java学习之SpringBoot2
SpringBoot2尚硅谷学习笔记
- 1.什么是SpringBoot?
- 2.HelloWorld
- 3.SpringBoot的自动配置原理
-
- 3.1SpringBoot的特点
-
- 3.1.1依赖管理
- 3.1.2自动配置
- 3.2容器功能
-
- 3.2.1组件添加
- 3.2.2原生配置文件引入
- 3.2.3配置绑定
- 3.3源码分析(了解)
- 4.如何开发一个SpringBoot应用?
- 5.几个开发小工具(Lombok,dev-tools,Spring Initailizr)
- 6.核心功能
-
- 6.1 配置文件-yaml的用法
- 6.2 Web开发
-
- 6.2.1静态资源规则与定制化
- 6.2.2welcome与favicon
- 6.2.3源码分析(静态资源)
- 6.2.4Rest风格映射及源码解析
- 6.2.5常用请求参数注解的使用及源码分析
- 6.2.6响应数据处理及源码分析
- 6.2.7视图解析及源码解析(Thymeleaf)
- 6.2.8拦截器及其源码分析
- 6.2.9文件上传及源码解析
- 6.2.10springboot的异常处理机制即源码分析
- 6.2.11原生注解与spring方式注入(Servlet,Filter,Listener)
- 6.2.12嵌入式servlet容器及源码分析
- 6.2.13定制化原理
- 6.3数据访问
-
- 6.3.1SQL
- 6.3.2使用Druid数据源
- 6.3.3整合mybatis
- 6.3.4Redis
- 6.4单元测试(JUnit5)
-
- 6.4.1常用测试注解
- 6.4.2断言机制
- 6.4.3前置条件
- 6.4.4嵌套测试
- 6.4.5参数化测试
- 6.4.6迁移指南(JUnit4-JUnit5)
- 6.5指标监控
-
- 6.5.1自定义端点
- 6.5.2可视化界面
- 7.原理解析
-
- 7.1Profile功能
- 7.2配置加载优先级
- 7.3自定义starter
- 7.4springboot的启动过程
参考资料
尚硅谷springboot2教程
笔记地址
尚硅谷springboot笔记
1.什么是SpringBoot?
SpringBoot是一个高层的框架。他的底层就是我们之前学习过的springFrameWork,也就是说Spring可以帮助我们整合spring,防止“配置地狱”,能快速创建出生产级别的Spring应用
a)SpringBoot的优点:
SpringBoot是整合Spring技术栈的一站式框架
SpringBoot是简化Spring技术栈的快速开发脚手架
● Create stand-alone Spring applications
○ 创建独立Spring应用
● Embed Tomcat, Jetty or Undertow directly (no need to deploy WAR files)
○ 内嵌web服务器(免安装)
● Provide opinionated ‘starter’ dependencies to simplify your build configuration
○ 自动starter依赖,简化构建配置(启动器,减少需要导入的jar包数量,减少错误)
● Automatically configure Spring and 3rd party libraries whenever possible
○ 自动配置Spring以及第三方功能
● Provide production-ready features such as metrics, health checks, and externalized configuration
○ 提供生产级别的监控、健康检查及外部化配置
● Absolutely no code generation and no requirement for XML configuration
○ 无代码生成、无需编写XML
b)SpringBoot的缺点:
● 人称版本帝,迭代快,需要时刻关注变化
● 封装太深,内部原理复杂,不容易精通
c)大时代背景
微服务,分布式,云原生
详情
d)SpringBoot的官方文档
官方网页地址
点击Reference.Doc

2.HelloWorld
详细原文链接
系统要求:
● Java 8 & 兼容java14 .
● Maven 3.3+
● idea 2019.1.2
maven设置:
阿里云的国内镜像以及使用JDK1.8编译
a)创建一个maven工程
b)引入依赖
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.3.4.RELEASEversion>
parent>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
dependencies>
c)创建主程序(入口)
/**
* 主程序类:入口
*@SpringBootApplication:表名这是一个springboot应用
*/
@SpringBootApplication
public class MainApplication {
public static void main(String[] args) {
//固定写法
SpringApplication.run(MainApplication.class,args);
}
}
d)编写业务(无需任何过多的配置)
//@ResponseBody返回值直接给浏览器,而不是跳转到某个页面
//@Controller
@RestController//同时包含了上面两个注解的功能
public class HelloController {
@RequestMapping("/hello")
public String handler01(){
return "hello,spring boot";
}
}
e)测试
直接运行主程序中的main方法即可
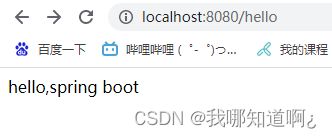
需求:浏览发送/hello请求,响应 Hello,Spring Boot
运行后的控制台信息

这时候我们直接在浏览器访问即可
f)简化配置
在resources中创建一个application.properties文件
这是一个统一的配置文件,springboot中的所有配置都可以在这里写
配置文件中可以写哪些信息可以在官方文档中下图的位置找到

g)简化部署
我们不必在pom.xml中修改部署方式为war包了
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
此时,我们使用maven的package操作后,可以把项目打成jar包,直接在目标服务器执行即可。
3.SpringBoot的自动配置原理
3.1SpringBoot的特点
3.1.1依赖管理
我们创建的项目使用父项目做依赖管理,子项目继承后,就不需要写版本号了
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.3.4.RELEASEversion>
parent>
这个父项目还有一个父项目
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-dependenciesartifactId>
<version>2.3.4.RELEASEversion>
parent>
点进去后发现这个spring-boot-dependencies已经声明了很多jar包的版本号,所以我们就无需写版本号了
当然,我们也可以手动修改,使用properties标签,下面假设我们需要修改mysql的版本号
<properties>
<mysql.version>5.1.43mysql.version>
properties>
版本号可以在这个网站搜索
mvn
总结一下:
我们可以先在spring-boot-dependencies中查看依赖的版本号,如果我们需要修改,在当前工程中使用properties标签即可
我们在开发中,可能会用到非常多的spring-boot-starter-* : *就某种场景开头的依赖,这个意思就是引入一组完整的依赖,只要引入starter,这个场景的所有常规依赖都会被自动引入
点击官方文档的use springboot,再如下图点击,就可以查看springboot所有支持的场景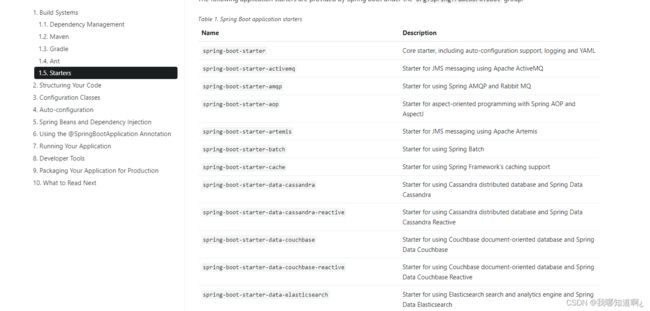
我们也可能见到 *-spring-boot-starter: 第三方为我们提供的简化开发的场景启动器。
点进每一个starter,所有的场景启动器中最底层的依赖是下面这个springboot的核心依赖
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starterartifactId>
<version>2.3.4.RELEASEversion>
<scope>compilescope>
3.1.2自动配置
1.自动配好了Tomcat
①引入Tomcat依赖(在前面的依赖管理中引入)
②配置Tomcat
2.自动配好SpringMVC
①引入SpringMVC全套组件
②自动配好SpringMVC常用组件(功能)
3.自动配好Web常见功能,如:字符编码问题
SpringBoot帮我们配置好了所有web开发的常见场景
在主程序中可以查看
//1.返回IOC容器
ConfigurableApplicationContext run = SpringApplication.run(MainApplication.class,args);
//2.查看容器里面所有的组件
String[] names = run.getBeanDefinitionNames();
for (String name : names) {
System.out.println(name);
}
4.默认的包结构
①主程序所在的包及其下面的所有子包,里面的组件都会被默认扫描(以外的包则不会)
②所以我们无需配置包扫描
③如果要手动改变包的路径,可以在主程序中做以下修改
@SpringBootApplication(scanBasePackages = 扫描路径)
@SpringBootApplication
等同于
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan("这里是要扫描的包的路径")
5.各种配置有默认值
默认配置最终都是映射到某个类上,如:MultipartProperties(文件上传),如果想要修改,直接在application.properties中修改即可
6.按需加载所有自动配置项
①非常多的starter
②引入了哪些场景这个场景的自动配置才会开启
③SpringBoot所有的自动配置功能都在 spring-boot-autoconfigure 包里面
3.2容器功能
3.2.1组件添加
回忆一下原生的Spring,当我们需要添加组件时,就需要一个xml配置文件,并用id来添加一个类,再用property为其的属性赋值,但在springboot中,我们不再需要这么麻烦了,下面介绍几种方式
a)@Configuration
用Configuration可以创建一个配置类,来代替xml
重点关注:proxyBeanMethods
回顾一下原生spring中标识组件的注释
@Bean
@Component
@Controller:控制器
@Service:业务逻辑组件
@Repository:数据库组件
一个简单的配置类:
/**
* 1、配置类中使用@Bean标注在方法上给容器注册组件,默认也是单实例的
* 2、配置类本身也是一个组件
* 3、proxyBeanMethods:代理bean的方法
* true:保持单实例,每次调用方法获取的都是容器中的对象
* false:调用方法获取对象时,不会再检查容器中是否已经存在,每次都会新建一个对象,这样启动快
* true可以实现组件依赖,若没有组件依赖,推荐使用false
* 组件依赖:某个组件中有一个属性是另一个组件,且要求这个属性在容器中
*
*/
@Configuration(proxyBeanMethods = false)//告诉springboot这是一个配置类 == 配置文件
public class MyConfig {
/**
* Full:外部无论对配置类中的这个组件注册方法调用多少次获取的都是之前注册容器中的单实例对象
* @return
*/
@Bean//给容器中添加组件,以方法名作为组件的id,返回类型就是组件类型,返回的值,就是组件在容器中的实例
public User user01(){
return new User("zhangsan",18);
}
@Bean("tom")//不想用方法名作为名字,也可以在这里给id赋值
public Pet tomcatPet(){
return new Pet("tomcat");
}
}
在主程序中的测试
//从容器中获取组件
Pet tom = run.getBean("tom",Pet.class);
Pet tom2 = run.getBean("tom",Pet.class);
System.out.println(tom2 == tom);//true,说明是单实例
//配置类本身也是一个组件
MyConfig bean = run.getBean(MyConfig.class);
//若@Configuration(proxyBeanMethods = true)就代表对象调用方法,同时获取的配置类也是一个代理对象springboot总会检查这个组件是否在容器中有,如果有,就不会新建,保持组件单实例
//若为false,配置类就不是一个代理对象,每次调用方法所得到的就不是相同对象了
User user01 = bean.user01();
User user02 = bean.user01();
System.out.println(user01 == user02);
b)@Import
在容器中导入,可以写在任何在容器中的组件上,参数是一个数组,可以在容器中自动创建出相应类型的组件,默认的组件名字就是全类名,是通过无参的构造方法创建的组件
@Import({
User.class,
DBHelper.class,
})
c)@Conditional
条件装配:满足Conditional指定的条件,则进行组件注入
注意@Conditional是一个根注解,其下面还有很多派生的注解
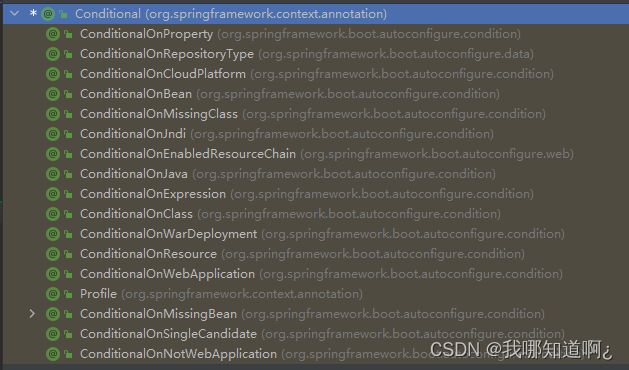
下面举两个例子
@ConditionalOnBean:容器中有组件时
@ConditionalOnMissingBean容器中没有组件时
这个注释可以用在方法和类名上
@Bean("tom")
public Pet tomcatPet(){
return new Pet("tomcat");
}
//注意tom和user01的先后顺序
@ConditionalOnBean(name = "tom")//这个注释表示只有当容器中有tom这个组件时,才会注册一个user01组件
@Bean
public User user01(){
return new User("zhangsan",18);
}
3.2.2原生配置文件引入
@ImportResource
可以利用这个注释,导入原生的spring的配置文件,使其生效
@Configuration(proxyBeanMethods = true)//告诉springboot这是一个配置类 == 配置文件
@ImportResource("classpath:beans.xml")
public class MyConfig {
3.2.3配置绑定
a)@Component + @ConfigurationProperties
现在假设我们有一个实体类Car,我们要通过配置文件application.properties中的值,在容器中注册一个组件,这种方法的注释写在对应的实体类上
配置文件中:
mycar.brand=BYD
mycar.price=100000
注册方法:
@Component//放在容器中
@ConfigurationProperties(prefix = "mycar")//prefix:前缀,在我们的配置文件中,前缀是mycar
public class Car {
private String brand;
private Integer price;
此时我们的容器中就已经注册了一个组件

b)@EnableConfigurationProperties + @ConfigurationProperties
@EnableConfigurationProperties注释写在配置类上
@EnableConfigurationProperties(Car.class)
//功能:1.开启Car类的配置绑定功能
//2、把这个Car这个组件自动注册到容器中
当我们这么写了以后,在Car的实体类上就可以把@Component去掉了
3.3源码分析(了解)
1、主程序中的SpringBootApplication
上文也说了,这是一个组合注解,我们看源码,下面就来分析一下这个组合注解的各个成分
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan(
excludeFilters = {@Filter(
type = FilterType.CUSTOM,
classes = {TypeExcludeFilter.class}
), @Filter(
type = FilterType.CUSTOM,
classes = {AutoConfigurationExcludeFilter.class}
)}
)
a)SpringBootConfiguration
与原生spring中的@Configuration类似,代表这是一个配置类
b)ComponentScan
指定要扫描那些包
c)EnableAutoConfiguration(重点)
点进源码,发现他也是一个合成注解
@AutoConfigurationPackage
@Import({AutoConfigurationImportSelector.class})
public @interface EnableAutoConfiguration {
①@AutoConfigurationPackage
该注解的作用,是实现自动导入包
@Import({AutoConfigurationPackages.Registrar.class})//在容器中导入一个组件
public @interface AutoConfigurationPackage {
利用Registrar来批量导入一系列组件:将指定的一个包下的所有组件导入,没有自己写路径就是MainApplication(主程序)所在包下。
②@Import({AutoConfigurationImportSelector.class})
1、利用getAutoConfigurationEntry方法,在容器中批量导入一些组件

