举个例子,如何用GCN图卷积神经网络实现摔倒监测?


作者 | 李秋键
责编 | 寇雪芹
头图 | 下载于视觉中国

引言
近几年来深度学习的发展越来越火热,其中最为典型的就是半监督学习的新研究进展GCN。由Kipf和Welling提出的GCN被证明是一种有效的图半监督学习框架应用,如社会、医疗、商业和交通网络分析,其中典型的对象是在少数有标记数据的帮助下对无标记数据进行分类图中的样本。
图卷积网络(GCN)已被证明是一种有效的基于图的半卷积网络框架监督学习应用。GCN的核心操作块是卷积层通过融合节点属性和关系,使网络能够构造节点嵌入节点之间。不同的特性或特性的相互作用本身就具有不同的影响卷积的层。
然而,关于特征重要性影响的研究非常有限在GCN-related社区。在这项工作中,我们试图增加卷积层的GCNS通过建模特征的潜在交互作用,统计注意特征的重要性,即补充标准GCNS和只需要简单的计算与统计而不是沉重的培训。
为此,我们将每个卷积层的特征输入作为一个单独的multi-分层异构图,并提出了图统计自注意(GSSA)方法学习特征重要性的层次结构。更具体地说,我们建议在信道自注意(CSA),以捕获特征信道之间的依赖关系,和基于均值的自我注意(MSA)来重新加权特征之间的相似性。瞄准每个图形卷积层,GSSA可以以“即插即用”的方式应用于广泛的GCN变体。
据我们所知,这是优化GCNs特性的第一个实现重要的视角。大量的实验表明,GSSA可以促进现有的流行在半监督节点分类任务中,基线是非常重要的。

系统概述
本系统主要使用的是openpose提取特征,然后对特征使用GCN算法进行分类,以检验GCN的模型效果。
1.运行环境
由于需要使用到openpose工具,故需要配置以下环境。分别是:
python环境及相关库(opencv、numpy、pytorch等)环境、CUDA搭建GPU环境、C++环境、swig编译环境、以及ffmpeg环境和openpose环境;
2.openpose概述:
openpose是依赖于卷积神经网络和监督学习实现人体姿态评估算法,其主要的优点在于适用于多人二维且较为精准和迅速的识别开源。
整个系统的搭建主要是依赖于openpose的姿态识别环境。Openpose的调用在这里通过调用其中设定好的主函数即可,其中包括模型加载程序、调用程序以及Estimator评估等等。
3.GCN简述:
图卷积方法主要有两大流派:基于频谱的方法和基于空间的方法。
基于频谱的方法主要有Spectral CNN (第一代 GCN)、第二代GCN、ChebyNet、 CayleyNet、一阶 ChebyNet等。在行为识别领域,ChebyNet 及一阶近似被广泛应用。基于空间的方法主要有消息传递与聚合、图采样与聚合、图结构序列化、关注卷积方式、基于注意力机制、关注感知域的方法。
随着GCN方法的发展,其方法主要分为两大类:基于频谱的方法 (spectral-based)和基于空间的方法 (spatial-based)。基于频谱的图卷积网络是将图信号与频谱信号进行转换和分析,然后再恢复图信号所在的空域,从而完成图信号的降噪与特征提取。以“降低复杂度”为主线,将常用于图像的卷积神经网络应用到图数据上。
基于频谱的图卷积通过添加自我连接单位矩阵、归一化邻接矩阵 A 的方式解决了基于空间的图卷积忽略节点自身特征、邻接矩阵过于庞大的两个问题。但由于基于频谱的图卷积方法存在灵活性不高、普适性不强、运行效率较低等问题,基于空间的图卷积方法利用邻域聚合的思想降低了复杂度,增强了泛化能力,提高了运行效率,是行为识别领域在图结构数据上进行分析的基本思想。

