Linux基础开发工具
提示:本文内容较长,请参考左侧目录阅读
Linux基础开发工具
- 1.软件包管理器yum
-
- 1.1 yum的基本操作
- 1.2 关于lrzsz
- 2.Linux编辑器vim
-
- 2.1 安装vimforcpp插件
- 2.2 修改vim配置
- 2.3 常见错误
- 2.4 三种模式的转换关系
- 2.5 正常模式指令
-
- 移动光标
- 删除文本
- 复制
- 替换
- 撤销
- 更改
- 跳转至指定行
- 多行注释/多行去注释
- 替换
- 2.6 末行模式指令
-
- 跳转
- 查找字符
- 保存文件
- 退出vim
- 3.Linux编译器gcc/g++
-
- 3.1 程序编译的四个阶段
-
- 预处理
- 编译
- 汇编
- 链接
- 3.2 函数库的概念
- 4.Linux调试器gdb
-
- 4.1 背景:C程序的两种发布方式
- 4.2 gdb调试
-
- 获取可执行程序
- 使用gdb指令开始进入调试状态
- gdb中的基本命令
- 4.3 核心转储文件:core dump
- 5.Linux项目自动化构建工具make/makefile
-
- 5.1 make与makefile的作用
- 5.2 工作原理
- 5.3 makefile细节:酌情补全的情况
- 5.4 makefile文件中的自定义变量和内置变量
-
- 内置变量:
- 自定义变量
- 5.5 伪目标与项目清理
-
- 伪目标
- 项目清理
- 6.git的使用
1.软件包管理器yum
yum(Yellow dog Updater,Modified)是Linux下常用的一种包管理器,我们可以把它理解成手机中的应用商店。
1.1 yum的基本操作
以下载安装lrzsz为例子,演示yum的三个基本功能
- 1.查看软件包
yum list | grep lrzsz
这个指令的含义是:通过管道把yum检索的结果传递给grep,过滤其中包含lrzsz的软件包。
- 2.安装软件
sudo yum install lrzsz
调用root权限安装lrzsz软件。
- 3.卸载软件
sudo yum remove lrzsz
调用root权限删除lrzsz软件。
1.2 关于lrzsz
lrzsz是一个用于文件的上传和下载的工具
- rz(zmodem file receive)接收到Linux端
- sz(zmodem file send)发送到windows机器
2.Linux编辑器vim
vim和vi都是多模式的编辑器,区别就是vim是vi的升级版,可以兼容vi的所有指令。
vim有三种常用模式:
普通模式,插入模式,末行模式。
2.1 安装vimforcpp插件
在使用vim前,可以安装一个vimforcpp插件,方便写C/C++代码。初学时不了安装和配置可以直接复制下面这段指令到命令行中:
curl -sLf https://gitee.com/HGtz2222/VimForCpp/raw/master/install.sh -o ./install.sh && bash ./install.sh
2.2 修改vim配置
通过修改"~/.vimrc"(家目录下的.vimrc文件)文件修改vim配置
![]()

下面的内容可以根据自己的代码风格选择是否修改:

如果代码风格是上图中的style不用更改,而如果代码风格是上图的style2则需要进行更改:

初学时对这些修改内容的含义可能不理解,可以先照搬,不用完全理解。
2.3 常见错误
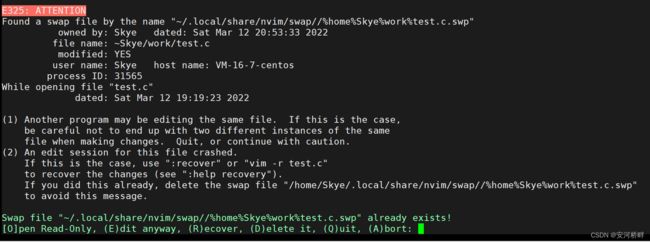
如果上一次编辑时异常退出了,就会产生这样的警告,这是因为异常退出导致.swp文件没有删除,当进入vim时遇到这样的警告,按"d"将.swp文件删除即可。
2.4 三种模式的转换关系