2、调用List configurations = getCandidateConfigurations(annotationMetadata, attributes)获取到所有需要导入到容器中的配置类
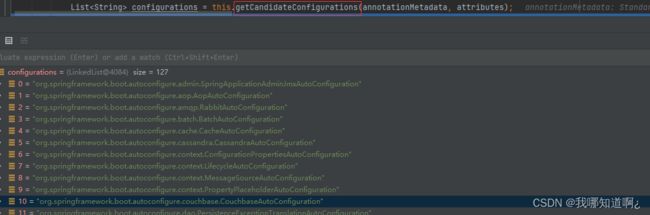
3、利用工厂加载Map
4、从META-INF/spring.factories位置来加载一个文件,默认扫描我们当前系统里面所有META-INF/spring.factories位置的文件
其中,核心在下图的这个包里
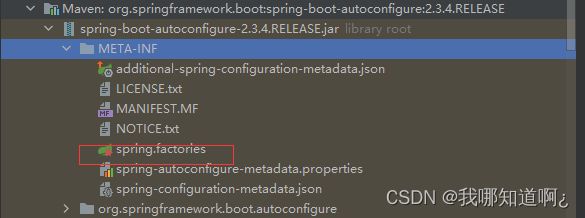
这个文件里面写死了springboot一启动就要给容器中加载的所有配置类,共127个
5、虽然我们127个场景的所有自动配置启动的时候默认全部加载。xxxxAutoConfiguration(某某自动配置类)
每一个xxxxAutoConfiguration类按照条件装配规则(@Conditional),最终会按需配置。
下面举一个文件上传解析器的例子
@Bean
@ConditionalOnBean(MultipartResolver.class) //容器中有这个类型组件
@ConditionalOnMissingBean(name = DispatcherServlet.MULTIPART_RESOLVER_BEAN_NAME) //容器中没有这个名字 multipartResolver 的组件
public MultipartResolver multipartResolver(MultipartResolver resolver) {
//给@Bean标注的方法传入了对象参数,这个参数的值就会从容器中找。
//SpringMVC multipartResolver。防止有些用户配置的文件上传解析器不符合规范
// Detect if the user has created a MultipartResolver but named it incorrectly
return resolver;
}
//最后返回的文件上传解析器名字就是标准的multipartResolver
6、SpringBoot默认会在底层配好所有的组件。但是如果用户自己配置了以用户的优先
下面以用户字符编码过滤器为例,只有用户没配,springboot才会配

7、总结:
● SpringBoot先加载所有的自动配置类 xxxxxAutoConfiguration
● 每个自动配置类按照条件进行生效,默认都会绑定配置文件指定的值。xxxxProperties里面拿。xxxProperties和配置文件application.properties进行了绑定,所以我们只需要改配置文件就可以了
● 生效的配置类就会给容器中装配很多组件
● 只要容器中有这些组件,相当于这些功能就有了
● 定制化配置
○ 用户直接自己@Bean替换底层的组件
○ 用户去看这个组件是获取的配置文件什么值就去修改,可以查看官方文档去看有什么配置文件
xxxxxAutoConfiguration —> 组件 —> xxxxProperties里面拿值 ---->application.properties
4.如何开发一个SpringBoot应用?
1、引入场景依赖,这里可以参考官方文档,下面是链接
starter
2、引入场景依赖后,我们可以查看他为我们自动配置了什么
①自己分析,比较繁琐
②在配置文件中输入debug=true开启自动配置报告,再运行,然后观察控制台


3、检查是否需要修改
①自己分析,查看xxxxProperties绑定了配置文件的哪些,同样较为繁琐
②参照文档来修改配置
properties
4、 自定义加入或者替换组件
@Bean、@Component等等,或者还有XXXXXCustomizer等自定义器,后面会说到
5.几个开发小工具(Lombok,dev-tools,Spring Initailizr)
a)Lombok
简化javabean的开发,可以简化我们在写javabean时,要写构造方法,set方法的一系列流程
首先先引入依赖
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
dependency>
然后在idea中安装插件,注:版本较新的idea中已经自带了这个插件
完成后我们以后就可以在bean类上使用注释了:
@NoArgsConstructor:无参构造器
@AllArgsConstructor:有参构造器
@Data:get和set
@ToString
@EqualsAndHashCode:重写equals和HashCode
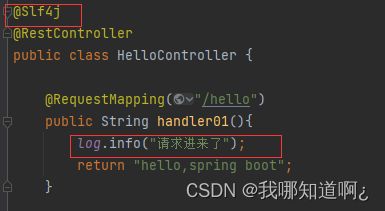
@Slf4j:简化日志,使用方法如下图
b)dev-tools
项目或者页面修改以后:Ctrl+F9就可以生效,不必再重启
引入依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-devtoolsartifactId>
<optional>trueoptional>
dependency>
c)Spring Initailizr
在新建项目时可以直接选择Spring Initailizr,快速创建一个springboot应用
next后直接勾选对应的场景就可以快速创建springboot应用
这样可以自动帮我们创建目录和主程序类,并且在pom.xml中引入好了依赖
6.核心功能
6.1 配置文件-yaml的用法
1.基本语法
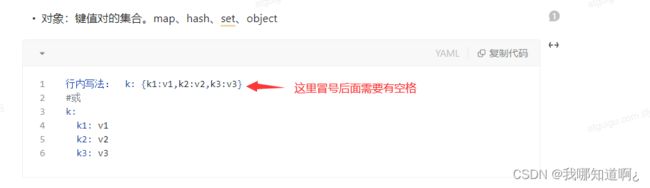
● key: value;kv之间有空格(键值对)
● 大小写敏感
● 使用空格缩进表示层级关系
● 缩进不允许使用tab,只允许空格
● 缩进的空格数不重要,只要相同层级的元素左对齐即可
● '#‘表示注释
● 字符串无需加引号,如果要加,’‘与""表示字符串内容 会被 转义/不转义,例如’'会将\n作为字符串输出,""会将\n作为换行输出
2.创建ymal配置文件

properties的优先级高于ymal
3.数据类型与例子
尚硅谷详细笔记
经过测试,上面笔记中存在一处问题
4.加入配置处理器
我们自定义的类,在写配置的时候一般没有提示,这个时候就可以加入下面的配置处理器
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-configuration-processorartifactId>
<optional>trueoptional>
dependency>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-configuration-processorartifactId>
exclude>
excludes>
configuration>
plugin>
plugins>
build>
6.2 Web开发
springboot已经帮我们完成了大部分的配置,所以我们大多数情况下无需进行复杂的配置比如说,静态资源的自动配置,视图解析器,等等。
6.2.1静态资源规则与定制化
a)静态资源目录
官方的帮助文档中规定了静态资源文件夹的名字,只要静态资源放在这些路径下,我们只需要通过当前项目根路径/+静态资源名就可以访问到了
原理:
静态映射/**(拦截所有请求)
请求一进来,先看Controller能不能处理,若不能,就交给静态资源管理器,就会去下图的几个文件夹中找,如果还找不到,则报404错误

我们也可以设置一个静态资源的访问前缀,默认是无前缀的,我们可以在配置文件中设置
spring:
mvc:
static-path-pattern:这里写你的路径名
这个效果就是当前项目+路径名+静态资源名,就会去你的静态资源文件夹下找
当然,默认的静态资源存储的路径也可以修改
web:
resources:
static-locations: classpath:[/你的文件夹/]
这样修改后,系统就会默认你的静态资源存储在resources中你的文件夹下了,当然,上文的几个静态资源的文件夹同样生效
我们也可以访问webjars
webjars
引入对应的依赖
<dependency>
<groupId>org.webjarsgroupId>
<artifactId>jqueryartifactId>
<version>3.5.1version>
dependency>
访问地址:http://localhost:8080/webjars/jquery/3.5.1/jquery.js 后面地址要按照依赖里面的包路径
6.2.2welcome与favicon
a)欢迎页
两种方式:
- 静态资源下的index.html(可以配置静态资源路径,但是不可以配置静态资源的访问前缀。否则导致 index.html不能被默认访问)
- 若没有上面的html页面,则需要一个能处理/index的controller方法
b)自定义网站图标
我们只需要将我们想设置的网页图标的图片文件名改为favicon.ico ,放在静态资源目录下即可
注意:静态资源的访问前缀也会影响这个功能
6.2.3源码分析(静态资源)
a)静态资源配置原理
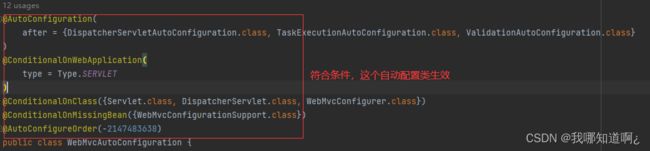
1、首先,SpringBoot启动默认加载 xxxAutoConfiguration 类(自动配置类),SpringMVC功能的自动配置类 WebMvcAutoConfiguration,经过查看,发现其生效
2、再查看这个自动配置类给容器中配了什么,经过寻找,发现了下面这样一个内部类

配置文件的相关属性和xxx进行了绑定。WebMvcProperties== spring.mvc、WebProperties==web.resources
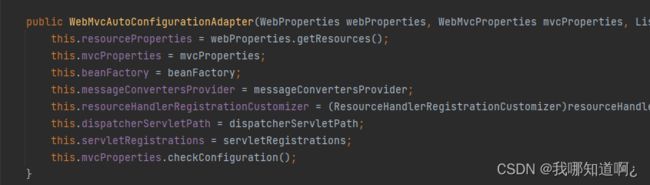
3、这个配置类只有一个有参构造器
那么有参构造器中所有参数的值都会从容器中确定,一共有如下的几个参数
WebProperties webProperties;获取和spring.web绑定的所有的值的对象
WebMvcProperties mvcProperties 获取和spring.mvc绑定的所有的值的对象
ListableBeanFactory beanFactory Spring的beanFactory
HttpMessageConverters 找到所有的HttpMessageConverters
ResourceHandlerRegistrationCustomizer 找到 资源处理器的自定义器。=========
DispatcherServletPath
ServletRegistrationBean 给应用注册Servlet、Filter…
4、下面是静态资源处理的源码
public void addResourceHandlers(ResourceHandlerRegistry registry) {
//1.通过这里发现,我们其实可以禁用掉所有的静态资源
if (!this.resourceProperties.isAddMappings()) {
logger.debug("Default resource handling disabled");
} else {
//这里可以解释我们之前访问webjars静态资源的规则
this.addResourceHandler(registry, "/webjars/**", "classpath:/META-INF/resources/webjars/");
//设置缓存时间
this.addResourceHandler(registry, this.mvcProperties.getStaticPathPattern(), (registration) -> {
//2.点进这个getStaticLocations,我们就可以找到静态资源的默认文件夹
registration.addResourceLocations(this.resourceProperties.getStaticLocations());
if (this.servletContext != null) {
ServletContextResource resource = new ServletContextResource(this.servletContext, "/");
registration.addResourceLocations(new Resource[]{resource});
}
});
}
}
private void addResourceHandler(ResourceHandlerRegistry registry, String pattern, String... locations) {
this.addResourceHandler(registry, pattern, (registration) -> {
registration.addResourceLocations(locations);
});
}
private void addResourceHandler(ResourceHandlerRegistry registry, String pattern, Consumer<ResourceHandlerRegistration> customizer) {
if (!registry.hasMappingForPattern(pattern)) {
ResourceHandlerRegistration registration = registry.addResourceHandler(new String[]{pattern});
customizer.accept(registration);
//通过这个,我们可以发现我们可以设置动态资源的缓存时间
registration.setCachePeriod(this.getSeconds(this.resourceProperties.getCache().getPeriod()));
registration.setCacheControl(this.resourceProperties.getCache().getCachecontrol().toHttpCacheControl());
registration.setUseLastModified(this.resourceProperties.getCache().isUseLastModified());
this.customizeResourceHandlerRegistration(registration);
}
}
1.禁用所有静态资源(add-mappings)
spring:
web:
resources:
add-mappings: false
2.点进getStaticLocations方法找到静态资源的默认文件夹

3.源码中欢迎页的处理规则
@Bean
public WelcomePageHandlerMapping welcomePageHandlerMapping(ApplicationContext applicationContext, FormattingConversionService mvcConversionService, ResourceUrlProvider mvcResourceUrlProvider) {
WelcomePageHandlerMapping welcomePageHandlerMapping = new WelcomePageHandlerMapping(new TemplateAvailabilityProviders(applicationContext), applicationContext, this.getWelcomePage(), this.mvcProperties.getStaticPathPattern());
welcomePageHandlerMapping.setInterceptors(this.getInterceptors(mvcConversionService, mvcResourceUrlProvider));
welcomePageHandlerMapping.setCorsConfigurations(this.getCorsConfigurations());
return welcomePageHandlerMapping;
}
//点进WelcomePageHandlerMapping的构造方法
WelcomePageHandlerMapping(TemplateAvailabilityProviders templateAvailabilityProviders, ApplicationContext applicationContext, Resource welcomePage, String staticPathPattern) {
//要用欢迎页功能,必须是/**
if (welcomePage != null && "/**".equals(staticPathPattern)) {
logger.info("Adding welcome page: " + welcomePage);
this.setRootViewName("forward:index.html");
//如果不是/**,就调用controller,看谁可以处理/index
} else if (this.welcomeTemplateExists(templateAvailabilityProviders, applicationContext)) {
logger.info("Adding welcome page template: index");
this.setRootViewName("index");
}
}
6.2.4Rest风格映射及源码解析
a)请求映射(xxxMapping)
Rest风格的映射例子:
/user GET-获取用户 DELETE-删除用户 PUT-修改用户 POST-保存用户
○ 核心Filter;HiddenHttpMethodFilter
■ 用法: 表单method=post,隐藏域 _method=put
■ SpringBoot中手动开启,我们可以直接运用,下面是个小例子
# 在yaml配置文件中手动开启rest风格
spring:
mvc:
hiddenmethod:
filter:
enabled: true
<form action="/user" method="post">
<input name="_method" type="hidden" value="DELETE">
<input value="REST-DELETE 提交" type="submit"/>
form>
<form action="/user" method="post">
<input name="_method" type="hidden" value="PUT">
<input value="REST-PUT 提交" type="submit"/>
form>
b)rest源码(基于表单提交)
只针对于表单form的提交,因为form不支持put和delete,若使用客户端能直接发这两个请求,就不需要开启这个功能了。
1、表单提交会带上一个_method参数,其值代表真正的请求方式
2、请求过来会被HiddenHttpMethodFilter拦截
3、处理请求
除了post和get,兼容delete与put

4、如何把_method改成我们自己喜欢的名字
自己在容器中放一个HiddenHttpMethodFilter
@Configuration(proxyBeanMethods = false)
public class WebConfig {
@Bean
public HiddenHttpMethodFilter hiddenHttpMethodFilter(){
HiddenHttpMethodFilter hiddenHttpMethodFilter = new HiddenHttpMethodFilter();
hiddenHttpMethodFilter.setMethodParam("_m");//设置名字
return hiddenHttpMethodFilter;
}
}
c)源码分析映射原理
我们来分析一下DispatcherServlet的继承关系

SpringMVC功能分析都从 org.springframework.web.servlet.DispatcherServlet-》doDispatch()开启分析
protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
HttpServletRequest processedRequest = request;
HandlerExecutionChain mappedHandler = null;
boolean multipartRequestParsed = false;
WebAsyncManager asyncManager = WebAsyncUtils.getAsyncManager(request);
try {
try {
ModelAndView mv = null;
Exception dispatchException = null;
try {
processedRequest = this.checkMultipart(request);
multipartRequestParsed = processedRequest != request;
//这一行源码就是找到哪个Handler(Controller)方法进行处理
mappedHandler = this.getHandler(processedRequest);
我们点进这个getHandler方法
![]()
HandlerMapping:处理器映射。/xxx->>xxxx

