计算机视觉的自动编码器:无限可能的世界
介绍
大家好,在过去的几个月中,我致力于计算机视觉自动编码器 的开发,坦白地说,我对使用它们可以构建的大量应用程序印象深刻。
本文的目的是解释自动编码器,可以使用自动编码器构建的一些应用程序,未连接的编码器-解码器层的缺点以及诸如U-Net之类的体系结构如何帮助提高自动编码器的质量。
1. 什么是自动编码器?
简单来说,自动编码器是一种顺序神经网络,由两个组件组成,一个是编码器,另一个是**解码器。**供我们参考,假设我们正在处理图像,**编码器的工作是从图像中提取特征,从而减小图像的高度和宽度,但同时增加其深度,**即编码器对图像进行了潜在表示。现在,解码器的工作是解码潜在表示并形成满足我们给定标准的图像。从下面的图像中可以很容易理解。
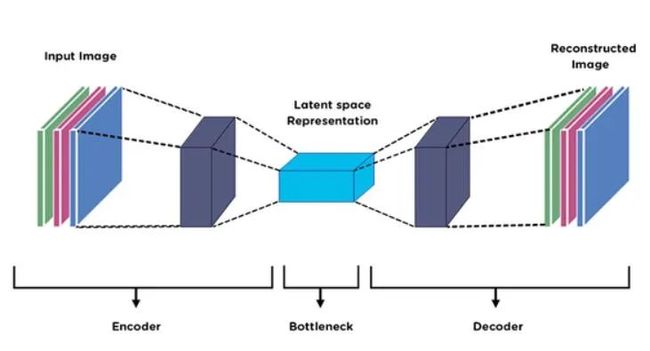
图1:自动编码器架构
自动编码器的输入和输出都是图像,在下面给出的示例中,自动编码器将输入转换为Monet样式的绘画。
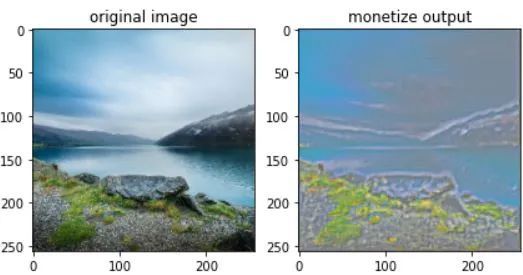
图2:自动编码器的输入和输出
2. 自动编码器,用于语义分割和未连接的编码器-解码器层的缺点
语义分割是指为图像的每个像素分配标签,从而将属于同一对象的像素分组在一起,以下图像将帮助你更好地理解这一点。
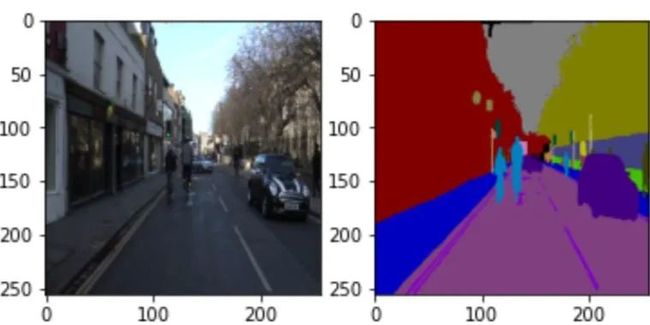
图3:图像及其语义分割输出
以下代码定义了用于此应用程序的自动编码器体系结构:
myTransformer = tf.keras.models.Sequential([
## defining encoder
tf.keras.layers.Input(shape= (256, 256, 3)),
tf.keras.layers.Conv2D(filters = 16, kernel_size = (3,3), activation = 'relu', padding = 'same'),
tf.keras.layers.MaxPool2D(pool_size = (2, 2)),
tf.keras.layers.Conv2D(filters = 32, kernel_size = (3,3), strides = (2,2), activation = 'relu',
padding = 'valid'),
tf.keras.layers.Conv2D(filters = 64, kernel_size = (3,3), strides = (2,2), activation = 'relu',
padding = 'same'),
tf.keras.layers.MaxPool2D(pool_size = (2, 2)),
tf.keras.layers.Conv2D(filters = 64, kernel_size = (3,3), activation = 'relu', padding = 'same'),
tf.keras.layers.Conv2D(filters = 128, kernel_size = (3,3), activation = 'relu', padding = 'same'),
tf.keras.layers.Conv2D(filters = 128, kernel_size = (3,3), activation = 'relu', padding = 'same'),
tf.keras.layers.Conv2D(filters = 256, kernel_size = (3,3), activation = 'relu', padding = 'same'),
tf.keras.layers.Conv2D(filters = 512, kernel_size = (3,3), activation = 'relu', padding = 'same'),
## defining decoder path
tf.keras.layers.UpSampling2D(size = (2,2)),
tf.keras.layers.Conv2D(filters = 256, kernel_size = (3,3), activation = 'relu', padding = 'same'),
