恶意攻击和可解释性
Network 在一般的情况下得到高的正确率是不够的,它要在有人试图想要欺骗它的情况下,也得到高的正确率,所以就要能够对恶意攻击采取一定的防御措施。本节将介绍恶意攻击的概念、方法和防御措施
恶意攻击的概念
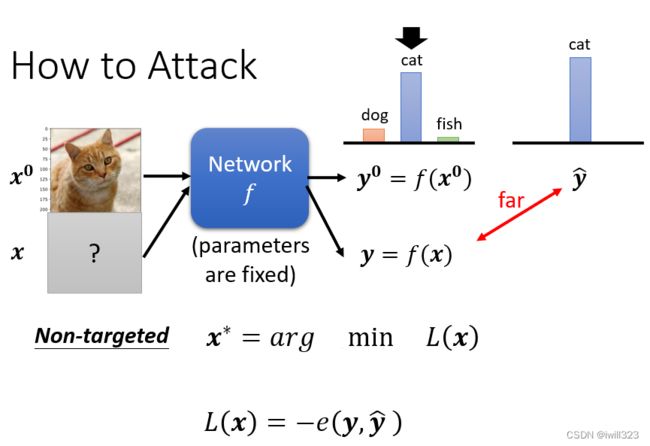
恶意攻击的概念是给正常输入加入特殊的杂讯,形成一个带有攻击性的输入,当其进入模型之后,输出的内容是错误的。根据输出内容的错误,恶意攻击分为non-targeted(无目标攻击)和targeted(目标攻击),前者是指输出只要不是正常的就行(输入猫,输出不是猫就行),而后者规定了错误的输出内容是什么(输入猫,输出海星)。有被加杂讯的照片叫做 Attacked Image,还没有被加杂讯的照片,一般就叫做Benign Image。一般加入的杂讯是很小的,人的肉眼是看不出来的,下图中的攻击图片是夸张了的

攻击前分类的信心分数(置信度)是 0.64,攻击后分类的信心分数是100 %,即反而可能上升

恶意者怎么进行攻击的?
Network是一个函数f,输入是一张图片,我们叫它x0,输出是一个 Distribution,分类的结果叫y0。被攻击的模型参数是固定的,攻击者是修改不了模型的,只能修改输入内容。
- 如果是 Non-Targeted Attack,要找到一张新的图片x, 经过Network输出是 y,正确的答案叫做 ŷ,希望 y 跟 ŷ 的差距越大越好。loss函数就是y和ŷ的负cross entropy,这一项越小越好,代表 y 跟 ŷ的 Cross Entropy 越大
- 如果是目标攻击。用ytarget代表目标,ŷ 其实是一个 One-Hot Vector,ytarget也是一个 One-Hot Vector,希望 y 不止跟 ŷ 越远越好,还要跟ytarget越近越好。
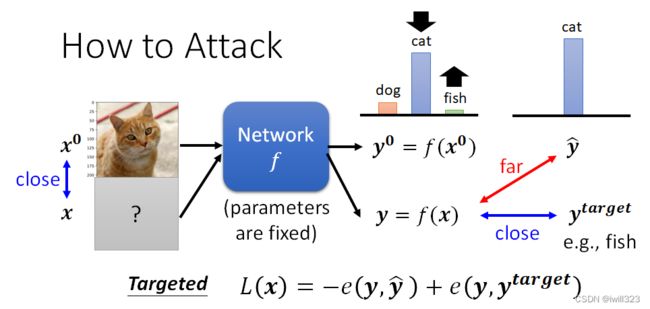
加入的杂讯越小越好,也就是新找到的图片跟原来的图片要越相近越好。所以我们在解这个Optimization 的 Problem 的时候,还会多加入一个限制
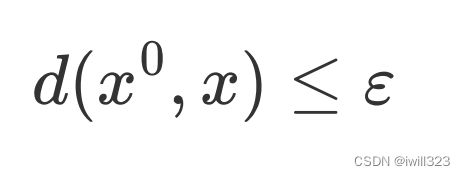
希望 x 跟x0之间的差距小於某一个 Threshold,这个閾值是人类可以感知的极限,如果x0 跟 x 之间的差距大於 Σ,人就会发现有一个杂讯存在。让x0 跟 x 它的差距小於等於 Σ,就可以產生一张图片,人类看起来 x 跟 x0是一模一样的,但產生的结果对 Network 来说是非常不一样的
d(x0, x) 的计算方法
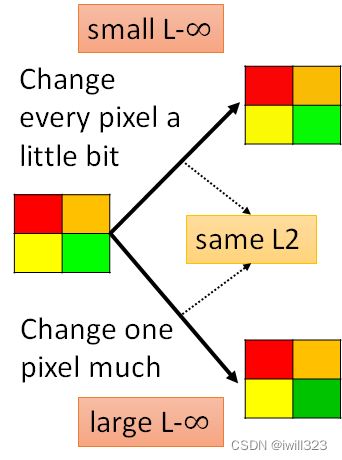
计算d(x0, x)有两个方法。第一种L2:将∆每一维的差值的平方相加,要开根号也是可以的;第二种L-∞:将∆中绝对值最大元素作为差异大小。∆是正常输入和恶意输入的差值(也就是杂讯)

