【Apache Spark 】第 10 章使用 MLlib 进行机器学习
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
什么是机器学习?
监督学习
无监督学习
为什么使用 Spark 进行机器学习?
设计机器学习管道
数据摄取和探索
创建训练和测试数据集
使用 Transformer 准备功能
了解线性回归
使用 Estimator 构建模型
创建管道
One-hot编码
评估模型
均方根误差
R2
保存和加载模型
超参数调优
基于树的模型
决策树
随机森林
k折交叉验证
优化管道
概括
到目前为止,我们一直专注于使用 Apache Spark 的数据工程工作负载。数据工程通常是为机器学习 (ML) 任务准备数据的前期步骤,这将是本章的重点。我们生活在一个机器学习和人工智能应用程序已成为我们生活中不可或缺的一部分的时代。无论我们是否意识到,我们每天都可能出于在线购物推荐和广告、欺诈检测、分类、图像识别、模式匹配等目的而接触 ML 模型。这些 ML 模型推动了许多公司的重要业务决策。根据麦肯锡的这项研究,35% 的消费者在亚马逊上购买的内容和 75% 的在 Netflix 上观看的内容是由基于机器学习的产品推荐驱动的。建立一个表现良好的模型可以成就或破坏公司。
在本章中,我们将帮助您开始使用MLlib构建 ML 模型,MLlib是 Apache Spark 中事实上的机器学习库。我们将从机器学习的简要介绍开始,然后介绍分布式机器学习和大规模特征工程的最佳实践(如果您已经熟悉机器学习基础知识,可以直接跳到“设计机器学习管道”)。通过此处提供的简短代码片段和本书GitHub存储库中提供的笔记本,您将学习如何构建基本的 ML 模型和使用 MLlib。
笔记
本章涵盖了 Scala 和 Python API;如果您有兴趣将 R ( sparklyr) 与 Spark 一起用于机器学习,我们邀请您查看Javier Luraschi、Kevin Kuo 和 Edgar Ruiz (O'Reilly) 的Mastering Spark with R。
什么是机器学习?
这些天机器学习得到了很多炒作——但它到底是什么?从广义上讲,机器学习是一个使用统计、线性代数和数值优化从数据中提取模式的过程。机器学习可应用于预测功耗、确定视频中是否有猫或对具有相似特征的项目进行聚类等问题。
机器学习有几种类型,包括监督学习、半监督学习、无监督学习和强化学习。本章将主要关注有监督的机器学习,仅涉及无监督学习。在我们深入研究之前,让我们简要讨论有监督和无监督 ML 之间的区别。
监督学习
在监督机器学习中,您的数据由一组输入记录组成,每个记录都有关联的标签,目标是在给定新的未标记输入的情况下预测输出标签。这些输出标签可以是离散的或连续的,这将我们带到了两种类型的监督机器学习:分类和回归。
在分类问题中,目标是将输入分成一组离散的类或标签。对于二元分类,您要预测两个离散的标签,例如“狗”或“非狗”,如图 10-1 所示。
图 10-1。二进制分类示例:dog or not dog
使用multiclass,也称为多项式分类,可以有三个或更多离散标签,例如预测狗的品种(例如,澳大利亚牧羊犬、金毛猎犬或贵宾犬,如图 10-2所示)。

图 10-2。多项分类示例:澳大利亚牧羊犬、金毛猎犬或贵宾犬
在回归问题中,要预测的值是一个连续数字,而不是一个标签。这意味着您可以预测模型在训练期间没有看到的值,如图 10-3所示。例如,您可以建立一个模型来预测给定温度的每日冰淇淋销量。您的模型可能会预测价值 77.67 美元,即使它所训练的输入/输出对都不包含该价值。

图 10-3。回归示例:根据温度预测冰淇淋销量
表 10-1列出了一些在Spark MLlib中可用的常用监督机器学习算法,并说明它们是否可用于回归、分类或两者兼有.
| 算法 | 典型用法 |
|---|---|
| 线性回归 | 回归 |
| 逻辑回归 | 分类(我们知道,它的名字有回归!) |
| 决策树 | 两个都 |
| 梯度增强树 | 两个都 |
| 随机森林 | 两个都 |
| 朴素贝叶斯 | 分类 |
| 支持向量机 (SVM) | 分类 |
无监督学习
获得监督机器学习所需的标记数据可能非常昂贵和/或不可行。这就是无监督机器学习发挥作用的地方。无监督机器学习不是预测标签,而是帮助您更好地理解数据的结构。
例如,考虑图 10-4左侧的原始未聚类数据。每个数据点 ( x 1 , x 2 ) 都没有已知的真实标签,但通过对我们的数据应用无监督机器学习,我们可以找到自然形成的集群,如右图所示。
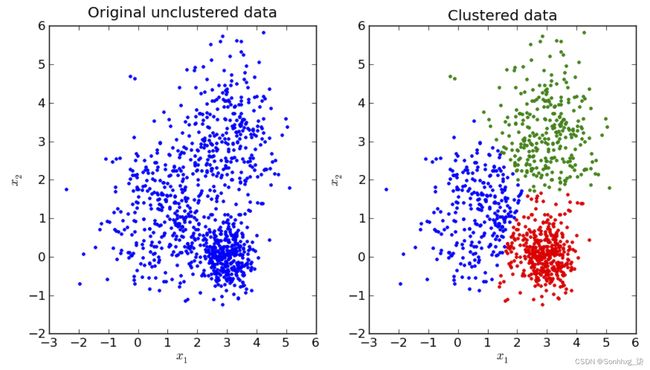
图 10-4。聚类示例
无监督机器学习可用于异常值检测或作为监督机器学习的预处理步骤——例如,减少数据集的维数(即每个数据的维数),这对于降低存储需求或简化下游很有用任务。MLlib 中的一些无监督机器学习算法包括k均值、潜在狄利克雷分配 (LDA) 和高斯混合模型。
为什么使用 Spark 进行机器学习?
Spark 是一个统一的分析引擎,它为数据摄取、特征工程、模型训练和部署提供了一个生态系统。如果没有 Spark,开发人员将需要许多不同的工具来完成这组任务,并且可能仍然难以实现可扩展性。
Spark 有两个机器学习包:spark.mllib和spark.ml. spark.mllib是基于 RDD API(自 Spark 2.0 以来一直处于维护模式)的原始机器学习 API,spark.ml而是基于 DataFrames 的较新 API。本章的其余部分将重点介绍如何使用该spark.ml包以及如何在 Spark 中设计机器学习管道。但是,我们使用“MLlib”作为总称来指代 Apache Spark 中的两个机器学习库包。
借助spark.ml,数据科学家可以使用一个生态系统进行数据准备和模型构建,而无需对数据进行下采样以适应单台机器。spark.ml专注于 O( n ) 横向扩展,其中模型随您拥有的数据点数量线性扩展,因此它可以扩展到大量数据。在下一章中,我们将讨论在分布式框架(如( ))spark.ml和单节点框架(如)之间进行选择时所涉及的一些权衡。如果您以前使用过,其中的许多 API会感觉很熟悉,但我们将讨论一些细微的差异。scikit-learnsklearnscikit-learnspark.ml
设计机器学习管道
在本节中,我们将介绍如何创建和调整 ML 管道。管道的概念在许多 ML 框架中很常见,作为组织一系列操作以应用于您的数据的一种方式。在 MLlib 中,Pipeline API提供了一个构建在 DataFrames 之上的高级 API 来组织您的机器学习工作流。Pipeline API 由一系列转换器和估计器组成,我们将在后面深入讨论。
在本章中,我们将使用来自Inside Airbnb的旧金山住房数据集。它包含有关旧金山 Airbnb 租金的信息,例如卧室数量、位置、评论分数等,我们的目标是建立一个模型来预测该城市房源的每晚租金价格。这是一个回归问题,因为价格是一个连续变量。我们将指导您完成数据科学家解决此问题时所经历的工作流程,包括特征工程、构建模型、超参数调整和评估模型性能。这个数据集非常混乱并且很难建模(就像大多数真实世界的数据集一样!),所以如果你自己进行实验,如果你的早期模型不是很好,不要感到难过。
本章的目的不是向您展示 MLlib 中的每个 API,而是为您提供开始使用 MLlib 构建端到端管道的技能和知识。在进入细节之前,让我们定义一些 MLlib 术语:
Transformer