tf.keras.layers.Conv2D(filters = 128, kernel_size = (3,3), activation = 'relu', padding = 'same'),
tf.keras.layers.Conv2D(filters = 128, kernel_size = (3,3), activation = 'relu', padding = 'same'),
tf.keras.layers.Conv2D(filters = 128, kernel_size = (3,3), activation = 'relu', padding = 'same'),
tf.keras.layers.UpSampling2D(size = (2,2)),
tf.keras.layers.Conv2D(filters = 64, kernel_size = (3,3), activation = 'relu', padding = 'same'),
tf.keras.layers.UpSampling2D(size = (2,2)),
tf.keras.layers.Conv2D(filters = 32, kernel_size = (3,3), activation = 'relu', padding = 'same'),
tf.keras.layers.UpSampling2D(size = (2,2)),
tf.keras.layers.Conv2D(filters = 16, kernel_size = (3,3), activation = 'relu', padding = 'same'),
tf.keras.layers.Conv2D(filters = 3, kernel_size = (3,3), activation = 'relu', padding = 'same'),
])
请参考本文的参考部分以获取完整的训练渠道。以下是你使用此网络可获得的结果
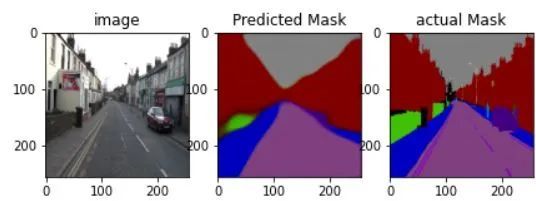
图4:用于语义分割的自动编码器结果
很好,看来我们的自动编码器可以很好地解决此问题,但是,你是否觉得所获得的结果有点模糊,可能出了什么问题?
2.1 自动编码器中未连接的编码器-解码器层的缺点
这种模糊性的原因在于**,**即使我们可以实现目标,但输出质量还不够好。因此,当信息从编码器传递到解码器时,功能映射就会丢失。因此,最合乎逻辑的方法是将解码器层与编码器层中的对应层连接起来,从而补偿重建图像时丢失的特征,这就是像U-Net这样的体系结构。从下图可以更好地理解这一点:
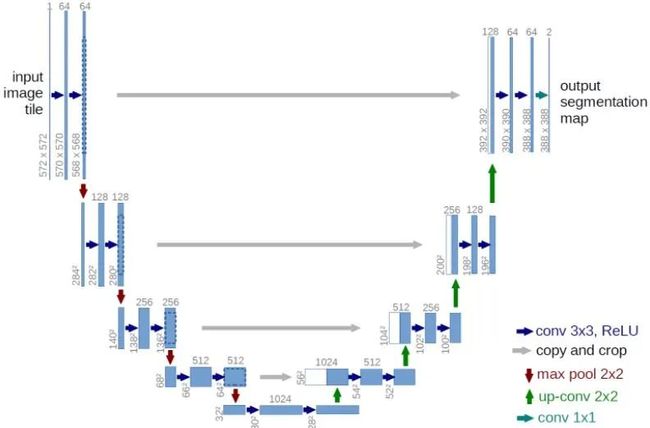
图5:Unet体系结构
看一下解码器和编码器层之间的互连,它们使像U-Net这样的体系结构优于原始自动编码器。
如此说来,让我们讨论一些可以使用UNet构建的实际应用程序。
3. 自动编码器的一些实际应用
3.1 通过预测相关掩码进行图像分割
这是你遇到的另一个分割问题,与上述示例不同。给定一幅图像,将要求你为图像中的目标物体预测一个二进制掩码,当你将此预测掩码与给定图像相乘时,你将获得目标图像。
此类预测模型可用于查找肾脏中癌细胞或结石的位置。因为一张图片的价值胜过千言万语,这里有一张图片可以说明我所说的:
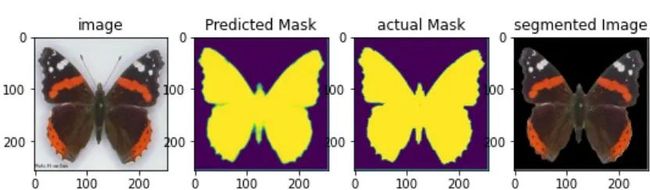
图6:实际的分割
这是定义所用模型架构的代码。
# defining Conv2d block for our u-net
# this block essentially performs 2 convolution
def Conv2dBlock(inputTensor, numFilters, kernelSize = 3, doBatchNorm = True):
#first Conv
x = tf.keras.layers.Conv2D(filters = numFilters, kernel_size = (kernelSize, kernelSize),
kernel_initializer = 'he_normal', padding = 'same') (inputTensor)
