使用FME封装一个多线程爬取m3u8在线视频的小玩意
一闲话
这一片博客其实和fme没有太大关系,事情是这样的,51放假,我回家后终于有时间,可以追一下《月光骑士》这部美剧。由于很多原因,美剧基本上只能在某些小网站上追。但是这些小网站,有一个很大的问题,就是资源太慢了,动不动卡半天。
后来突发奇想发,我能不能直接写爬虫获取到资源?
由于小网站类型很多,各种资源链接下载方式各不相同,因此,我偷了一个懒,制作了m3u8格式的下载和数据合并的方法。并将其封装到FME里面。
之所以选择FME,是因为我懒得写GUI界面,每次找到新的资源,再去改代码的话非常麻烦,因此直接用FME封装。而且如果我要批量下载网站上的作品,在前期提取视频地址的时候,还能发挥FME的优势,这是最方便的了。
整个部分核心为下载m3u8格式数据,然后对其进行合并,我分别将其封装成了两个自定义转器。
二m3u8格式下载
再次之前先讲一下m3u8格式,一般大家获取到的m3u8网址,下载下来是一个文本文件。如下图所示。
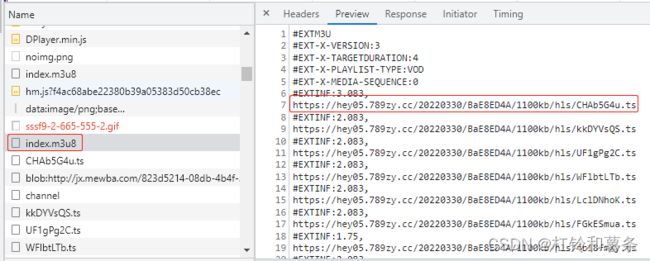
#EXINF下面的则为对应的下载链接,它将整个视频分割成无数个几秒钟的片段,这样不必每次就把整个视频全部下载到浏览器上,极大的减少了服务器的压力。关于m3u8的格式,我就不做过多的讲解,主要说爬取思路。
基本上下载的思路就是,下载index.m3u8文件,然后解析对应的每一个ts文件的地址,最后下载,记住必须要按照现有顺序对其进行整理排序。要不然后续视频拼接的时候就乱了。
下载的实现思路主要还是用的python,具体代码如下:
import requests
from requests.adapters import HTTPAdapter
import os
from threading import Thread
from queue import Queue
import re
class DownloadVideo():
def __init__(self, fanout_dir, name, base_url, max_thread):
self.headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Mobile Safari/537.36",
}
self.video_path = fanout_dir + '\\' + name
self.base_url = base_url
self.session = requests.session()
# 去除警告信息
requests.packages.urllib3.disable_warnings()
self.session.mount('http://', HTTPAdapter(max_retries=3))
self.qurl = Queue()
self.data = list()
self.thread_num = max_thread
pass
# 发送请求
def parse_url(self, url):
try:
response = self.session.get(url, headers=self.headers, timeout=30, verify=False)
return response.content
except requests.exceptions.RequestException as e:
print(e)
pass
def get_m3u8_data(self, m3u8_url, base_url):
try:
print(m3u8_url)
data = self.parse_url(m3u8_url)
data = data.decode(encoding="utf-8", errors="strict")
# print(data)
except Exception as e:
print(e)
return
# 不加?贪婪模式,替换所有匹配到的字符串
m3u8_data = re.sub('#E.*', '', data).split()
m3u8_data_list = []
for i in m3u8_data:
ts_url = base_url + i
m3u8_data_list.append(ts_url)
return m3u8_data_list
def write_files(self, title, url):
print('3.开始下载:' + str(title) + '---' + str(url))
r = self.parse_url(url)
out_dir = self.video_path
if not os.path.exists(out_dir):
os.makedirs(out_dir)
file_name = title + '.ts'
out_path = os.path.join(out_dir, file_name)
# with open(out_path, 'ab') as f: 用这个方法可以将视频以二进制形式追加并写入
with open(out_path, 'wb') as f:
f.write(r)
print('3.下载完成:' + str(title) + '---' + str(url))
pass
def get_info(self):
while not self.qurl.empty():
item = self.qurl.get()
url = item["url"]