第二种方法L∞更加符合人类的感知情况,所以攻击者一般会考虑采用L-infinity。为什么呢?以方块图来说明,右上角的正方形中四个方块都有微小变化,右下角的正方形中只有绿色方块发生变化。并且令两者对原正方形做差,有相同的L2值,但右下角L-∞更大,右上角L-∞比较小,因為 L-∞ 只在意最大的变化量。而从人肉眼观察来看,能明显看出右下角的变化,所以限制最大的差值(L-∞)也许能够更好地将恶意输入伪装成正常输入。
刚才举的例子是影像上的例子,如果要攻击的对象是一个跟语音相关的系统,那什麼样的声音讯号对人类来说听起来有差距,那就不见得是 L2 跟 L-Infinity 了,要研究人类的听觉系统,看看人类对什麼频态的变化特别敏感,根据人类的听觉系统来制定比较适合的 x 跟 x0之间距离的衡量方式,这个部分需要用到 Domain Knowledge
攻击方法的实现
和以前模型里面的函数不同,之前的是固定输入,调整参数来使loss最小,现在是固定模型参数,调整输入来使loss最小,还是用的梯度下降的方法:将正常的输入x当作初始化值,再迭代更新x,迭代过程是算出loss对输入x的偏微分g,乘上学习率后再更新x。
上图中是省略了d(x0, x)这个条件的,Update 完你的参数以后发现,你的 跟 的差距大於 ε 以后,你就做一个修改,把 做个修改,把它 改回符合限制就结束了
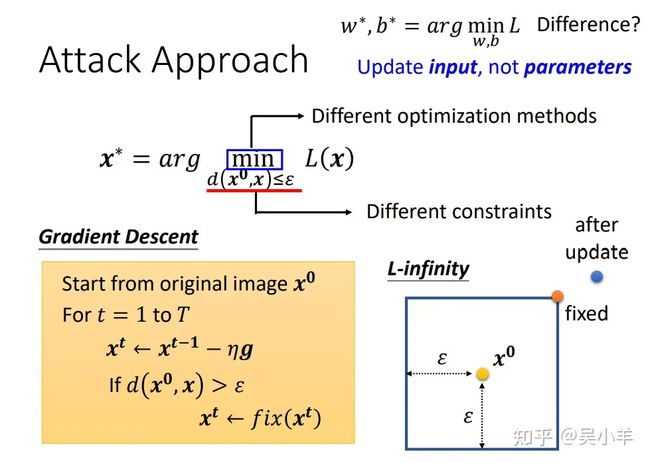
下面对这个条件的实现进行说明:这个式子可以用以x0为中心的正方形来表示(因为应用L-∞),x只能在正方形上或内。在更新完x之后,如果x在这个正方形外,那么就用正方形上最近的点来替代。
当然,这只是多数方法中的一个,攻击方法可以使用不一样的优化函数,不一样的限制条件,但是本质思想就是 ∗这样的。
攻击方法:FGSM
这个方法重点在于只要更新一次x,不需要迭代多次。
因为梯度g的输出只有1和-1两种可能,而学习率又是用差值表示,所以更新一次的x必定会在圆上!假如迭代要多重复几轮,那么x很大概率会跑出圆的范围,这时只要用圆上最近的点来代替即可。出去了就给拉回来。