接受一个 DataFrame 作为输入,并返回一个新的 DataFrame,其中附加了一个或多个列。Transformers 不会从您的数据中学习任何参数,而只是应用基于规则的转换来准备数据以进行模型训练或使用经过训练的 MLlib 模型生成预测。他们有一个.transform()方法。
Estimator
通过方法从 DataFrame 中学习(或“拟合”)参数.fit()并返回 a Model,它是一个转换器。
Pipeline
将一系列转换器和估计器组织成一个模型。虽然管道本身是估计器,但输出pipeline.fit()返回PipelineModel一个变压器。
虽然这些概念现在看起来相当抽象,但本章中的代码片段和示例将帮助您了解它们是如何组合在一起的。但在我们构建 ML 模型并使用转换器、估计器和管道之前,我们需要加载数据并执行一些数据准备。
数据摄取和探索
我们对示例数据集中的数据进行了轻微预处理,以去除异常值(例如,Airbnb 发布的价格为 0 美元/晚),将所有整数转换为双精度数,并从一百多个字段中选择一个信息子集。此外,对于我们的数据列中任何缺失的数值,我们已经估算了中值并添加了一个指示列(列名后跟_na,例如bedrooms_na)。这样,ML 模型或人工分析师可以将该列中的任何值解释为估算值,而不是真实值。您可以在本书的GitHub存储库中查看数据准备笔记本。请注意,还有许多其他方法可以处理缺失值,这超出了本书的范围。
让我们快速浏览一下数据集和相应的模式(输出仅显示列的子集):
# In Python
filePath = """/databricks-datasets/learning-spark-v2/sf-airbnb/
sf-airbnb-clean.parquet/"""
airbnbDF = spark.read.parquet(filePath)
airbnbDF.select("neighbourhood_cleansed", "room_type", "bedrooms", "bathrooms",
"number_of_reviews", "price").show(5)// In Scala
val filePath =
"/databricks-datasets/learning-spark-v2/sf-airbnb/sf-airbnb-clean.parquet/"
val airbnbDF = spark.read.parquet(filePath)
airbnbDF.select("neighbourhood_cleansed", "room_type", "bedrooms", "bathrooms",
"number_of_reviews", "price").show(5)
+----------------------+---------------+--------+---------+----------+-----+
|neighbourhood_cleansed| room_type|bedrooms|bathrooms|number_...|price|
+----------------------+---------------+--------+---------+----------+-----+
| Western Addition|Entire home/apt| 1.0| 1.0| 180.0|170.0|
| Bernal Heights|Entire home/apt| 2.0| 1.0| 111.0|235.0|
| Haight Ashbury| Private room| 1.0| 4.0| 17.0| 65.0|
| Haight Ashbury| Private room| 1.0| 4.0| 8.0| 65.0|
| Western Addition|Entire home/apt| 2.0| 1.5| 27.0|785.0|
+----------------------+---------------+--------+---------+----------+-----+我们的目标是根据我们的功能预测出租物业的每晚价格。
笔记
在数据科学家开始建模之前,他们需要探索和理解他们的数据。他们通常会使用 Spark 对数据进行分组,然后使用matplotlib等数据可视化库来可视化数据。我们将把数据探索作为练习留给读者。
创建训练和测试数据集
在开始特征工程和建模之前,我们会将数据集分为两组:训练和测试. 根据数据集的大小,您的训练/测试比率可能会有所不同,但许多数据科学家使用 80/20 作为标准的训练/测试分割。您可能想知道,“为什么不使用整个数据集来训练模型?” 问题是,如果我们在整个数据集上构建模型,该模型可能会记住或“过度拟合”我们提供的训练数据,并且我们将没有更多数据来评估它对之前的泛化效果如何看不见的数据。假设数据遵循相似的分布,模型在测试集上的性能代表了它在看不见的数据(即在野外或生产中)上的表现。这种拆分如图 10-5 所示。
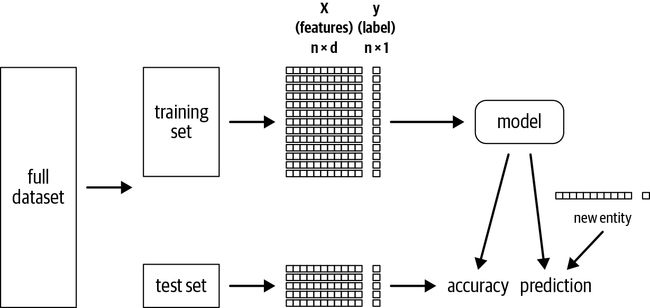
图 10-5。训练/测试拆分
我们的训练集由一组特征 X 和一个标签 y 组成。这里我们使用大写的 X 来表示维度为 n x d的矩阵,其中n是数据点(或示例)的数量, d是特征的数量(这就是我们在 DataFrame 中所说的字段或列)。我们使用小写的 y 来表示一个向量,维度为 n x 1;对于每个示例,都有一个标签。
不同的指标用于衡量模型的性能。对于分类问题,标准度量是正确预测的准确性或百分比。一旦模型在使用该指标的训练集上具有令人满意的性能,我们就会将该模型应用于我们的测试集。如果它根据我们的评估指标在我们的测试集上表现良好,那么我们可以确信我们已经建立了一个可以“泛化”到看不见的数据的模型。
对于我们的 Airbnb 数据集,我们将保留 80% 的数据用于训练集,并留出 20% 的数据用于测试集。此外,我们将为可重复性设置一个随机种子,这样如果我们重新运行此代码,我们将分别获得相同的数据点进入我们的训练和测试数据集。种子本身的价值无关紧要,但数据科学家通常喜欢将其设置为 42,因为这是生命终极问题的答案:
# In Python
trainDF, testDF = airbnbDF.randomSplit([.8, .2], seed=42)
print(f"""There are {trainDF.count()} rows in the training set,
and {testDF.count()} in the test set""")// In Scala
val Array(trainDF, testDF) = airbnbDF.randomSplit(Array(.8, .2), seed=42)
println(f"""There are ${trainDF.count} rows in the training set, and
${testDF.count} in the test set""")这会产生以下输出:
There are 5780 rows in the training set, and 1366 in the test set
但是如果我们改变 Spark 集群中的执行器数量会发生什么?Catalyst 优化器根据集群资源和数据集大小确定分区数据的最佳方式。鉴于 Spark DataFrame 中的数据是行分区的,并且每个 worker 独立于其他 worker 执行其拆分,如果分区中的数据发生更改,则拆分 (by randomSplit()) 的结果将不一样。
虽然您可以修复集群配置和种子以确保获得一致的结果,但我们的建议是将您的数据拆分一次,然后将其写入自己的训练/测试文件夹,这样您就不会遇到这些可重复性问题.
