浅尝CNN之LeNet的原理简述及Python实现
今天是1024,大家的节日,最近在看CNN,所以来总结一下,顺带摸一个1024勋章,嘿嘿嘿!

LeNet-5模型是Yann LeCun教授与1998年在论文Gradient-based learning applied to document recognition中提出的,它是第一个成功应用于数字识别问题的卷积神经网络。
首先先甩上Yann LeCun教授的论文(是我见到的最长的论文):
链接:https://pan.baidu.com/s/1LVSCH7UlIF8OOHYgaufjzQ
提取码:ebcy
LeNet-5模型顾名思义共有5层,但分的细一些它一共有7层。第一层卷积层、第一层池化层、第二层卷积层、第二层池化层、第三层全连接层(卷积层)、第四层全连接层、第五层全连接输出。
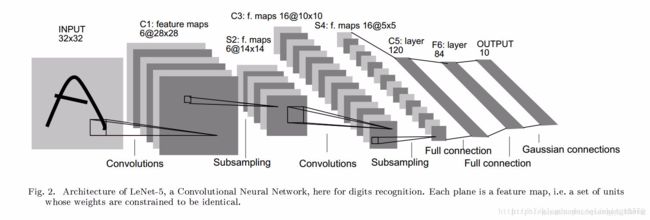
1、首先输入图像是单通道的2828大小的图像,用矩阵表示就是[28,28,1]
2、第一个卷积层conv1所用的卷积核尺寸为55,滑动步长为1,卷积核数目为6,那么经过该层后图像尺寸变为24,28-5+1=24,输出矩阵为[24,24,6]。
3、第一个池化层pool核尺寸为22,步长2,这是没有重叠的max pooling,池化操作后,图像尺寸减半,变为12×12,输出矩阵为[12,12,6]。
4、第二个卷积层conv2的卷积核尺寸为55,步长1,卷积核数目为16,卷积后图像尺寸变为8,这是因为12-5+1=8,输出矩阵为[8,8,16].
5、第二个池化层pool2核尺寸为2*2,步长2,这是没有重叠的max pooling,池化操作后,图像尺寸减半,变为4×4,输出矩阵为[4,4,16]。
6、pool2后面接全连接层fc1,神经元数目为120,再接relu激活函数。
7、再接全连接层fc2,神经元数目为84,再用relu激活函数。
8、添加一步dropout,防止过拟合。
9、最后接fc3,神经元个数为10,得到10维的特征向量,用于10个数字的分类训练,送入softmax分类,得到分类结果的概率output。
至于卷积核的大小,每一层卷积、池化的深度以及激活函数,我觉得都可以适当的改动,看一看效果。
以下是整体的训练代码,由于不想加班所以没有给出调用模型测试部分的代码,后续会补上。
'''
*Author :Jianfeng Zhang
*e-mail :[email protected]
*Blog :https://me.csdn.net/qq_39004111
*Github :https://github.com/JianfengZhang112358
*Data :2019.10.24
*Description:LeNet-5
'''
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import matplotlib.pyplot as plt
import pylab
import os
import time
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'#去除红色警告
mnist = input_data.read_data_sets("mnist_data", one_hot=True)#使用TensorFlow远程下载MNIST数据集,并且保存到当前文件夹下的mnist_data文件夹
'''
代码中的one_hot=True,表示将样本标签转化为one_hot编码。
举例来解释one_hot编码:假如一共有10类:0的one_hot为1000000000,1的ont_hot为0100000000,
2的one_hot为0010000000,依次类推。只要有一个位为1,1所在的位置就代表着第几类。
'''
#下面的代码可以打印出训练、测试、验证各数据集的数据和对应的标签数据
print('训练数据:',mnist.train.images)
print(mnist.train.images.shape)
print('测试数据:',mnist.test.images)
print(mnist.test.images.shape)
print('验证数据:',mnist.validation.images)
print(mnist.validation.images.shape)
print('训练集标签:',mnist.train.labels)
print(mnist.train.labels.shape)
print('测试集标签:',mnist.test.labels)
print(mnist.test.labels.shape)
print('验证集标签:',mnist.validation.labels)
print(mnist.validation.labels.shape)
#打印一幅训练集中的图片看一看
image = mnist.train.images[0]#读出第一幅图片数据1*784
image = image.reshape(-1,28)#重塑成28*28的像素矩阵
pylab.imshow(image)
pylab.show()
sess = tf.InteractiveSession()
# 1、权重初始化,偏置初始化
def weights(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
#2、卷积函数和最大池化函数
'''
tf.nn.conv2d是Tensorflow中的二维卷积函数,参数x是输入,w是卷积的参数
strides代表卷积模块移动的步长,都是1代表会不遗漏地划过图片的每一个点,padding代表边界的处理方式
padding = 'SAME',表示padding后卷积的图与原图尺寸一致,激活函数relu()
tf.nn.max_pool是Tensorflow中的最大池化函数,这里使用2 * 2 的最大池化,即将2 * 2 的像素降为1 * 1的像素
最大池化会保留原像素块中灰度值最高的那一个像素,即保留最显著的特征,因为希望整体缩小图片尺寸
ksize:池化窗口的大小,取一个四维向量,一般是[1,height,width,1]
因为我们不想再batch和channel上做池化,一般也是[1,stride,stride,1]
'''
def conv2d(x, W):
return tf.nn.conv2d(input=x, filter=W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
'''
这里的x,y_并不是特定的值,它们只是一个占位符,可以在TensorFlow运行某一计算时根据该占位符输入具体的值