7.1.3 black box attack(黑箱攻击)
知道模型参数的攻击叫做白箱攻击,不知道模型参数的攻击叫做黑箱攻击。黑箱攻击容易实现无目标攻击,但是很难实现目标攻击。
有被攻击网络的训练资料时:
我们使用这些训练资料,自己来训练一个proxy网络,将proxy网络当作被攻击对象,来生成带有攻击性的输入,再把这个训练出来的图片输入到正常网络中,就实现了攻击。本质思想就是将黑箱攻击转变成白箱攻击!!想象出一个网络来代替原网络。

没有被攻击网络的训练资料时:
没有训练资料的时候,用已知的相似的网络来代替。下面第一张图的对角线是属于白箱攻击,准确率都为0%(准确率越低,证明攻击越成功),非对角线属于黑箱攻击;第二张图的网络前面带上负号意思是proxy不用这个网络而用其余的四个网络来训练,所以对角线是黑箱攻击,非对角线是白箱攻击。

为什么攻击这么容易?
为什么在A网络上攻击成功了,恶意攻击用在B网络上也能成功呢?目前大多数人认同的说法:
因为多数模型被攻击的样子类似,被攻击成功的方向都是将图片在横轴上移动,在纵轴上移动图片不会被攻击成功。下图的深蓝色区域表示能正常识别小丑鱼的区域,当杂讯使输入上下移动时,一般不会产生破坏,而杂讯使输入左右移动时,这个网络就辨识不出小丑鱼了。
大多数学者认为,攻击成功的原因可能出现在训练资料上,而不是模型上。

7.1.4 其他攻击方法
one pixel attack:只要改动图片的一个像素点,就能使得辨识系统出错。
universal adversarial attack:通用恶意攻击,某一个杂讯恶意性强大,将其加入到很多照片中,都能使辨识系统出错。
攻击对象不仅是图片,还能是其他的东西,例如侦测合成语音等等.......
在物理世界的攻击
以人脸辨识系统为例,攻击该系统需要考虑的因素:
1、考虑三维的各个角度都要能使辨识系统出错。
2、考虑摄像头的解析度极限,如果加入的杂讯太小以至于摄像头解析不出来,那么这个杂讯就等于是白加了。
3、考虑电脑和现实中的色差,如果训练出来的眼镜有现实中印不出来的颜色,那么这副眼镜还是起不到攻击作用。

训练阶段发起攻击
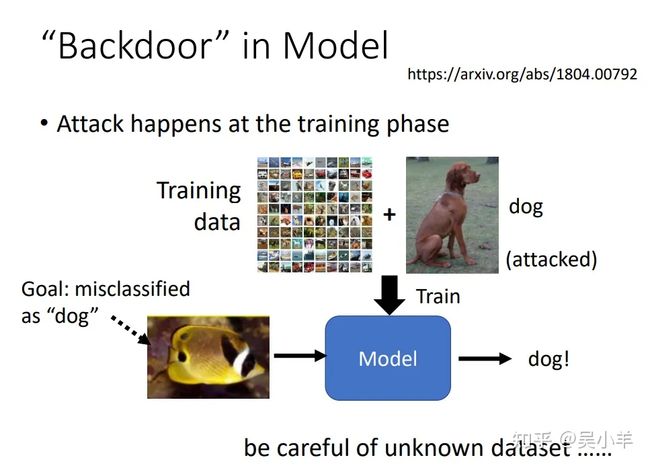
前面的攻击对象都是已经训练好的模型,这个介绍的是模型在训练过程中就被攻击了。这个就是对训练资料做手脚了(之前的是对输入做手脚),这个狗看起来没有问题,但是实际上是有问题的。而且这种方式的攻击只对某一特征有问题,而其他东西的分类都是正常的,所以训练结果一般看起来也正常,很难察觉自己被攻击了。所以不要随便用来路不明的训练资料!!!
7.1.5 防御措施
Passive defence(被动防御)
被动防御是不去改动模型的,通过处理输入内容实现防御。因为攻击讯号都很特殊且小,不是什么noise都能攻击的,所以稍微处理下输入就能降低攻击的威力。被动防御的副作用就是使分类分数降低。
第一种方法:图片模糊化