if doBatchNorm:
x = tf.keras.layers.BatchNormalization()(x)
x =tf.keras.layers.Activation('relu')(x)
#Second Conv
x = tf.keras.layers.Conv2D(filters = numFilters, kernel_size = (kernelSize, kernelSize),
kernel_initializer = 'he_normal', padding = 'same') (x)
if doBatchNorm:
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Activation('relu')(x)
return x
# Now defining Unet
def GiveMeUnet(inputImage, numFilters = 16, droupouts = 0.1, doBatchNorm = True):
# defining encoder Path
c1 = Conv2dBlock(inputImage, numFilters * 1, kernelSize = 3, doBatchNorm = doBatchNorm)
p1 = tf.keras.layers.MaxPooling2D((2,2))(c1)
p1 = tf.keras.layers.Dropout(droupouts)(p1)
c2 = Conv2dBlock(p1, numFilters * 2, kernelSize = 3, doBatchNorm = doBatchNorm)
p2 = tf.keras.layers.MaxPooling2D((2,2))(c2)
p2 = tf.keras.layers.Dropout(droupouts)(p2)
c3 = Conv2dBlock(p2, numFilters * 4, kernelSize = 3, doBatchNorm = doBatchNorm)
p3 = tf.keras.layers.MaxPooling2D((2,2))(c3)
p3 = tf.keras.layers.Dropout(droupouts)(p3)
c4 = Conv2dBlock(p3, numFilters * 8, kernelSize = 3, doBatchNorm = doBatchNorm)
p4 = tf.keras.layers.MaxPooling2D((2,2))(c4)
p4 = tf.keras.layers.Dropout(droupouts)(p4)
c5 = Conv2dBlock(p4, numFilters * 16, kernelSize = 3, doBatchNorm = doBatchNorm)
# defining decoder path
u6 = tf.keras.layers.Conv2DTranspose(numFilters*8, (3, 3), strides = (2, 2), padding = 'same')(c5)
u6 = tf.keras.layers.concatenate([u6, c4])
u6 = tf.keras.layers.Dropout(droupouts)(u6)
c6 = Conv2dBlock(u6, numFilters * 8, kernelSize = 3, doBatchNorm = doBatchNorm)
u7 = tf.keras.layers.Conv2DTranspose(numFilters*4, (3, 3), strides = (2, 2), padding = 'same')(c6)
u7 = tf.keras.layers.concatenate([u7, c3])
u7 = tf.keras.layers.Dropout(droupouts)(u7)
c7 = Conv2dBlock(u7, numFilters * 4, kernelSize = 3, doBatchNorm = doBatchNorm)