2.5 正常模式指令
七字真言
移、删、复、替、撤、更、跳,这是正常模式常用的七个类型的指令。
移动光标
- 小写英文字母,[h]、[j]、[k]、[l],分别控制光标的左、下、上、右移动一格。
- [gg] 移动到文本的开始
- [G] 移动到文本的最后
- [$] 移动到光标所在行行尾
- [^] 移动到光标所在行行首
- [w] 移动到下个字的开头
- [b] 移动到上个字的开头
- [Ctrl+b] back 屏幕往后移动一页
- [Ctrl+f] front 屏幕往前移动一页
- [Ctrl+u] up 光标往上移动半页
- [Ctrl+d] down 光标往下移动半页
删除文本
- [x] 删除光标所在位置字符
- [#x] 如6x,删除光标后面6个字符(包括光标所在位置)
- [X] 大写X, 删除光标所在位置“前面”的字符(不包括光标所在位置)
- [#X] 如8X,删除光标所在位置前面的8个字符
- [dd] 删除光标所在行
- [#dd] 从光标位置开始删除#行,进行多行删除时有一个技巧,如果要删除光标位置后面的所有行,可以键入一个很大的数字,如:10000dd。
✳这里的删除本质上都是剪切,可以通过p进行粘贴。
复制
- [yw] 复制光标所在位置到本行结束
- [#yw] 复制#个字(非字符)
- [yy] 复制光标所在行
- [#yy] 复制#行
- [p] 将缓冲区中的字符粘贴到光标所在下一行,对于yw和#yw来说是粘贴至本行
替换
- [R] 替换光标所在位置字符,直到按下Esc键
- [r] 替换光标所在处的单个字符
撤销
- [u] 撤销一次操作,可重复按下撤销多次操作,相当于Windows下的Ctrl+z
- [Ctrl +r] 撤销恢复,相当于Windows下的Ctrl+y
更改
- [cw] change world,改变光标所在字到字尾巴(即每次更改一个单词)
- [c#w] 更改#个字
跳转至指定行
- [Crtl+g] 展示光标所在行
- [#G] 跳转至指定行
除了这七种操作外,还有两种操作是比较常用的
多行注释/多行去注释
注释
1.正常模式下,将光标移动到要开始进行多行注释的行,按Ctrl+v进入多行注释模式

2.通过j和k上下移动光标选取行
被选中的行会变色。
3.shift+i进入插入模式

4.输入://

5.按Esc

多行注释完成。
去注释
1.第一步与多行注释相同,进入V-Block模式
2.移动光标选定要去注释的行,选完行后,再将光标向右移动,将注释符号//两个斜杠全部覆盖,如图:

3.按x,删除两个斜杆,完成去注释

替换
首先将光标移动至要进行替换的行,按":“进入底行模式,键入s/,后面跟要被替换的字符,再键入”/“,后面跟替换后的字符,最后面再跟一个”/"。
如图:
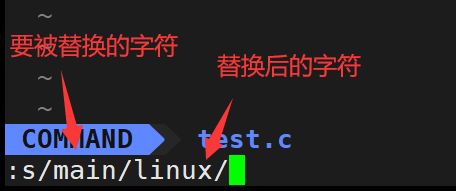
这个指令的含义是,将光标所在行的main替换成linux。
替换结果:

此外,还可可以在s前面加"%",表示全文,或"num1,num2"指定行,而在后面加"g"表示当前行所有。

这个语句的含义是,将全文所有的main替换成linux。
替换结果:

2.6 末行模式指令
进入末行模式之前,先按下Esc键返回正常模式,再按":"键进入末行模式。
跳转
- [num] 在冒号后面输入一个数字,按下回车键,光标便会跳到该行
查找字符
- [/关键字] 向后查找,先按"/"键,再输入要查找的字符,从光标所在位置向后查找关键字,按"n"会继续向后查找
- [?关键字] 向前查找,先按"?"键,再输入要查找的字符,从光标所在位置向前查找关键字,按"n"会继续向前查找
保存文件
- [w] 将编辑的内容保存
退出vim
- [q] 直接退出,后面可以跟[!]强制退出
- [wq]保存并退出,后面可以跟[!]强制退出
3.Linux编译器gcc/g++
Linux中使用gcc或者g++指令对C和C++程序进行编译。语法格式如下:
gcc [选项] 要编译的文件 [选项] 目标文件
3.1 程序编译的四个阶段
以test.c源文件的编译过程来演示程序编译的各个阶段

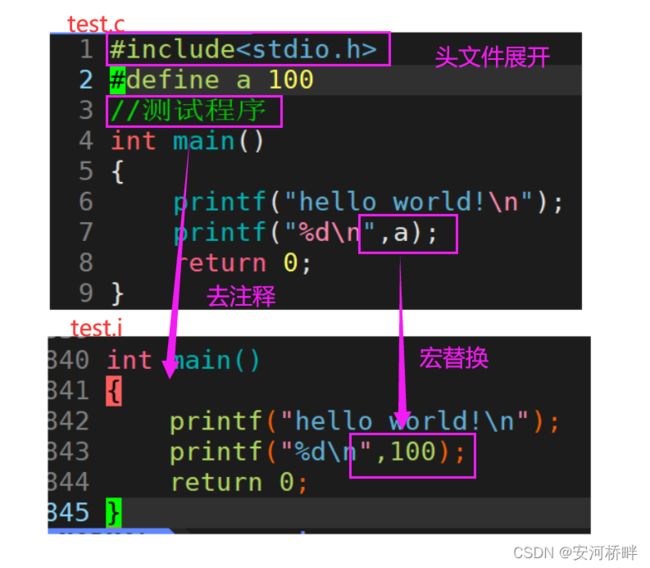
预处理
预处理阶段主要进行宏替换、头文件展开、去注释、条件编译等工作
指令:
gcc -E test.c -o test.i