下面是RequestMapping的详细信息
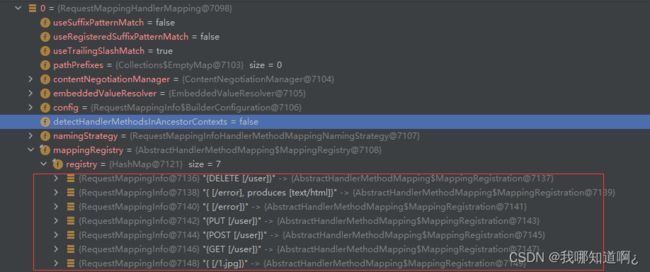
源码的处理流程:
所有的请求映射都在HandlerMapping中。
● SpringBoot自动配置欢迎页的 WelcomePageHandlerMapping 。访问 /能访问到index.html;
● SpringBoot自动配置了默认 的 RequestMappingHandlerMapping,保存用户的映射
● 请求进来,挨个尝试所有的HandlerMapping看是否有请求信息。
○ 如果有就找到这个请求对应的handler
○ 如果没有就是下一个 HandlerMapping
若我们需要一些自定义的映射处理,我们也可以自己给容器中放HandlerMapping。自定义 HandlerMapping
6.2.5常用请求参数注解的使用及源码分析
这些注解与springmvc很类似,可以查看下面这篇文章的获取参数部分
springmvc笔记
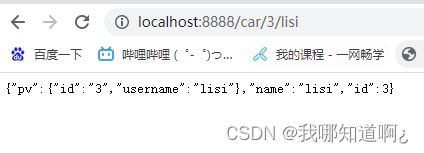
a)@PathVariable
这个注解可以获取占位符风格的参数,也可以将参数直接装在一个map集合中
//PathVariable注解获取请求路径上的变量id
@GetMapping("/car/{id}/{username}")
public Map<String,Object> getCar(@PathVariable("id") Integer id,//获取单个的id参数
@PathVariable("username") String name,//获取单个的name参数
//将获取到的id和name直接放到map中
@PathVariable Map<String,String> pv){
Map<String,Object> map = new HashMap<>();
map.put("id",id);
map.put("name",name);
map.put("pv",pv);
return map;
}
测试效果
b)@RequestHeader
用于获取请求头中的信息
在刚刚的方法参数中加上:
//获取请求头中的User-Agent信息
@RequestHeader("User-Agent") String userAgent,
//获取请求头中的所有信息
@RequestHeader Map<String,String> header

c)RequestParam
获取请求参数
@RequestParam("age") Integer age,
@RequestParam("inters") List<String> inters,
//一次性获取所有参数,放在map中
@RequestParam Map<String,String> params
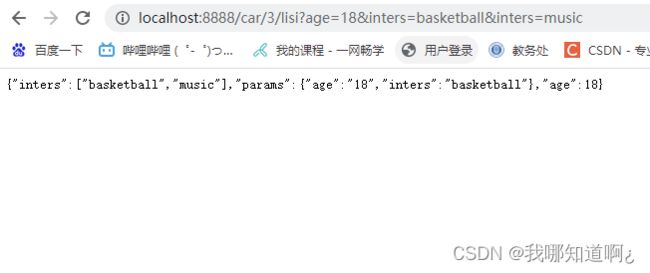
d)@CookieValue
获取Cookie的值
@CookieValue("_ga") String _ga,
//获取Cookie对象
@CookieValue("_ga") Cookie cookie
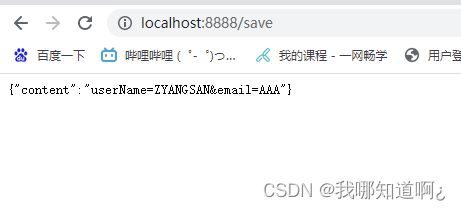
e)@RequestBody
获取请求体信息(只有post请求才有)
@PostMapping("/save")
public Map postMethod(@RequestBody String content){
Map<String,Object> map = new HashMap<>();
map.put("content",content);
return map;
}
这样操作,我们使用字符串获取了一个表单提交过来的username和email
f)@RequestAttribute
获取request域中的属性
@Controller
public class RequestController {
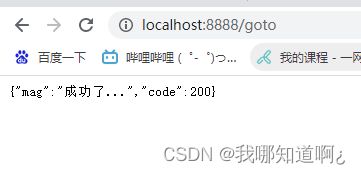
@GetMapping("/goto")
public String gotoPage(HttpServletRequest httpServletRequest){
httpServletRequest.setAttribute("msg","成功了...");
httpServletRequest.setAttribute("code",200);
return "forward:success";//转发到/success请求
}
@ResponseBody//将java对象转化为json响应给浏览器
@GetMapping("/success")
public Map success(@RequestAttribute("msg") String msg,
@RequestAttribute("code") Integer code,
//原始的方式
HttpServletRequest request){
Map<String,Object> map = new HashMap<>();
//原始的方式
Object msg1 = request.getAttribute("msg");
map.put("mag",msg);
map.put("code",code);
return map;
}
}
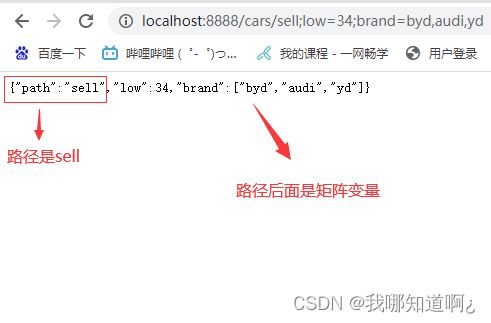
g)@MatrixVariable(矩阵变量)
应用场景:在页面开发中,如果cookie被禁用了,那么session中的值怎么获取。
我们知道,当我们在session中保存了某个数据,每一个session都有一个jessionid,这个id会保存在cookie中,并且每次发请求都会携带cookie,所以发请求时,服务器就可以根据cookie中的这个id,找到session,再调用get方法,就可以找到数据。
这个时候,我们就可以通过url重写,也就是把cookie的值使用矩阵变量的方式进行传递,以分号分割,下面是一个例子
/boss/1;age=20/2;age=20
分号前面,是真正的访问路径,分号后面是矩阵变了
下面是测试,注意,springboot是默认禁用了矩阵变量,需要手动开启
①开启矩阵变量
原理。对于路径的处理。UrlPathHelper进行解析。
removeSemicolonContent(移除分号内容)支持矩阵变量的
@Configuration(proxyBeanMethods = false)
//继承WebMvcConfigurer,重写configurePathMatch方法
public class WebConfig implements WebMvcConfigurer {
@Override
public void configurePathMatch(PathMatchConfigurer configurer) {
UrlPathHelper urlPathHelper = new UrlPathHelper();
//设置不移除分号后面的内容
urlPathHelper.setRemoveSemicolonContent(false);
configurer.setUrlPathHelper(urlPathHelper);
}
}
当然还有第二种写法,直接在配置类中放一个WebMvcConfigurer组件
@Bean
public WebMvcConfigurer webMvcConfigurer(){
return new WebMvcConfigurer() {
@Override
public void configurePathMatch(PathMatchConfigurer configurer) {
UrlPathHelper urlPathHelper = new UrlPathHelper();
urlPathHelper.setRemoveSemicolonContent(false);
configurer.setUrlPathHelper(urlPathHelper);
}
};
}
②测试代码
注意,矩阵变量必须有url路径变量才能被解析
//请求路径:/cars/sell;low=34;brand=byd,audi,yd
@ResponseBody
@GetMapping("/cars/{path}")//path是路径变量
public Map carsSell(@MatrixVariable("low") Integer low,
@MatrixVariable("brand") List<String> brand,
//拿到路径变量
@PathVariable("path") String path){
Map<String,Object> map = new HashMap<>();
map.put("low",low);
map.put("brand",brand);
map.put("path",path);
return map;
}
//请求路径:/boss/1;age=20/2;age=10
@GetMapping("/boss/{bossId}/{empId}")//有两个路径,且每个路径都带有一个矩阵变量,但是变量重名了,所以我们要指定一下路径
@ResponseBody
public Map boss(@MatrixVariable(value = "age",pathVar = "bossId") Integer bossAge,
@MatrixVariable(value = "age",pathVar = "empId") Integer empAge){
Map<String,Object> map = new HashMap<>();
map.put("bossId",bossAge);
map.put("empId",empAge);
return map;
}

h)酸爽的源码解析
①参数处理原理(DispatcherServlet的doDispatch方法开始分析)
通过前面的分析,我们知道了发送一个请求后,首先是在HandlerMapping中找到能处理请求的Handler(Controller)方法
然后继续往下走,为当前的Handler找一个适配器HandlerAdapter(一般都是RequestMappingInfoHandlerMapping),下面是源码片段
![]()
在debug模式中点击进源码中的这行代码,我们发现一共有四种HandlerAdapter

找到RequestMappingInfoHandlerMapping后,继续往后走,就到执行方法

继续往后走,在RequestMappingInfoHandlerMapping中找到了一个方法
//执行目标方法
mav = this.invokeHandlerMethod(request, response, handlerMethod);
再往下走,我们看到了下面的代码,作用是获取参数解析器,
if (this.argumentResolvers != null) {
invocableMethod.setHandlerMethodArgumentResolvers(this.argumentResolvers);
}
这些参数解析器的作用就是解析我们方法中带有注解的参数
springmvc目标方法能写多少种参数类型就取决于参数解析器
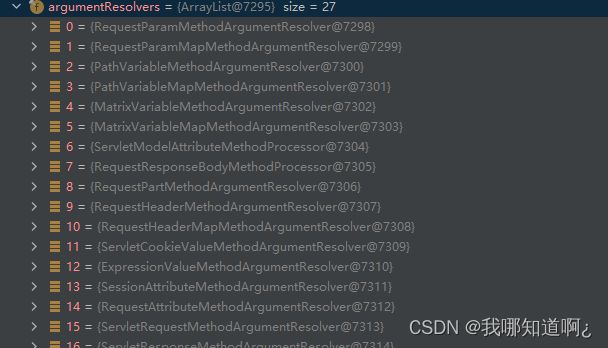
点进参数解析器,他其实是一个接口
功能:
● 判断当前解析器是否支持解析这种参数
● 支持就调用 resolveArgument

继续往下走,一样的,我们有找到了返回值处理器
这就表明了我们的方法可以写多少种返回值
if (this.returnValueHandlers != null) {
invocableMethod.setHandlerMethodReturnValueHandlers(this.returnValueHandlers);
}
共有15种
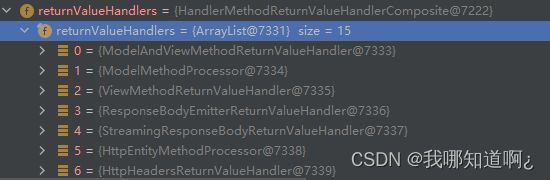
springmvc将上面的参数解析器和返回值处理器都放到了目标方法的可执行方法中
继续往下走,就到了真正执行方法的地方
//RequestMappingInfoHandlerMapping中的方法
invocableMethod.invokeAndHandle(webRequest, mavContainer, new Object[0]);
//点进上面的方法后的方法,执行完这个后就执行我们的方法
Object returnValue = this.invokeForRequest(webRequest, mavContainer, providedArgs);
//点进上面的方法,执行第二步:获取我们方法的参数值
Object[] args = this.getMethodArgumentValues(request, mavContainer, providedArgs);
所以,获取方法参数的关键代码,就是getMethodArgumentValues方法
这个方法在InvocableHandlerMethod类中
protected Object[] getMethodArgumentValues(NativeWebRequest request, @Nullable ModelAndViewContainer mavContainer, Object... providedArgs) throws Exception {
//获取每一个参数的详细信息
MethodParameter[] parameters = this.getMethodParameters();
//判断是否为空,为空就说明无需确定任何值
if (ObjectUtils.isEmpty(parameters)) {
return EMPTY_ARGS;
} else {
//建立一个数组,这个数组最终就返回我们的所有参数中
Object[] args = new Object[parameters.length];
//遍历这些参数
for(int i = 0; i < parameters.length; ++i) {
//初始化,不用管
MethodParameter parameter = parameters[i];
parameter.initParameterNameDiscovery(this.parameterNameDiscoverer);
args[i] = findProvidedArgument(parameter, providedArgs);
if (args[i] == null) {
//遍历27个解析器,判断解析器是否支持这种参数类型,支持就放入缓存
if (!this.resolvers.supportsParameter(parameter)) {
throw new IllegalStateException(formatArgumentError(parameter, "No suitable resolver"));
}
try {
//进入到解析流程,原理就是从缓存中拿出符合条件的参数解析器,然后调用解析器解析这个参数
args[i] = this.resolvers.resolveArgument(parameter, mavContainer, request, this.dataBinderFactory);
} catch (Exception var10) {
if (logger.isDebugEnabled()) {
String exMsg = var10.getMessage();
if (exMsg != null && !exMsg.contains(parameter.getExecutable().toGenericString())) {
logger.debug(formatArgumentError(parameter, exMsg));
}
}
throw var10;
}
}
}
return args;
}
}
目标方法执行完后,将所有数据放在ModelAndViewContainer,包含要去的页面地址View,还包含Model数据
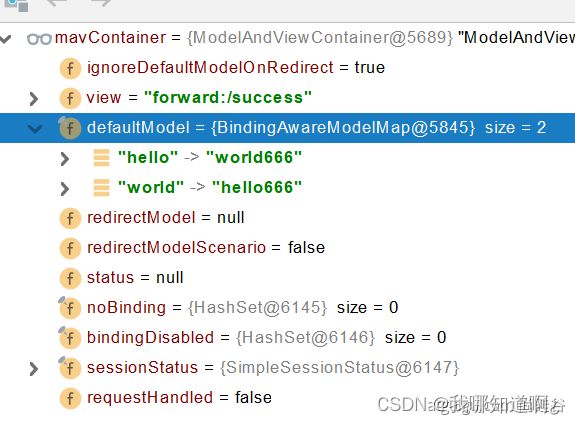
最后就是处理结果了
//从这个方法开始
processDispatchResult(processedRequest, response, mappedHandler, mv, dispatchException);
//通过层层深入,最终通过这个方法将其中的数据保存到request域中
renderMergedOutputModel(mergedModel, getRequestToExpose(request), response);
②ServletAPI参数解析原理
在我们的控制器方法中,我们经常也会传入原生的servlet参数,与上面的流程类似,这些原生的参数是由ServletRequestMethodArgumentResolver这个参数解析器解析的
③Model、Map参数的解析原理
Model,Map里面的数据会被放在request请求域中,相当于调用了request.setAttribute
可以用request.getAttribute获取
这两个参数在解析时的第一步也是先找到他们对应的解析器
Map、Model类型的参数,底层都会调用并返回 mavContainer.getModel();—> BindingAwareModelMap 是Model 也是Map