笔记
在您的探索性分析期间,您应该缓存训练数据集,因为您将在整个机器学习过程中多次访问它。请参考第 7 章“数据的缓存和持久化”部分。
使用 Transformer 准备功能
现在我们已经将数据分成训练集和测试集,让我们准备数据以建立一个线性回归模型来预测给定卧室数量的价格。在后面的示例中,我们将包含所有相关的功能,但现在让我们确保我们有适当的机制。线性回归(与 Spark 中的许多其他算法一样)要求所有输入特征都包含在 DataFrame 的单个向量中。因此,我们需要转换我们的数据。
Spark 中的 Transformer 接受一个 DataFrame 作为输入,并返回一个新的 DataFrame,其中附加了一个或多个列。transform()他们不会从您的数据中学习,而是使用该方法应用基于规则的转换。
为了将我们所有的特征放入一个向量中,我们将使用VectorAssembler转换器。VectorAssembler获取输入列列表并创建一个带有附加列的新 DataFrame,我们将其称为features. 它将这些输入列的值组合成一个向量:
# In Python
from pyspark.ml.feature import VectorAssembler
vecAssembler = VectorAssembler(inputCols=["bedrooms"], outputCol="features")
vecTrainDF = vecAssembler.transform(trainDF)
vecTrainDF.select("bedrooms", "features", "price").show(10)// In Scala
import org.apache.spark.ml.feature.VectorAssembler
val vecAssembler = new VectorAssembler()
.setInputCols(Array("bedrooms"))
.setOutputCol("features")
val vecTrainDF = vecAssembler.transform(trainDF)
vecTrainDF.select("bedrooms", "features", "price").show(10)
+--------+--------+-----+
|bedrooms|features|price|
+--------+--------+-----+
| 1.0| [1.0]|200.0|
| 1.0| [1.0]|130.0|
| 1.0| [1.0]| 95.0|
| 1.0| [1.0]|250.0|
| 3.0| [3.0]|250.0|
| 1.0| [1.0]|115.0|
| 1.0| [1.0]|105.0|
| 1.0| [1.0]| 86.0|
| 1.0| [1.0]|100.0|
| 2.0| [2.0]|220.0|
+--------+--------+-----+您会注意到,在 Scala 代码中,我们必须实例化新VectorAssembler对象以及使用 setter 方法来更改输入和输出列。在 Python 中,您可以选择直接将参数传递给构造函数VectorAssembler或使用 setter 方法,但在 Scala 中,您只能使用 setter 方法。
接下来我们将介绍线性回归的基础知识,但如果您已经熟悉该算法,请跳至“使用估计器构建模型”。
了解线性回归
线性回归对因变量(或标签)与一个或多个自变量(或特征)之间的线性关系建模。在我们的例子中,我们想要拟合一个线性回归模型来预测给定卧室数量的 Airbnb 租金价格。
在图 10-6中,我们有一个特征x和一个输出y(这是我们的因变量)。线性回归试图拟合x和y的直线方程,对于标量变量,可以表示为y = mx + b,其中m是斜率,b是偏移量或截距。
点表示我们数据集中的真实 ( x , y ) 对,实线表示最适合该数据集的线。数据点并没有完美对齐,所以我们通常认为线性回归将模型拟合到 y ≈ mx + b + ε,其中 ε (epsilon) 是每条记录x独立绘制的误差从一些分布。这些是我们的模型预测与真实值之间的误差。通常我们认为 ε 是高斯分布的或正态分布的。回归线上方的垂直线表示正 ε(或残差),其中您的真实值高于预测值,回归线下方的垂直线表示负残差。线性回归的目标是找到一条最小化这些残差平方的线。您会注意到,这条线可以推断出它没有看到的数据点的预测。
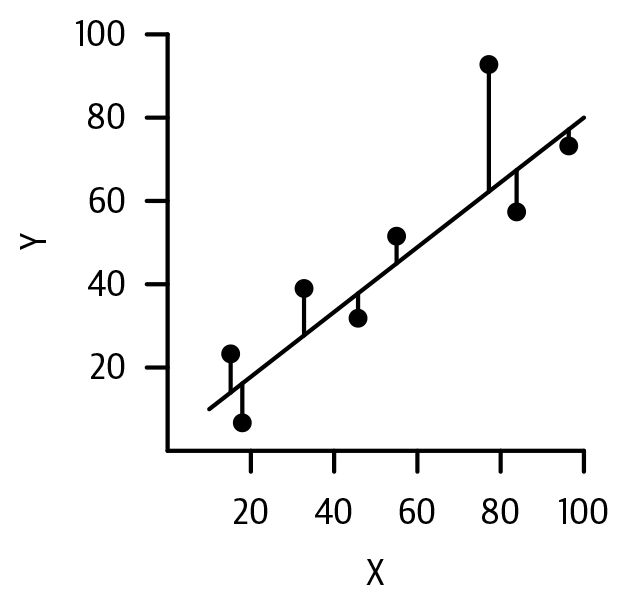
图 10-6。单变量线性回归
线性回归也可以扩展到处理多个自变量。如果我们有三个特征作为输入,x = [ x 1 , x 2 , x 3 ],那么我们可以将 y 建模为y ≈ w 0 + w 1 x 1 + w 2 x 2 + w 3 x 3 + ε。在这种情况下,每个特征都有一个单独的系数(或权重)和一个截距(w 0而不是b这里)。为我们的模型估计系数和截距的过程称为学习(或拟合)模型的参数。现在,我们将专注于在给定卧室数量的情况下预测价格的单变量回归示例,稍后我们将回到多元线性回归。
使用 Estimator 构建模型
设置好之后vectorAssembler,我们准备好数据并将其转换为线性回归模型所期望的格式。在 Spark 中,LinearRegression是一种估计器——它接收一个 DataFrame 并返回一个Model. Estimator 从你的数据中学习参数,有一个estimator_name.fit()方法,并被热切地评估(即,启动 Spark 作业),而 Transformer 被懒惰地评估。估计量的其他一些示例包括Imputer、DecisionTreeClassifier和RandomForestRegressor。
您会注意到线性回归 ( features) 的输入列是我们的输出vectorAssembler:
# In Python
from pyspark.ml.regression import LinearRegression
lr = LinearRegression(featuresCol="features", labelCol="price")
lrModel = lr.fit(vecTrainDF)// In Scala
import org.apache.spark.ml.regression.LinearRegression
val lr = new LinearRegression()
.setFeaturesCol("features")
.setLabelCol("price")
val lrModel = lr.fit(vecTrainDF)lr.fit()返回一个LinearRegressionModel( lrModel),它是一个转换器。换句话说,估计器fit()方法的输出是一个转换器。一旦估计器学习了参数,转换器就可以将这些参数应用于新的数据点以生成预测。让我们检查一下它学到的参数:
# In Python
m = round(lrModel.coefficients[0], 2)
b = round(lrModel.intercept, 2)
print(f"""The formula for the linear regression line is
price = {m}*bedrooms + {b}""")// In Scala
val m = lrModel.coefficients(0)
val b = lrModel.intercept
println(f"""The formula for the linear regression line is
price = $m%1.2f*bedrooms + $b%1.2f""")这打印:
The formula for the linear regression line is price = 123.68*bedrooms + 47.51
创建管道
如果我们想将我们的模型应用于我们的测试集,那么我们需要以与训练集相同的方式准备该数据(即,将其传递给向量组装器)。通常,数据准备管道会有多个步骤,不仅要记住要应用哪些步骤,还要记住步骤的顺序,这变得很麻烦。这是Pipeline API的动机:您只需按顺序指定您希望数据通过的阶段,Spark 会为您处理处理。它们为用户提供了更好的代码可重用性和组织性。在 Spark 中,Pipelines 是估计器,而 s——PipelineModel拟合Pipeline的 s——是变换器。
现在让我们构建我们的管道:
# In Python
from pyspark.ml import Pipeline
pipeline = Pipeline(stages=[vecAssembler, lr])
pipelineModel = pipeline.fit(trainDF)// In Scala
import org.apache.spark.ml.Pipeline
val pipeline = new Pipeline().setStages(Array(vecAssembler, lr))
val pipelineModel = pipeline.fit(trainDF)使用 Pipeline API 的另一个优点是它可以为您确定哪些阶段是估算器/转换器,因此您不必担心为每个阶段指定name.fit()与否。name.transform()
由于pipelineModel是一个转换器,因此也可以直接将其应用于我们的测试数据集:
# In Python
predDF = pipelineModel.transform(testDF)
predDF.select("bedrooms", "features", "price", "prediction").show(10)// In Scala
val predDF = pipelineModel.transform(testDF)
predDF.select("bedrooms", "features", "price", "prediction").show(10)
+--------+--------+------+------------------+
|bedrooms|features| price| prediction|
+--------+--------+------+------------------+
| 1.0| [1.0]| 85.0|171.18598011578285|
| 1.0| [1.0]| 45.0|171.18598011578285|
| 1.0| [1.0]| 70.0|171.18598011578285|
| 1.0| [1.0]| 128.0|171.18598011578285|
| 1.0| [1.0]| 159.0|171.18598011578285|
| 2.0| [2.0]| 250.0|294.86172649777757|
| 1.0| [1.0]| 99.0|171.18598011578285|
| 1.0| [1.0]| 95.0|171.18598011578285|
| 1.0| [1.0]| 100.0|171.18598011578285|
| 1.0| [1.0]|2010.0|171.18598011578285|
+--------+--------+------+------------------+在这段代码中,我们只使用一个特性构建了一个模型(您可以在本书的GitHubbedrooms存储库中找到本章的笔记本)。但是,您可能希望使用所有特征构建模型,其中一些特征可能是分类的,例如. 分类特征采用离散值并且没有内在顺序——例如职业或国家名称。在下一节中,我们将考虑如何处理这些类型的变量的解决方案,称为one-hot encoding。host_is_superhost
One-hot编码
在我们刚刚创建的管道中,我们只有两个阶段,我们的线性回归模型只使用了一个特征。让我们看看如何构建一个稍微复杂一点的管道,它包含我们所有的数字和分类特征。
MLlib 中的大多数机器学习模型都期望数值作为输入,以向量表示。要将分类值转换为数值,我们可以使用一种称为单热编码 (OHE) 的技术。假设我们有一个名为的列Animal,我们有三种类型的动物:Dog、Cat和Fish。我们不能直接将字符串类型传递到我们的 ML 模型中,因此我们需要分配一个数字映射,例如:
Animal = {"Dog", "Cat", "Fish"}
"Dog" = 1, "Cat" = 2, "Fish" = 3但是,使用这种方法,我们在数据集中引入了一些以前没有的虚假关系。例如,为什么我们分配Cat两倍的值Dog?我们使用的数值不应该在我们的数据集中引入任何关系。相反,我们希望为列中的每个不同值创建一个单独的Animal列:
"Dog" = [ 1, 0, 0]
"Cat" = [ 0, 1, 0]
"Fish" = [0, 0, 1]如果动物是狗,它在第一列有一个,在其他地方有一个零。如果它是一只猫,它在第二列有一个 1,在其他列有 0。列的顺序无关紧要。如果您以前使用过 pandas,您会注意到这与pandas.get_dummies().
