CBAM: Convolutional Block Attention Module 通道+空间注意力机制

前言
在了解了基于通道的注意力机制SE-NET之后,发现CBAM对于upsample造成的图像损失有一定的弥补作用,这让改进网络结构有了一定的思路。
Abstract
我们提出了卷积块注意模块(CBAM),一种简单而有效的前馈卷积神经网络注意模块。
给定一个中间特征映射,我们的模块沿着两个独立的维度(通道和空间)顺序推理注意映射,然后将注意映射乘以输入特征映射以进行自适应特征细化。因为CBAM是一个轻量级的通用模块,它可以无缝地集成到任何CNN架构中,开销可以忽略不计,并且可以与基础CNN一起进行端到端的训练。我们通过在ImageNet-1K、MS COCO检测和VOC 2007检测数据集上的大量实验来验证我们的CBAM。我们的实验表明,各种模型在分类和检测性能方面都有一致的改进,证明了CBAM的广泛适用性。代码和模型将公开提供。
Keywords: Object recognition, attention mechanism, gated convolution
1 Introduction
卷积神经网络(CNN)凭借其丰富的表示能力,显著提升了视觉任务的性能[1,2,3]。
为了提高CNN的性能,最近的研究主要研究了网络的三个重要因素: d e p t h , w i d t h , a n d c a r d i n a l i t y . depth,width, and cardinality. depth,width,andcardinality.
从LeNet体系结构[4]到残差式网络[5,6,7,8],到目前为止,网络已经变得更深,以获得丰富的表示。VGGNet[9]表明,相同形状的堆叠块可以得到公平的结果。遵循同样的灵感,ResNet[5]将残差块的相同拓扑与跳过连接堆叠在一起,以构建一个极深的体系结构。GoogLeNet[10]表明,宽度是提高模型性能的另一个重要因素。Zagoruyko和Komodakis[6]建议基于ResNet架构增加网络的宽度。Xception[11]和ResNeXt[7]提出了增加网络基数的方法。他们的经验表明,基数不仅节省了参数总数,而且比其他两个因素(深度和宽度)具有更强的表示能力。
除了这些因素之外,我们还研究了结构设计的另一个方面,即注意力。在以前的文献[12,13,14,15,16,17]中,对注意力的重要性进行了广泛的研究。注意力不仅告诉我们应该把注意力集中在哪里,它还提高了兴趣的表现力。我们的目标是通过使用注意机制来提高表征能力:关注重要特征并抑制不必要的特征。在本文中,我们提出了一个新的网络模块,称为“卷积块注意模块”(CBAM)。由于卷积运算通过混合交叉通道和空间信息来提取信息特征,我们采用我们的模块来强调这两个主要维度上的有意义特征:通道和空间轴。为了实现这一点,我们依次应用通道和空间注意模块(如图1所示),这样,每个分支都可以分别在通道轴和空间轴上学习“什么”和“在哪里”。因此,我们的模块通过学习强调或抑制哪些信息,有效地帮助信息在网络中流动。
在ImageNet-1K数据集中,我们通过插入我们的微型模块,从各种基线网络中获得精度改进,从而揭示了CBAM的功效。我们使用grad-CAM[18]可视化训练模型,并观察到CBAM增强网络比其baseline网络更适合于target objects。
grad-CAM(可视化训练模型)
18. Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad-
cam: Visual explanations from deep networks via gradient-based localization. In:
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
(2017) 618–6262,10,12
然后,我们进行 u s e r s t u d y user study userstudy,以定量评估模型可解释性方面的改进。我们表明,使用CBAM可以同时获得更好的性能和更好的可解释性。考虑到这一点,我们推测性能提升来自于精确的注意力和非相关噪声的抑制。最后,我们在MS COCO和VOC 2007数据集上验证了目标检测的性能改进,证明了CBAM的广泛适用性。由于我们仔细设计了轻量级的模块,因此在大多数情况下,参数和计算的开销可以忽略不计。
Contribution: 我们的主要贡献有三个方面。
- 我们提出了一种简单而有效的注意模块(CBAM),可广泛应用于提高CNN的表征能力。
- 我们通过广泛的消融研究来验证我们的注意力模块的有效性。