数据预处理
1.openpose图像数据生成
在配置好openpose环境以后,使用cut.py中的代码可以读取fall.mp4的视频,并生成数据集保存在datasets文件夹下,然后我们再手动分好类,分别为shuaidao和common这两个动作。其中文件夹数据如下:
图1 common文件夹数据图片
图2 shuaidao文件夹数据图片
分割的步骤就是读取mp4视频文件,利用循环分视频帧,然后手动分好数据集。其中分割部分的代码为cut.py,代码如下:
1e = TfPoseEstimator(get_graph_path('mobilenet_thin'), target_size=(432, 368))
2cap=cv2.VideoCapture("fall.mp4")
3num=0
4while True:
5 num+=1
6 ret,frame = cap.read()
7 image = frame
8 cv2.imwrite("datasets/"+str(num)+".jpg",image)
9 cv2.imshow("1", image)
10 cv2.waitKey(1)2.2 特征提取
在分割好数据集后分别对各自的类别图片提取特征,将特征分别保存在shuaidao.txt和common.txt文件中。但是考虑到有的时候并不是可以完整地提取到特征,对特征缺少的部分,使用均值替换。其中特征提取的代码为feature.py文件,得到的txt数据如下可见:
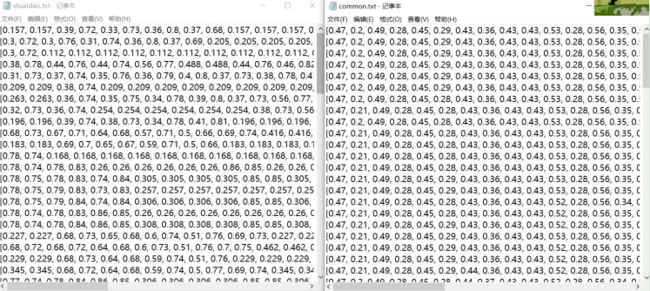
图3 特征提取结果显示
关键代码如下:
1e = TfPoseEstimator(get_graph_path('mobilenet_thin'), target_size=(432, 368))
2f0=open("shuaidao.txt","w")
3f1=open("common.txt","w")
4for file in os.listdir("datasets/shuaidao"):
5 print(file)
6 image = cv2.imread("datasets/shuaidao/"+file)
7 cv2.imshow("test",image)
8 cv2.waitKey(1)
9 humans = e.inference(image, upsample_size=4.0)
10 try:
11 a = str(humans[0]).split("BodyPart:")
12 b = []
13 id = []
14 position = []
15 features=[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
16 for i in a:
17 try:
18 position.append(
19 float(str(i.split(" score")[0]).split("-")[1].replace("(", "").replace(")", "").split(", ")[0])
20 )
21 position.append(
22 float(str(i.split(" score")[0]).split("-")[1].replace("(", "").replace(")", "").split(", ")[1])
23 )
24 except:
25 pass
26 try:
27 id.append(
28 float(str(i.split(" score")[0]).split("-")[0]),
29 )
30 except:
31 pass
32 for t in range(len(id)):
33 features[int(2*id[t])]=position[2*t]
34 features[int(2 * id[t]+1)] =position[2*t+1]
35 avg_feat=round(sum(features)/len(features),3)
36 for i in range(len(features)):
37 if features[i]==0:
38 features[i]=avg_feat
39 f0.write(str(features)+"\n")
40 print(features)
41 except:
42 pass
43f0.close()