title = item["title"]
try:
self.write_files(title, url)
except Exception as e:
print(e)
def run(self, m3u8_url):
# 下载url
url_list = self.get_m3u8_data(m3u8_url, self.base_url)
# print(url_list)
for i in range(len(url_list)):
item = {}
item["title"] = str(i).rjust(5, '0')
item["url"] = url_list[i]
self.qurl.put(item)
# 开始提取下载
ths = []
for _ in range(self.thread_num):
th = Thread(target=self.get_info)
th.start()
ths.append(th)
for th in ths:
th.join()
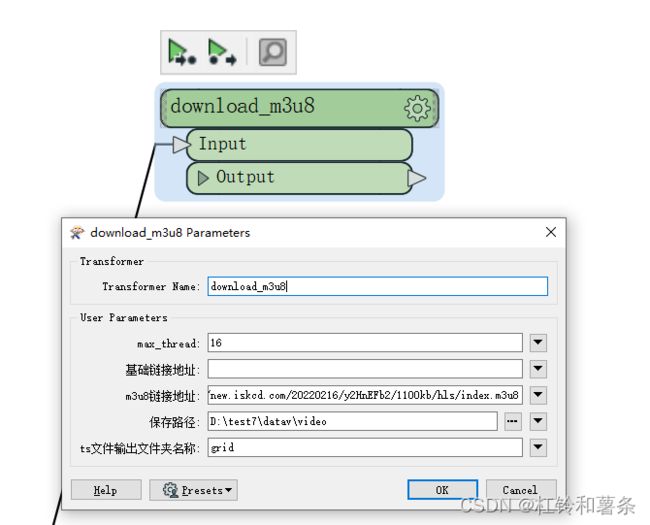
我将其整个封装到了FME里面,转换前参数如下:
- max_threa为下载的最大线程数,意味着我同时可以进行多少个数据的下载。
- 基础链接地址表示的,在某些情况下,m3u8文件下的的地址是一个相对的,你需要告诉程序,我要给他拼接上什么样的地址,记得最后是带斜杠”/“的。如果没有则不填写
- m3u8地址:
- 保存路径和名称,则是将这一片数据存储的地方,ts文件名称必须要改,因为后续拼接视频的时候是根据文件名称给视频命名的。
三ts文件拼接
下载后的ts文件,是每个几秒钟的视频片段,我们最终肯定是要对其进行合并的。具体代码如下:
class MergeTs():
def __init__(self, ffmpeg_path, input_dir, output_dir, max_thread, key_text, key_iv):
self.log = fmeobjects.FMELogFile()
self.ffmpeg_path = ffmpeg_path
######################配置信息##########################
self.ts_dir = input_dir
self.out_dir = output_dir
self.qurl = Queue()
self.data = list()
self.thread_num = max_thread
# 新增解密方式
self.keyText = key_text
self.keyiv = key_iv
def check_exits(self, path):
if not os.path.exists(path):
os.makedirs(path)
# 将文件合并成一个
def merge_ts(self, out_dir, in_dir, files, key_text, key_iv):
# 输出路径+文件名称
output_fp = open(out_dir, "wb+")
for file in files:
# print('开始合并' + in_dir + "/" + file)
input_file_path = in_dir + "/" + file
input_fp = open(input_file_path, "rb")
file_data = input_fp.read()
cryptor = self.decrypt(key_text, key_iv)
try:
if cryptor is None:
output_fp.write(file_data)
else:
output_fp.write(cryptor.decrypt(file_data))
except Exception as exception:
input_fp.close()
output_fp.close()
self.log.logMessageString(exception)
return False
input_fp.close()
output_fp.close()
return True
# 视频解密
def decrypt(self, keyText, keyiv):
# 判断是否进行了加密
if keyText is None or keyText == '':
return None
# 判断是否有偏移量
if keyiv is not None and keyiv != '':
cryptor = AES.new(bytes(keyText, encoding='utf8'), AES.MODE_CBC, bytes(keyiv, encoding='utf8'))
else:
cryptor = AES.new(bytes(keyText, encoding='utf8'), AES.MODE_CBC, bytes(keyText, encoding='utf8'))
return cryptor
def ffmpeg2mp4(self, input_file_path):
ouput_file_path = input_file_path.split('.flv')[0] + '.mp4'
if not os.path.exists(input_file_path):
self.log.logMessageString(input_file_path + " 路径不存在!")