第二种方法:图片压缩(会造成失真)
第三种方法:用generator重新生成输入图片

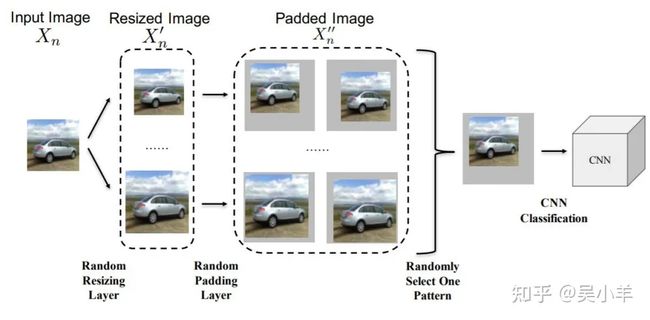
第四种方法:加入随机化
随机放大缩小图片,随机贴图......
Proactive defence(主动防御)
主动防御的思想就是训练出一个见多识广的模型,见识过各种各样的攻击。
给一堆训练资料,然后通过攻击算法故意弄坏输入,再将弄坏的输入与正确输出对应上,最后用正常的输入和弄坏的输入一起去训练模型!!这个方法其实类似于data augmentation(资料增强)
主动防御的缺点:不能挡住新算法的攻击;需求的资料多,对计算能力要求高。

7.2 explainable machine learning(机器学习的可解释性)
7.2.1 为什么需要机器学习的可解释性?
1、我们需要知道机器做决策的背后理由,否则谁敢真正应用于实际,例如医学诊断、法庭判决、自动驾驶非正常紧急刹车等等,都直接作用于人类,搞清楚能决策成功的原因很重要。
2、我们可以通过这个解释性来提升模型的性能。
可解释性 VS 强劲力
有一些模型在本质上是可以解释的,例如线性模型(从权重能知道特征的占比重要性),但是效果却并不厉害。深度神经网络很难解释其操作机制,因为它是黑箱,但是他却比线性模型的效果更好。
那么我们应该选择用什么模型呢?当然是深度神经网络。因为线性模型作用的效果存在局限性,在很多问题上并不适用。而神经网络效果好,只是机制还不具备可解释性,所以我们应该努力去研究其机制的可解释性,而不是逃避黑箱模型!

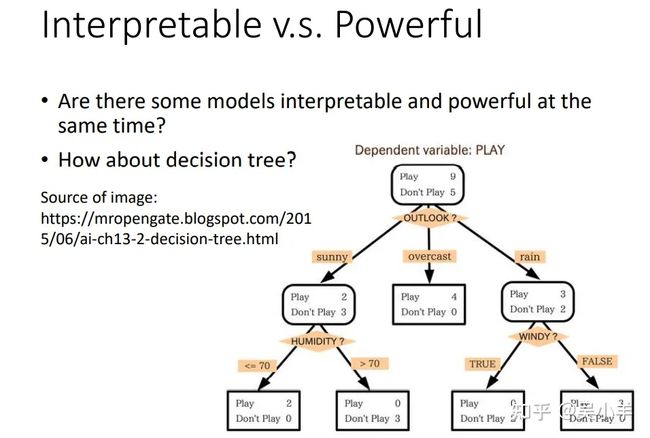
那有没有一种模型同时具有可解释性和强劲力呢?决策树,一棵树能同时具备上述两个要素,但是在实际训练中,我们往往会用到很多棵树,这种情况也很难解释其机制。
做机器学习的可解释性,做到什么程度?我们不需要完全知道网络是怎么运行的,只要做出来的解释性是能够让人所认同就行!!