- 通过插入我们的轻量级模块,我们验证了在多个基准(ImageNet-1K、MS COCO和VOC 2007)上,各种网络的性能得到了极大的提高。
2 Related Work
Network engineering: “Network engineering”一直以来都是最重要的视觉研究之一,因为设计良好的网络可以确保在各种应用中显著提高性能。自从大规模CNN的成功实施以来,已经提出了广泛的体系结构[19]。一种直观而简单的扩展方法是增加神经网络的深度[9]。Szegedyet al.[10]介绍了一个使用多分支架构的深度初始网络,其中每个分支都经过仔细自定义。由于梯度传播的困难,深度的简单增加达到饱和,ResNet[5]提出了一种简单的恒等跳过连接,以缓解深度网络的优化问题。基于ResNet体系结构,开发了各种模型,如WideResNet[6]、Inception ResNet[8]和ResNeXt[7]。WideResNet[6]提出了一种具有更多卷积滤波器和减少深度的残差网络。PyramidNet[20]是WideResNet的严格推广,其中网络的宽度逐渐增加。ResNeXt[7]建议使用分组卷积,并表明增加基数可以提高分类精度。最近,Huanget等人[21]提出了一种新的架构,DenseNet。它迭代地将输入特征与输出特征连接起来,使每个卷积块能够接收来自所有先前块的原始信息。虽然大多数最新的网络工程方法主要针对三个因素:深度[19,9,10,5]、宽度[10,22,6,8]和基数[7,11],但我们关注的是另一个方面,“注意”,这是人类视觉系统的一个奇特方面。
Attention mechanism: 众所周知,注意力在人类感知中起着重要作用[23,24,25]。人类视觉系统的一个重要特性是,人们不会试图同时处理整个场景。相反,为了更好地捕捉视觉结构,人类利用一系列的部分瞥见,并有选择地聚焦于突出部分[26]。
最近,有几次尝试[27,28]将注意力处理结合起来,以提高CNN在大规模分类任务中的性能。Wanget al.[27]提出了一种使用encoder-decoder style注意模块的Residual Attention Network。通过细化特征映射,该网络不仅性能良好,而且对噪声输入具有鲁棒性。
- Wang, F., Jiang, M., Qian, C., Yang, S., Li, C., Zhang, H., Wang, X., Tang, X.: Residual attention network for image classification. arXiv preprint arXiv:1704.06904 (2017)3,4
通过细化特征映射,该网络不仅性能良好,而且对噪声输入具有鲁棒性。我们没有直接计算3d注意图,而是将学习通道注意和空间注意的过程分别分解。3D特征图的单独注意力生成过程具有更少的计算和参数开销,因此可以用作现有基础CNN架构的即插即用模块。
与我们的工作更接近的是,Huet al.[28]引入了一个紧凑的模块来利用通道间的关系。
- Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. arXiv preprint
arXiv:1709.01507 (2017)3,4,5,6,7,8,9,10,11,13,14
在他们的 S q u e e z e − a n d − E x c i t a t i o n m o d u l e Squeeze-and-Excitation\ module Squeeze−and−Excitation module中,他们使用 g l o b a l a v e r a g e − p o o l e d global\ average-pooled global average−pooled特征来计算 c h a n n e l − w i s e a t t e n t i o n channel-wise\ attention channel−wise attention。然而,我们表明,这些都是次优的特征,以推理精细通道注意,我们还建议使用 m a x − p o o l e d max-pooled max−pooled特征。他们还忽略了空间注意力,空间注意力在决定“在哪里”集中注意力方面起着重要作用,如[29]所示。
- Chen, L., Zhang, H., Xiao, J., Nie, L., Shao, J., Chua, T.S.: Sca-cnn: Spatial and
channel-wise attention in convolutional networks for image captioning. In: Proc.
