GitHub 3.1K业界首个流式语音合成系统开源
智能语音技术已经在生活中随处可见,常见的智能应用助手、语音播报、近年来火热的虚拟数字人,这些都有着智能语音技术的身影。智能语音是由语音识别,语音合成,自然语言处理等诸多技术组成的综合型技术,对开发者要求高,一直是企业应用的难点。
飞桨语音模型库 PaddleSpeech ,为开发者提供了语音识别、语音合成、声纹识别、声音分类等多种语音处理能力,代码全部开源,各类服务一键部署,并附带保姆级教学文档,让开发者轻松搞定产业级应用!
PaddleSpeech 自开源以来,就受到了开发者们的广泛关注,关注度持续上涨。
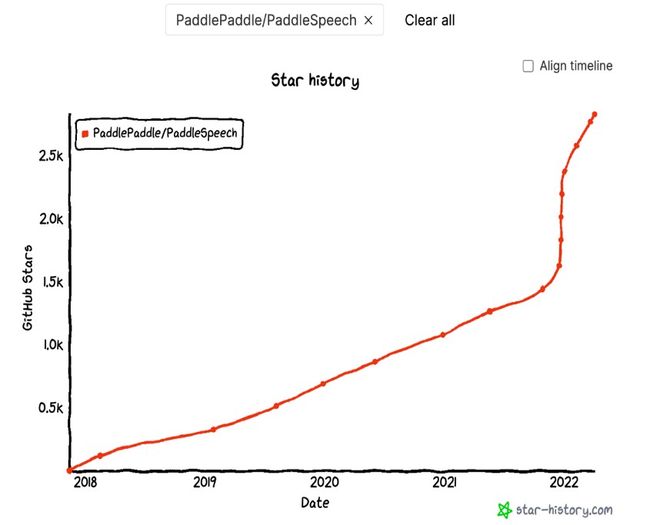
在此过程中,我们也根据用户的反馈不断升级,推陈出新,优化用户体验。
本次, PaddleSpeech 1.0 版本正式发布,为开发者带来了四项重要升级:
全新发布 PP-TTS :业界首个开源端到端流式语音合成系统,支持流式声学模型与流式声码器,开源一键式流式语音合成服务部署方案。
全新发布 PP-ASR :开源基于上万小时数据的流式语音识别系统,开源一键式流式语音识别服务部署方案。支持 Language Model 解码和个性化语音识别。
全新发布 PP-VPR :开源全链路声纹提取与检索系统,10分钟轻松搭建产业级系统。
一键服务化能力:语音识别、语音合成、声纹识别、声音分类、标点恢复,一键部署五项核心语音服务。
★ 项目传送门 ★
点击文末阅读原文一键GET!
GitHub - PaddlePaddle/PaddleSpeech: Easy-to-use Speech Toolkit including SOTA/Streaming ASR with punctuation, influential TTS with text frontend, Speaker Verification System and End-to-End Speech Simultaneous Translation.
以下为本次发布内容详细解读。
1.PP-TTS 业界首个开源端到端流式语音合成系统
语音合成是机器“说话”的“嘴巴”。随着深度学习技术的发展,采用端到端神经网络进行语音合成的效果相较于传统技术有了极大的提升,但是端到端语音合成的响应时间长,在实时性要求较高的场景中难以满足业务需求。
如在实时交互的虚拟数字人应用中, 需要虚拟人对用户指令快速做出应答,否则会消耗用户的耐心、降低用户体验,此时就需要流式语音合成系统,在保障合成质量的同时,提高响应速度、提升交互体验。

PaddleSpeech 全新发布的 PP-TTS ,提供了一键式部署流式语音合成系统的方案,解决了在语音合成技术应用过程中,响应时间长、落地困难的问题。
流式推理结构,降低平均响应时延
以声学模型 FastSpeech2 、声码器 HiFi-GAN 为例, PP-TTS 对 FastSpeech2 的 Decoder 模块进行了创新,替换了 FFT-Block 为卷积结构,创新性地提出了基于 FastSpeech2 结合 HiFi-GAN 的流式推理结构, 以 Chunk 的方式进行流式推理,可以使声学模型和声码器的输出与非流式推理保持一致。

PP-TTS 的流式语音合成可以在保证合成质量的前提下,大幅降低平均响应时延:
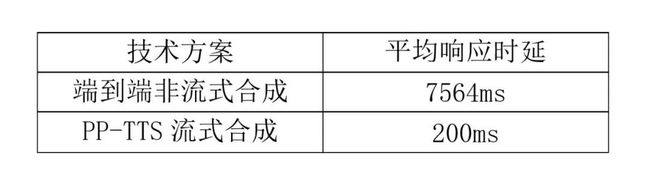
测试环境:测试用例为 CSMSC 数据集后100条, CPU 为 Intel(R) Core(TM) i5-8250U CPU @ 1.60GHz
相较于端到端非流式合成, PP-TTS 流式合成的平均响应时延降低了97.4%,即使在普通的 CPU 笔记本上也能够实时响应。
文本前端优化
PP-TTS 提供了针对中文场景的语音合成文本前端优化方案:针对时间、日期、电话、温度等常见非标准词进行了文本正则化处理;开源了针对中文场景的轻声变调、三声变调和“一”“不”变调等字音转换( G2P )解决方案。在自建的文本正则化测试集上, CER 低至0.73%;以 CSMSC 数据集的拼音标注为 Ground Truth ,字音转换( G2P )的 WER 低至 2.6%。

