注意力机制 - Bahdanau注意力
文章目录
- Bahdanau注意力
-
- 1 - 模型
- 2 - 定义注意力解码器
- 3 - 训练
- 4 - 小结
Bahdanau注意力
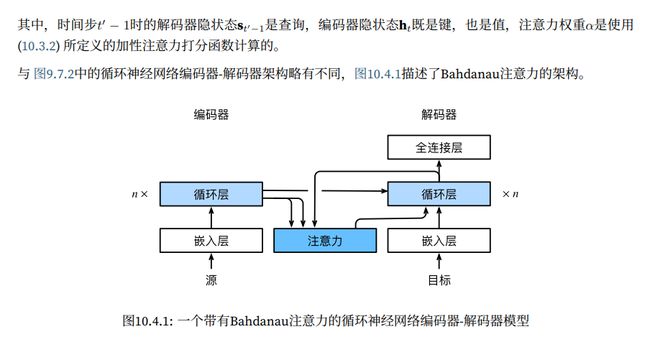
我们在 9.7节中探讨了机器翻译问题:通过设计⼀个基于两个循环神经⽹络的编码器-解码器架构,⽤于序列到序列学习。具体来说,循环神经⽹络编码器将⻓度可变的序列转换为固定形状的上下⽂变量,然后循环神经⽹络解码器根据⽣成的词元和上下⽂变量按词元⽣成输出(⽬标)序列词元。然⽽,即使并⾮所有输⼊(源)词元都对解码某个词元都有⽤,在每个解码步骤中仍使⽤编码相同的上下⽂变量。有什么⽅法能改变上下⽂变量呢?
我们试着从 [Graves, 2013]中找到灵感:在为给定⽂本序列⽣成⼿写的挑战中,Graves设计了⼀种可微注意⼒模型,将⽂本字符与更⻓的笔迹对⻬,其中对⻬⽅式仅向⼀个⽅向移动。受学习对⻬想法的启发,Bahdanau等⼈提出了⼀个没有严格单向对⻬限制的可微注意⼒模型 [Bahdanau et al., 2014]。在预测词元时,如果不是所有输⼊词元都相关,模型将仅对⻬(或参与)输⼊序列中与当前预测相关的部分。这是通过将上下⽂变量视为注意⼒集中的输出来实现的
1 - 模型

import torch
from torch import nn
from d2l import torch as d2l
2 - 定义注意力解码器
下面我们看看如何定义Bahdanau注意力,实现循环神经网络编码器-解码器。其实,我们只需要重新定义解码器即可。为了更方便地显示学习的注意力权重,以下AttentionDecoder类定义了带有注意力机制解码器的基本接口
class AttentionDecoder(d2l.Decoder):
"""带有注意力机制解码器的基本接口"""
def __init__(self,**kwargs):
super(AttentionDecoder,self).__init__(**kwargs)
@property
def attention_weights(self):
raise NotImplementedError
接下来,让我们在接下来的Seq2SeqAttentionDecoder类中实现带有Bahdanau注意力的循环神经网络解码器。首先,我们初始化解码器的状态,需要下面的输入:
- 编码器在所有时间步的最终层隐状态,将作为注意力的键和值:
- 上一时间步的编码器全层隐状态,将作为初始化解码器的隐状态
- 编码器的有效长度(排除在注意力池中填充词元)
在每个解码时间步骤中,解码器上一个时间步的最终层隐状态将用作查询。因此,注意力输出和输入嵌入都连结为循环神经网络解码器的输入
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self,vocab_size,embed_size,num_hiddens,num_layers,dropout=0,**kwargs):
super(Seq2SeqAttentionDecoder,self).__init__(**kwargs)
self.attention = d2l.AdditiveAttention(num_hiddens,num_hiddens,num_hiddens,dropout)
self.embedding = nn.Embedding(vocab_size,embed_size)
self.rnn = nn.GRU(embed_size + num_hiddens,num_hiddens,num_layers,dropout=dropout)
self.dense = nn.Linear(num_hiddens,vocab_size)
def init_state(self,enc_outputs,enc_valid_lens,*args):
# outputs的形状为(batch_size,num_steps,num_hiddens)
# hidden_state的形状为(num_layers,batch_size,num_hiddens)
outputs,hidden_state = enc_outputs
return (outputs.permute(1,0,2),hidden_state,enc_valid_lens)
def forward(self,X,state):