return False
cmd = r'{0} -i "{1}" -vcodec copy -acodec copy "{2}"'.format(self.ffmpeg_path, input_file_path, ouput_file_path)
self.log.logMessageString('开始执行{0}'.format(cmd))
if os.system(cmd) == 0:
self.log.logMessageString(input_file_path + "转换成功!")
return True
else:
self.log.logMessageString(input_file_path + "转换失败!")
return False
# 开始合并
def merge_start(self):
while not self.qurl.empty():
item = self.qurl.get()
root = item["root"]
files = item["files"]
# 检查路径是否有,没有则创建
self.check_exits(self.out_dir)
out_dir = self.out_dir + "\\" + root.split('\\')[-1] + '.flv'
# print(out_dir)
self.merge_ts(out_dir, root, files)
self.ffmpeg2mp4(out_dir)
pass
def main(self):
# 1.遍历文件,获取数据路径
for root, dirs, files in os.walk(self.ts_dir):
# 当前目录
# print(root.split('\\')[-1])
# files.sort()
item = {}
item["root"] = root
item["files"] = files
if len(files) > 0:
self.qurl.put(item)
# print(item)
# 多进程开启,合并数据
ths = []
for _ in range(self.thread_num):
th = Thread(target=self.merge_start)
th.start()
ths.append(th)
for th in ths:
th.join()
上面的代码需要注意一点,因为是在FME内部的PythonCaller里面执行的,因此我使用的fmeobjects.FMELogFile().logMessageString()方法替代print方法进行日志的输出,这在fme之外使用代码是无法执行的,如果又在外部程序使用的需求,记得改掉即可。
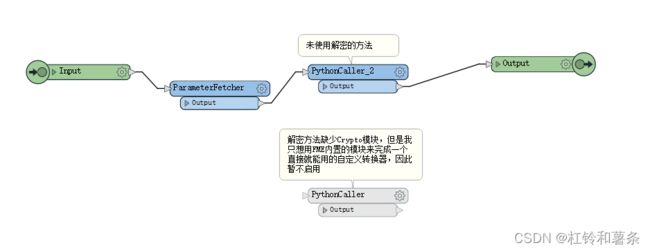
对于上面的功能,我也将其封装到了FME里面,具体参数看下图:

其中使用了ffmpeg.exe这个程序进行视频的转码,因此,大家记得要选择这个程序才能进行拼接。
需要注意的一点是,有些网站的视频是对其进行了加密处理的。我一开始的时候是下了解密的方法,但是其中使用了Crypto这个库,这个库在FME里面没有,所以对加密视频的处理这个功能,我暂未进行启用,有解密需求的,可以下载安装这个第三方库之后,将图下的转换器重新替换一下即可。
对于视频加密解密这部分功能,要讲清楚要很多时间了,我代码里已经有写了解密过程,在此略过不讲。【主要是懒,或许下次?】
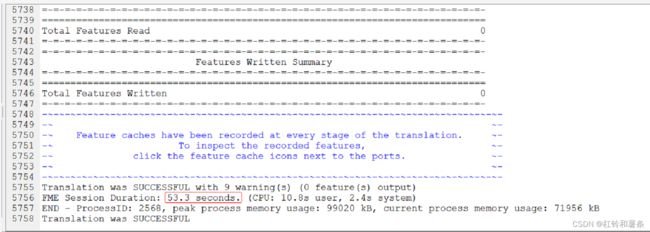
最后展示一下下载速度,45分钟的视频,开了16个线程,下载只需要53秒多一点,速度还是很可观的。以后再也不用担心追剧卡顿了。
文末是最喜爱的分享环节,包括FME的工作空间文件和ffmpeg.exe程序
链接:https://pan.baidu.com/s/1cApoUOWFPebbSRFIvIC-7Q
提取码:kxou
如果有喜欢的,可以关注我个人公众号,不务正业的GISER,后续会继续分享一些不务正业的有趣的东西