如果我们有一个拥有 300 只动物的动物园,OHE 会大量增加内存/计算资源的消耗吗?不是 Spark!SparseVector当大多数条目是时,Spark 在内部使用 a 0,就像 OHE 之后的情况一样,因此它不会浪费存储0值的空间。让我们看一个例子来更好地理解SparseVectors 是如何工作的:
DenseVector(0, 0, 0, 7, 0, 2, 0, 0, 0, 0)
SparseVector(10, [3, 5], [7, 2])此DenseVector示例中的 包含 10 个值,其中除了 2 个之外都是0. 要创建SparseVector,我们需要跟踪向量的大小、非零元素的索引以及这些索引处的相应值。在此示例中,向量的大小为 10,索引 3 和 5 处有两个非零值,并且这些索引处的对应值是 7 和 2。
有几种方法可以使用 Spark 对数据进行一次热编码。一种常见的方法是使用StringIndexerand OneHotEncoder。使用这种方法,第一步是应用StringIndexer估计器将分类值转换为类别索引。这些类别索引按标签频率排序,因此最频繁的标签获得索引 0,这为我们提供了跨相同数据的各种运行的可重现结果。
创建类别索引后,您可以将它们作为输入传递给OneHotEncoder(OneHotEncoderEstimator如果使用 Spark 2.3/2.4)。将OneHotEncoder一列类别索引映射到一列二进制向量。查看表 10-2 ,了解Spark 2.3/2.4 到 3.0StringIndexer和API的差异。OneHotEncoder
| Spark 2.3 和 2.4 | Spark 3.0 | |
|---|---|---|
StringIndexer |
单列作为输入/输出 | 多列作为输入/输出 |
OneHotEncoder |
已弃用 | 多列作为输入/输出 |
OneHotEncoderEstimator |
多列作为输入/输出 | 不适用 |
以下代码演示了如何对我们的分类特征进行 one-hot 编码。在我们的数据集中,任何类型的列都string被视为分类特征,但有时您可能希望将数字特征视为分类特征,反之亦然。您需要仔细确定哪些列是数字的,哪些是分类的:
# In Python
from pyspark.ml.feature import OneHotEncoder, StringIndexer
categoricalCols = [field for (field, dataType) in trainDF.dtypes
if dataType == "string"]
indexOutputCols = [x + "Index" for x in categoricalCols]
oheOutputCols = [x + "OHE" for x in categoricalCols]
stringIndexer = StringIndexer(inputCols=categoricalCols,
outputCols=indexOutputCols,
handleInvalid="skip")
oheEncoder = OneHotEncoder(inputCols=indexOutputCols,
outputCols=oheOutputCols)
numericCols = [field for (field, dataType) in trainDF.dtypes
if ((dataType == "double") & (field != "price"))]
assemblerInputs = oheOutputCols + numericCols
vecAssembler = VectorAssembler(inputCols=assemblerInputs,
outputCol="features")// In Scala
import org.apache.spark.ml.feature.{OneHotEncoder, StringIndexer}
val categoricalCols = trainDF.dtypes.filter(_._2 == "StringType").map(_._1)
val indexOutputCols = categoricalCols.map(_ + "Index")
val oheOutputCols = categoricalCols.map(_ + "OHE")
val stringIndexer = new StringIndexer()
.setInputCols(categoricalCols)
.setOutputCols(indexOutputCols)
.setHandleInvalid("skip")
val oheEncoder = new OneHotEncoder()
.setInputCols(indexOutputCols)
.setOutputCols(oheOutputCols)
val numericCols = trainDF.dtypes.filter{ case (field, dataType) =>
dataType == "DoubleType" && field != "price"}.map(_._1)
val assemblerInputs = oheOutputCols ++ numericCols
val vecAssembler = new VectorAssembler()
.setInputCols(assemblerInputs)
.setOutputCol("features")现在您可能想知道,“如何StringIndexer处理出现在测试数据集中但不在训练数据集中的新类别?” 有一个handleInvalid参数指定您要如何处理它们。选项是skip(过滤掉包含无效数据的行)、error(抛出错误)或keep(将无效数据放入特殊的附加存储桶中,位于索引处numLabels)。对于这个例子,我们只是跳过了无效记录。
这种方法的一个困难是您需要StringIndexer明确地告诉哪些特征应该被视为分类特征。您可以使用它VectorIndexer来自动检测所有分类变量,但它的计算成本很高,因为它必须遍历每一列并检测它是否具有少于maxCategories不同的值。maxCategories是用户指定的参数,确定这个值也很困难。
另一种方法是使用RFormula. 其语法受到 R 编程语言的启发。使用RFormula,您可以提供您的标签以及您想要包含的功能。它支持有限的 R 运算符子集,包括~、.、:、+和-。例如,您可以指定formula = "y ~ bedrooms + bathrooms",这意味着预测y给定的bedrooms和bathrooms,或者formula = "y ~ .",这意味着使用所有可用的特征(并自动y从特征中排除)。RFormula将自动StringIndex和 OHE 您的所有string列,将您的数字列转换为double类型,并使用将所有这些组合成一个向量VectorAssembler在引擎盖下。因此,我们可以用一行代码替换前面的所有代码,我们将得到相同的结果:
# In Python
from pyspark.ml.feature import RFormula
rFormula = RFormula(formula="price ~ .",
featuresCol="features",
labelCol="price",
handleInvalid="skip")// In Scala
import org.apache.spark.ml.feature.RFormula
val rFormula = new RFormula()
.setFormula("price ~ .")
.setFeaturesCol("features")
.setLabelCol("price")
.setHandleInvalid("skip")RFormula自动组合StringIndexer和的缺点OneHotEncoder是所有算法都不需要或不推荐使用 one-hot 编码。例如,如果您仅将StringIndexer用于分类特征,则基于树的算法可以直接处理分类变量。您不需要一次性对基于树的方法的分类特征进行编码,这通常会使您的基于树的模型变得更糟。不幸的是,特征工程没有万能的解决方案,理想的方法与您计划应用于数据集的下游算法密切相关。
笔记
如果其他人为您执行特征工程,请确保他们记录了他们如何生成这些特征。
编写代码来转换数据集后,您可以使用所有特征作为输入来添加线性回归模型。
在这里,我们将所有的特征准备和模型构建放入管道中,并将其应用于我们的数据集:
# In Python
lr = LinearRegression(labelCol="price", featuresCol="features")
pipeline = Pipeline(stages = [stringIndexer, oheEncoder, vecAssembler, lr])
# Or use RFormula
# pipeline = Pipeline(stages = [rFormula, lr])
pipelineModel = pipeline.fit(trainDF)
predDF = pipelineModel.transform(testDF)
predDF.select("features", "price", "prediction").show(5)// In Scala
val lr = new LinearRegression()
.setLabelCol("price")
.setFeaturesCol("features")
val pipeline = new Pipeline()
.setStages(Array(stringIndexer, oheEncoder, vecAssembler, lr))
// Or use RFormula
// val pipeline = new Pipeline().setStages(Array(rFormula, lr))
val pipelineModel = pipeline.fit(trainDF)
val predDF = pipelineModel.transform(testDF)
predDF.select("features", "price", "prediction").show(5)
+--------------------+-----+------------------+
| features|price| prediction|
+--------------------+-----+------------------+
|(98,[0,3,6,7,23,4...| 85.0| 55.80250714362137|
|(98,[0,3,6,7,23,4...| 45.0| 22.74720286761658|
|(98,[0,3,6,7,23,4...| 70.0|27.115811183814913|
|(98,[0,3,6,7,13,4...|128.0|-91.60763412465076|
|(98,[0,3,6,7,13,4...|159.0| 94.70374072351933|
+--------------------+-----+------------------+如您所见,特征列表示为SparseVector. one-hot 编码后有 98 个特征,然后是非零索引,然后是值本身。truncate=False如果你传入 . 你可以看到整个输出show()。
我们的模型表现如何?您可以看到,虽然一些预测可能被认为是“接近”,但其他预测则相距甚远(租金为负价!?)。接下来,我们将通过数值评估我们的模型在整个测试集上的表现如何.