of Computer Vision and Pattern Recognition (CVPR). (2017)4
在我们的CBAM中,我们基于一个有效的体系结构同时利用了空间和通道注意,并通过实证验证了利用两者优于仅使用通道注意[28]。
此外,我们的经验表明,我们的模块是有效的检测任务(MS-COCO和VOC)。特别是,我们只需将我们的模块置于VOC2007测试集中现有的one-shot detector[30]之上,即可实现最先进的性能。
- Sanghyun, W., Soonmin, H., So, K.I.: Stairnet: Top-down semantic aggregation
for accurate one shot detection. In: Proc. of Winter Conference on Applications of
Computer Vision (W ACV). (2018)4,13,14
同时,BAM[31]采用了类似的方法,将3D注意力map推理分解为通道和空间。他们在网络的每个瓶颈处放置BAM模块,而我们在每个卷积块处插入。
- Park, J., Woo, S., Lee, J.Y., Kweon, I.S.: Bam: Bottleneck attention module. In:
Proc. of British Machine Vision Conference (BMVC). (2018)4
Convolutional Block Attention Module
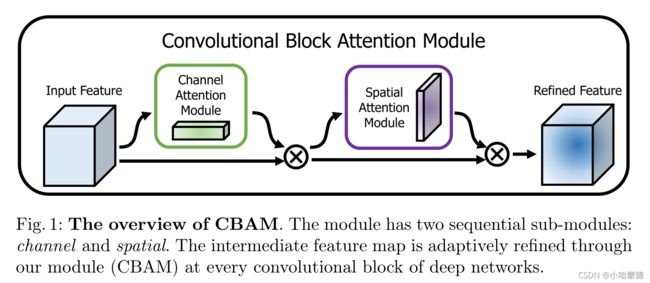
给定一个中间特征映射 F ∈ R C × H × W F\in \mathbb R^{C\times H\times W} F∈RC×H×W作为输入,CBAM 按顺序推理1D的通道注意映射 M c ∈ R C × 1 × 1 M_c\in\mathbb R^{C\times 1\times 1} Mc∈RC×1×1和一个2D的空间注意映射 M s ∈ R 1 × H × W M_s\in\mathbb R^{1\times H\times W} Ms∈R1×H×W如图1所示。整体注意力处理可概括为:
F ∗ = M c ( F ) ⨂ F , F ∗ ∗ = M s ( F ∗ ) ⨂ F ∗ , − − − ( 1 ) F^*=M_c(F)\bigotimes F, \\ F^{**}=M_s(F^*)\bigotimes F^*,---(1) F∗=Mc(F)⨂F,F∗∗=Ms(F∗)⨂F∗,−−−(1)
其中 ⨂ \bigotimes ⨂表示逐元素乘法算子。在乘法过程中,注意值相应地广播(复制):通道注意值沿空间维度广播,反之亦然。 F ∗ ∗ F^{**} F∗∗是最终的精炼输出。图2显示了每个注意力映射的计算过程。下面介绍每个注意模块的详细信息。
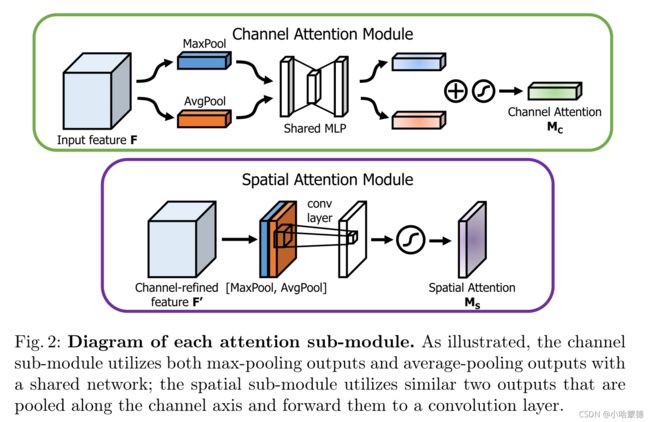
图2:各注意子模块示意图。如图所示,通道子模块利用共享网络的max-pooling输出和average-pooling输出;空间子模块利用沿通道轴汇集的两个类似输出,并将它们传入到卷积层。
Channel attention module: 我们利用特征的通道间关系生成通道注意映射。由于特征映射的每个通道都被视为一个特征检测器[32],通道注意力集中在给定输入图像的“什么”是有意义的。为了有效地计算通道注意,我们压缩了输入特征映射的空间维度。为了聚合空间信息,到目前为止通常采用 average-pooling。
- Zeiler, M.D., Fergus, R.: Visualizing and understanding convolutional networks.In: Proc. of European Conf. on Computer Vision (ECCV). (2014)4
Zhou等人[33]建议使用它来有效地了解目标物体的范围,Huet al.[28]在他们的注意模块中采用它来计算空间统计。
- Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., Torralba, A.: Learning deep features for discriminative localization. In: Computer Vision and Pattern Recognition(CVPR), 2016 IEEE Conference on, IEEE (2016) 2921–29295
- Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. arXiv preprint arXiv:1709.01507 (2017)3,4,5,6,7,8,9,10,11,13,14
除了之前的工作,我们认为max-pooling收集了另一个关于不同对象特征的重要线索,以推理更精细的通道注意。因此,我们同时使用average-pooled和max-pooled 特征。我们根据经验证实,利用这两种特性大大提高了网络的表示能力,而不是单独使用每种特性(见第4.1节),这表明了我们设计选择的有效性。我们将在下面描述详细的操作。