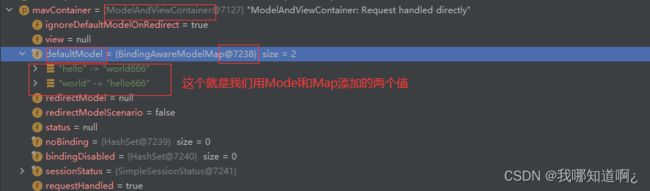
④自定义参数绑定原理
数据绑定:页面提交的请求数据(Post,Get)都可以和我们的自定义对象属性进行绑定,那么接下来就来探究一下他的原理
还是一样的,处理流程的第一步也是找到一个参数解析器,经过debug,发现是ServletModelAttributeMethodProcessor这个参数解析器用于解析自定义参数
为什么会使用这个参数解析器?因为这个解析器会用下面的这些代码来判断方法参数是否为简单类型,其实就是枚举的方式
public static boolean isSimpleValueType(Class<?> type) {
return (Void.class != type && void.class != type &&
(ClassUtils.isPrimitiveOrWrapper(type) ||
Enum.class.isAssignableFrom(type) ||
CharSequence.class.isAssignableFrom(type) ||
Number.class.isAssignableFrom(type) ||
Date.class.isAssignableFrom(type) ||
Temporal.class.isAssignableFrom(type) ||
URI.class == type ||
URL.class == type ||
Locale.class == type ||
Class.class == type));
}
接下来在底层,会创建一个WebDataBinder:web数据绑定器,将请求参数的值绑定到指定的javaBean(由底层创建的空的java对象)中
![]()
在WebDataBinder:web中,有非常多的Converter,他就可以帮助我们Http请求中的字符,通过反射的方式,转换成指定的数据类型,最终绑定到我们的目标对象上,那么是怎么找到对应的Converter呢?其实也很简单,和我们找到参数解析器十分类似,就是遍历所有的Converter,看看哪个Converter能够实现我们需要的转换(request带来的参数的字符串转换成指定的类型)。
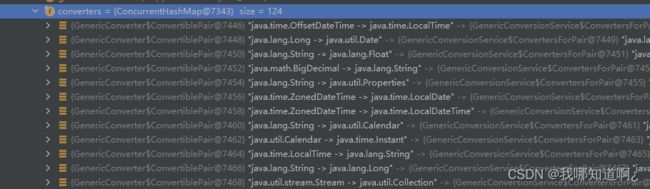
未来我们也可以在WebDataBinder中放自定义的Converter,下面是自定义Converter的例子
假设我们有一张表,提交一个Person对象,Person中又有一个Pet对象,Pet有name和age,那么我们常规的表单设计应该是下面的这种
宠物姓名:<input name="pet.name" value="阿猫"/><br/>
宠物年龄:<input name="pet.age" value="5"/>
但是假如说我们不适用级联属性,像下面这样提交一个字符串,这时候就要用到自定义的Converter了
宠物:<input name="pet" value="阿猫,3">
下面是自定义的代码,也是在配置类中设置WebMvcConfigurer的组件
@Bean
public WebMvcConfigurer webMvcConfigurer(){
return new WebMvcConfigurer() {
@Override
public void addFormatters(FormatterRegistry registry) {
//将Srtring类型转换成Pet对象
registry.addConverter(new Converter<String, Pet>() {
@Override
//这个source就是页面提交过来的值
public Pet convert(String source) {
//阿猫,3
if (!StringUtils.isEmpty(source)){
Pet pet = new Pet();
//以逗号分割字符串
String[] split = source.split(",");
pet.setName(split[0]);
pet.setAge(String.valueOf(Integer.parseInt(split[1])));
return pet;
}
return null;
}
});
}
};
}
6.2.6响应数据处理及源码分析
a)响应json
需要先引入jar包,当然引入web场景后这个会自动帮我们引入
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jsonartifactId>
<version>2.7.1version>
<scope>compilescope>
dependency>
使用时,我们只需要在控制器方法上加上@ResponseBody注解,我们就可以给前段返回json数据了,当然也可以直接在控制器类上写@RestController注解,这样就代表这个控制器中的每个方法都会加上@ResponseBody
接下来就来探究一下返回json数据的原理
首先,在执行之前,springboot底层会自动获取返回值解析器,这个和我们上面获取参数的流程类似
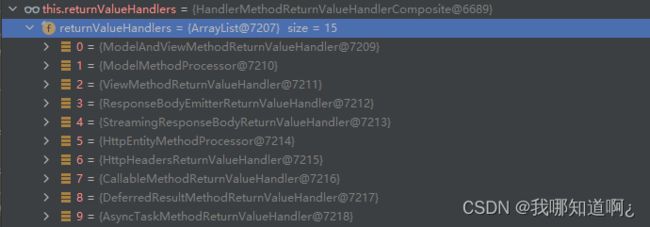
通过debug,我们在源码中发现了这个方法,寻找返回值处理器的原理也和上文寻找参数解析器很类似,都是直接通过遍历查找
public void handleReturnValue(@Nullable Object returnValue, MethodParameter returnType, ModelAndViewContainer mavContainer, NativeWebRequest webRequest) throws Exception {
//寻找符合条件的返回值处理器(遍历所有的返回值处理器)
HandlerMethodReturnValueHandler handler = this.selectHandler(returnValue, returnType);
if (handler == null) {
throw new IllegalArgumentException("Unknown return value type: " + returnType.getParameterType().getName());
} else {
//调用找到的处理器来处理返回值
handler.handleReturnValue(returnValue, returnType, mavContainer, webRequest);
}
}
下面是返回值处理器的逻辑
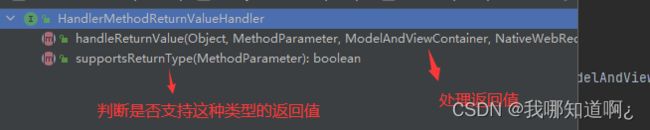
最后我们发现,我们带有@ResponseBody注解的,是用RequestResponseBodyMethodProcessor这个处理器来处理的
下面来拓展一下我们可以写的所有返回值的类型
ModelAndView
Model
View
ResponseEntity
ResponseBodyEmitter
StreamingResponseBody
HttpEntity
HttpHeaders
Callable
DeferredResult
ListenableFuture
CompletionStage
WebAsyncTask
有 @ModelAttribute 且为对象类型的
@ResponseBody 注解 —> RequestResponseBodyMethodProcessor;
寻找完返回值处理器后,就要处理返回值了,通过debug,我们在RequestResponseBodyMethodProcessor类中找到了最终处理返回值的方法,翻译过来就是利用MessageConverter(消息处理器)把返回值写为json

通过寻找消息转换器后(下文内容协商的内容),最终通过MappingJackson2HttpMessageConverter把对象转换为json
所以@ResponseBody注解的实质就是在底层调用返回值处理器里面的消息处理器进行处理,实现将数据转换为json给服务器
b)内容协商
1.浏览器默认会用请求头的方式告诉服务器他能接受什么样的内容类型
2.服务器最终根据自身的能力,决定服务器能生产出什么样内容类型的数据
3.springMVC会遍历所有容器底层的HttpMessageConverter(消息转化器),看谁能处理
4.最终根据客户端接受能力的不同,返回不同媒体类型的数据
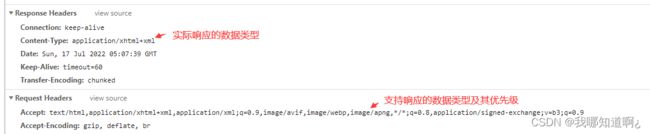
HttpMessageConverter: 看是否支持将 此 Class类型的对象,转为MediaType类型的数据。
例子:Person对象转为JSON。或者 JSON转为Person
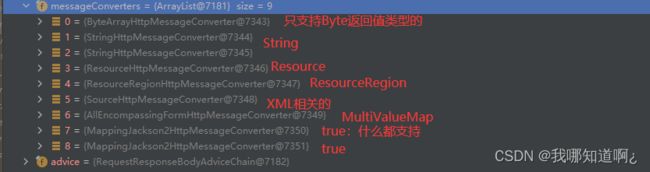
下面是系统中自带的MessageConverter,系统会遍历这些MessageConverter,判断是否可以处理,当然,我们导入对应的jar包后,对应的MessageConverter就会自动添加进来
内容协商的原理:
1、 判断当前响应头中是否已经有确定的媒体类型,如果有,就用之前确定的媒体类型,如果没有,继续往后

2、获取客户端支持的支持接受的请求类型(获取客户端Accept请求头字段)【application/xml】

3、遍历循环所有当前系统的MessageConverter,看谁支持操作我们的方法返回值对象【Person】
4、找到支持操作Person的Converter,把Converter支持的媒体类型(可以返回给客户端的)统计出来
5、客户端需要【application/xml】,当前服务端的能力【10种,json,xml】
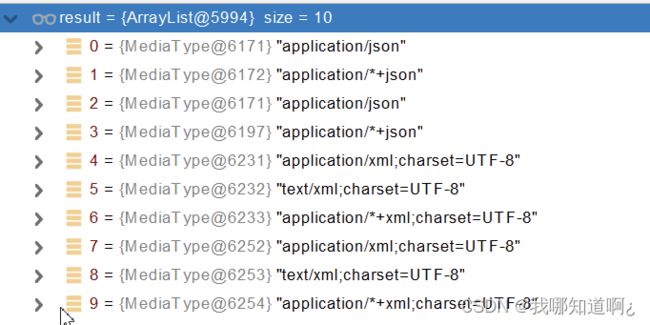
6、下面进入最关键的匹配阶段,其实就是一个双重循环(最佳匹配),对于上面的那个例子,客户端需要【application/xml】,进行最佳匹配后,我们发现4号和7号MessageConverter可以处理