评估模型
现在我们已经建立了一个模型,我们需要评估它的性能。其中spark.ml有分类、回归、聚类和排名评估器(在 Spark 3.0 中引入)。鉴于这是一个回归问题,我们将使用均方根误差 (RMSE)和R 2(发音为“R-squared”)来评估我们模型的性能。
均方根误差
RMSE 是一个范围从零到无穷大的度量。越接近零越好。
让我们一步一步地看一下数学公式:
-
计算真实值y i和预测值ŷ i之间的差异(或误差)(读作y -hat,其中“帽子”表示它是帽子下数量的预测值):

-
将y i和ŷ i之间的差平方,这样我们的正负残差就不会抵消。这称为平方误差:
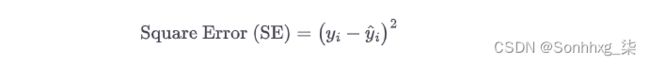
-
然后我们将所有n个数据点的平方误差相加,称为误差平方和 (SSE) 或残差平方和:

-
但是,SSE 会随着数据集中记录数n的增加而增长,因此我们希望通过记录数对其进行归一化。为我们提供了均方误差 (MSE),这是一种非常常用的回归度量:

-
如果我们停在 MSE,那么我们的误差项就在unit 2的范围内。我们通常会取 MSE 的平方根来将误差恢复到原始单位的范围内,这给了我们均方根误差 (RMSE):

让我们使用 RMSE 评估我们的模型:
# In Python
from pyspark.ml.evaluation import RegressionEvaluator
regressionEvaluator = RegressionEvaluator(
predictionCol="prediction",
labelCol="price",
metricName="rmse")
rmse = regressionEvaluator.evaluate(predDF)
print(f"RMSE is {rmse:.1f}")// In Scala
import org.apache.spark.ml.evaluation.RegressionEvaluator
val regressionEvaluator = new RegressionEvaluator()
.setPredictionCol("prediction")
.setLabelCol("price")
.setMetricName("rmse")
val rmse = regressionEvaluator.evaluate(predDF)
println(f"RMSE is $rmse%.1f")这会产生以下输出:
RMSE is 220.6
解释 RMSE 的值
那么我们如何知道 220.6 是否是 RMSE 的一个好值呢?有多种方法可以解释这个值,其中一种是建立一个简单的基线模型并计算其 RMSE 以进行比较。回归任务的一个常见基线模型是计算训练集上标签的平均值? (发音为y -bar),然后预测测试数据集中每条记录的 ? 并计算生成的 RMSE(示例代码可在本书的GitHub 存储库)。如果你试试这个,你会看到我们的基线模型的 RMSE 为 240.7,所以我们超过了基线。如果您没有超过基线,那么您的模型构建过程可能出现了问题。
笔记
如果这是一个分类问题,您可能希望预测最流行的类作为您的基线模型。
请记住,标签的单位直接影响您的 RMSE。例如,如果您的标签是高度,那么如果您使用厘米而不是米作为测量单位,那么您的 RMSE 会更高。您可以通过使用不同的单位来任意降低 RMSE,这就是为什么将您的 RMSE 与基线进行比较很重要的原因。
还有一些指标可以自然地让您直观地了解您在基线上的表现,例如R 2,我们将在下面讨论。
R2
尽管名称R 2包含“平方”,但R 2值的范围从负无穷到 1。让我们来看看这个度量背后的数学。R 2计算如下:

如果您总是预测ȳ ,则SS tot是总平方和:
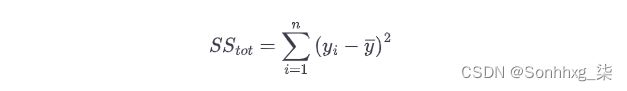
SS res是模型预测的残差平方和(也称为误差平方和,我们用它来计算 RMSE):
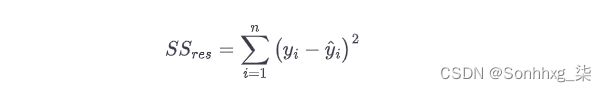
如果你的模型完美地预测了每个数据点,那么你的SS res = 0,使你的R 2 = 1。如果你的SS res = SS tot,那么分数是 1/1,所以你的R 2是 0。这就是如果您的模型执行与始终预测平均值ȳ相同的情况,就会发生这种情况。
但是,如果您的模型的性能比总是预测的差,并且您的SS res真的很大,该怎么办?那么你的R 2实际上可能是负数!如果您的R 2是负数,您应该重新评估您的建模过程。使用R 2的好处是您不一定需要定义一个基线模型来进行比较。
如果我们想将回归评估器更改为使用R 2,而不是重新定义回归评估器,我们可以使用 setter 属性设置度量名称:
# In Python
r2 = regressionEvaluator.setMetricName("r2").evaluate(predDF)
print(f"R2 is {r2}")// In Scala
val r2 = regressionEvaluator.setMetricName("r2").evaluate(predDF)
println(s"R2 is $r2")输出是:
R2 is 0.159854
我们的R 2是正的,但它非常接近于 0。我们的模型表现不佳的原因之一是因为我们的标签price看起来是对数正态分布的。如果一个分布是对数正态分布,这意味着如果我们取值的对数,结果看起来像一个正态分布。价格通常是对数正态分布的。如果您考虑旧金山的租金价格,大多数租金约为每晚 200 美元,但也有一些租金为每晚数千美元!您可以在图 10-7中看到我们的训练数据集的 Airbnb 价格分布。
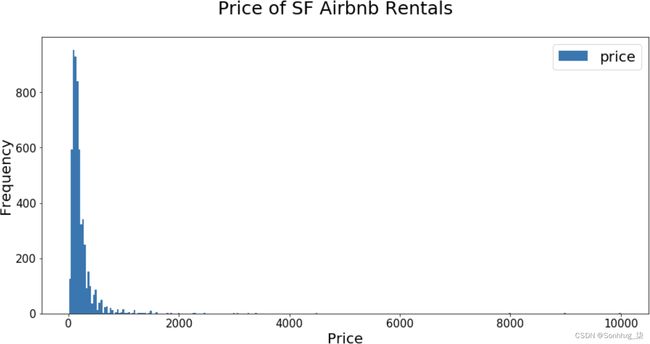
图 10-7。旧金山房价分布
如果我们改为查看价格的对数(图 10-8),让我们看看结果分布。

图 10-8。旧金山住房对数价格分布
你可以在这里看到我们的对数价格分布看起来更像一个正态分布。作为练习,尝试建立一个模型来预测对数尺度的价格,然后对预测取幂以使其超出对数尺度并评估您的模型。代码也可以在本书的GitHub 存储库中的本章笔记本中找到。你应该看到你的 RMSE 降低了,你的R 2增加了这个数据集.
保存和加载模型
现在我们已经构建并评估了一个模型,让我们将它保存到持久存储中以供以后重用(或者如果我们的集群出现故障,我们不必重新计算模型)。保存模型与编写 DataFrame 非常相似——API 是. 您可以选择提供命令来覆盖该路径中包含的任何数据:model.write().save(path)overwrite()
# In Python
pipelinePath = "/tmp/lr-pipeline-model"
pipelineModel.write().overwrite().save(pipelinePath)// In Scala
val pipelinePath = "/tmp/lr-pipeline-model"
pipelineModel.write.overwrite().save(pipelinePath)当您加载已保存的模型时,您需要指定要加载的模型的类型(例如,它是 aLinearRegressionModel还是 a LogisticRegressionModel?)。出于这个原因,我们建议您始终将转换器/估计器放入 aPipeline中,以便为所有模型加载 aPipelineModel并且只需要更改模型的文件路径:
# In Python
from pyspark.ml import PipelineModel
savedPipelineModel = PipelineModel.load(pipelinePath)// In Scala
import org.apache.spark.ml.PipelineModel
val savedPipelineModel = PipelineModel.load(pipelinePath)加载后,您可以将其应用于新数据点。但是,您不能使用此模型的权重作为训练新模型的初始化参数(而不是从随机权重开始),因为 Spark 没有“热启动”的概念。如果您的数据集略有变化,您将不得不从头开始重新训练整个线性回归模型。
随着我们的线性回归模型的建立和评估,让我们来探索一些其他模型在我们的数据集上的表现。在下一节中,我们将探索基于树的模型,并查看一些常用的超参数进行调整,以提高模型性能.
