深度学习在文档矫正中的应用
深度学习在文档矫正中的应用
一、扫描文稿
在日常生活中,我们经常会使用到扫描文稿的功能。包括IOS备忘录自带的扫描功能、扫描全能王等,文稿扫描给我们带来了许多便利。文稿扫描可以应对的范围非常广、包括身份证、银行卡、纸质表格等。我们扫描文稿的目的在于更好的辨别文字信息。但在扫描文稿时会遇到千奇百怪的问题,包括阴影、文稿褶皱、文稿形变等,我们今天主要来讨论一下文稿形变的问题。
二、传统办法解决文档形变
2.1、形变文档
在我们日常生活中,扫描文档通常无法完整把整个文档拍下来,或者拍出一个规范的矩形,会遇到各种各样的问题,导致扫描的图像有一定形变。这里主要包括弯曲、折叠、褶皱、透视、旋转等。计算机处理规范的文稿非常简单,但是当我们简单把文稿旋转后就会出现一些问题。而面对其它更复杂的变换时,扫描的工作就变得更加困难。
下面左图是计算机比较容易处理的情况,而在处理右侧几张图时,结果不是那么理想。
为了方便识别,我们会对发生形变的图像进行矫正。这里我们来对比一下传统矫正方法和基于深度学习的矫正方法。
2.2、传统办法
在深度学习流行前,就已经有了相关的对策来解决文档形变的问题。比如下图的扑克牌,有旋转、透视等问题。我们希望可以扑克以一个近似完美矩形的形式单独展现出来。

这里以小王为例,首先会找到扑克(文档)的四个角的坐标,这里会使用到各种图像处理的办法,图像梯度、边缘检测等算法。然后估计扑克的宽高。然后我们可以把图像还原的过程理解为下图:
我们可以根据左图红框的四点坐标和右图红框的四点坐标得到一个变换矩阵,然后对原图进行仿射变换,得到矫正后的图像。之后再对矫正后的图像进行文字识别,这样得到的结果要更加精确。
在上面的例子中,我们对每个像素点进行同样的变换,这样可以很好地解决透视问题。如果面对更加复杂的形变,比如弯曲、折叠等。我们还需要对上面的处理进行调整。
使用传统的办法可以在一定程度上复原图像,但是真实情况远比上面要复杂的多,使用传统办法会遇到各种问题。
三、基于偏移场的方法
深度学习提供了一种新的方法可以对图像进行形变矫正。这个方法类似于上面的仿射变换,但是变换矩阵的获取是通过深度学习来得到的,我们把这个变换矩阵叫做“偏移场”。
3.1、偏移场
偏移场是一个带有方向和大小的图像,它类似于图像梯度。下图是一个偏移场的例子。
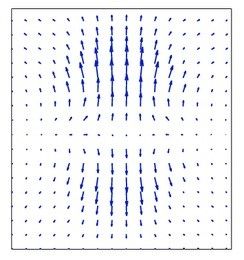
偏移场的形状与图像相同,偏移场中每个箭头都是一个向量,包含方向和大小信息。即图像对应位置需要往那个方向偏移,以及偏移量。
在实际操作时会训练一个神经网络,将形变图像作为输入,然后输出偏移场。如下图所示:
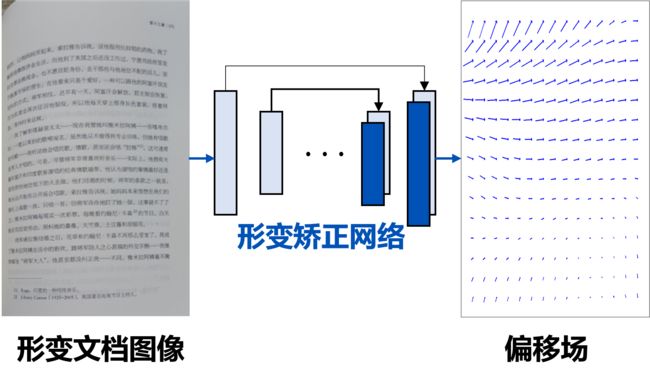
得到偏移场后我们就可以对图像进行矫正。
3.2、文档矫正
我们可以让原图和偏移场做类似仿射变换的操作,即对原图每个像素进行对应的偏移,然后就可以得到矫正后的图像。偏移操作图示如下:

在上面的例子中,原图只是局部形变这种问题使用传统方法难以处理,而使用偏移场的方式却可以简单解决。相比传统的仿射变换,偏移场可以对每个像素做不同的变换,从而进行更灵活的调整。想褶皱、弯曲等问题可以很好地解决。
有时候矫正后的文档会有部分空缺,因此完整的修复过程还会添加一个填充的操作。填充的方式也有很多,其中一种就是用Inpatienting网络对其填充。具体骤如下:
现在扫描文稿已经能做到非常智能、可以识别各种复杂文稿。包括手写文稿、词云图片、表格等。这里以合合信息智能文字识别服务平台TextIn为例子,体验一下文稿扫描的功能。
四、实际体验
4.1、规范图片、文稿
我们可以在TextIn体验我们文字识别相关的功能。我们先测试相对标准的图像。这里使用一个表格图像进行测试。

左侧是用来识别的图像,右侧是识别结果。内容被完美识别出来了,右侧内容可以直接复制。
Vehicledepartment用车部门 合合信息 Transporttime用车时间 2020年5月20日 Number ofpassengers乘车人数 14人 Destination目的地 上海静安区市北·云立方 Contact联系人 合小合 contactnumber联系电话 18888888888 Driver drive safely and on time司机驾车安全、准时性 Car reason(用车事由):公务出行 drive safely安全驾驶pick-up on time接送准时(Check after the car is finished bythe rider.由乘车人用车结束后勾选) License plate number 车牌号沪M888888 Driver’s name 司机姓名合小安 contact number联系电话021-88888888 Pick-Up Locations 接送地点上海工业园区88号 Person incharge audit用车部门负责人 刘杨 Administrativemanager行政部负责人 杨周
4.2、拍摄文稿
通常文稿扫描都是使用拍摄图片进行。接下来我们尝试用自己拍摄的图像来进行测试,拍照时人为添加一些困难。左侧是被识别图像,这里认为制造了阴影、褶皱等,加大识别难度。右侧则是识别结果,可以看出大致内容被正常识别出来了。

下面是一部分内容:
以下五个部分:
(1)采样孔:使数字化设备实现对特定图像元素的观测,不受图像其他部分的影响。
(2)图像扫描机构:使采样孔按照预先定义的方式在图像上移动,从而按顺序观测每
一个像素。
(3)光传感器:通过采样检测图像的每一个像素的亮度,通常采用CCD阵列。
(4)量化器:将光传感器输出的连续量转化为整数值。典型的量化器是A/D转换电
路,它产生一个与输入电压或电流成比例的数值。
4.3、词云图像
除了上述两种常规图像,TextIn还可以扫描证件照、简历、房产证、词云等复杂图像,比如下面是一个词云的例子:

相比前面几个问题,词云的情况要更为复杂。这里的文本是多语言、多角度的,识别起来非常困难。在TextIn中识别结果非常可以:
ПриветT.
Ahoj.
Kaixo.
Bunǎ.
Përshëndetje.
Haloo.
Прывітанне
Salam
在识别出文字的同时还以相应的语言展示出来。
4.4、摩尔纹去除
在我们对电子产品拍照时,会出现一些奇怪的纹理,这种纹理就是摩尔纹。消除摩尔纹可以提高图像、文字清晰度,更便于识别。摩尔纹识别也可以使用深度学习的方式实现,可以训练专门的摩尔纹去除网络。这里是去除摩尔纹的一个体验地址,下面是带有摩尔纹图像及出去摩尔纹图像的对比:

去除后可以很清晰看到文字内容。
4.5、PS智能检测
处理上面和文稿相关的扫描、文字识别等任务外,TextIn还可以进行PS智能检测,检测图像是否PS过。在防诈骗时非常有效。现在PS技术非常成熟,很多PS过的图像人眼无法辨别,可以用PS伪造转载记录、学历证书、纸质证明文件等。使用PS智能检测可以很好的辨别这些伪造的图像,这里我们对正常图像进行人为的PS处理,然后在TextIn进行测试。
左侧是使用了PS的图像,用人眼很难判断是否被PS过。右侧是检测结果,除了会显示是否有篡改,结果还会展现被篡改的区域。
4.6、去除水印
去除水印也是我们经常需要用到的功能,有时候我们下载图像时会自动添加一些水印,会遮挡一部分内容。TextIn中提供了去除水印的功能,可以在TextIn进行体验,下面是实际效果的一个例子:

左侧是处理后的效果,右侧是带有水印的效果。首先去除水印的效果非常好,水印被正常去除了。并且去除水印的部分没有模糊的感觉。
另外我们可以做一件有趣的事,可以手动给一个文档添加水印,然后使用TextIn对其去水印,再把去水印的结果交给前面提到的PS智能检测检测是否被篡改过,可以发现一个非常有趣的现象。大家可以自行测试。
4.7、自动擦除手写文字
在TextIn中还有个有趣的功能,就是自动擦除手写文字。这个在我们扫描试卷时非常有用,此功能可以在TextIn体验。下面是测试结果:

我们测试的是一张已经写过和批改过的试卷,试卷里用包括手写英文,人为框选、勾叉等。在去除后,手写的部分都被去除了,而试卷本身的内容则保留了。另外,去除结果还对原图像进行了一个增强,更便于观看。
4.8、印章检测识别
对于一些企业,可能会使用到印章识别检测的功能。印章的文字通常是弯曲的,一般的文字识别程序不能很好的处理,在TextIn中提供了印章检测识别的功能。包括检测图像中的印章、识别印章中的文字,下面是一个具体效果:
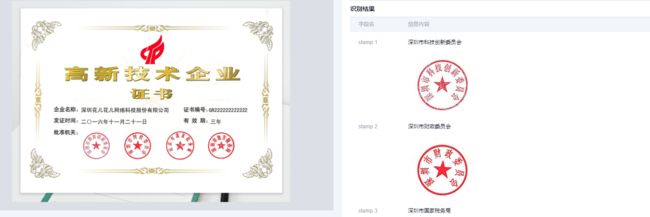
左图是被检测图像,图像中有多个印章。右图是检测结果,把每个印章检测出来了,并识别出印章的文本内容。上述功能可以在TextIn体验。
4.9、其它功能
除了上述功能,TextIn还能做诸如二维码识别、票据识别、车辆相关识别、个人证据识别等功能。另外还有文档转换功能,下面是可以使用的一些接口:
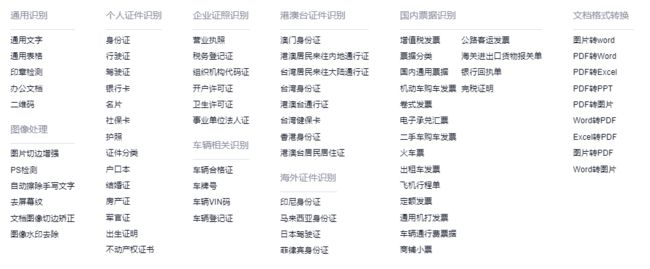
上面功能可以直接直线体验,也可以使用TextIn提供的API,将功能接入自己的应用程序。具体api文档可以参考https://www.textin.com/document/index。
比如下面是Python通用文字识别的一段代码:
import requests
import json
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
class CommonOcr(object):
def __init__(self, img_path):
# 请登录后前往 “工作台-账号设置-开发者信息” 查看 x-ti-app-id
# 示例代码中 x-ti-app-id 非真实数据
self._app_id = 'c81f*************************e9ff'
# 请登录后前往 “工作台-账号设置-开发者信息” 查看 x-ti-secret-code
# 示例代码中 x-ti-secret-code 非真实数据
self._secret_code = '5508***********************1c17'
self._img_path = img_path
def recognize(self):
# 通用文字识别
url = 'https://api.textin.com/ai/service/v2/recognize'
head = {}
try:
image = get_file_content(self._img_path)
head['x-ti-app-id'] = self._app_id
head['x-ti-secret-code'] = self._secret_code
result = requests.post(url, data=image, headers=head)
return result.text
except Exception as e:
return e
if __name__ == "__main__":
response = CommonOcr(r'example.jpg')
print(response.recognize())
实现起来非常简洁,我们只需要修改CommonOcr中的图片路径就可以了。更多功能可以参考https://www.textin.com/