7、按照权重给上面找到的MessageConverter进行排序,用优先级最高的进行数据的处理
c)响应xml
首先还是引入xml依赖
<dependency>
<groupId>com.fasterxml.jackson.dataformatgroupId>
<artifactId>jackson-dataformat-xmlartifactId>
dependency>
d)基于请求参数的内容协商
上文的内容协商是基于请求头中的accept参数的,为了方便内容协商,我们也可以使用基于请求参数的内容协商
首先 在yaml配置文件中设置这个参数为true
![]()
使用时我们只需要在请求后加上一个format参数
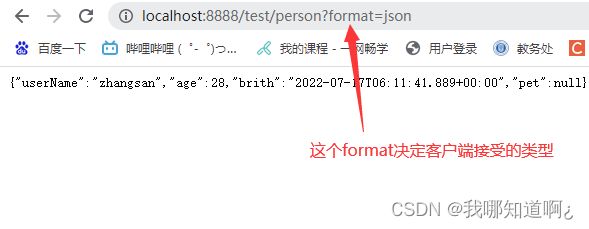
基于参数的内容协商他的优先级是高于基于请求头的
总结一下前面的响应数据的原理
0、@ResponseBody 响应数据出去 调用 RequestResponseBodyMethodProcessor 处理
1、Processor 处理方法返回值。通过 MessageConverter 处理
2、所有 MessageConverter 合起来可以支持各种媒体类型数据的操作(读、写)
3、内容协商找到最终的 messageConverter;
e)自定义MessageConverter
背景:
当app发请求,他需要服务器返回application/x-guigu这种类型的媒体数据,我们就需要我们自定义的MessageConverter来进行数据的转换
最简单的方法一就是写三个方法,三种请求各对应自己的方法,但有了内容协商后,我们就可以使用一个方法来实现这个功能
步骤:
1、添加自定义的messageConverter进系统底层
想要改SpringMVC的什么功能。给容器中添加一个 WebMvcConfigurer,修改即可
@Bean
public WebMvcConfigurer webMvcConfigurer(){
return new WebMvcConfigurer() {
@Override
//重写这个方法:extend代表额外添加
public void extendMessageConverters(List<HttpMessageConverter<?>> converters) {
//这里添加我们自己创建的MessageConverter
converters.add(new GuiguMessageConverter());
}
}
}
这个是自己创建的MessageConverter(基于请求头的内容协商),这样设置完后,若请求头中accept的值是application/x-guigu系统就会调用我们自己定义的这个MessageConverter来进行数据的转换
/**
* 这是我们自定义的MessageConverter类
*/
public class GuiguMessageConverter implements HttpMessageConverter<Person> //这个MessageConverter可以操作Person类数据,并将Person类的数据转换成我们的自定义数据类型application/x-guigu返回给客户端{
//能不能把我们的数据读成某个类型,这与我们的要求无关,所以直接返回false
@Override
public boolean canRead(Class<?> clazz, MediaType mediaType) {
return false;
}
//能不能写
@Override
public boolean canWrite(Class<?> clazz, MediaType mediaType) {
//只要是person类型就进行写
return clazz.isAssignableFrom(Person.class);
}
//获取所有MessageConverter能写出的内容类型
@Override
public List<MediaType> getSupportedMediaTypes() {
//这里返回我们的自定义数据类型,当服务器得知我们要返回这种类型的数据给客户端时,就会调用这个MessageConverter
return MediaType.parseMediaTypes("application/x-guigu");
}
@Override
public Person read(Class<? extends Person> clazz, HttpInputMessage inputMessage) throws IOException, HttpMessageNotReadableException {
return null;
}
@Override
public void write(Person person, MediaType contentType, HttpOutputMessage outputMessage) throws IOException, HttpMessageNotWritableException {
//自定义协议的数据写出
String data = person.getUserName()+";"+person.getAge()+";"+person.getBrith();
//写出去
OutputStream body = outputMessage.getBody();
body.write(data.getBytes());
}
}
注意,基于参数的内容协商默认只支持json和xml,如下图所示
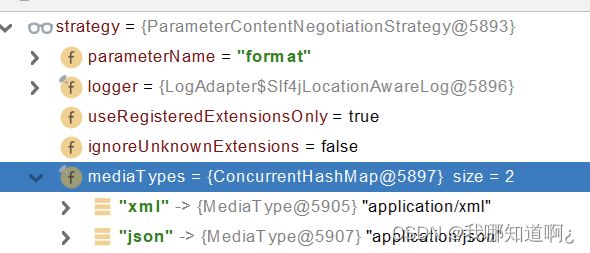
所以我们需要在WebMvcConfigurer中配置内容协商功能
@Bean
public WebMvcConfigurer webMvcConfigurer(){
return new WebMvcConfigurer() {
/**
* 自定义内容协商策略后,我们的format就可以传三种值了
* @param configurer
*/
@Override
public void configureContentNegotiation(ContentNegotiationConfigurer configurer) {
//传入支持的媒体类型
Map<String, MediaType> mediaTypes = new HashMap<>();
//指定支持解析哪些参数对应的哪些媒体类型
//这两个是系统默认的,这个会覆盖系统原来的协商策略,键是format的值,值是返回给客户端的类型
mediaTypes.put("json",MediaType.APPLICATION_JSON);
mediaTypes.put("xml",MediaType.APPLICATION_XML);
//这个是我们自定义的
mediaTypes.put("gg",MediaType.parseMediaType("application/x-guigu"));
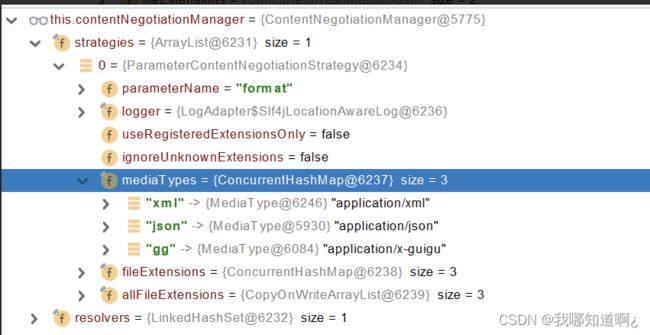
ParameterContentNegotiationStrategy strategy = new ParameterContentNegotiationStrategy(mediaTypes);
//自己设置内容协商策略,系统默认是json和xml
configurer.strategies(Arrays.asList(strategy));
}
重写后,我们的format就可以识别三个参数了,然后底部运行时,后面的流程就和基于请求头内容协商一致了
但注意我们配置了内容协商以后,我们基于请求头的就失效了,因为系统里面的策略只剩一个基于参数的了,无论请求头中的accept是什么,最终都会返回json,为了保持基于请求头的正常运行,我们在配置时,要加上一个基于请求头的策略
HeaderContentNegotiationStrategy strategy1 = new HeaderContentNegotiationStrategy();
//自己设置内容协商策略,系统默认是json和xml
configurer.strategies(Arrays.asList(strategy,strategy1));
2、运行时系统底层会统计出所有messageConverter能操作哪些类型
3、客户端协商后若符合条件,就会调用我们自定义的MessageConverter
6.2.7视图解析及源码解析(Thymeleaf)
注意,springboot默认不支持jsp,需要引入第三方模板引擎技术实现页面渲染
具体有哪些第三方的模板引擎详情见帮助文档
视图的处理方式主要有:转发,重定向和自定义视图三种
a)Thymeleaf的简单语法
Thymeleaf3.0帮助文档
详情见
尚硅谷官方笔记
b)Thymeleaf的使用
1、引入starter
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-thymeleafartifactId>
dependency>
2、引入后springboot就自动配置好了Thymeleaf
@AutoConfiguration(
after = {WebMvcAutoConfiguration.class, WebFluxAutoConfiguration.class}
)
@EnableConfigurationProperties({ThymeleafProperties.class})
@ConditionalOnClass({TemplateMode.class, SpringTemplateEngine.class})
@Import({TemplateEngineConfigurations.ReactiveTemplateEngineConfiguration.class, TemplateEngineConfigurations.DefaultTemplateEngineConfiguration.class})
public class ThymeleafAutoConfiguration {
自动配好的策略:
①所有的Thymeleaf的配置值都在ThymeleafProperties
②配置好了SpringTemplateEngine
③配置好了配好了 ThymeleafViewResolver
④我们只需要直接开发页面即可
3、Thymeleaf的页面位置
打开源码:
//放在资源目录的templates文件夹下
public static final String DEFAULT_PREFIX = "classpath:/templates/";
//后缀是.html
public static final String DEFAULT_SUFFIX = ".html";
4、一个简单的小案例
控制器方法
@Controller
public class ViewTestController {
@GetMapping("/atguigu")
public String atguigu(Model model){
//model中的数据会被放在请求域中,相当于request.setAttribute
model.addAttribute("msg","你好!");
model.addAttribute("link","http://www.baidu.com");
//这里直接写html文件的名字即可,就代表我们要去的是template中的success.html页面
return "success";
}
}
template下的success.html
DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>Titletitle>
head>
<body>
<h1 th:text="${msg}">h1>
<h2>
<a th:href="${link}">去百度a>
<a th:href="@{link}">去百度a>
h2>
body>
html>
c)构建一个后台管理系统
尚硅谷springboot笔记
所用到的静态资源的下载地址
视频教程:P43-P45
Thymeleaf官方文档中对公共资源引用的介绍:
<body>
...
<div th:insert="footer :: copy">div>
<div th:replace="footer :: copy">div>
<div th:include="footer :: copy">div>
body>
<body>
...
<div>
<footer>
© 2011 The Good Thymes Virtual Grocery
footer>
div>
<footer>
© 2011 The Good Thymes Virtual Grocery
footer>
<div>
© 2011 The Good Thymes Virtual Grocery
div>
body>
d)视图解析器与视图的源码解析
1、执行目标方法的流程与上文说到的参数解析类似,接受到请求后, 先找到适配器,然后配置好参数解析器以及返回值处理器,返回值就是我们return的字符串,通过遍历返回值处理器,最终我们发现,处理字符串的返回值处理器是ViewNameMethodReturnValueHandler。将数据 放在 ModelAndViewContainer 里面。包括数据和视图地址
2、方法的参数是一个自定义类型对象(从请求参数中确定的),也会把他重新放在 ModelAndViewContainer中
3、任何目标方法执行完成以后都会返回 ModelAndView(数据(操作目标方法时,在model中放的数据)和视图地址(目标方法返回值))。
4、processDispatchResult(DispatcherServlet中的方法) 处理派发结果(页面改如何响应)
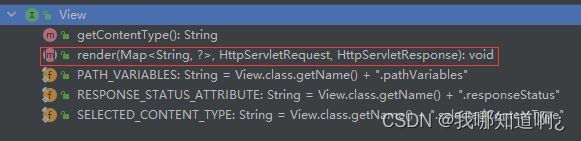
①调用render(mv(ModelAndView), request, response);进行页面渲染逻辑,根据方法的String返回值得到 View 对象【定义了页面的渲染逻辑】
a)所有的视图解析器尝试是否能根据当前返回值得到View对象,共有五个解析器
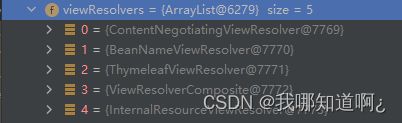
b)我测试用的方法返回值是 redirect:/main.html,通过debug发现调用了上图中的Thymeleaf解析器创建了一个RedirectView(重定向视图)
c)ContentNegotiationViewResolver 里面包含了上图所有的视图解析器,内部还是遍历上图所有视图解析器得到视图对象。
d)视图对象调用自定义的render方法进行页面渲染工作,分两步,第一步就是获取目标的url地址,然后调用原生的servlet重定向:response.sendRedirect();
5、上面是以redirect重定向为例子,下面是视图解析的一般过程,这个在学习springMVC的时候已经涉及到了
视图解析:
○ 返回值以 forward: 开始: 创建一个转发视图,new InternalResourceView(forwardUrl); --> 转发调用了原生servlet中的
request.getRequestDispatcher(path).forward(request, response);
○ 返回值以 redirect: 开始: 创建一个重定向视图,new RedirectView() --》 render就是重定向
○ 返回值是普通字符串: new ThymeleafView()—>
6.2.8拦截器及其源码分析
a)HandlerInterceptor 接口
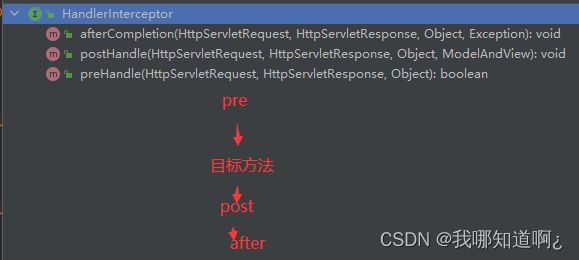
下面是一个拦截器的例子
/**
* 此拦截器的作用:登录检查
* 1.配置好拦截器要拦截哪些请求
* 2.把这些配置放在容器中
*/
@Slf4j
public class LoginInterceptor implements HandlerInterceptor {
@Override
//目标方法执行之前
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String requestUrl = request.getRequestURI();
log.info("拦截的请求路径是"+requestUrl);
//在执行方法之前检查登录
HttpSession session = request.getSession();
Object loginUser = session.getAttribute("loginUser");
if (loginUser!=null)
return true;//放行
//拦截住,跳转到登录页
request.setAttribute("msg","请先登录");
// response.sendRedirect("/");
request.getRequestDispatcher("/").forward(request,response);
return false;
}
@Override
//目标方法执行完成后
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
log.info("postHandle在方法执行完后执行");
}
@Override
//页面渲染完成后
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
log.info("afterCompletion在页面渲染完成后执行");
}
}
下面是在配置类中加入这个拦截器
//配置类,所有实现web功能的,都实现WebMvcConfigurer这个接口
@Configuration
public class AdminWebConfig implements WebMvcConfigurer {
//重写这个方法
@Override
public void addInterceptors(InterceptorRegistry registry) {
//加入拦截器
registry.addInterceptor(new LoginInterceptor())
//拦截哪些请求
.addPathPatterns("/**")// /**代表所有请求,包括静态资源
//不拦截哪些请求
.excludePathPatterns("/","/login","/css/**","/js/**","/fonts/**","/images/**");//要注意放行静态资源
}
}
b)源码分析
拦截器的三个方法执行顺序与springmvc类似,可以参考我之前笔记中的拦截器源码部分
springmvc笔记
1、根据当前请求,找到可以处理请求的handler以及所有的拦截器

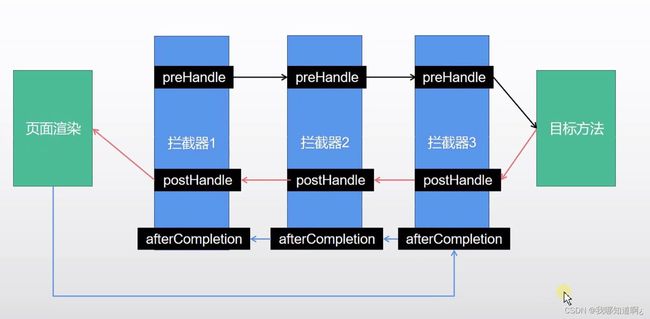
2、先来顺序执行所有拦截器的preHandle方法,如果返回为true,则执行下一个拦截器的preHandle,如果返回为false,直接倒序执行所有已经执行的拦截器的afterCompletion,如果任何一个拦截器的preHandle返回false,就直接跳出

3、如果所有的拦截器preHandle都返回true,执行目标方法,倒序执行所有拦截器的postHandle方法,前面的所有步骤如果有任何异常,都会直接触发已执行拦截器的afterCompletion方法

4、页面渲染完后,倒序执行已执行拦截器的afterCompletion
5、用一张图来形象生动的描述
6.2.9文件上传及源码解析
a)测试用表单
<form role="form" th:action="@{/upload}" method="post" enctype="multipart/form-data">
<div class="form-group">
<label for="exampleInputEmail1">邮箱label>
<input type="email" name="email" class="form-control" id="exampleInputEmail1" placeholder="Enter email">
div>
<div class="form-group">
<label for="exampleInputPassword1">名字label>
<input type="text" name="username" class="form-control" id="exampleInputPassword1" placeholder="Password">
div>
<div class="form-group">
<label for="exampleInputFile">头像label>
<input type="file" name="headerImg" id="exampleInputFile">
div>
<div class="form-group">
<label for="exampleInputFile">生活照label>
<input type="file" name="photos" multiple>
div>
<div class="checkbox">
<label>
<input type="checkbox"> Check me out
label>
div>
<button type="submit" class="btn btn-primary">提交button>
form>
b)在配置文件中修改相关设置
所有根文件有关的设置的开头
c)用于接受并保存文件的控制器方法
重点:@RequestPar注解,MultipartFile ,transferTo方法
//MultipartFile:自动封装上传过来的文件
@PostMapping("/upload")
public String upload(@RequestParam("email") String email,
@RequestParam("username") String username,
@RequestPart("headerImg") MultipartFile headerImg,
@RequestPart("photos") MultipartFile[] photos) throws IOException {
log.info("上传信息email={},username={},headerImg={},photos={}",
email,username,headerImg.getSize(),photos.length);
//把文件保存到服务器
if (!headerImg.isEmpty()){
//保存
String Filename = headerImg.getOriginalFilename();
headerImg.transferTo(new File("C:\\temp\\"+Filename));
}
if (photos.length>0){
for (MultipartFile photo : photos) {
if (!photo.isEmpty()){
String Filename = photo.getOriginalFilename();
photo.transferTo(new File("C:\\temp\\"+Filename));
}
}
}
return "main";
}
d)源码分析文件上传原理
1、首先springboot帮我们自动配置的和文件上传有关的功能,都在MultipartAutoConfiguration这个类中
①自动配置好了StandardServletMultipartResolver(文件上传解析器),需要替换的话我们只需要在容器中自己放一个MultipartResolver类就行了
原理步骤:
1、当请求发送时,先使用文件上传解析器的isMultipart方法判断是不是一个文件上传请求,依据就是我们表单提交时的enctype属性,如果是,就将请求封装成一个MultipartHttpServletRequest(文件上传请求)并返回
2、经过debug,发现使用的是下图的参数解析器来解析请求中的文件内容封装成MultipartFile

3、底层实现的功能:将request中文件信息封装为一个Map;MultiValueMap
6.2.10springboot的异常处理机制即源码分析
详细的可以在官方文档的
a)默认规则
● 默认情况下,Spring Boot提供/error处理所有错误的映射
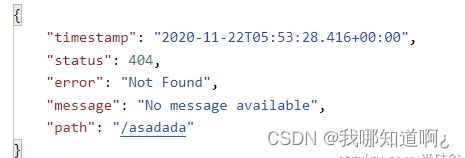
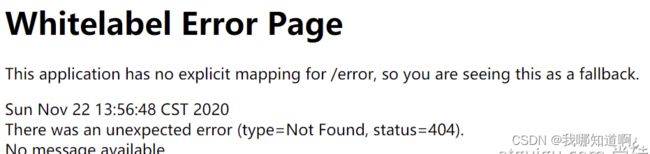
● 对于机器客户端,它将生成JSON响应,其中包含错误,HTTP状态和异常消息的详细信息。对于浏览器客户端,响应一个“ whitelabel”错误视图,以HTML格式呈现相同的数据
机器客户端的json:
浏览器客户端的白页:
b)自定义错误处理逻辑
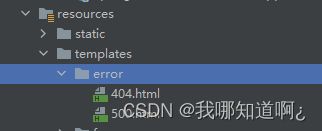
● 要完全替换默认行为,可以实现 ErrorController 并注册该类型的Bean定义,或添加ErrorAttributes类型的组件以使用现有机制但替换其内容。
● (templates或者静态资源文件夹下的)error/下的4xx,5xx页面会被自动解析;
注意:若将404改为4xx,那么所有4开头的错误都会最终响应为4xx.html
c)异常处理的自动配置原理(源码)
下面是三个组件,通过分析源码中这三个组件的作用,我们就可以知道当我们要自定义错误信息时,要修改哪个错误组件了
1、找到ErrorMvcAutoConfiguration这个类,它自动配置了异常处理规则,下面是容器中的各个组件
○ 容器中的组件:类型:DefaultErrorAttributes -> id:errorAttributes
■ public class DefaultErrorAttributes implements ErrorAttributes, HandlerExceptionResolver
■ DefaultErrorAttributes:定义错误页面中可以包含哪些数据(下图只是一部分)
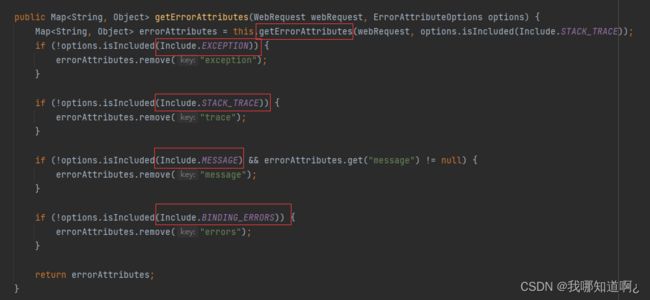
○ 容器中的组件:类型:BasicErrorController --> id:basicErrorController(json(客户端)+白页(浏览器))
■ 处理默认 /error 路径的请求;页面响应 new ModelAndView(“error”, model);

■ 容器中有组件 View->id是error;(响应默认错误页)
■ 容器中放组件 BeanNameViewResolver(视图解析器);按照返回的视图名作为组件的id去容器中找View对象。
所以如果想要返回页面,就会找error视图【StaticView】(默认是一个白页)
在BasicErrorController中有两个方法,一个是响应json的,一个是响应页面的
响应页面的

