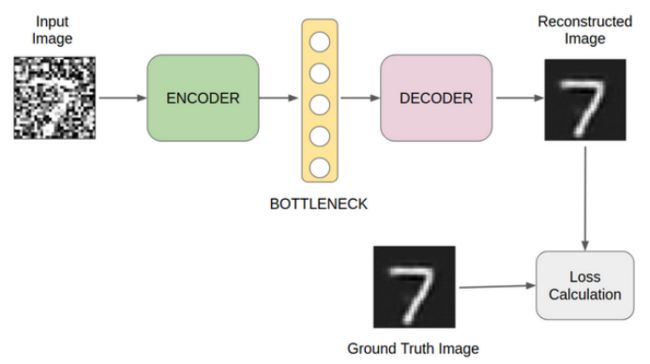
图像去噪自编码器
现在我们已经熟悉了去噪自动编码器的功能,下面我们回到期望使用自动编码器解决的问题。
三、问题描述-使用自动编码器提高图像分辨率
对这个问题相信你不会陌生。我们大多数人遇到模糊图像都很郁闷,都希望图片能清晰些。下面我们将使用自动编码器解决该问题!
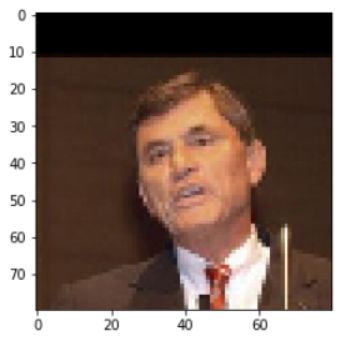
假设我们有一组低分辨率的人脸图像。我们的任务是提高这些图像的分辨率。可以借助Photoshop等照片编辑工具来完成此操作。但是,当手头有成千上万张图像时,我们需要一种更智能的方法来执行此任务。
以下是一些示例图像及其原始图像:

四、使用Python实现自动编码器
让我们打开我们的Juyter Notebook并导入所需的库:
下载数据集
我们的研究基于流行的“Labeled Faces in the Wild”数据集。它设计用于研究无约束人脸识别问题。然而,在这里我们的目标不是人脸识别,而是建立一个模型来提高图像分辨率。
让我们下载和提取数据集:
# download dataset
! wget http://vis-www.cs.umass.edu/lfw/lfw.tgz
# extract dataset
! tar -xvzf lfw.tgz
此数据集将被提取到多个文件夹中。因此,捕获所有图像的文件路径是很重要的。我们可以借助glob库轻松地做到这一点。
#capture paths to images
face_images = glob.glob('lfw/**/*.jpg')
加载和预处理图像
图像的原始大小是250×250像素。然而,在一般配置的系统上处理这些图像需要消耗相当多的计算资源。因此,我们需要裁剪所有图像的尺寸。
模型的训练数据准备
接下来,我们将数据集(图像)分成两组——训练和验证。我们将使用训练集来训练我们的模型,并用验证集来评估模型的性能:
让我们来看看数据集中的图像:
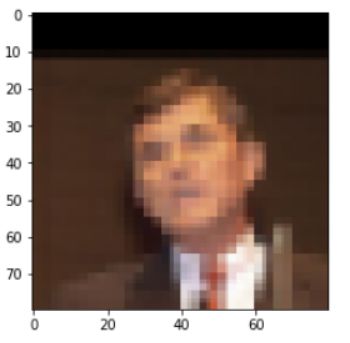
这个案例的思想和去噪自动编码器非常相似。
我们将对输入图像做一些修改,并使用原始图像计算损失。作为一个提高分辨率的任务,我们降低原始图像的分辨率,并将其输入到模型中。
如下是处理后的输入图片:
我们将使用下面的函数来降低所有图像的分辨率,并创建一组单独的低分辨率图像。
准备输入图像
降低所有图像的分辨率,包括训练集和验证集。
模型创建
模型的结构定义如下:
可以根据需要修改该结构。你可以改变层的数量,改变层的类型,使用正则化,以及其他很多参数。当下我们继续使用这个结构。
模型结构可视化对于调试(如果出现错误)很有帮助。在Keras中很容易实现,仅需执行
autoencoder.summary()
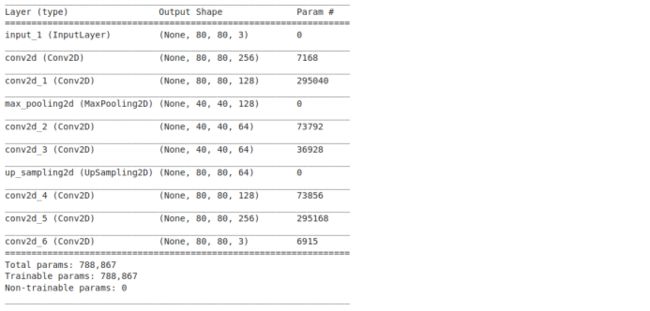
我们最终可以训练我们的模型:
预测(增强图像)
predictions = autoencoder.predict(val_x_px)

后记
本教程讲解了自动编码器,我们基于图像去噪的思路实现了提高图像分辨率。我们可以将其扩展到其他很多地方。
例如,我们也可以使用这种技术来提高低分辨率视频的质量。 因此,即使没有给图像打上标签,我们也可以处理图像数据并解决一些实际问题。如果您还有其他基于无监督学习的图像处理案例或技术,请在下面的评论部分中共享它。
原文标题:
What are Autoencoders? Learn How to Enhance a Blurred Image using an Autoencoder!
原文链接:
https://www.analyticsvidhya.com/blog/2020/02/what-is-autoencoder-enhance-image-resolution/
如您想与我们保持交流探讨、持续获得数据科学领域相关动态,包括大数据技术类、行业前沿应用、讲座论坛活动信息、各种活动福利等内容,敬请扫码加入数据派THU粉丝交流群,红数点恭候各位。

编辑:黄继彦
校对:林亦霖
译者简介

程超,中国建设银行大数据中心,东南大学硕士。工作涉猎较杂,从DSP开发,QT开发,再到数据挖掘、数据产品,以及目前的数据安全工作。对自己的定位是成为数据科学领域的全栈科学家。工作之余希望能多补充前沿的数据科学知识和理念,多和大家交流学习。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织