我们首先使用average-pooling和max-pooling操作聚合特征映射的空间信息,生成两个不同的空间上下文描述符: F a v g c F_{avg}^c Favgc和 F m a x c F_{max}^c Fmaxc,分别表示average-pooled特征和 max-pooled特征。然后,这两个描述符被传入到一个共享网络,以生成我们的通道注意力映射 M c ∈ R C × 1 × 1 M_c\in\mathbb R^{C\times1\times 1} Mc∈RC×1×1。共享网络由多层感知器(MLP)和一个隐藏层组成。为了减少参数开销,将隐藏激活大小设置为 R C / r × 1 × 1 \mathbb R^{C/r\times 1\times 1} RC/r×1×1,其中 r r r为缩减率。将共享网络应用于每个描述符后,我们使用逐元素加法合并输出特征向量。简言之,通道注意力的计算如下:
M c ( F ) = σ ( M L P ( A v g P o o l ( F ) ) + M L P ( M a x P o o l ( F ) ) ) = σ ( W 1 ( W 0 ( F a v g c ) ) + W 1 ( W 0 ( F m a x c ) ) ) , − − − ( 2 ) M_c(F)=\sigma(MLP(AvgPool(F))+MLP(MaxPool(F)))\\=\sigma(W_1(W_0(F_{avg}^c))+W_1(W_0(F_{max}^c))),---(2) Mc(F)=σ(MLP(AvgPool(F))+MLP(MaxPool(F)))=σ(W1(W0(Favgc))+W1(W0(Fmaxc))),−−−(2)
其中 σ \sigma σ表示sigmoid函数, W 0 ∈ R C / r × C , W 1 ∈ R C × C / r W_0\in\mathbb R^{C/r\times C},W_1\in\mathbb R^{C\times C/r} W0∈RC/r×C,W1∈RC×C/r.请注意,MLP权重 W 0 W_0 W0和 W 1 W_1 W1,被两个输入共享,且ReLU激活函数后接 W 0 W_0 W0。
Spatial attention module: 利用特征间的空间关系生成空间注意映射。与通道注意不同的是,空间注意侧重于“何处”是信息部分,与通道注意是互补的。为了计算空间注意,我们首先沿通道轴应用average-pooling和max-pooling操作,并将它们concat起来以生成有效的特征描述符。沿通道轴应用pooling操作可以有效地突出显示信息区域[34]。在concatenated特征描述符上,我们应用卷积层来生成空间注意映射 M s ( F ) ∈ R H × W M_s(F)\in\mathbb R^{H\times W} Ms(F)∈RH×W,其中它对强调或抑制的位置进行encodes。我们将在下面描述详细的操作。
我们通过使用两个pooling操作聚合特征映射的通道信息,生成两个2D映射: F a v g c ∈ R 1 × H × W F_{avg}^c\in\mathbb R^{1\times H\times W} Favgc∈R1×H×W和 F m a x s ∈ R 1 × H × W F^s_{max}\in\mathbb R^{1\times H\times W} Fmaxs∈R1×H×W。每个表示通道中的average-pooled特征和max-pooled特征。然后,通过一个标准卷积层将它们concat并卷积,生成我们的2D空间注意力映射。简言之,空间注意力的计算如下:
M s ( F ) = σ ( f 7 × 7 ( [ A v g P o o l ( F ) ; M a x P o o l ( F ) ] ) ) = σ ( f 7 × 7 ( [ F a v g s ; F m a x s ] ) ) , − − − ( 3 ) M_s(F)=\sigma(f^{7\times 7}([AvgPool(F);MaxPool(F)]))\\=\sigma(f^{7\times 7}([F^s_{avg};F^s_{max}])),---(3) Ms(F)=σ(f7×7([AvgPool(F);MaxPool(F)]))=σ(f7×7([Favgs;Fmaxs])),−−−(3)
其中 σ \sigma σ表示sigmoid函数, f 7 × 7 f^{7\times 7} f7×7表示卷积核大小。
Arrangement of attention modules: 给定一幅输入图像,通道和空间两个注意模块计算互补注意,分别关注“什么”和“哪里”。考虑到这一点,两个模块可以并行或顺序放置。我们发现顺序排列比平行排列效果更好。对于顺序过程的安排,我们的实验结果表明,channel-first略优于spatial-first。我们将在第4.1节讨论网络工程的实验结果。
4 Experiments
我们根据标准基准评估CBAM:ImageNet-1K用于图像分类;MS COCO和VOC 2007用于目标检测。为了更好地进行apple-to-apple的比较,我们在PyTorch框架[36]中复制了所有经过评估的网络[5,6,7,35,28],并在整个实验中报告了我们的复制结果。