响应json的

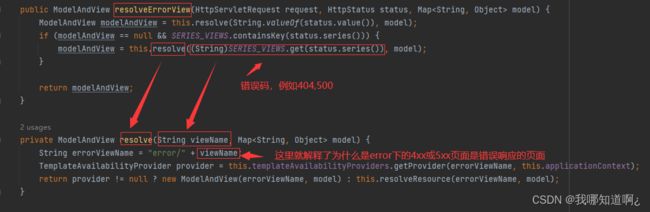
○ 容器中的组件:类型:DefaultErrorViewResolver -> id:conventionErrorViewResolver
■ 如果发生错误,会以HTTP的状态码 作为视图页地址(viewName),找到真正的页面
■ error/viewName.html
d)异常处理的流程(源码)
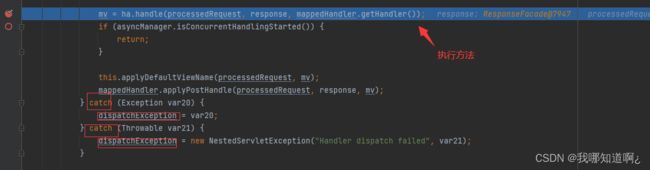
1、执行目标方法,目标方法运行期间有任何异常,都会被catch,而且标志当前请求结束,并且用dispatchException封装
2、进入视图解析流程(准备页面跳转)
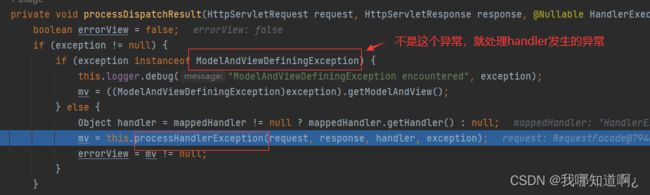
this.processDispatchResult(processedRequest, response, mappedHandler, mv, (Exception)dispatchException);
3、处理handler发生的异常,处理完成返回mv(ModelAndView)
4、第三步中处理handler发生的异常的第一步:遍历所有的handlerExceptionResolvers(异常解析器),看谁可以处理异常,系统默认的异常解析器
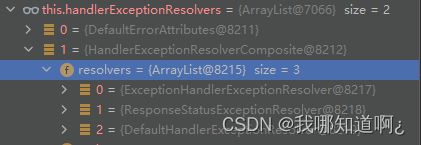
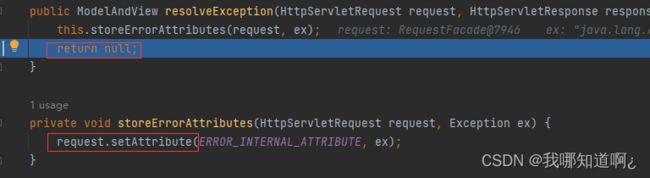
5、 DefaultErrorAttributes先来处理异常,他把异常信息保存到了request域,并且返回空
6、经过测试,默认没有任何异常解析器能够处理int i = 10/0的异常,所以异常会被抛出,触发拦截器的after方法
7、没有任何人能处理,最终底层就会发送一个/error请求由上文说过的BasicErrorController专门处理
8、最终,调用到了上文的DefaultErrorViewResolver 来响应异常,作用在上文也讲过,就是把响应的状态码作为错误页的地址,然后再找到error/下的html
e)定制错误处理逻辑
方式一:自定义错误页
这个在前面已经讲过,就是error/下的4xx,5xx,有精确的错误状态码页面就匹配精确,没有就找 4xx.html;如果都没有就触发白页
方式二(推荐):@ControllerAdvice+@ExceptionHandler处理全局异常
标有@ExceptionHandler注解的,都是调用了底层的ExceptionHandlerExceptionResolver 这个异常解析器
下面是一个例子,我们专门写了个类,并且有一个方法专门处理空指针和数学异常
/**
* 这个类是全局异常处理器,用来处理整个web controller的异常
*/
@Slf4j
@ControllerAdvice//需要使用这个注解
public class GlobalExceptionHandler {
@ExceptionHandler({ArithmeticException.class,NullPointerException.class})//这个注解表示处理的异常的种类,参数是一个数组
public String handleArithException(Exception e){
log.error("异常是:{}",e);
return "login";//返回一个视图地址,或者直接返回ModelAndView
}
}
方式三:@ResponseStatus+自定义异常
底层是 ResponseStatusExceptionResolver 这个异常解析器,把responsestatus注解的信息底层调用 response.sendError(statusCode, resolvedReason);由tomcat发送的/error,然后再到BasicErrorController,然后到error/下的页面
下面是我们自定义的一个异常类,假设在登录用户过多时,就会抛出这个异常
@ResponseStatus(value = HttpStatus.FORBIDDEN,reason = "用户数量太多")//这个注解的意思就是这个异常可以返回一个状态码
public class UserToManyException extends RuntimeException{
public UserToManyException() {
}
public UserToManyException (String message){
super(message);
}
}
方式四:Spring底层的异常,如 参数类型转换异常
DefaultHandlerExceptionResolver 处理框架底层的异常。可以在前面这个异常解析器的类中,找到有哪些异常的种类
方式五:自定义实现 HandlerExceptionResolver 处理异常
方式二三四中的异常解析器,其实都是HandlerExceptionResolver的一部分,所以我们就可以自定义一个解析器实现这个接口来处理异常,可以作为全局异常处理规则
@Order(value = Ordered.HIGHEST_PRECEDENCE)//这个异常解析器的优先级,数字越小,数字越高
@Component
public class CustomerHandlerExceptionResolver implements HandlerExceptionResolver {
@Override
public ModelAndView resolveException(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) {
try {
response.sendError(511,"我喜欢的错误");
} catch (IOException e) {
throw new RuntimeException(e);
}
return new ModelAndView();
}
}
方式六:ErrorViewResolver 实现自定义处理异常
○ response.sendError 。error请求就会转给controller
○ 你的异常没有任何人能处理。tomcat底层 response.sendError。error请求就会转给controller
○ basicErrorController 要去的页面地址是 ErrorViewResolver ;
所以只要没人处理的异常基本上都能被他捕获
6.2.11原生注解与spring方式注入(Servlet,Filter,Listener)
a)原生servlet API
首先,先写一个原生的servlet,加上@WebServlet注解
经过测试,这个原生的servlet执行并没有经过spring的拦截器
@WebServlet(urlPatterns = "/my")
public class MyServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.getWriter().write("66666");
}
}
然后再主类中加上@ServletComponentScan要扫描的包
@SpringBootApplication
@ServletComponentScan(basePackages = "com.javalearn.admin")
public class SpringbootWebAdminDemoApplication {
注,其他原生组件Filter,Listener都类似于servlet,需要使用@WebFilter或@WebListener加@ServletComponentScan
b)第二种注入方式:使用RegistrationBean(推荐)
写一个配置类,返回:ServletRegistrationBean, FilterRegistrationBean, and ServletListenerRegistrationBean
@Configuration(proxyBeanMethods = true)//true:保证是单实例的
public class MyRegistConfig {
@Bean
public ServletRegistrationBean myServlet(){
//myServlet是自己写的一个原生servlet类,下面同理
MyServlet myServlet = new MyServlet();
return new ServletRegistrationBean(myServlet,"/my","/my02");
}
@Bean
public FilterRegistrationBean myFilter(){
MyFilter myFilter = new MyFilter();
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean(myFilter);
filterRegistrationBean.setUrlPatterns(Arrays.asList("/my","/css/*"));
return filterRegistrationBean;
}
@Bean
public ServletListenerRegistrationBean myListener(){
MyServletContextListener myServletContextListener = new MyServletContextListener();
return new ServletListenerRegistrationBean(myServletContextListener);
}
}
c)DispatcherServlet注入原理
关于DispatcherServlet的自动配置,都在DispatcherServletAutoConfiguration中
1、容器中自动配置了 DispatcherServlet 属性绑定到 WebMvcProperties;对应的配置文件配置项是 spring.mvc。
2、通过 ServletRegistrationBean 把 DispatcherServlet 配置进来。也就是第二种方式
3、默认映射的是 / 路径
之前我们已经学习过:
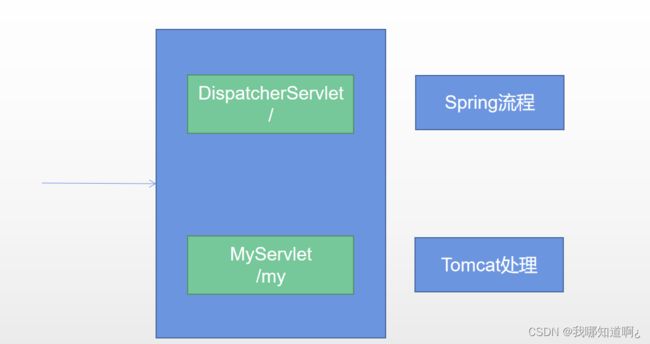
Tomcat-Servlet;
多个Servlet都能处理到同一层路径,精确优选原则(最长匹配原则)
A: /my/
B: /my/1
所以我们刚刚的时候,我们自己写的servlet不会经过spring的拦截器,因为我们发/my请求时,此时有两个servlet,根据最长匹配原则,底层就走了我们自己配置的servlet,所以没有经过spring的流程
6.2.12嵌入式servlet容器及源码分析
1、springboot默认支持的webServer
Tomcat, Jetty, or Undertow
2、原理
○ SpringBoot应用启动发现当前是Web应用。web场景包-导入tomcat
○ web应用会创建一个web版的ioc容器 ServletWebServerApplicationContext
○ ServletWebServerApplicationContext 启动的时候寻找 ServletWebServerFactory(Servlet 的web服务器工厂—> Servlet 的web服务器)
○ SpringBoot底层默认有很多的WebServer工厂;TomcatServletWebServerFactory, JettyServletWebServerFactory, or UndertowServletWebServerFactory
○ 底层直接会有一个自动配置类。ServletWebServerFactoryAutoConfiguration
○ ServletWebServerFactoryAutoConfiguration导入了ServletWebServerFactoryConfiguration(配置类)
○ ServletWebServerFactoryConfiguration 配置类 根据动态判断系统中到底导入了那个Web服务器的包。(默认是web-starter导入tomcat包),容器中就有 TomcatServletWebServerFactory
○ TomcatServletWebServerFactory 创建出Tomcat服务器并启动;TomcatWebServer 的构造器拥有初始化方法initialize—this.tomcat.start();
○ 内嵌服务器,就是手动把启动服务器的代码调用(tomcat核心jar包存在)
3、定制服务器服务器
切换别的服务器,我们只需要首先排除tomcat的导入,然后再导入想用的服务器即可
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-tomcatartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-undertowartifactId>
dependency>
若想对服务器进行修改:
1、修改配置文件 server.xxx(推荐)
2、直接自定义 ConfigurableServletWebServerFactory
6.2.13定制化原理
a)定制化的常见方式
1、 修改配置文件;
2、 xxxxxCustomizer;
3、 编写自定义的配置类 xxxConfiguration;+ @Bean替换、增加容器中默认组件;视图解析器
4、Web应用 编写一个配置类实现 WebMvcConfigurer 即可定制化web功能;+ @Bean给容器中再扩展一些组件
//配置类,所有实现web功能的,都实现WebMvcConfigurer这个接口
@Configuration
public class AdminWebConfig implements WebMvcConfigurer {
5、@EnableWebMvc + WebMvcConfigurer —— @Bean 可以全面接管SpringMVC,所有规则全部自己重新配置(静态资源、视图解析器、欢迎页),所有自动配置全部失效,我们就可以实现定制和扩展功能,这个注解要慎用。
b)原理分析套路
场景starter - xxxxAutoConfiguration - 导入xxx组件 - 绑定xxxProperties – 绑定配置文件项
6.3数据访问
6.3.1SQL
a)导入jdbc场景
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-jdbcartifactId>
dependency>
导入的内容