GCN图卷积神经网络
图神经网络常常用在对图模型的识别和训练上,这里我们通过修改使得他可以用于训练姿态识别的数据。
1.读取特征数据:
在第二步中将获取到的姿态特征保存成了txt文件中,现在分别对他们进行读入数据,代码如下:
1#读取特征数据
2x=[]
3y=[]
4f=open("shuaidao.txt")
5text=f.read()
6text=text.split("\n")
7for t in text:
8 try:
9 t=t.replace("]", "")
10 temp=t.replace("[","").split(",")
11 temp=[float(i) for i in temp]
12 x.append(temp)
13 y.append(1)
14 except:
15 pass
16f=open("common.txt")
17text=f.read()
18text=text.split("\n")
19for t in text:
20 try:
21 t=t.replace("]", "")
22 temp=t.replace("[","").split(",")
23 temp=[float(i) for i in temp]
24 x.append(temp)
25 y.append(0)
26 except:
27 pass
2.建立图数据:
建立函数为create_graph,通过dgl库建立图,图的节点数为输入数据的长度:
1def creat_graph():
2 g = dgl.DGLGraph()
3 g.add_nodes(len(x))
4 return g
3.建立图网络中的message方法和reduce方法:
基于节点的GCN利用消息传播(messagepropagation)来交换相邻节点之间的信息。这一过程可以在图的较大相邻范围内提取特征,其作用类似于卷积网络中的卷积层和池化层。由于该过程中不会有节点消失,因此基于节点的GCN扩展了感受野,并避免了局部位置信息出现损失。代码如下:
1# 主要定义message方法和reduce方法
2def gcn_message(edges):
3 return {'msg' : edges.src['h']}
4def gcn_reduce(nodes):
5 return {'h' : torch.sum(nodes.mailbox['msg'], dim=1)}
4.建立GCN层
以图为对象的基础上,建立图网络触发信息和节点特征设置功能:
1# 定义GCNLayer模块
2class GCNLayer(nn.Module):
3 def __init__(self, in_feats, out_feats):
4 super(GCNLayer, self).__init__()
5 self.linear = nn.Linear(in_feats, out_feats)
6 def forward(self, g, inputs):
7 # g 为图对象;inputs 为节点特征矩阵
8 # 设置图的节点特征
9 g.ndata['h'] = inputs
10 # 触发边的信息传递触发节点的聚合函数
11 g.send_and_recv(g.edges(), gcn_message, gcn_reduce)
12 # 取得节点向量
13 h = g.ndata.pop('h')
14 # 线性变换
15 return self.linear(h)
5.网络层搭建
设置一二层为GCN,激活函数使用relu激活函数。
1class GCN(nn.Module):
2 def __init__(self, in_feats, hidden_size, num_classes):
3 super(GCN, self).__init__()
4 self.gcn1 = GCNLayer(in_feats, hidden_size)
5 self.gcn2 = GCNLayer(hidden_size, num_classes)
6 def forward(self, g, inputs):
7 h = self.gcn1(g, inputs)
8 h = torch.relu(h)
9 h = self.gcn2(g, h)
10 return h
6.模型训练
建立优化器为adam优化器,学习率使用0.01。将读入的特征数据转成tensor类型,作为输入。迭代400次,并计算其中的损失输出:
1net = GCN(36, 8, 2)
2x=np.array(x)
3inputs = torch.from_numpy(x)
4inputs = torch.tensor(inputs, dtype=torch.float32)
5print(type(inputs))
6labeled_nodes = torch.tensor([0, 2])
7labels = torch.tensor([0, 1]) # 它们的标签是不同的
8optimizer = torch.optim.Adam(net.parameters(), lr=0.01)
9all_logits = []
10nx_G = G.to_networkx().to_undirected()
11pos = nx.kamada_kawai_layout(nx_G)
12print(inputs)
13for epoch in range(400):
14 logits = net(G, inputs)
15 #我们保存logit以便稍后进行可视化
16 all_logits.append(logits.detach())
17 logp = F.log_softmax(logits, 1)
18 # 我们只计算标记节点的损失
19 loss = F.nll_loss(logp[labeled_nodes], labels)
20 optimizer.zero_grad()
21 loss.backward()
22 optimizer.step()
23 print('Epoch %d | Loss: %.4f' % (epoch, loss.item()))
最终模型测试精度如下图可见:

图4 损失函数实验图
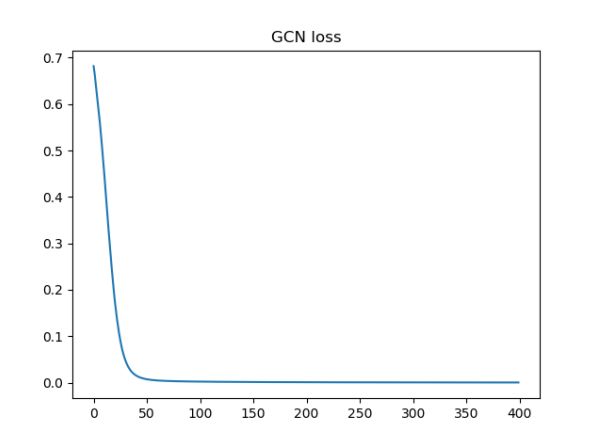
图5 损失函数变换曲线

图6 参考效果图
作者简介:李秋键,CSDN博客专家,CSDN达人课作者。硕士在读于中国矿业大学,开发有taptap竞赛获奖等。

更多精彩推荐
☞明年,我要用 AI 给全村写对联☞Ant Design 遭删库!☞每年节省170万美元的文档预览费用,借助机器学习的DropBox有多强?☞三年投 1000 亿,达摩院何以仗剑走天涯?点分享点收藏点点赞点在看