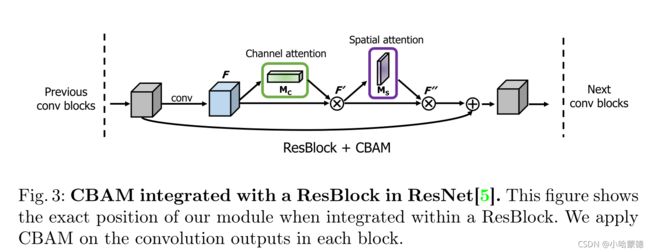
为了彻底评估我们最终模块的有效性,我们首先进行了广泛的消融实验。然后,我们验证了CBAM的性能优于所有的baseline,证明了CBAM在不同体系结构和不同任务中的普遍适用性。可以在任何CNN架构中无缝集成CBAM,并联合训练组合的CBAM增强网络。图3以ResNet[5]中与ResBlock集成的CBAM图为例。
4.1 Ablation studies
在这一小节中,我们以经验证明了我们的设计选择的有效性。对于本消融研究,我们使用ImageNet-1K数据集,并采用ResNet-50[5]作为基础架构。ImageNet-1K分类数据集[1]包括120万张用于训练的图像和50000张用于1000个对象类验证的图像。我们采用与[5,37]相同的数据扩充方案进行训练,并在测试时应用224×224大小的single-crop评估。学习率从0.1开始,每30个epochs下降一次。我们训练网络90个epochs。在[5,37,38]之后,我们报告了验证集上的分类错误。
我们的模块设计过程分为三个部分。我们首先寻找计算通道注意的有效方法,然后是空间注意。最后,我们考虑如何结合通道和空间注意模块。我们在下面解释每个实验的细节。
Channel attention: 我们通过实验验证了使用average-pooled和max-pooled特征可以实现更精细的注意推理。我们比较了3种通道注意的变体:average pooling、max pooling和两种pooling的联合使用。请注意,具有average pooling的通道注意模块与SE[28]模块相同。此外,当使用两个pooling时,我们使用共享MLP进行注意推理以保存参数,因为两个聚合通道特征位于相同的语义嵌入空间中。在本实验中,我们只使用了通道注意模块,并将缩减比 r r r固定为16。
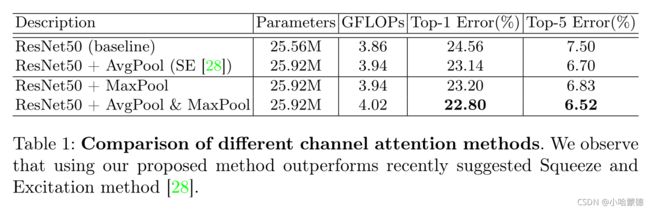
表1:不同通道注意方法的比较。 我们观察到,使用我们提出的方法优于最近提出的SE方法[28]。

表2:不同空间注意方法的比较。 使用建议的channel-pooling(沿通道轴的average-pooling和max-pooling)以及size为7的大卷积核,对于以下情况,卷积运算的性能最佳。

表3:通道和空间注意相结合的方法。 使用两种注意力是至关重要的,而最佳组合策略(即顺序、通道优先)进一步提高了准确性。
表1显示了各种pooling方法的实验结果。我们观察到,max-pooled特征与average-pooled特征一样有意义,比较了与baseline相比的准确性改进。然而,在SE[28]的工作中,他们只利用average-pooled特征,忽略了max-pooled特征的重要性。我们认为,encode最显著部分程度的max-pooled特征可以补偿encode全局统计信息的average-pooled特征。因此,我们建议同时使用这两个功能,并对这些功能应用共享网络。共享网络的输出通过元素求和进行合并。我们的经验表明,我们的通道注意方法是一种有效的方法,可以在不增加额外可学习参数的情况下进一步提高SE[28]的性能。作为一个简短的结论,在下面的实验中,我们在通道注意模块中使用了average-pooled和max-pooled特征,缩减比 r r r为16。
Spatial attention: 基于逐通道细化特征,我们探索了一种计算空间注意的有效方法。设计理念与通道注意分支对称。为了生成2D空间注意映射,我们首先计算2D描述符,该描述符对所有空间位置上每个像素处的通道信息进行encode。然后,我们将一个卷积层应用于2D描述符,获得原始注意映射。最后的注意力映射由sigmoid函数进行归一化。
我们比较两种生成2D描述符的方法:channel pooling沿着通道轴使用average-pooling和max-pooling,然后标准的 1 × 1 1\times 1 1×1卷积减少通道维度为1维。此外,我们还研究了以下卷积层中卷积核大小的影响:卷积核大小为3和7。在实验中,我们将空间注意模块放在先前设计的通道注意模块之后,因为最终目标是将这两个模块一起使用。
表2显示了实验结果。我们可以观察到,通道pooling产生了更好的准确性,这表明显式建模的pooling导致了更精细的注意推断,而不是可学习的加权通道pooling(实现为1×1卷积)。在不同卷积核大小的比较中,我们发现在这两种情况下,采用较大的核大小可以获得更好的精度。这意味着决定空间上重要的区域需要广阔的视野(即大的感受野)。考虑到这一点,我们采用了通道pooling方法和具有较大卷积核大小的卷积层来计算空间注意。在一个简短的结论中,我们使用通道轴上的average-pooling和max-pooling特征,卷积核大小为7,作为我们的空间注意模块。