# enc_outputs的形状为(batch_size,num_steps,num_hiddens).
# hidden_state的形状为(num_layers,batch_size,num_hiddens)
enc_outputs, hidden_state, enc_valid_lens = state
# 输出X的形状为(num_steps,batch_size,embed_size)
X = self.embedding(X).permute(1,0,2)
outputs,self._attention_weight = [],[]
for x in X:
# query的形状为(batch_size,1,num_hiddens)
query = torch.unsqueeze(hidden_state[-1],dim=1)
# conetxt的形状为(batch_size,1,num_hiddens)
context = self.attention(query,enc_outputs,enc_outputs,enc_valid_lens)
# 在特征维度上连结
x = torch.cat((context,torch.unsqueeze(x,dim=1)),dim=-1)
# 将x变形为(1,batch_size,embed_size + num_hiddens)
out,hidden_state = self.rnn(x.permute(1,0,2),hidden_state)
outputs.append(out)
self._attention_weight.append(self.attention.attention_weights)
# 全连接层变换后,outputs的形状为(num_steps,batch_size,vocab_size)
outputs = self.dense(torch.cat(outputs,dim=0))
return outputs.permute(1,0,2),[enc_outputs,hidden_state,enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weight
接下来,我们使用包含7个时间步的4个序列输入的小批量测试Bahdanau注意力解码器
encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,num_layers=2)
encoder.eval()
decoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8, num_hiddens=16,num_layers=2)
decoder.eval()
X = torch.zeros((4, 7), dtype=torch.long) # (batch_size,num_steps)
state = decoder.init_state(encoder(X), None)
output, state = decoder(X, state)
output.shape, len(state), state[0].shape, len(state[1]), state[1][0].shape
(torch.Size([4, 7, 10]), 3, torch.Size([4, 7, 16]), 2, torch.Size([4, 16]))
3 - 训练
我们在这里指定超参数,实例化一个带有Bahdanau注意力的编码器和解码器,并对这个模型进行机器翻译训练。由于新增的注意力机制,训练要比没有注意力机制慢得多
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 250, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = d2l.Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
loss 0.019, 8321.3 tokens/sec on cuda:0
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7fe6j7ca-1662988224385)(https://yingziimage.oss-cn-beijing.aliyuncs.com/img/202209122107923.svg)]
模型训练后,我们用它将几个句子翻译成法语并计算它们的BLEU分数
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng,fra in zip(engs,fras):
translation,dec_attention_weight_seq = d2l.predict_seq2seq(net,eng,src_vocab,tgt_vocab,num_steps,device,True)
print(f'{eng} => {translation}, ',f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
go . => va !, bleu 1.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => il est mouillé ., bleu 0.658
i'm home . => je suis chez moi ., bleu 1.000
attention_weights = torch.cat([step[0][0][0] for step in dec_attention_weight_seq],0).reshape((1, 1, -1, num_steps))
训练结束后,下面我们通过可视化注意力权重你会发现,每个查询都会在键值对上分配不同的权重,这说明在每个解码步中,输入序列的不同部分被选择性地聚集在注意力池中
d2l.show_heatmaps(
attention_weights[:,:,:,:len(engs[-1].split()) + 1].cpu(),
xlabel='Key postions',ylabel='Query positions')
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dPuco183-1662988224385)(https://yingziimage.oss-cn-beijing.aliyuncs.com/img/202209122107924.svg)]
4 - 小结
- 在预测词元时,如果不是所有输⼊词元都是相关的,那么具有Bahdanau注意⼒的循环神经⽹络编码器-解码器会有选择地统计输⼊序列的不同部分。这是通过将上下⽂变量视为加性注意⼒池化的输出来实现的
- 在循环神经⽹络编码器-解码器中,Bahdanau注意⼒将上⼀时间步的解码器隐状态视为查询,在所有时间步的编码器隐状态同时视为键和值