超参数调优
当数据科学家谈论调整他们的模型时,他们经常讨论调整超参数以提高模型的预测能力。超参数是您在训练之前定义的关于模型的属性,它不是在训练过程中学习的(不要与在训练过程中学习的参数混淆)。随机森林中的树数是超参数的一个示例。
在本节中,我们将重点使用基于树的模型作为超参数调整过程的示例,但同样的概念也适用于其他模型。一旦我们设置了进行超参数调整的机制spark.ml,我们将讨论优化管道的方法。让我们先简要介绍一下决策树,然后介绍如何在spark.ml.
基于树的模型
基于树的模型,例如决策树、梯度提升树和随机森林,是相对简单但功能强大的模型,易于解释(意思是,很容易解释它们所做的预测)。因此,它们在机器学习任务中非常受欢迎。我们很快就会谈到随机森林,但首先我们需要了解决策树的基础知识。
决策树
作为现成的解决方案,决策树非常适合数据挖掘。它们的构建速度相对较快,可解释性强,并且尺度不变(即,标准化或缩放数字特征不会改变树的性能)。那么什么是决策树呢?
决策树是从数据中学习的一系列 if-then-else 规则,用于分类或回归任务。假设我们正在尝试建立一个模型来预测某人是否会接受工作机会,并且特征包括薪水、通勤时间、免费咖啡等。如果我们将决策树拟合到这个数据集,我们可能会得到一个模型如图 10-9所示。
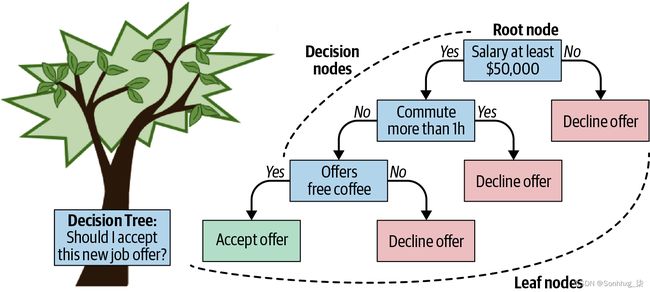
图 10-9。决策树示例
树顶部的节点称为树的“根”,因为它是我们“拆分”的第一个特征。此功能应该提供最有用的信息——在这种情况下,如果工资低于 50,000 美元,那么大多数候选人将拒绝工作机会。“拒绝报价”节点称为“叶节点”,因为该节点没有其他拆分;它在一个分支的末端。(是的,我们称它为决策“树”有点好笑,但在顶部绘制树的根,在底部绘制叶子!)
但是,如果提供的薪水大于 50,000 美元,我们将继续进行决策树中下一个信息量最大的特征,在这种情况下是通勤时间。即使工资超过 50,000 美元,如果通勤时间超过一小时,那么大多数人都会拒绝这份工作。
笔记
我们不会在这里详细介绍如何确定哪些特征会给您带来最高的信息增益,但如果您有兴趣,请查看由 Trevor Hastie、Robert Tibshirani 和 Jerome 撰写的The Elements of Statistical Learning 的第 9 章弗里德曼(施普林格)。
我们模型的最后一个特征是免费咖啡。在这种情况下,决策树显示,如果工资大于 50,000 美元,通勤时间不到一小时,并且有免费咖啡,那么大多数人都会接受我们的工作机会(如果就这么简单!)。作为后续资源,R2D3对决策树的工作方式进行了很好的可视化。
笔记
可以在单个决策树中多次拆分同一特征,但每次拆分将以不同的值发生。
决策树的深度是从根节点到任何给定叶节点的最长路径。在图 10-9中,深度为 3。非常深的树容易过度拟合,或者在训练数据集中记忆噪声,但太浅的树将不适合您的数据集(即,可能从数据中获取更多信号)。
解释完决策树的本质后,让我们继续讨论决策树的特征准备。对于决策树,您不必担心标准化或缩放输入特征,因为这对拆分没有影响——但您必须小心准备分类特征的方式。
基于树的方法可以自然地处理分类变量。在spark.ml中,您只需将分类列传递给StringIndexer,决策树可以处理其余部分。让我们将决策树拟合到我们的数据集:
# In Python
from pyspark.ml.regression import DecisionTreeRegressor
dt = DecisionTreeRegressor(labelCol="price")
# Filter for just numeric columns (and exclude price, our label)
numericCols = [field for (field, dataType) in trainDF.dtypes
if ((dataType == "double") & (field != "price"))]
# Combine output of StringIndexer defined above and numeric columns
assemblerInputs = indexOutputCols + numericCols
vecAssembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
# Combine stages into pipeline
stages = [stringIndexer, vecAssembler, dt]
pipeline = Pipeline(stages=stages)
pipelineModel = pipeline.fit(trainDF) # This line should error// In Scala
import org.apache.spark.ml.regression.DecisionTreeRegressor
val dt = new DecisionTreeRegressor()
.setLabelCol("price")
// Filter for just numeric columns (and exclude price, our label)
val numericCols = trainDF.dtypes.filter{ case (field, dataType) =>
dataType == "DoubleType" && field != "price"}.map(_._1)
// Combine output of StringIndexer defined above and numeric columns
val assemblerInputs = indexOutputCols ++ numericCols
val vecAssembler = new VectorAssembler()
.setInputCols(assemblerInputs)
.setOutputCol("features")
// Combine stages into pipeline
val stages = Array(stringIndexer, vecAssembler, dt)
val pipeline = new Pipeline()
.setStages(stages)
val pipelineModel = pipeline.fit(trainDF) // This line should error这会产生以下错误:
java.lang.IllegalArgumentException: requirement failed: DecisionTree requires
maxBins (= 32) to be at least as large as the number of values in each
categorical feature, but categorical feature 3 has 36 values. Consider removing
this and other categorical features with a large number of values, or add more
training examples.我们可以看到maxBins参数有问题。该参数有什么作用?maxBins确定将连续特征离散化或拆分的 bin 数量。这个离散化步骤对于执行分布式训练至关重要。没有maxBins参数,scikit-learn因为所有数据和模型都驻留在一台机器上。然而,在 Spark 中,worker 拥有数据的所有列,但只有行的一个子集。因此,在讨论要拆分的特征和值时,我们需要确保它们都在谈论相同的拆分值,这是我们从训练时设置的通用离散化中获得的。让我们看一下图 10-10,它显示了PLANET分布式决策树的实现,以更好地理解分布式机器学习并说明maxBins参数。

图 10-10。PLANET 分布式决策树的实现(来源:https ://oreil.ly/RAvvP )
每个工作人员都必须计算每个特征和每个可能的分割点的汇总统计数据,这些统计数据将在工作人员之间汇总。MLlib 需要maxBins足够大以处理分类列的离散化。的默认值maxBins是32,我们有一个包含 36 个不同值的分类列,这就是我们之前得到错误的原因。虽然我们可以增加maxBins以64更准确地表示我们的连续特征,但这将使连续变量的可能拆分数量增加一倍,从而大大增加我们的计算时间。让我们改为设置maxBins并40重新训练管道。你会注意到这里我们使用的是 setter 方法setMaxBins()修改决策树而不是完全重新定义它:
# In Python
dt.setMaxBins(40)
pipelineModel = pipeline.fit(trainDF)// In Scala
dt.setMaxBins(40)
val pipelineModel = pipeline.fit(trainDF)笔记
scikit-learn由于实现上的差异,在使用MLlib构建模型时,您通常不会得到完全相同的结果。不过,没关系。关键是要了解它们为何不同,并查看您可以控制哪些参数以使它们按照您需要的方式执行。如果您要将工作负载从scikit-learnMLlib 移植,我们鼓励您查看文档以了解哪些参数不同,spark.ml并scikit-learn调整这些参数以获得相同数据的可比较结果。一旦这些值足够接近,您就可以将 MLlib 模型扩展到scikit-learn无法处理的更大数据大小。
现在我们已经成功构建了模型,我们可以提取决策树学习到的 if-then-else 规则:
# In Python
dtModel = pipelineModel.stages[-1]
print(dtModel.toDebugString)// In Scala
val dtModel = pipelineModel.stages.last
.asInstanceOf[org.apache.spark.ml.regression.DecisionTreeRegressionModel]
println(dtModel.toDebugString)
DecisionTreeRegressionModel: uid=dtr_005040f1efac, depth=5, numNodes=47,...