Arrangement of the channel and spatial attention: 在本实验中,我们比较了三种不同的安排通道和空间注意子模块的方式:顺序channel-spatial、顺序spatial-channel以及两个注意模块的并行使用。由于每个模块具有不同的功能,因此顺序可能会影响整体性能。例如,从空间角度来看,通道注意是全局应用的,而空间注意是局部应用的。此外,我们自然会认为我们可以结合两种注意力输出来构建一个3D注意力映射。在这种情况下,两个注意可以并行应用,然后将两个注意模块的输出相加,并使用sigmoid函数进行归一化。
表3总结了不同注意安排方法的实验结果。从结果中,我们可以发现,顺序生成一个注意映射比并行生成一个更精细的注意映射。此外,通道优先表现比空间优先稍好。请注意,所有的安排方法都优于单独使用通道注意,这表明利用这两种注意是至关重要的,而最佳安排策略会进一步提高性能。
4.2 Image Classification on ImageNet-1K
我们执行ImageNet-1K分类实验,以严格评估我们的模块。我们遵循第4.1节中规定的相同协议,并在各种网络架构(包括ResNet[5]、WideResNet[6]和ResNext[7])中评估我们的模块。
表4总结了实验结果。使用CBAM的网络性能显著优于所有baseline,表明CBAM可以在大规模数据集中的各种模型上很好地推广。此外,使用CBAM的模型提高了最强方法之一SE的精度[28],这是ILSVRC 2017分类任务的成功方法。这意味着我们提出的方法是强大的,显示了新的pooling方法的有效性,它可以产生更丰富的描述符和空间注意,有效地补充通道注意。
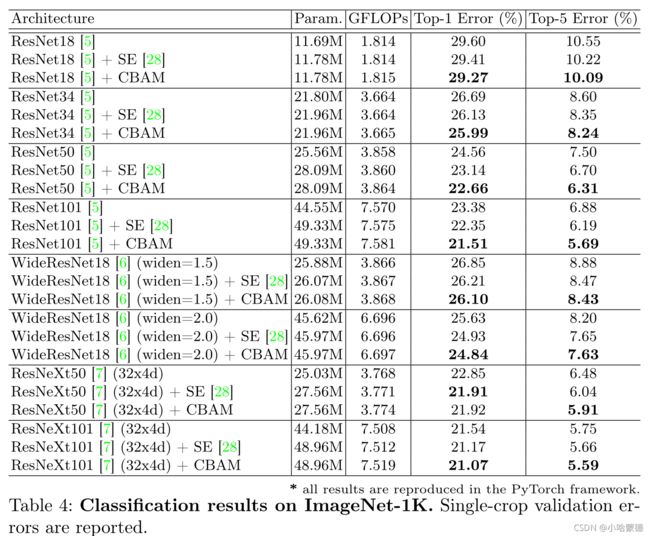
我们还发现,就参数和计算而言,CBAM的总体开销非常小。这促使我们将我们提出的模块CBAM应用于轻量级网络MobileNet[35]。表5总结了我们基于MobileNet架构进行的实验结果。我们将CBAM分为两种模型,basic模型和capacity-reduced模型(即,将宽度乘数(α)调整为0.7)。我们观察到类似的现象,如表4所示。CBAM不仅显著提高了baseline的准确性,而且有利于提高SE的性能[28]。这显示了CBAM在低端设备上应用的巨大潜力。

4.3 Network Visualization with Grad-CAM [18]
对于定性分析,我们使用ImageNet验证集的图像将Grad CAM[18]应用于不同的网络。Grad-CAM是最近提出的一种可视化方法,它使用梯度来计算卷积层中空间位置的重要性。由于梯度是针对于唯一类别计算的,Grad-CAM结果清楚地显示了参与区域。
- Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad-cam: Visual explanations from deep networks via gradient-based localization. In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.(2017) 618–6262,10,12
通过观察网络认为对预测一个类很重要的区域,我们试图了解这个网络是如何充分利用特征的。我们比较了CBAM-integrated网络(ResNet50+CBAM)与baseline(ResNet50)和SE-integrated网络(ResNet50+SE)的可视化结果。图4显示了可视化结果。图中还显示了目标类的softmax分数。
在图4中,我们可以清楚地看到CBAM-integrated网络的Grad-CAM masks比其他方法更好地覆盖目标对象区域。也就是说,CBAM-integrated网络能够很好地利用目标区域中的信息并从中聚合特征。注意,target class的分数也相应增加。
图4:Grad-CAM [18] visualization results. 我们比较了CBAM-integrated网络(ResNet50+CBAM)与baseline(ResNet50)和SE-integrated网络(ResNet50+SE)的可视化结果。计算最后卷积输出的Grad-CAM可视化。 ground-truth标签显示在每个输入图像的顶部,并显示 ground-truth类别的每个网络的softmax分数。

4.4 Quantitative evaluation of improved interpretability
根据Grad CAM论文第5.1节,我们进行了基于Grad CAM可视化的user study。我们从ImageNet验证集中随机选择了50幅使用两种方法(即baseline和CBAM)正确分类的图像。user study是在Google Forms platform上进行的。对于每个问题,随机打乱的可视化显示给respondents。对于可视化,显示Grad-CAM值为0.6或更大的图像区域。在实践中,respondents被给予完整的输入图像、ground-truth标签和每种方法的两个图像区域(见图5)。比较标准是“给定类别标签,哪个区域似乎更具类别区分性?”。Respondents可以选择其中一个更好,或者两者相似。共有50组图片和25名respondents,共获得1250张votes。结果如表6所示。我们可以清楚地看到,CBAM的性能优于baseline,显示出更好的可解释性。