预处理前后对比:
编译
编译阶段,gcc会检查代码的语法正确性,将代码翻译成汇编语言
指令:
gcc -s test.i -o test.s
含义与预处理阶段相似,这里的test.i文件也可以用test.c文件替代,即编译阶段可以直接编译未经处理的.c文件,也可以编译预处理阶段生成的.i文件

编译后生成汇编:

汇编
汇编阶段将汇编代码转换为二进制机器码
gcc -c test.s -o test.o
与前一阶段相同,这里的test.s文件也可以用test.i或者test.c

test.o就是生成的二进制目标代码:

二进制机器码用vim打开会看到上图所示的乱码。
链接
链接阶段会生成可执行文件或库文件,即将若干个二进制代码文件或库文件链接起来生成可执行程序
gcc test.o -o mytest
这里gcc后面没有可选项,直接跟二进制文件,生成可执行程序mytest

至此,程序编译的四个阶段完成,最终生成可执行程序。
总结C/C++程序编译的四个步骤:

3.2 函数库的概念
系统会把基本函数功能的实现都放到名为lib.so.6的库文件当中去,在使用到这些函数时,gcc会到系统默认的搜索路径"/usr/lib"下进行查找,即链接到lib.so.6库函数当中。
静态编译与动态编译:
- 静态编译 :在编译链接时,将库文件中的代码全部加入可执行文件中,这样生成的文件较大,但在运行时就不再需要库文件,后缀名一般为.a。
- 动态编译 :动态编译与静态编译相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序运行时由运行时链接文件加载库,节省内存开销。动态库后缀名一般为.so。
gcc编译时默认使用动态库,可以通过file指令查看文件属性,并通过ldd指令查看可执行程序连接的库文件,如图:

从上图可以看出gcc编译使用的动态链接,并看出链接的库文件。如果要进行静态编译,需要加上-static
4.Linux调试器gdb
4.1 背景:C程序的两种发布方式
- release模式 使用gcc/g++进行编译时,默认是release模式
- debug模式 若要使用gdb调试,须在源代码产生二进制程序的时候,加上"-g"选项
gdb进行调试时,必须使用debug版本,如果使用release版本,会有报错:

4.2 gdb调试
获取可执行程序
进行调试前,要先拥有一个可执行程序
test.c源文件:
#include
使用gdb指令开始进入调试状态
gdb mytest
输入指令后看到下面的结果说明已经进入调试状态:

gdb中的基本命令
源码显示
- [list] 也可用简写l,展示源代码, 每次10行
- [l 行号] 展示该行号为中心10行的代码
- [l 函数名] 列出一个函数的源代码
- [l -] 展示上面10行的源代码
运行程序
-
[r] 运行程序,停在断点处(有断点的行不执行)
r指令执行结果:

-
[n] 即next,逐过程,不进入调用的函数,相当于VS中的F10
-
[s] 即step,逐语句,进入函数调用,相当于VS中的F11
断点
-
[b 行号] 在某一行设置断点
-
[b 函数名] 在函数开头设置断点
-
[i b] 即info break,查看断点信息
断电信息:

-
[delete breakpointes] 删除所有断点
-
[delete breakpointes n] 删除序号为n的断点
-
[disable breakpointes] 禁用断点
-
[enable breakpointes] 启用断点
查看变量
- [p] 即print,打印变量值,可查看普通变量、指针、结构体、数组等
- [display 变量名] 追踪查看一个变量,每次停下来都会显示它的值
堆栈及函数调用
- [bt] breaktrace,查看各级函数调用及参数,即反应函数之间的调用关系
- [i locals] info locals 查看当前栈帧局部变量的值,即当前函数的帧栈内部
Tips
gdb调试时,若无指令输入时按回车,会执行上一次的指令,在进行逐步调试时可以用到,第一次键入n或者s即可,后面按回车键即可。
4.3 核心转储文件:core dump
核心转储文件core dump反应的是在程序运行崩溃的一瞬间的内存映像(相当于案发现场)
core file size,表示 核心转储文件的大小,当core file size的值为0时,表示不产生核心转储文件;core file size值为unlimited表示不限制核心转储文件大小,只要core dump大小小于磁盘空间,都会正常产生。
- ulimit -a 可以查看当前核心转储文件的限制大小
如图:

- ulimit -c [0~unlimited] 修改core file size大小

修改core file size大小为unlimited后,若程序崩溃,如产生指针越界访问等问题,便会产生coredump文件,如图:
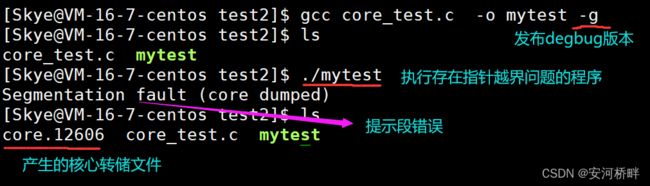
gdb coredump调试

根据core dump文件中提供的信息分析程序发生崩溃的原因。
5.Linux项目自动化构建工具make/makefile
5.1 make与makefile的作用
- makefile是文件,其内部定义编译程序的规则文件格式为:
目标对象:依赖对象
编译命令
注意第二行编译命令的前面有一个Tap键的空间(四个空格)。
- make是一个指令
5.2 工作原理
1.执行make指令时,它会自动查找当前目录中文件名为"makefile"或"Makefile"的文,并对其内容进行解析,编译程序,若未找则会报错。
2.make只为生成第一个目标对象而服务,如果为了生成第一个目标对象,需要先生成依赖对象,则会继续在makefile文件中查找生成依赖对象的方法,若发现依赖对象不存在,报错返回。
eg:
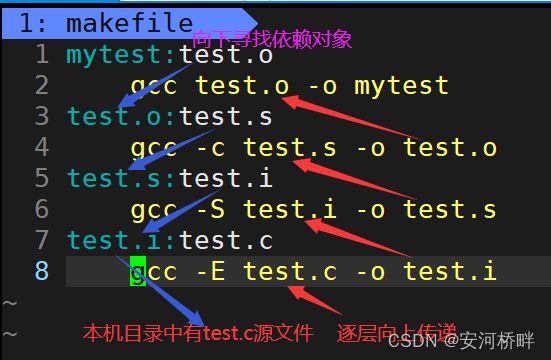
此时,执行make指令相当于执行了4个gcc指令,一次产生了"test.i"“test.s”“test.o"文件和可执行程序"mytest”。

5.3 makefile细节:酌情补全的情况
makefile中的依赖对象为test.o文件,原则上这时应该在当前目录中寻找test.o文件,如图:

当前目录中并没有test.o文件,但是仍然生成了可执行程序:

这是因为当前目录下有一个名为"test.c"的文件,make自动补全了一条指令,将"test.c"文件编译成了makefile中的依赖对象"test.o"文件,可以称为酌情补全,在编译程序时,不能依赖这种补全方式,要将"makefile"文件写完整。
5.4 makefile文件中的自定义变量和内置变量
内置变量:
- $^ 所有的依赖对象
- $@ 目标对象
- $< 第一个依赖对象
eg:

因为依赖对象可以由多个,所以这里可以由多个源文件生成一个可执行程序,这便是makefile的内部变量的意义。
自定义变量
- 自己取变量名,使用$进行解析
eg:

5.5 伪目标与项目清理
在执行make指令时,会碰到这种情况:

因为依赖对象的最后一次修改时间小于目标对象的修改时间,所以make指令不执行。(即当前可执行程序已经是最新的,不用再进行编译)
伪目标
.PHONY:[伪目标名称]
伪目标的特性:命令总是被执行,不关心最后一次修改时间
如图:

用.PHONY修饰了mytest,所以再次make时,gcc仍会执行,如图:

项目清理
根据伪目标的特性,可以进行项目清理,清除所有目标文件,以便重新编译:


这样便利用伪目标的特性实现了便捷的项目清理。
6.git的使用
-
git clone [地址]克隆仓库到本地,这里的地址指仓库的地址
-
git add [文件名 ] 添加文件到
-
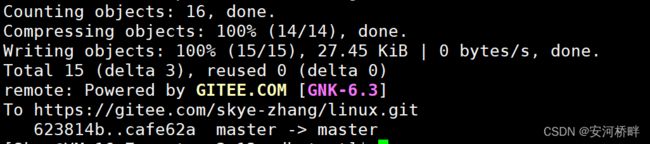
git commit [文件名] -m “备注信息” 提交改动到本地
如图:

-
git push origin master 同步到远端服务器,origin表示源,master是分支
如图表示远端同步成功:
-
git pull 远端仓库同步到本地