If (feature 12 <= 2.5)
If (feature 12 <= 1.5)
If (feature 5 in {1.0,2.0})
If (feature 4 in {0.0,1.0,3.0,5.0,9.0,10.0,11.0,13.0,14.0,16.0,18.0,24.0})
If (feature 3 in
{0.0,1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0,11.0,12.0,13.0,14.0,...})
Predict: 104.23992784125075
Else (feature 3 not in {0.0,1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0,...})
Predict: 250.7111111111111
...这只是打印输出的一个子集,但您会注意到可以多次拆分同一特征(例如,特征 12),但拆分值不同。还要注意决策树在数字特征与分类特征上的分割方式之间的区别:对于数字特征,它检查值是否小于或等于阈值,而对于分类特征,它检查值是否在该集合中。
我们还可以从模型中提取特征重要性分数以查看最重要的特征:
# In Python
import pandas as pd
featureImp = pd.DataFrame(
list(zip(vecAssembler.getInputCols(), dtModel.featureImportances)),
columns=["feature", "importance"])
featureImp.sort_values(by="importance", ascending=False)// In Scala
val featureImp = vecAssembler
.getInputCols.zip(dtModel.featureImportances.toArray)
val columns = Array("feature", "Importance")
val featureImpDF = spark.createDataFrame(featureImp).toDF(columns: _*)
featureImpDF.orderBy($"Importance".desc).show()| 特征 | 重要性 |
|---|---|
| bedrooms | 0.283406 |
| cancellation_policyIndex | 0.167893 |
| instant_bookableIndex | 0.140081 |
| property_typeIndex | 0.128179 |
| number_of_reviews | 0.126233 |
| neighbourhood_cleansedIndex | 0.056200 |
| longitude | 0.038810 |
| minimum_nights | 0.029473 |
| beds | 0.015218 |
| room_typeIndex | 0.010905 |
| accommodates | 0.003603 |
虽然决策树非常灵活且易于使用,但它们并不总是最准确的模型。如果我们要在测试数据集上计算我们的R 2,我们实际上会得到一个负分!这比仅仅预测平均值还要糟糕。(您可以在本书的GitHub 存储库中的本章笔记本中看到这一点。)
让我们看一下通过使用组合不同模型以获得更好结果的集成方法来改进此模型:随机森林。
随机森林
Ensembles 通过采取民主的方式工作。想象一下,一个罐子里有很多 M&M。你让一百个人猜测 M&M 的数量,然后取所有猜测的平均值。与大多数个人猜测相比,平均值可能更接近真实值。同样的概念也适用于机器学习模型。如果您构建许多模型并组合/平均它们的预测,它们将比任何单个模型产生的更稳健。
随机森林是决策树的集合,有两个关键调整:
按行引导样本
Bootstrapping是一种通过对原始数据进行替换采样来模拟新数据的技术。每个决策树都在数据集的不同引导样本上进行训练,生成略有不同的决策树,然后汇总它们的预测。这种技术称为引导聚合或装袋。在典型的随机森林实现中,每棵树从原始数据集中采样相同数量的数据点并进行替换,并且可以通过subsamplingRate参数控制该数量。
按列随机选择特征
bagging 的主要缺点是树都是高度相关的,因此可以在数据中学习相似的模式。为了缓解这个问题,每次你想要进行拆分时,你只考虑列的一个随机子集(1/3 的特征RandomForestRegressor和#特征为RandomForestClassifier)。由于您引入的这种随机性,您通常希望每棵树都非常浅。你可能会想:这些树中的每一个都会比任何一个决策树表现得更差,那么这种方法怎么可能更好呢?事实证明,每棵树都对您的数据集学习到不同的东西,并且将这些“弱”学习者的集合组合成一个集合使森林比单个决策树更加健壮。
图 10-11展示了训练时的随机森林。在每次拆分时,它会考虑 10 个原始特征中的 3 个进行拆分;最后,它会从中选出最好的。
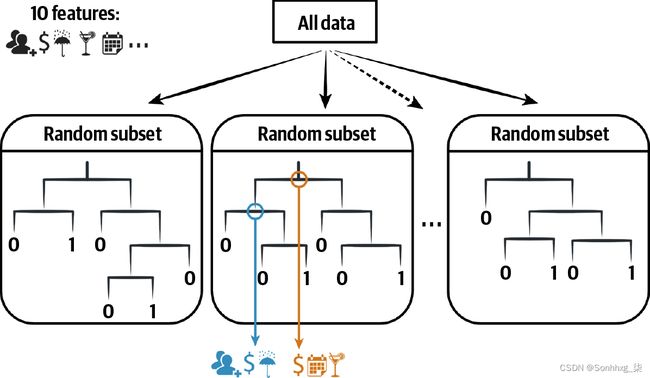
图 10-11。随机森林训练
随机森林和决策树的 API 相似,都可以应用于回归或分类任务:
# In Python
from pyspark.ml.regression import RandomForestRegressor
rf = RandomForestRegressor(labelCol="price", maxBins=40, seed=42)// In Scala
import org.apache.spark.ml.regression.RandomForestRegressor
val rf = new RandomForestRegressor()
.setLabelCol("price")
.setMaxBins(40)
.setSeed(42)一旦你训练了你的随机森林,你就可以通过在集成中训练的不同树传递新的数据点。
如图10-12所示,如果您构建一个随机森林进行分类,它会将测试点通过森林中的每棵树,并在各个树的预测中获得多数票。(相比之下,在回归中,随机森林只是对这些预测进行平均。)即使这些树中的每一棵树的性能都低于任何单个决策树,但集合(或集合)实际上提供了更稳健的模型。

图 10-12。随机森林预测
随机森林真正展示了 Spark 分布式机器学习的强大功能,因为每棵树都可以独立于其他树构建(例如,您无需在构建树 10 之前构建树 3)。此外,在树的每个级别内,您可以并行化工作以找到最佳拆分。
那么我们如何确定随机森林中的最佳树数或这些树的最大深度应该是多少?这个过程称为超参数调整。与参数相比,超参数是控制模型的学习过程或结构的值,并且在训练期间不会学习。树的数量和最大深度都是可以为随机森林调整的超参数的示例。现在让我们将重点转移到如何通过调整一些超参数来发现和评估最佳随机森林模型.
k折交叉验证
我们应该使用哪个数据集来确定最佳超参数值?如果我们使用训练集,那么模型很可能会过拟合,或者会记住我们训练数据的细微差别。这意味着它不太可能泛化到看不见的数据。但是,如果我们使用测试集,那么它将不再代表“看不见的”数据,因此我们将无法使用它来验证我们的模型的泛化程度。因此,我们需要另一个数据集来帮助我们确定最佳超参数:验证数据集。
例如,不像我们之前所做的那样将我们的数据分成 80/20 的训练/测试拆分,我们可以进行 60/20/20 的拆分来分别生成训练、验证和测试数据集。然后,我们可以在训练集上构建模型,评估验证集的性能以选择最佳超参数配置,并将模型应用于测试集以查看它在新数据上的表现如何。然而,这种方法的一个缺点是我们丢失了 25% 的训练数据(80% -> 60%),这些数据本来可以用来帮助改进模型。这促使使用k 折交叉验证技术来解决这个问题。
使用这种方法,我们没有将数据集拆分为单独的训练集、验证集和测试集,而是像以前一样将其拆分为训练集和测试集——但我们将训练数据用于训练和验证。为了实现这一点,我们将训练数据分成k个子集,或“折叠”(例如,三个)。然后,对于给定的超参数配置,我们在k– 1 折上训练我们的模型并评估剩余的折,重复这个过程k次。图 10-13说明了这种方法。
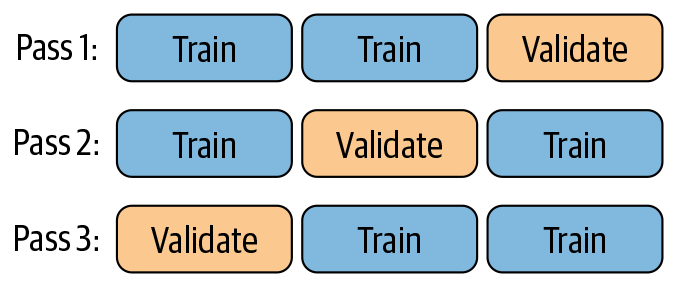
图 10-13。k折交叉验证
如图所示,如果我们将数据分成三份,我们的模型首先在数据的第一和第二份(或分割)上进行训练,并在第三份上进行评估。然后,我们在第一和第三折数据上构建具有相同超参数的相同模型,并在第二折数据上评估其性能。最后,我们在第二和第三折上构建模型,并在第一折上对其进行评估。然后,我们对这三个(或k个)验证数据集的性能进行平均,作为该模型在看不见的数据上的表现的代理,因为每个数据点都有机会恰好成为验证数据集的一部分。接下来,我们对所有不同的超参数配置重复此过程,以确定最佳配置。
确定超参数的搜索空间可能很困难,并且通常对超参数进行随机搜索优于结构化网格搜索。有专门的库,例如Hyperopt,可以帮助您确定最佳的超参数配置,我们将在第 11 章中介绍。
要在 Spark 中执行超参数搜索,请执行以下步骤:
-
定义
estimator要评估的。 -
使用ParamGridBuilder.