输入图片x是一个2维的浮点数张量,这里分配给它的shape为[None, 784],784是一张展平的MNIST图片的维度
None 表示其值的大小不定,在这里作为第1个维度值,用以指代batch的大小,
输出类别y也是一个2维张量,其中每一行为一个10维的one_hot向量,用于代表某一MNIST图片的类别
'''
x = tf.placeholder(tf.float32, [None,784])
y = tf.placeholder(tf.float32,[None,10])
x_image = tf.reshape(x,[-1,28,28,1])#输入的图片整形成像素
# 1st layer: conv+relu+max_pool
w_conv1 = weights([5, 5, 1, 6])
b_conv1 = bias([6])
h_conv1 = tf.nn.relu(conv2d(x_image, w_conv1)+b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# 2nd layer: conv+relu+max_pool
w_conv2 = weights([5, 5, 6, 16])
b_conv2 = bias([16])
h_conv2 = tf.nn.relu(conv2d(h_pool1, w_conv2)+b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*16])
# 3rd layer: 3*full connection(convolution)
w_fc1 = weights([7*7*16, 120])
b_fc1 = bias([120])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, w_fc1)+b_fc1)
# 4rd layer:full connection
w_fc2 = weights([120, 84])
b_fc2 = bias([84])
h_fc2 = tf.nn.relu(tf.matmul(h_fc1, w_fc2)+b_fc2)
# dropout是在神经网络里面使用的方法,以此来防止过拟合
# 用一个placeholder来代表一个神经元的输出
# tf.nn.dropout操作除了可以屏蔽神经元的输出外,
# 还会自动处理神经元输出值的scale,所以用dropout的时候可以不用考虑scale
keep_prob = tf.placeholder(tf.float32, name="keep_prob")
h_fc1_drop = tf.nn.dropout(h_fc2, keep_prob)
# 5rd layer:Output full connection
w_fc3 = weights([84, 10])
b_fc3 = bias([10])
h_fc3 = tf.nn.softmax(tf.matmul(h_fc1_drop, w_fc3)+b_fc3)
cross_entropy = -tf.reduce_sum(y*tf.log(h_fc3))
train_step = tf.train.AdamOptimizer(1e-3).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(h_fc3, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, 'float'))
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver(max_to_keep=1)#保存最后一个模型
X = []
Y = []
#开始训练
t1 = time.time()
print('==================Start Training=================')
for i in range(1000):
batch = mnist.train.next_batch(60)
if i%100 == 0:
train_accuracy = accuracy.eval(session=sess, feed_dict={x: batch[0], y: batch[1],keep_prob:1.0})
print('step {}, training accuracy: {}'.format(i, train_accuracy))
X.append(60*i)
Y.append(train_accuracy)
train_step.run(session=sess, feed_dict={x: batch[0], y: batch[1],keep_prob:0.5})
print('test accuracy: {}'.format(accuracy.eval(session=sess, feed_dict={x: mnist.test.images, y:mnist.test.labels,keep_prob:1.0})))
model_path = "Model/LeNet-5.ckpt"
saver.save(sess,model_path)#保存模型于文件夹Model
t2 = time.time()
print('==================Finish Saving Model=================')
print('==================Finish Training=================')
print('==================Took Time:{}s================='.format(t2-t1))
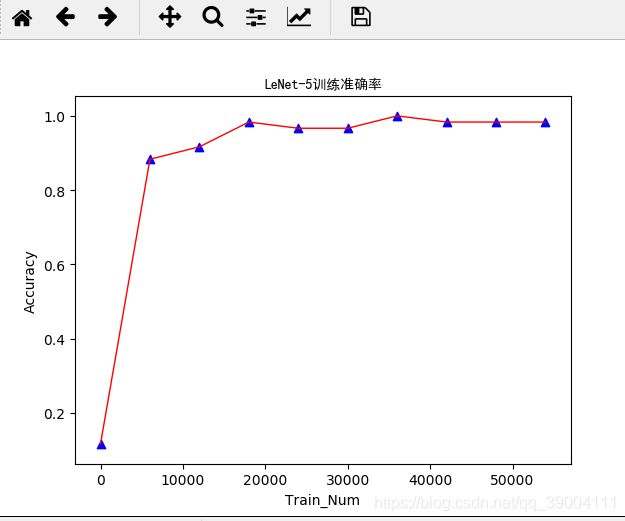
#画出训练曲线
plt.plot(X, Y, c='r', linewidth=1)
plt.scatter(X, Y, c='b', marker='^', linewidths=1)
plt.title(u"LeNet-5训练准确率", fontproperties='SimHei')
plt.xlabel("Train_Num")
plt.ylabel("Accuracy")
plt.legend()
plt.show()
python
在这里插入代码片
加载出来的原始数据集图片如下:
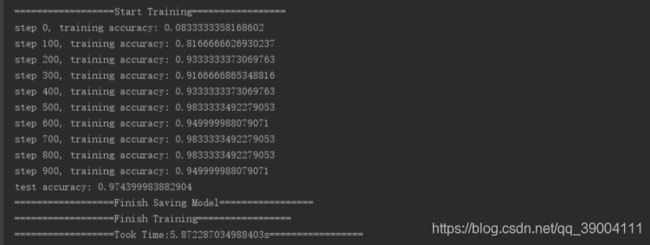
训练结果如下:
最终的准确率曲线如下:
参考了网上好多人的博客,还有我师兄的(https://me.csdn.net/chai_zheng),有问题的话欢迎大家交流。今天就先到这了,下班啦,吼吼吼。