但是我们发现,官方并没有帮我们导入数据库,所以接下来我们要导入数据库
对应的驱动可以去这个网站搜索
mvn
springboot底层是8版本的,如果要调整版本,需要自己修改(直接依赖引入具体版本或者在properties标签中声明版本)
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
b)分析自动配置
1、自动配置的类:DataSourceAutoConfiguration(数据源的自动配置)
①通过分析发现,想要修改数据源相关的配置,修改配置文件中的spring.datasource就可以了
②且数据库连接池的配置,是自己的容器中没有DataSource才自动配置的
③底层配置好的连接池是:HikariDataSource
2、自动配置的类:DataSourceTransactionManagerAutoConfiguration(数据源的事务)
3、自动配置的类:JdbcTemplateAutoConfiguration: JdbcTemplate的自动配置,可以来对数据库进行crud
○ 可以修改这个配置项@ConfigurationProperties(prefix = “spring.jdbc”) 来修改JdbcTemplate
○ @Bean@Primary JdbcTemplate;容器中有这个组件
4、自动配置的类:JndiDataSourceAutoConfiguration: jndi的自动配置
5、自动配置的类:XADataSourceAutoConfiguration: 分布式事务相关的
c)修改配置项
在yaml配置文件中的
spring:
datasource:
url: jdbc:mysql://localhost:3306/javalearn
username: root
password: 你的密码
driver-class-name: com.mysql.cj.jdbc.Driver
d)测试代码
@Test
void contextLoads() {
Long l =jdbcTemplate.queryForObject("select count(*) from account_tbl",Long.class);
log.info("记录总数:{}",l);
}
6.3.2使用Druid数据源
a)Druid的官方网站
Druid
在这个网站中可以找到官方文档之类的,要整合第三方的技术,通过之前的学习,主要就是自定义和找starter这两种方式
b)自定义方式整合Druid
首先,先引入数据源
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druidartifactId>
<version>1.1.17version>
dependency>
然后通过配置类直接添加到我们的容器中即可,如果需要配置别的功能,比如说监控,防火墙,那么就要可以参考官方文档来配置
详细笔记见尚硅谷springboot笔记
@Configuration
public class MyDataSourceConfig {
//默认的配置是判断容器中没有数据源,才会默认配,所以当我们自己加了以后,默认的数据源就不会生效了
@Bean
@ConfigurationProperties("spring.datasource")//绑定我们配置文件
public DataSource dataSource(){
DruidDataSource dataSource = new DruidDataSource();
// 绑定了配置文件后,就不需要再像下面那样写了
// dataSource.setUrl();
// dataSource.setUsername();
// dataSource.setPassword();
return dataSource;
}
}
所有调用set方法给数据源设置属性的,我们都可以在配置文件中写,然后绑定配置文件
c)Druid数据源的starter整合方式
首先,引入starter
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druid-spring-boot-starterartifactId>
<version>1.1.17version>
dependency>
然后我们分析一下自动配置
①配置文件的扩展配置项:spring.datasource.druid
②自动导入了
DruidSpringAopConfiguration.class:监控spring组件,配置项:spring.datasource.druid.aop-patterns
DruidStatViewServletConfiguration.class:监控页的配置:spring.datasource.druid.stat-view-servlet;默认开启
DruidWebStatFilterConfiguration.class:web监控配置;spring.datasource.druid.web-stat-filter;默认开启
DruidFilterConfiguration.class:所有Druid自己filter的配置
导入完以后,所有的相关设置都可以在设置文件中进行,下面举一个小例子:
spring:
datasource:
url: jdbc:mysql://localhost:3306/javalearn
username: root
password:
driver-class-name: com.mysql.cj.jdbc.Driver
druid:
filters: stat,wall #开启的功能组件
stat-view-servlet: #监控页的配置
enabled: true
login-username: admin
login-password: admin
reset-enable: false
web-stat-filter: #web监控配置
enabled: true
url-pattern: /*
exclusions: "*.js,*.gif,*.png,*.css,*.ico,/druid/*"
aop-patterns: com.javalearn.admin.* #spring监控的范围
filter: #对上面filters的详细设置
stat:
slow-sql-millis: 1000
log-slow-sql: true
enabled: true
wall:
enabled: true
下面是官方文档:
Druid中文官方文档
6.3.3整合mybatis
第三方的starter,铭铭一般都是*-spring-boot-starter
下面是官方的网址
mybatis官方github
a)配置版
首先,引入依赖
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>2.1.4version>
dependency>
然后也是一样的,查看MybatisAutoConfiguration这个自动配置类,发现修改配置文件中mybatis开头的,就可以修改mybatis的配置,下面是通过分析自动配置类得到的结果
● 全局配置文件
● SqlSessionFactory: 自动配置好了
● SqlSession:自动配置了 SqlSessionTemplate 组合了SqlSession
● Mapper: 只要我们写的操作MyBatis的接口标准了 @Mapper 就会被自动扫描进来
@EnableConfigurationProperties(MybatisProperties.class) : MyBatis配置项绑定类。
@AutoConfigureAfter({ DataSourceAutoConfiguration.class, MybatisLanguageDriverAutoConfiguration.class })
public class MybatisAutoConfiguration{}
@ConfigurationProperties(prefix = "mybatis")
public class MybatisProperties
第一步,在yaml配置文件中指定mybatis的全局配置文件和sql映射文件位置
#配置mybatis的两个规则
mybatis:
config-location: classpath:mybatis/mybatis-config.xml
mapper-locations: classpath:mybatis/mapper/*.xml
接下来就和我们之前学习到mybatis使用方法一致了Mapper接口—>绑定Xml,详情见下面的文章:
mybatis学习笔记
注意接口要标注Mpper注解,以前mybatis全局配置文件中的配置,都可以写在配置文件中,以mybatis.configuration开头
下面是配置文件的例子,开启驼峰,可以不写全局;配置文件,所有全局配置文件的配置都放在configuration配置项中即可
#配置mybatis的两个规则
mybatis:
# config-location: classpath:mybatis/mybatis-config.xml 使用了这个就不能使用configuration了
mapper-locations: classpath:mybatis/mapper/*.xml
configuration: #指定mybatis配置文件中的相关项
map-underscore-to-camel-case: true
总结,配置版的步骤:
● 导入mybatis官方starter
● 编写mapper接口。标准@Mapper注解
● 编写sql映射文件并绑定mapper接口
● 在application.yaml中指定Mapper配置文件的位置,以及指定全局配置文件的信息 (建议;配置在mybatis.configuration)
b)注解配置混合版
在新建springboot项目的时候,就可以选择mybatis框架
下面是纯注解整合mybatis的方式,其实很好理解,就是不用写mapper映射文件了,但是这种方式如果设计到复杂SQL,并不推荐使用,涉及到纷杂的sql,推荐使用上面的配置版,也就是混合配置
@Mapper
public interface CityMapper {
@Select("select * from city where id=#{id}")
public City getById(Long id);
}
下面举一个复杂SQL的例子
xml中的
<insert id="insert" useGeneratedKeys="true" keyProperty="id">
insert into city(`name`,`state`,`country`) values (#{name},#{state},#{country})
insert>
若要使用注解:
@Insert("insert into city(`name`,`state`,`country`) values (#{name},#{state},#{country})")
@Options(useGeneratedKeys = true,keyProperty = "id")
public void insert(City city);
最后总结:引入mybatis的最佳实战
● 引入mybatis-starter
● 配置application.yaml中,指定mapper-location位置即可
● 编写Mapper接口并标注@Mapper注解
● 简单方法直接注解方式
● 复杂方法编写mapper.xml进行绑定映射
● 在配置类上用@MapperScan(“mapper接口所在的包”) 简化,其他的接口就可以不用标注@Mapper注解
c)整合mybatis-plus
MyBatis-Plus(简称 MP)是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
下面是官网
mybatis-plus官网
首先,先引入依赖
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.4.1version>
dependency>
然后分析一下自动配置类
● MybatisPlusAutoConfiguration 配置类,MybatisPlusProperties 配置项绑定。mybatis-plus:xxx 就是对mybatis-plus的定制
● SqlSessionFactory 自动配置好。底层是容器中默认的数据源
● mapperLocations 自动配置好的。有默认值。classpath*:/mapper/**/*.xml;任意包的类路径下的所有mapper文件夹下任意路径下的所有xml都是sql映射文件。 建议以后sql映射文件,放在 mapper下
● 容器中也自动配置好了 SqlSessionTemplate
● @Mapper 标注的接口也会被自动扫描;建议直接 @MapperScan 批量扫描就行
优点:
● 只需要我们的Mapper继承 BaseMapper 就可以拥有crud能力,只要不是特别复杂的,我们都不用在自己写映射文件了
6.3.4Redis
a)在pom.xml中引入依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>

b)分析自动配置类RedisAutoConfiguration
找到配置文件的前缀
连接工厂是准备好的,LettuceConnectionConfiguration、JedisConnectionConfiguration
自动注入了RedisTemplate
自动注入了StringRedisTemplate;k:v都是String
底层只要我们使用 StringRedisTemplate、RedisTemplate就可以操作redis
c)redis的环境搭建
1、阿里云按量付费redis。经典网络
2、申请redis的公网连接地址
3、修改白名单 允许0.0.0.0/0 访问
d)springboot操作redis
首先在配置文件中配制好相关的数据
redis:
host: r-bp1h3n11snsrnm9x09pd.redis.rds.aliyuncs.com
port: 6379
password:
password:用户名+:+密码
然后就可以直接使用了,下面写一个测试类
@Autowired
StringRedisTemplate redisTemplate;
@Test
void testRedis(){
ValueOperations<String, String> operations = redisTemplate.opsForValue();
operations.set("hello","world");
String s = operations.get("hello");
System.out.println(s);
}
e)切换至jedis
首先导入依赖:
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
dependency>
然后再配置文件中加上:
client-type: jedis
6.4单元测试(JUnit5)
基本概念见:
尚硅谷单元测试
Spring Boot 2.2.0 版本开始引入 JUnit 5 作为单元测试默认库
首先引入单元测试的依赖(创建springboot工程时会自动帮我们引入)
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
我们创建一个springboot工程后,系统就会自动为我们创建一个有@SpringBootTest注解的测试类,我们在这个类中用@Test写测试方法即可
@SpringBootTest
class Boot05WebAdminApplicationTests {
@Test
void contextLoads() {
}
}
SpringBoot 2.4 以上版本移除了默认对 Vintage 的依赖。如果需要兼容junit4需要自行引入(不能使用junit4的功能 @Test),如果像继续兼容JUnit4,需要加入的依赖
<dependency>
<groupId>org.junit.vintagegroupId>
<artifactId>junit-vintage-engineartifactId>
<scope>testscope>
<exclusions>
<exclusion>
<groupId>org.hamcrestgroupId>
<artifactId>hamcrest-coreartifactId>
exclusion>
exclusions>
dependency>
SpringBoot整合Junit以后。
● 编写测试方法:@Test标注(注意需要使用junit5版本的注解)

● Junit类具有Spring的功能,@Autowired、比如 @Transactional 标注测试方法,测试完成后自动回滚
6.4.1常用测试注解
下面是官方文档
JUnit5官方文档
在官方文档的2.1Annoations中即可找到
6.4.2断言机制
断言(assertions)是测试方法中的核心部分,用来对测试需要满足的条件进行验证。这些断言方法都是 org.junit.jupiter.api.Assertions 的静态方法,得益于断言机制,当所有测试运行结束后,会有一个详细的运行报告(那些方法成功,哪些失败,为什么失败等等)
在项目上线前,我们先clean再test,就可以得到一份完整的测试报告

a)简单断言
用来对单个值进行简单的验证
下面的案例主要测试了assertEquals与assertSame,更多的简单断言可以在Assertions这个类中找到
/**
* 注意,前面的断言只要失败,后面的代码都不会执行
*/
@Test
@DisplayName("测试简单断言")
void testSimpleAssertions(){
int cal = cal(2,3);
Assertions.assertEquals(5,cal,"业务逻辑计算失败");//判断是否相等,可以自定义错误信息
Object obj1 = new Object();
Object obj2 = new Object();
Assertions.assertSame(obj1,obj2,"两个对象不想等");//判断两个对象是否相等
}
//模拟业务逻辑
int cal(int i,int j){
return i+j;
}
b)数组断言
通过 assertArrayEquals 方法来判断两个对象或原始类型的数组是否相等
@Test
@DisplayName("array assertion")
public void array() {
Assertions.assertArrayEquals(new int[]{1, 2}, new int[] {2, 1},"数组内容不想等");
}
c)组合断言
assertAll 方法接受多个 org.junit.jupiter.api.Executable 函数式接口的实例作为要验证的断言,只有全部通过,才会继续往下走
@Test
@DisplayName("assert all")
public void all() {
/**
* 断言全部需要通过,才能往下通过
*/
Assertions.assertAll("test",
()->Assertions.assertTrue(true && true,"结果不为true"),
()->Assertions.assertEquals(1,2,"结果不是1")
);
System.out.println("=====");//没有输出,第二个断言不成立
}
d)异常断言
在JUnit4时期,想要测试方法的异常情况时,需要用@Rule注解的ExpectedException变量还是比较麻烦的。而JUnit5提供了一种新的断言方式Assertions.assertThrows() ,配合函数式编程就可以进行使用。
作用:断定业务逻辑一定会出现异常,若正常运行,则报错
@Test
@DisplayName("异常断言")
void testException(){
Assertions.assertThrows(ArithmeticException.class,()->{
int i=10/2;
}, "业务逻辑居然正常运行了?");
}
e)超时断言
Junit5还提供了Assertions.assertTimeout() 为测试方法设置了超时时间
@Test
@DisplayName("超时测试")
public void timeoutTest() {
//如果测试方法时间超过1s将会异常,前面为超时时间的设置
Assertions.assertTimeout(Duration.ofMillis(1000), () -> Thread.sleep(5000));
}
f)快速失败
通过 fail 方法直接使得测试失败
@Test
@DisplayName("快速失败")
void testFail(){
if (1==2){
Assertions.fail("测试失败");
}
}
6.4.3前置条件
JUnit 5 中的前置条件类似于断言,不同之处在于不满足的断言会使得测试方法失败,而不满足的前置条件只会使得测试方法的执行终止。前置条件可以看成是测试方法执行的前提,当该前提不满足时,就没有继续执行的必要。
使用Assumptions这个包
@Test
@DisplayName("测试添置条件")
void testassumption(){
Assumptions.assumeTrue(false,"结果不是true");
System.out.println("11111");
}
经过看测试报告,我们发现因为不满足前置条件,这个测试方法被跳过了
6.4.4嵌套测试
重点有两个:
1.外层的test不能驱动内层的Before(After)Each/All之类的方法运行
2.内层的test可以驱动外层的Before(After)Each/All之类的方法运行
有了嵌套测试,在直接运行测试类时,就能很方便的看出层级关系
@DisplayName("嵌套测试")
public class TestingAStackDemo {
//定义一个栈
Stack<Object> stack;
@Test
@DisplayName("new Stack()")
void isInstantiatedWithNew() {
new Stack<>();
//在嵌套测试时,外层的test不能驱动内层的Before(After)Each/All之类的方法运行
assertNull(stack);
}
@Nested//这个注解代表是嵌套测试
@DisplayName("when new")
class WhenNew {
@BeforeEach
void createNewStack() {
stack = new Stack<>();
}
@Test
@DisplayName("is empty")
void isEmpty() {
assertTrue(stack.isEmpty());
}
@Test
@DisplayName("throws EmptyStackException when popped")
void throwsExceptionWhenPopped() {
assertThrows(EmptyStackException.class, stack::pop);
}
@Test
@DisplayName("throws EmptyStackException when peeked")
void throwsExceptionWhenPeeked() {
assertThrows(EmptyStackException.class, stack::peek);
}
//内层的test可以驱动外层的Before(After)Each/All之类的方法运行
@Nested
@DisplayName("after pushing an element")
class AfterPushing {
String anElement = "an element";
@BeforeEach
void pushAnElement() {
stack.push(anElement);
}
@Test
@DisplayName("it is no longer empty")
void isNotEmpty() {
assertFalse(stack.isEmpty());
}
@Test
@DisplayName("returns the element when popped and is empty")
void returnElementWhenPopped() {
assertEquals(anElement, stack.pop());
assertTrue(stack.isEmpty());
}
@Test
@DisplayName("returns the element when peeked but remains not empty")
void returnElementWhenPeeked() {
assertEquals(anElement, stack.peek());
assertFalse(stack.isEmpty());
}
}
}
}

6.4.5参数化测试
参数化测试是JUnit5很重要的一个新特性,它使得用不同的参数多次运行测试成为了可能,也为我们的单元测试带来许多便利。
@ValueSource: 为参数化测试指定入参来源,支持八大基础类以及String类型,Class类型
@NullSource: 表示为参数化测试提供一个null的入参
@EnumSource: 表示为参数化测试提供一个枚举入参
@CsvFileSource:表示读取指定CSV文件内容作为参数化测试入参
@MethodSource:表示读取指定方法的返回值作为参数化测试入参(注意方法返回需要是一个流)
@ParameterizedTest//这个注解就代表当前方法是一个参数化测试
@DisplayName("参数化测试")
@ValueSource(ints = {1,2,3,4,5})//参数的来源,在运行测试时,会把这五个数字以此测试一遍,除了数字,其他类型也支持
void testParameteriezd(Integer i){
System.out.println(i);
}
static Stream<String> stringProcider(){
return Stream.of("apple","banana","atguigu");
}
@ParameterizedTest//这个注解就代表当前方法是一个参数化测试
@DisplayName("参数化测试")
@MethodSource("stringProcider")//参数来源于stringProcider方法
void testParameteriezd2(String i){
System.out.println(i);
}
6.4.6迁移指南(JUnit4-JUnit5)
更多细节可以参考官方文档的Migrating from JUnit 4
在进行迁移的时候需要注意如下的变化:
注解在 org.junit.jupiter.api 包中,断言在 org.junit.jupiter.api.Assertions 类中,前置条件在 org.junit.jupiter.api.Assumptions 类中。
把@Before 和@After 替换成@BeforeEach 和@AfterEach。
把@BeforeClass 和@AfterClass 替换成@BeforeAll 和@AfterAll。
把@Ignore 替换成@Disabled。
把@Category 替换成@Tag。
把@RunWith、@Rule 和@ClassRule 替换成@ExtendWith。
6.5指标监控
a)SpringBoot Actuator
未来每一个微服务在云上部署以后,我们都需要对其进行监控、追踪、审计、控制等。SpringBoot就抽取了Actuator场景,使得我们每个微服务快速引用即可获得生产级别的应用监控、审计等功能。
具体简介见:
尚硅谷springboot指标监控笔记
且springboot的官方文档也有专门的一节Actuator