7.2.2 explainable ML的分类
分为局部可解释性和全局可解释性,局部可解释性是针对一个特定的输入,为什么这张图片就是一只猫呢。全局可解释性是针对模型而言,不涉及某一具体的图片,模型会认为猫长什么样子呢,怎么样判断出一张图片是猫呢?

7.2.3 Local Explanation(局部可解释性)
哪个元件最重要?
判断component对做出决策的影响力,方法一般是删除或者修改某一component,如果网络的输出发生了巨大的改变,影响最后决策结果,那么这个元件就是很重要的。

用数学化语言描述上面方法:
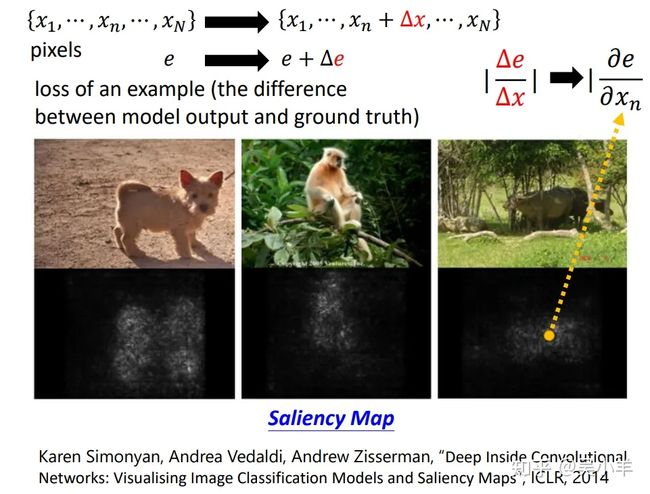
有N个输入元件x(如果是输入图片的话就是N个像素),只对其中的某一个 x 做出 Δx 的改变,其余的 x 保持不变;然后计算cross entropy的变化值 Δe ,再计算 Δe/Δx 的值,值越大,证明该 x 对决策越重要。
注意点:e 越大,判断结果和正确图片的差距越大,即辨识结果越差。saliency map(显著图)中的白点越白,代表 e/ x 的值越大,代表该处的像素点 x 对决策越重要。
上面方法的局限性:noisy gradient(杂讯梯度)
会存在杂讯梯度的问题,在未经处理的显著图中,白点分布杂乱无章看不出规律,通过smoothGrad方法后才减少了杂讯,使显著图有规律可循。
smoothGrad:给输入的图片随机加入杂讯,制造出很多带有杂讯的输入图,然后将这些输入图得到的显著图作平均,这样就知道哪些像素点才是真正的决策因素了。

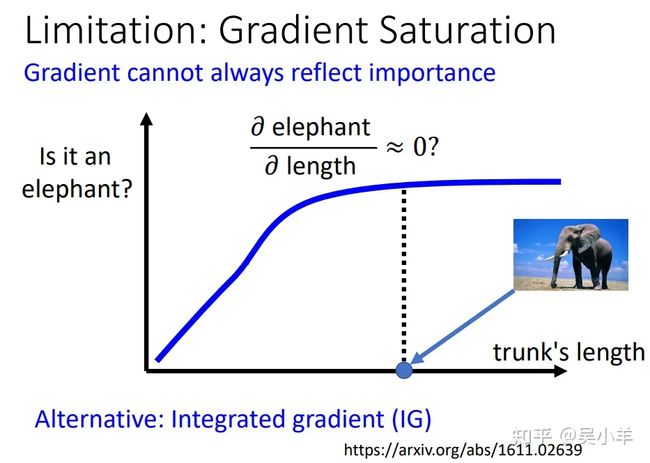
上面方法的局限性:gradient saturation(梯度饱和)
光看偏微分gradient不一定能看出component的重要性,例如在下图中的点处,鼻子很长,但是鼻子长度的变化对判断大象几乎没有影响了,也就是此时偏微分为零,我们就要因此认为鼻子处的像素点对决策不重要吗?所以不仅要考虑偏微分,还要考虑其余因素,具体参考下面论文。
网络如何处理输入数据
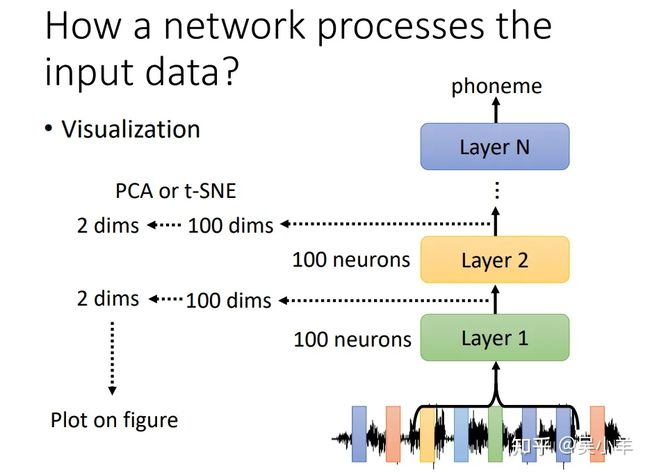
既然是找寻网络的可解释性,那么就要知道网络的隐藏层到底发生了什么,要知道每经过一层网络之后的结果是个什么东西。
visualization(可视化)
我们将隐藏层的输出抽出来,并将其维度降低,例如将100维的输出向量转成2维的向量,然后用2维向量生成图片或者图表。
第一张图是直接用输入内容做出的图表,杂乱无章;第二张图是用中间隐藏层的输出做出的图表,有规律可循,每一条纹代表同样内容的句子,不同颜色代表不同的语者。