4.5 MS COCO Object Detection
我们在Microsoft COCO数据集上进行对象检测[3]。该数据集包括80k训练图像(“2014训练”)和40k验证图像(“2014 val”)。不同IoU阈值(从0.5到0.95)上的平均map用于评估。根据[39,40],我们使用所有训练图像以及验证图像的子集来训练我们的模型,并给出5000个示例进行验证。我们的训练代码基于[41],我们训练网络进行49000次迭代,以实现快速性能验证。我们采用Faster-RCNN[42]作为检测方法,ImageNet预先训练的ResNet50和ResNet101[5]作为baseline网络。在这里,我们感兴趣的是通过将CBAM插入baseline网络来提高性能。由于我们在所有模型中使用相同的检测方法,因此增益只能归因于我们的模块CBAM提供的增强表示能力。如表7所示,我们观察到了与baseline相比的显著改善,证明了CBAM在其他识别任务中的泛化性能。
4.6 VOC 2007 Object Detection
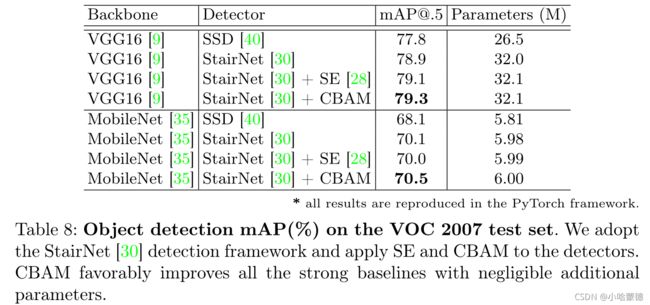
我们进一步在PASCAL VOC 2007测试集上进行了实验。在本实验中,我们将CBAM应用于检测器,而之前的实验(表7)将我们的模块应用于base网络。我们采用StairNet[30]框架,这是基于SSD的最强多尺度方法之一[40]。在实验中,我们在我们的PyTorch平台上复制了SSD和StairNet,以准确估计CBAM的性能改进,分别达到77.8%和78.9%[email protected]分别高于原始论文中报告的原始准确性。然后,我们将SE[28]和CBAM放在每个分类器之前,在预测之前细化由上采样的全局特征和相应的局部特征组成的最终特征,强制模型仅自适应地选择有意义的特征。我们在VOC 2007 trainval和VOC 2012 trainval的联合集(“07+12”)上训练所有模型,并在VOC 2007测试集上进行评估。训练的总次数为250次。我们使用0.0005的权重衰减和0.9的动量。在所有实验中,为了简单起见,输入图像的大小固定为300。
表8总结了实验结果。我们可以清楚地看到,CBAM通过两个backbone网网络提高了所有强baselines的准确性。请注意,CBAM的准确度提高带来的参数开销可以忽略不计,这表明增强不是由于简单的容量增加,而是由于我们有效的特征细化。此外,使用轻量级backbone网络[35]的结果再次表明,CBAM对于低端设备来说是一种令人感兴趣的方法。

5 Conclusion
我们提出了卷积块注意模块(CBAM),这是一种提高CNN网络表示能力的新方法。我们将基于注意力的特征细化应用于两个不同的模块:通道和空间,并在保持较小开销的同时实现了相当大的性能改进。对于通道注意,我们建议使用max-pooling特征和average-poooling特征,从而产生比SE[28]更精细的注意。我们进一步利用空间注意来提高绩效。我们的最后一个模块(CBAM)学习强调或抑制的内容和位置,并有效地细化中间特征。为了验证其有效性,我们对各种最先进的模型进行了广泛的实验,并确认CBAM在三种不同基准数据集(ImageNet1K、MS COCO和VOC 2007)上优于所有baseline。此外,我们还可视化了模块如何准确地推断给定的输入图像。有趣的是,我们观察到我们的模块诱导网络正确地聚焦于目标对象。我们希望CBAM成为各种网络架构的重要组成部分。
Acknowledgement
这项工作得到了贸易、工业和能源部(韩国密苏里州)资助的技术创新计划(编号10048320)的支持。
个人总结
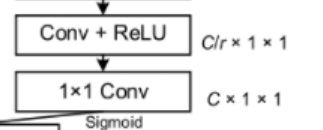
从坐标注意力机制的论文得知,CBAM的block如下:

CBAM的MLP部分采用了1X1Conv实现,作为MLP(FC)的实现方式,两种实现方式是等价的。
如下是原CBAM论文处的Shared MLP网络结构的1X1Conv实现:
pytorch源码
这里代码的MLP部分是没有采用conv实现,采用的是FC设计。
源码github链接
import torch
import math
import torch.nn as nn
import torch.nn.functional as F
class BasicConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True, bn=True, bias=False):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_planes,eps=1e-5, momentum=0.01, affine=True) if bn else None
self.relu = nn.ReLU() if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
class Flatten(nn.Module):
def forward(self, x):
return x.view(x.size(0), -1)