u8 = tf.keras.layers.Conv2DTranspose(numFilters*2, (3, 3), strides = (2, 2), padding = 'same')(c7)
u8 = tf.keras.layers.concatenate([u8, c2])
u8 = tf.keras.layers.Dropout(droupouts)(u8)
c8 = Conv2dBlock(u8, numFilters * 2, kernelSize = 3, doBatchNorm = doBatchNorm)
u9 = tf.keras.layers.Conv2DTranspose(numFilters*1, (3, 3), strides = (2, 2), padding = 'same')(c8)
u9 = tf.keras.layers.concatenate([u9, c1])
u9 = tf.keras.layers.Dropout(droupouts)(u9)
c9 = Conv2dBlock(u9, numFilters * 1, kernelSize = 3, doBatchNorm = doBatchNorm)
output = tf.keras.layers.Conv2D(1, (1, 1), activation = 'sigmoid')(c9)
model = tf.keras.Model(inputs = [inputImage], outputs = [output])
return model
请参考本文的参考部分以了解整个训练流程。
3.2 根据卫星图像预测路线图
你可以将上述架构应用于在卫星图像中查找道路,因为如果你想到这一点,那么这又是一个分割问题,使用适当的数据集就可以轻松实现此任务。与往常一样,这是一个显示此概念的图像。
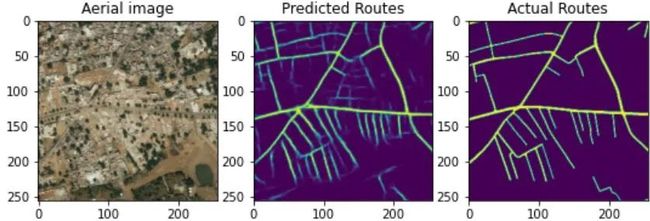
图7:根据航拍图像预测路线
与往常一样,你可以在“参考”部分中找到代码。
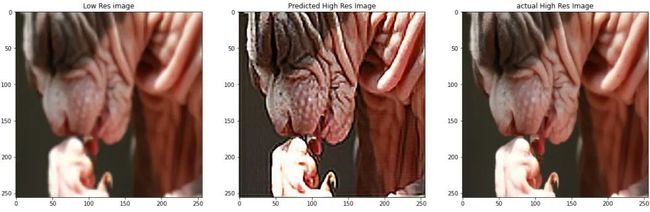
3.3 使用自动编码器实现超分辨率
你是否曾在放大低分辨率图像时注意到发生的像素失真?超分辨率本质上是指提高低分辨率图像的分辨率。现在,也可以仅通过对图像进行上采样并使用双线性插值法来填充新的像素值来实现此目的,但是由于你无法增加图像中的信息量,因此生成的图像将变得模糊。
为了解决这个问题,我们教了一个神经网络来预测高分辨率图像的像素值(**本质上是增加信息)。**你可以使用自动编码器来实现这一点(这就是本文标题为“无限可能的世界”的原因!)。
你只需在模型的输出层中将通道数更改为3(而不是1),就可以对上述体系结构进行一些小的更改。这里有几个结果:
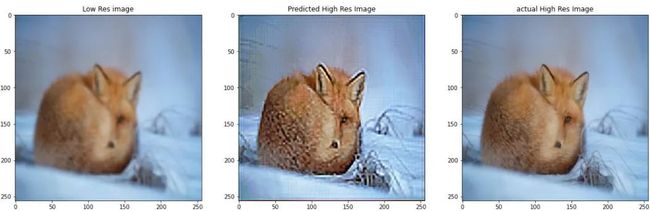

结论
这些只是我设法使用自动编码器构建的一些应用程序,但可能性是无限的,因此,我建议读者充分发挥自己的创造力,并找到更好的自动编码器用途。谢谢。
参考
1.) Vanilla AutoEncoder
https://www.kaggle.com/vanvalkenberg/image-segmentation-using-encoder-decoder-networks
2.) UNet Code and Binary Segmentation
https://www.kaggle.com/vanvalkenberg/coding-u-net-for-image-segmentation
3.) UNet for Road map generation from aerial Images.
https://www.kaggle.com/vanvalkenberg/road-maps-from-aerial-images
4.) Super Resolution
https://www.kaggle.com/vanvalkenberg/super-resolution-low-res-to-high-res-images
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 mthler」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