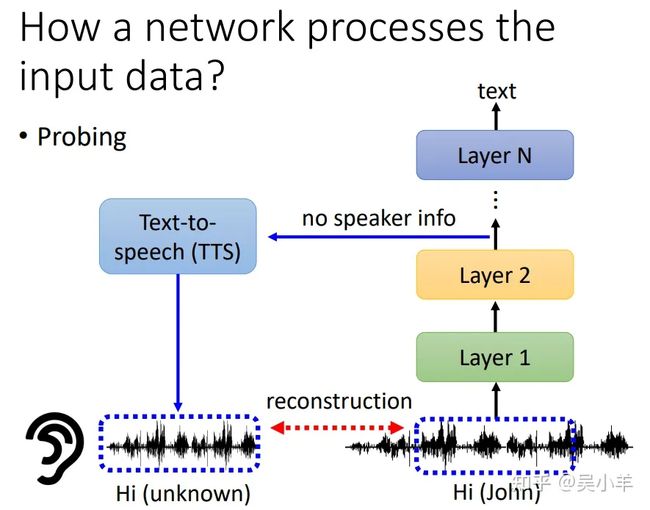
probing(探针)
我们直接训练多个分类器,将隐藏层的输出放到分类器中(例如词性分类、地理人名分类),从而就知道每一层是在分离什么资讯。假如第一层输出在词性分类的准确率高,那么证明第一层主要用于处理词性了。但是这个方法的结论不一定适用,因为可能我们的分类器性能本身就低........

还可以将文字转语音用于模型可解释性,输入一段语音,从隐藏层中抽取输出,假如这段输出合成的语音不包含语者资讯(机器人声音),那么就证明在训练过程中抹去了语者资讯,只保留语音内容。
7.2.4 global explanation(全局可解释性)
filter是怎么检测的
检测的基本思想
对于一张未知的图片,输入神经网络后,从隐藏层抽取输出,将其feature map(特征图)表示出来,如果某些特征值很大,那么就证明输入的图片 X 包含有该层filter能检测的图案。但是我们没有图片怎么办?用机器自己创造的图片,包含filter能检测的pattern。