-
定义一个
evaluator以指定使用哪个指标来比较各种模型。 -
使用CrossValidator执行交叉验证,评估各种模型中的每一个。
让我们从定义我们的管道估计器开始:
# In Python
pipeline = Pipeline(stages = [stringIndexer, vecAssembler, rf])// In Scala
val pipeline = new Pipeline()
.setStages(Array(stringIndexer, vecAssembler, rf))对于我们的ParamGridBuilder,我们将改变我们maxDepth的 2、4 或 6 并且numTrees(我们的随机森林中的树的数量)为 10 或 100。这将为我们提供 6 (3 x 2) 个不同超参数配置的网格全部的:
(maxDepth=2, numTrees=10)
(maxDepth=2, numTrees=100)
(maxDepth=4, numTrees=10)
(maxDepth=4, numTrees=100)
(maxDepth=6, numTrees=10)
(maxDepth=6, numTrees=100)# In Python
from pyspark.ml.tuning import ParamGridBuilder
paramGrid = (ParamGridBuilder()
.addGrid(rf.maxDepth, [2, 4, 6])
.addGrid(rf.numTrees, [10, 100])
.build())// In Scala
import org.apache.spark.ml.tuning.ParamGridBuilder
val paramGrid = new ParamGridBuilder()
.addGrid(rf.maxDepth, Array(2, 4, 6))
.addGrid(rf.numTrees, Array(10, 100))
.build()现在我们已经设置了超参数网格,我们需要定义如何评估每个模型以确定哪个模型表现最好。对于这个任务,我们将使用RegressionEvaluator,并且我们将使用 RMSE 作为我们感兴趣的度量:
# In Python
evaluator = RegressionEvaluator(labelCol="price",
predictionCol="prediction",
metricName="rmse")// In Scala
val evaluator = new RegressionEvaluator()
.setLabelCol("price")
.setPredictionCol("prediction")
.setMetricName("rmse")我们将使用 执行我们的k折交叉验证CrossValidator,它接受一个estimator,evaluator和 ,estimatorParamMaps以便它知道要使用哪个模型、如何评估模型以及为模型设置哪些超参数。我们还可以设置我们想要将数据拆分为 ( numFolds=3) 的折叠数,以及设置种子以便我们在折叠 ( seed=42) 中进行可重复的拆分。然后让我们将此交叉验证器拟合到我们的训练数据集:
# In Python
from pyspark.ml.tuning import CrossValidator
cv = CrossValidator(estimator=pipeline,
evaluator=evaluator,
estimatorParamMaps=paramGrid,
numFolds=3,
seed=42)
cvModel = cv.fit(trainDF)// In Scala
import org.apache.spark.ml.tuning.CrossValidator
val cv = new CrossValidator()
.setEstimator(pipeline)
.setEvaluator(evaluator)
.setEstimatorParamMaps(paramGrid)
.setNumFolds(3)
.setSeed(42)
val cvModel = cv.fit(trainDF)输出告诉我们操作花了多长时间:
Command took 1.07 minutes那么,我们刚刚训练了多少模型?如果您回答 18(6 个超参数配置 x 3 折交叉验证),那么您就接近了。一旦确定了最佳超参数配置,如何将这三个(或k个)模型组合在一起?虽然有些模型可能很容易平均在一起,但有些则不然。因此,一旦确定了最佳超参数配置,Spark 就会在整个训练数据集上重新训练您的模型,因此最终我们训练了 19 个模型。如果要保留训练出来的中间模型,可以collectSubModels=True在CrossValidator.
要检查交叉验证器的结果,您可以查看avgMetrics:
# In Python
list(zip(cvModel.getEstimatorParamMaps(), cvModel.avgMetrics))// In Scala
cvModel.getEstimatorParamMaps.zip(cvModel.avgMetrics)这是输出:
res1: Array[(org.apache.spark.ml.param.ParamMap, Double)] =
Array(({
rfr_a132fb1ab6c8-maxDepth: 2,
rfr_a132fb1ab6c8-numTrees: 10
},303.99522869739343), ({
rfr_a132fb1ab6c8-maxDepth: 2,
rfr_a132fb1ab6c8-numTrees: 100
},299.56501993529474), ({
rfr_a132fb1ab6c8-maxDepth: 4,
rfr_a132fb1ab6c8-numTrees: 10
},310.63687030886894), ({
rfr_a132fb1ab6c8-maxDepth: 4,
rfr_a132fb1ab6c8-numTrees: 100
},294.7369599168999), ({
rfr_a132fb1ab6c8-maxDepth: 6,
rfr_a132fb1ab6c8-numTrees: 10
},312.6678169109293), ({
rfr_a132fb1ab6c8-maxDepth: 6,
rfr_a132fb1ab6c8-numTrees: 100
},292.101039874209))我们可以看到,我们的最佳模型CrossValidator(具有最低 RMSE 的模型)具有maxDepth=6和numTrees=100。但是,这需要很长时间才能运行。在下一节中,我们将研究如何在保持相同模型性能的同时减少训练模型的时间.
优化管道
如果您的代码需要足够长的时间让您考虑改进它,那么您应该优化它。在前面的代码中,尽管交叉验证器中的每个模型在技术上都是独立的,spark.ml但实际上是按顺序而不是并行训练模型集合。在 Spark 2.3 中,parallelism引入了一个参数来解决这个问题。此参数确定要并行训练的模型数量,这些模型本身是并行拟合的。来自Spark 调优指南:
parallelism应谨慎选择的值,以在不超过集群资源的情况下最大化并行度,并且较大的值可能并不总能提高性能。一般来说,10对于大多数集群来说,最高的值应该足够了。
让我们将此值设置为4,看看我们是否可以更快地训练:
# In Python
cvModel = cv.setParallelism(4).fit(trainDF)// In Scala
val cvModel = cv.setParallelism(4).fit(trainDF)答案是肯定的:
Command took 31.45 seconds
我们将训练时间缩短了一半(从 1.07 分钟减少到 31.45 秒),但我们仍然可以进一步改进!我们可以使用另一个技巧来加速模型训练:将交叉验证器放在管道中(例如,Pipeline(stages=[..., cv])而不是将管道放在交叉验证器中(例如,CrossValidator(estimator=pipeline, ...))。每次交叉验证器评估管道时,它都会运行通过每个模型的管道的每一步,即使某些步骤没有改变,例如StringIndexer. 通过重新评估管道中的每一步,我们StringIndexer一遍又一遍地学习相同的映射,即使它没有改变。
StringIndexer相反,如果我们将交叉验证器放在管道中,那么每次尝试不同的模型时,我们都不会重新评估(或任何其他估计器):
# In Python
cv = CrossValidator(estimator=rf,
evaluator=evaluator,
estimatorParamMaps=paramGrid,
numFolds=3,
parallelism=4,
seed=42)
pipeline = Pipeline(stages=[stringIndexer, vecAssembler, cv])
pipelineModel = pipeline.fit(trainDF)// In Scala
val cv = new CrossValidator()
.setEstimator(rf)
.setEvaluator(evaluator)
.setEstimatorParamMaps(paramGrid)
.setNumFolds(3)
.setParallelism(4)
.setSeed(42)
val pipeline = new Pipeline()
.setStages(Array(stringIndexer, vecAssembler, cv))
val pipelineModel = pipeline.fit(trainDF)这将我们的训练时间缩短了 5 秒:
Command took 26.21 seconds
由于parallelism参数和重新排列我们管道的顺序,最后一次运行是最快的——如果你将它应用到测试数据集,你会看到你得到了相同的结果。虽然这些收益是几秒钟的数量级,但相同的技术适用于更大的数据集和模型,相应地节省了更多的时间。您可以通过访问本书的GitHub 存储库中的笔记本来尝试自己运行此代码.
概括
在本章中,我们介绍了如何使用 Spark MLlib 构建管道——特别是其基于 DataFrame 的 API 包,spark.ml. 我们讨论了转换器和估计器之间的区别,如何使用 Pipeline API 组合它们,以及评估模型的一些不同指标。然后,我们探讨了如何使用交叉验证来执行超参数调整以提供最佳模型,以及在 Spark 中优化交叉验证和模型训练的技巧。