b)如何使用
首先,引入依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-actuatorartifactId>
dependency>
访问 http://localhost:8080/actuator/**
注:actuator后面的叫做端点具体有哪些,见官方文档
web方式默认只暴露health,所以我们现在配置文件中修改,使web方式暴露所有断点方便后续测试
# management是所有actuator的配置
management:
endpoints:
enabled-by-default: true #默认开启所有监控端点
web:
exposure:
include: '*' #以web方式暴露所有断点
格式:http://localhost:8080/actuator/endpointName/detailPath
下面是几个测试链接
http://localhost:8080/actuator/beans
http://localhost:8080/actuator/configprops
http://localhost:8080/actuator/metrics
http://localhost:8080/actuator/metrics/jvm.gc.pause
c)监控端点
在springboot的官方文档可以找到详细的描述
在配置文件中:management.endpoint.端点名.xxxx 就是对某个断点的详细配置
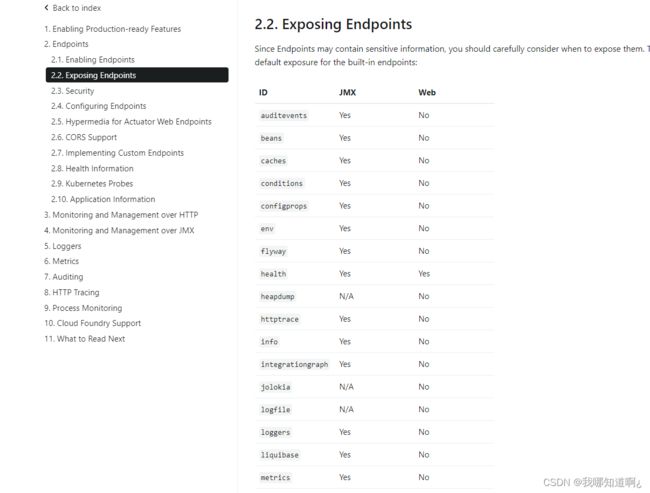
最常用的监控端点
● Health:监控状况
● Metrics:运行时指标
● Loggers:日志记录
d)管理端点
1、开启与禁用Endpoints
● 默认所有的Endpoint除过shutdown都是开启的。
● 需要开启或者禁用某个Endpoint。配置模式为 management.endpoint..enabled = true/false
management:
endpoint:
beans:
enabled: true
或者禁用所有的Endpoint然后手动开启指定的Endpoint
management:
endpoints:
enabled-by-default: false
endpoint:
beans:
enabled: true
health:
enabled: true
6.5.1自定义端点
a)定制health信息
@Component//把组件放到容器中即可
public class MyComHealthIndicator extends AbstractHealthIndicator {
/**
* 编写真实的检查方法
* @param builder
* @throws Exception
*/
@Override
protected void doHealthCheck(Health.Builder builder) throws Exception {
Map<String,Object> map = new HashMap<>();//保存信息
if (1 == 1){
//builder.up(); 代表健康,或者用下面的写法
builder.status(Status.UP);//只要不是UP就都不是健康,下面的不健康也同样可以写成Status.
map.put("count",1);
map.put("ms",100);
}else {
builder.down();//不健康
map.put("error","连接超时");//这里的信息都可以基于自己的业务代码修改
map.put("ms",1000);
}
builder.withDetail("code",100)
.withDetails(map);//返回的信息
}
}
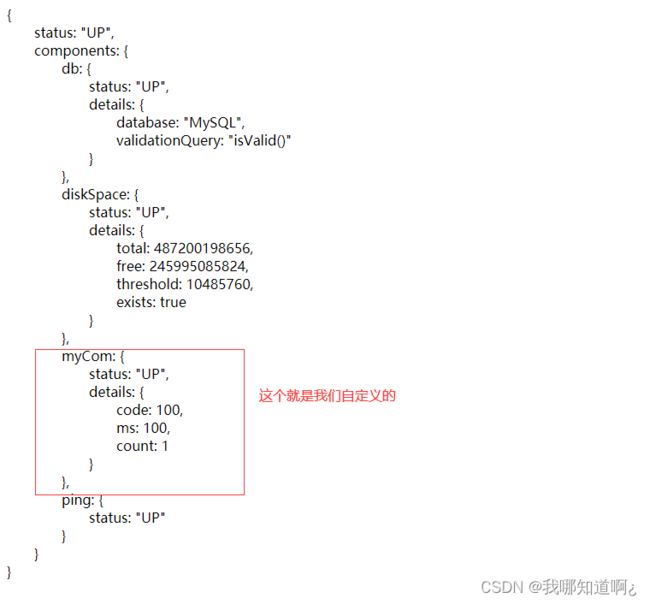
b)定义info信息(当前应用的详细信息)
第一种方式,直接在配置文件中写(但经过测试我的并得不到,原因尚未知)
management:
info:
enabled: true
appName: boot-admin
appVersion: 1.0.0
mavenProject: @project.artifactId@ #获取pom配置文件中的值
mavenProjectVersion: @project.version@
第二种方式就是编写一个类实现InfoContributor并放入容器中
@Component
public class AppInfoContributor implements InfoContributor {
@Override
public void contribute(Info.Builder builder) {
builder.withDetail("msg","你好")
.withDetail("key","value");
/*.withDetails(); Details里面加一个集合*/
}
}
c)定制metrics
1、SpringBoot支持自动适配的Metrics,下面的这些都是自动配置的
● JVM metrics, report utilization of:
○ Various memory and buffer pools
○ Statistics related to garbage collection
○ Threads utilization
○ Number of classes loaded/unloaded
● CPU metrics
● File descriptor metrics
● Kafka consumer and producer metrics
● Log4j2 metrics: record the number of events logged to Log4j2 at each level
● Logback metrics: record the number of events logged to Logback at each level
● Uptime metrics: report a gauge for uptime and a fixed gauge representing the application’s absolute start time
● Tomcat metrics (server.tomcat.mbeanregistry.enabled must be set to true for all Tomcat metrics to be registered)
● Spring Integration metrics
2、增加定制Metrics
直接在类中注入,比如说,我们想统计MyService类中的hello方法被调用了多少次
class MyService{
Counter counter;
public MyService(MeterRegistry meterRegistry){
counter = meterRegistry.counter("myservice.method.running.counter");
}
public void hello() {
counter.increment();
}
}
d)定制endpoint
如果框架给我们提供的端点不能满足使用,我们也可以定制自己的endpoint,只需要使用@Component,@Endpoint这两个注解即可
@Component
@Endpoint(id = "myservice")//端点名
public class MyServiceEndPoint {
@ReadOperation//端点的读操作,访问这个端点就会返回的数据
public Map getDockerInfo(){
//端点的读操作:http://localhost:8080/actuator/myservice
return Collections.singletonMap("dockerInfo","docker started......");
}
@WriteOperation//写操作
public void stopDocker(){
System.out.println("docker stopped......");
}
}
6.5.2可视化界面
官方地址:
https://github.com/codecentric/spring-boot-admin
帮助文档:
quick-start
需要引入的依赖有:
<dependency>
<groupId>de.codecentricgroupId>
<artifactId>spring-boot-admin-starter-serverartifactId>
<version>2.5.1version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
然后再主类上加上@EnableAdminServer注解即可
然后在被监控的项目中加上依赖
<dependency>
<groupId>de.codecentricgroupId>
<artifactId>spring-boot-admin-starter-clientartifactId>
<version>2.5.1version>
dependency>
然后修改其配置文件
spring.boot.admin.client.url=监控器的地址
management.endpoints.web.exposure.include=*
配置完后我们访问监控器的localhost即可
7.原理解析
7.1Profile功能
为了方便多环境适配,springboot简化了profile功能,就比如说,从开发环境到生产环境,这个功能能够极大地简化我们的操作。
官方文档位置:
profiles
a)一个小例子
假设我们现在有三个配置文件,分别对应了三个不同的环境,其中,不带任何标识的application,也就是我们开发环境的配置文件,无论何时都会加载,是默认的配置文件

那么如果我们想要切换环境,我们只需要在我们的开发默认的配置文件中修改即可,想同时激活其他环境的配置文件,只需去掉application-的前缀即可,若存在相同的配置,以新激活的配置文件为主
比如说切换到测试环境test
spring.profiles.active=test
当然,如果项目已经打包完毕,我们也可以使用命令行的方式来切换环境,且命令行优先:
java -jar xxx.jar --spring.profiles.active=你要激活的环境 --也可以在这修改其他的属性
b)@Profile条件装配功能
这个注解即可以标在类上,也可以标在方法上,标在类上,也就是只有符合这个注解的环境时,类中的内容才生效,标在方法上,也就是符合环境,指定的方法才生效
@Configuration(proxyBeanMethods = false)
@Profile("production")
public class ProductionConfiguration {
// ...
}
c)profile分组
spring.profiles.group.production[0]=proddb
spring.profiles.group.production[1]=prodmq
使用:--spring.profiles.active=production 激活
这样的意思就是,production这个分组中有proddb和prodmq两个配置文件,激活production分组就会同时激活这两个配置文件
7.2配置加载优先级
a)外部化配置
官方文档位置:
外部配置
b)外部配置源
常用:Java属性文件、YAML文件、环境变量、命令行参数,这些在我们运行程序时,都可以拿到
其他的可以作为配置源的,在官方文档中都可以查到

且后面的可以覆盖前面的
c)配置文件查找位置
配置文件并不是只能放在resources文件夹下

也是一样的,后面的可以覆盖前面的,也就是说优先级从上往下依次升高
d)配置文件的加载顺序
还是一样,后面的可以覆盖前面的同名配置项,指定环境优先,外部优先
- 当前jar包内部的application.properties和application.yml
- 当前jar包内部的application-{profile}.properties 和 application-{profile}.yml
- 引用的外部jar包的application.properties和application.yml
- 引用的外部jar包的application-{profile}.properties 和 application-{profile}.yml
7.3自定义starter
a)starter的启动原理
首先,我们在pom.xml中引入依赖

● autoconfigure包中配置使用resources下的 META-INF/spring.factories 中 EnableAutoConfiguration 的值,使得项目启动加载指定的自动配置类
● 编写自动配置类 xxxAutoConfiguration -> xxxxProperties
○ @Configuration
○ @Conditional
○ @EnableConfigurationProperties
○ @Bean
○ …
引入starter — xxxAutoConfiguration — 容器中放入组件 ---- 绑定xxxProperties ---- 配置项
b)自定义starter的小案例
首先先创建两个模块

在starter中引入autoconfigure模块
假设autoconfigure中有一个 HelloService可以实现打招呼的业务,他的配置类是HelloProperties
public class HelloService {
@Autowired
HelloProperties helloProperties;
public String sayHello(String userName){
return helloProperties.getPrefix() + ":" +userName +helloProperties.getSuffix();
}
}
接下来编写HelloProperties
@ConfigurationProperties("atguigu.hello")
public class HelloProperties {
public HelloProperties() {
}
private String prefix;
private String suffix;
public String getPrefix() {
return prefix;
}
public void setPrefix(String prefix) {
this.prefix = prefix;
}
public String getSuffix() {
return suffix;
}
public void setSuffix(String suffix) {
this.suffix = suffix;
}
}
然后是他们的自动配置类
@Configuration
@EnableConfigurationProperties(HelloProperties.class)//默认把这个组件放到容器中
public class HelloServiceAutoConfiguration {
public HelloServiceAutoConfiguration() {
}
@Bean
@ConditionalOnMissingBean(HelloService.class)//底层没有HelloService,就调用这个放一下
public HelloService helloService(){
HelloService helloService = new HelloService();
return helloService;
}
}
最后别忘记创建spring.factories,指定自动配置类


这样我们就实现了一个建议的starter,在我们别的项目中可以直接导入,并且在配置文件中修改atguigu.hello.xxx就可以修改sayhello方法返回的数值
7.4springboot的启动过程
接下来我们来关注一下springboot主配置类时的流程
首先,创建springApplication,再运行springApplication

a)创建 SpringApplication时
○ 保存一些信息。
○ 判定当前应用的类型。通过ClassUtils类型判断是Servlet还是响应式
○ bootstrapRegistryInitializers:初始启动引导器(List):去spring.factories文件中找org.springframework.boot.BootstrapRegistryInitializer
○ 找 ApplicationContextInitializer;去spring.factories找 ApplicationContextInitializer
○ 找 ApplicationListener ;应用监听器。去spring.factories找 ApplicationListener
注意,当我们在分析springboot源码时,只要看到下图红框的方法,就说明是去spring.factories文件中寻找某个类
![]()
创建的最后一步,通过寻找main方法,找到主配置类
b)运行SpringApplication时
○ 记录应用的启动时间

○ 创建引导上下文(Context环境)createBootstrapContext()方法,然后获取到所有之前的 bootstrapRegistryInitializers挨个执行 intitialize() 来完成对引导启动器上下文环境设置

○ 调用configureHeadlessProperty()方法,让当前应用进入headless模式。java.awt.headless

○ 调用getRunListeners方法,获取所有的RunListener(运行监听器),去spring.factories找 SpringApplicationRunListener,为了方便所有Listener进行事件感知


○ 遍历 SpringApplicationRunListener 调用 starting 方法,相当于通知所有感兴趣系统正在启动过程的人,项目正在 starting,下图是SpringApplicationRunListener的结构
○ 接下来 保存命令行参数;ApplicationArguments
![]()
○ 然后调用prepareEnvironment方法准备环境,首先返回或者创建基础环境信息对象。
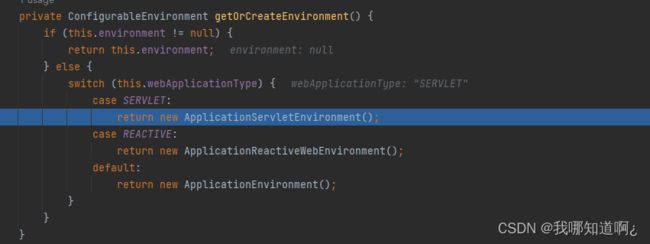
然后配置环境信息,配置完后就绑定环境信息

然后监听器调用environmentPrepared方法,遍历监听器,并通知所有监听器当前环境准备完成

随后就是一系列的绑定,在prepareEnvironment这个方法结束后,所有的环境信息就准备完毕了
○ 接下来,创建IOC容器,根据项目类型(Servlet)创建容器,当前会创建 AnnotationConfigServletWebServerApplicationContext
![]()
○ 随后,调用prepareContext方法,准备ApplicationContext IOC容器的基本信息,保存环境信息,IOC容器的后置处理流程。
然后, 遍历所有的 ApplicationContextInitializer 。调用 initialize.。来对ioc容器进行初始化扩展功能
然后,遍历所有的 listener 调用 contextPrepared,通知所有的监听器contextPrepared
然后,所有的监听器 调用 contextLoaded。通知所有的监听器 contextLoaded;
○ 到此为止,IOC容器的前置准备就结束了,然后执行refreshContext方法刷新IOC容器,创建容器中的所有组件(Spring注解),这里就是spring的源码了。
○ 容器刷新完成后, 所有监听 器 调用 listeners.started(context); 通知所有的监听器 started
○ 调用callRunners方法调用所有runners,
■ 获取容器中的 ApplicationRunner
■ 获取容器中的 CommandLineRunner
■ 合并所有runner并且按照@Order进行排序
■ 遍历所有的runner。调用 run 方法
下面是ApplicationRunner
下面是CommandLineRunner
○ 如果以上有异常,调用Listener 的 failed
○ 调用所有监听器的 running 方法 listeners.running(context); 通知所有的监听器 running (项目正在运行)
○ running如果有问题。继续通知 failed 。调用所有 Listener 的 failed;通知所有的监听器 failed(当前失败了)