用数学语言描述机器创造图片的过程:
特征图中每一个元素的值表示为aij,用梯度上升的方法,找出能够使aij最大的 X,这个 X 就会包含filter能侦测的pattern。
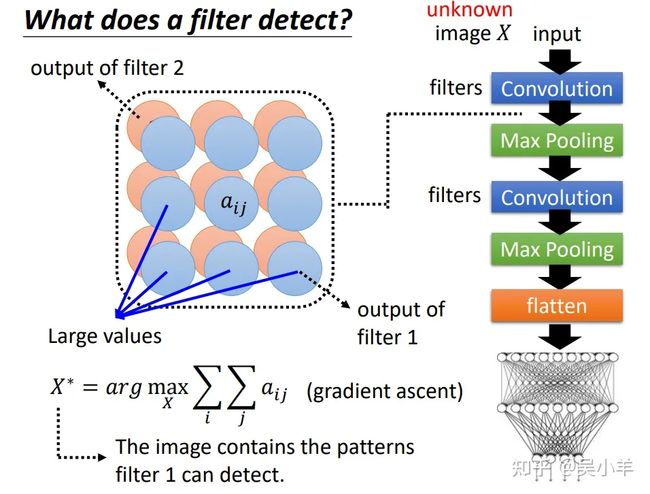
以数字辨识为例:
第一张图是通过隐藏层的输出找 X 可能包含的图案,找出来的 X 特征是横线斜线啥的。第二张图是通过最后结果找 X 可能包含的图案,当输出为0~8时,找到的 X 看起来都是杂讯,没有啥规律,就和恶意攻击时的杂讯一样。


改善检测效果
为了改善上面第二张图,让我们找到的 X 能够看起来像数字。我们给函数 X∗ 加上一项R(X),这一项是用来衡量 X 有多像数字,最后找到的结果还是有点数字的影子。

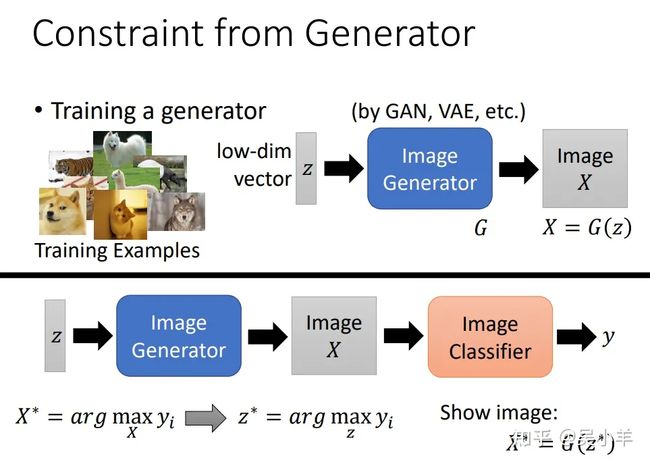
采用生成器解决找不到像图片的 X 的问题
上面通过神经网络的结果来找 X ,这个 X 要看起来像数字。我们发现很难找出像样的 X ,所以我们改变策略,将找像样的 X改为找像样的低维向量。操作过程是这样的:通过图片生成器,训练出能够转变成training image的低维向量,然后去找能使结果yi能够最大的低维向量z∗ ,再用找到的z∗ 去生成图片,这样就能解释神经网络在干什么了。
7.2.5 展望 outlook
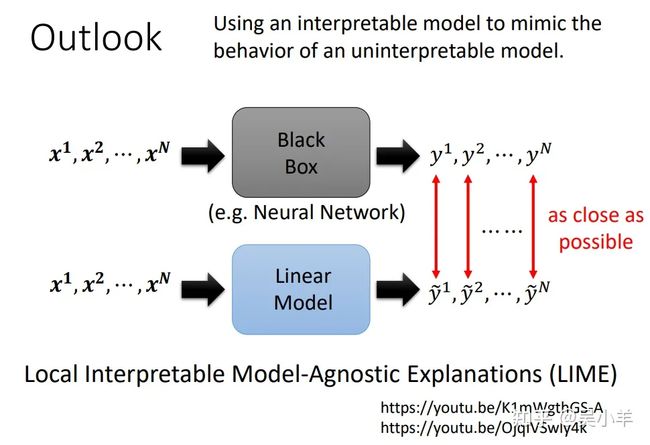
可以用简单模型来模仿复杂model的行为,再分析简单模型,这样就知道复杂model的行为在干嘛了。当然我们并不是让简单模型去模仿黑箱的全部行为,而是通过简单模型模仿黑箱中一小块区域的行为!
恭喜