2.PP-ASR.基于上万小时数据的流式语音识别系统
如果说语音合成是机器的“嘴巴”,那语音识别就是机器的“耳朵”,拥有一个识别准确的“耳朵”,才能让机器变得更加聪明。端到端非流式语音识别模型的优势在于识别效果更好,但是劣势是系统延迟大,无法满足实时交互场景的需求。针对这个问题, PaddleSpeech 1.0 版本给大家带来了PP-ASR:基于 WenetSpeech 上万小时数据的流式语音识别系统。
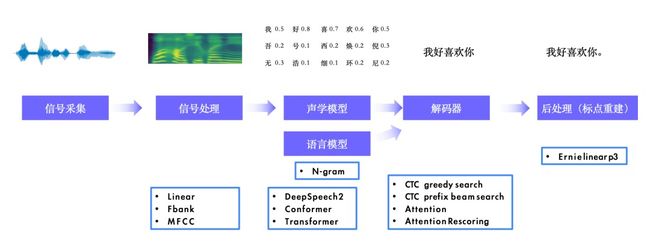
PP-ASR 流式语音识别在保障识别效果的前提下,响应时延显著降低,可以实时得到识别结果,提升用户的使用体验。

测试数据集:Conformer 模型,测试数据集为 AIShell-1 ,流式识别分块长度为 640ms , GPU: Tesla V100-SXM2-32GB,CPU:80 Core Intel(R) Xeon(R) Gold 6271C CPU@ 2.60GHz
个性化识别方案
基于 WFST 的个性化识别方案,支持特定场景的语音识别任务。例如交通报销场景,针对通用语音识别对 POI 、日期、时间等实体识别效果差,通过基于 WFST 的个性化识别可以提升识别的准确率。在打车报销内部测试集上,通用识别 CER 为5.4%,优化后 CER 为1.32%,绝对提升4.08%。
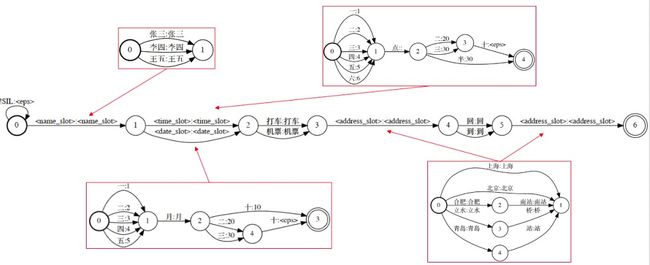
演示效果见文末示例
3.PP-VPR.全链路声纹识别与音频检索系统
声纹特征作为生物特征,具有防伪性好,不易篡改和窃取等优点,配合语音识别与动态密码技术,非常适合于远程身份认证场景。在声纹识别技术的基础上,配合音频检索技术(如演讲、音乐、说话人等检索),可在海量音频数据中快速查询并找出相似声音(或相同说话人)片段。
其中声纹识别作为一个典型的模式识别问题,其基本的系统架构如下:

PaddleSpeech 这次开源的 PP-VPR 声纹识别与音频检索系统,集成了业界领先的声纹识别模型,使用 ECAPA-TDNN 模型提取声纹特征,识别等错误率( EER , Equal error rate )低至0.83%,并且通过串联 MySQL 和 Milvus ,可以搭建完整的音频检索系统,实现毫秒级声音检索。
4.一键部署五项核心语音服务,语音识别、语音合成、声纹识别,声音分类和标点恢复
在产业应用中,将训练好的模型以服务的形式提供给他人使用可以更方便。考虑到搭建一套完整的网络服务应用是一件繁琐的工作, PaddleSpeech 为大家提供了一键式部署服务,命令行一行代码即可同时启动语音识别,语音合成,声纹识别,声音分类和标点恢复五大服务。
Demo使用及展示
进入 demo/speech_server 目录下,一键启动语音识别、语音合成、声纹识别、声音分类和标点恢复服务。
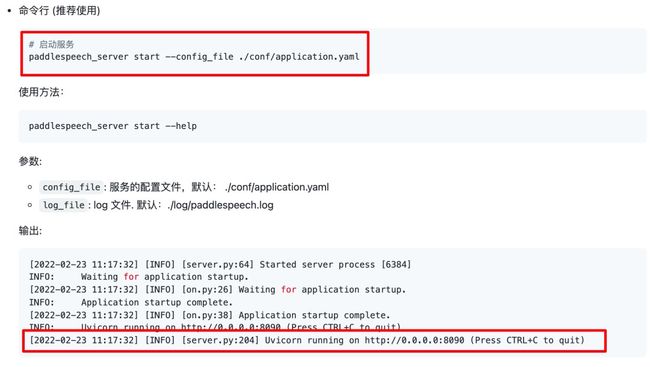
此时服务已经挂载到了配置的8090端口了,我们可以通过命令行对服务进行调用。
客户端调用,以语音识别为例:
![]()
识别结果:
![]()
语音合成、声纹识别、声音分类和标点恢复的服务使用类似,可以参考对应的文档。