class ChannelGate(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max']):
super(ChannelGate, self).__init__()
self.gate_channels = gate_channels
self.mlp = nn.Sequential(
Flatten(),
nn.Linear(gate_channels, gate_channels // reduction_ratio),
nn.ReLU(),
nn.Linear(gate_channels // reduction_ratio, gate_channels)
)
self.pool_types = pool_types
def forward(self, x):
channel_att_sum = None
for pool_type in self.pool_types:
if pool_type=='avg':
avg_pool = F.avg_pool2d( x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_att_raw = self.mlp( avg_pool )
elif pool_type=='max':
max_pool = F.max_pool2d( x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_att_raw = self.mlp( max_pool )
elif pool_type=='lp':
lp_pool = F.lp_pool2d( x, 2, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_att_raw = self.mlp( lp_pool )
elif pool_type=='lse':
# LSE pool only
lse_pool = logsumexp_2d(x)
channel_att_raw = self.mlp( lse_pool )
if channel_att_sum is None:
channel_att_sum = channel_att_raw
else:
channel_att_sum = channel_att_sum + channel_att_raw
scale = F.sigmoid( channel_att_sum ).unsqueeze(2).unsqueeze(3).expand_as(x)
return x * scale
def logsumexp_2d(tensor):
tensor_flatten = tensor.view(tensor.size(0), tensor.size(1), -1)
s, _ = torch.max(tensor_flatten, dim=2, keepdim=True)
outputs = s + (tensor_flatten - s).exp().sum(dim=2, keepdim=True).log()
return outputs
class ChannelPool(nn.Module):
def forward(self, x):
return torch.cat( (torch.max(x,1)[0].unsqueeze(1), torch.mean(x,1).unsqueeze(1)), dim=1 )
class SpatialGate(nn.Module):
def __init__(self):
super(SpatialGate, self).__init__()
kernel_size = 7
self.compress = ChannelPool()
self.spatial = BasicConv(2, 1, kernel_size, stride=1, padding=(kernel_size-1) // 2, relu=False)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.spatial(x_compress)
scale = F.sigmoid(x_out) # broadcasting
return x * scale
class CBAM(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max'], no_spatial=False):
super(CBAM, self).__init__()
self.ChannelGate = ChannelGate(gate_channels, reduction_ratio, pool_types)
self.no_spatial=no_spatial
if not no_spatial:
self.SpatialGate = SpatialGate()
def forward(self, x):
x_out = self.ChannelGate(x)
if not self.no_spatial:
x_out = self.SpatialGate(x_out)
return x_out