机器学习期末考试多选题
1.神经网络优化计算存在的问题有(ABC )。
A.解的不稳定性 B.参数难以确定
C.难以保证最优解 D.能量函数存在大量局部极大值
2.下列Python数据类型中,可变数据类型是( AC)。
A.字典 B.元组 C.列表 D.字符串
可变数据类型:value值改变,id值不变;不可变数据类型:value值改变,id值也随之改变。元组元素不可修改故不可变。常见不可变类型:数字、字符串、布尔、元组。
3.下面哪些Python数据类型是有序序列( ABD)。
A.元组 B.列表 C.字典 D.字符串
Python中的列表是可变序列,通常用于存储相同类型的数据集合,当然也可以存储不同类型数据。Tuple是不可变序列,通常用于存储异构数据集合。有序序列主要体现在元素有序。
4.决定人工神经网络性能的要素有(ABC )。
A.神经元的特性
B.神经元之间相互连接的形式为拓扑结构
C.为适应环境而改善性能的学习规则
D.数据量大小
5.Python语言的应用领域有( ABCD)。
A.Web开发 B.操作系统管理和服务器运维的自动化脚本
C.科学计算 D.游戏开发
6.前馈型神经网络常用于(AD )。
A.图像识别 B.文本处理 C.问答系统 D.图像检测
前馈神经网络中,各神经元分别属于不同的层。每一层的神经元可以接收前一层神经元的信号,并产生信号输出到下一层。第 0 层叫输入层,最后一层叫输出层,其它中间层叫做隐藏层,相邻两层的神经元之间为全连接关系,也称为全连接神经网络(FNN),其主要特点为单向多层,网络表示为一个有向无环图。分为三种:,一种为感知器网络,主要用于模式分类、多模态感知;一种叫反向传播网络(Back propagation Networks)也可简称为BP网络,常用于非线性映射;一种叫做径向基函数神经网络(RBF Network),常用于识别细胞,识别图像,识别声音。
7.机器学习的实现过程,包括数据收集、( ABCD )等环节。
A.数据分析处理 B.算法选择 C.训练模型 D.模型调整
机器学习一般过程:明确问题、收集数据、分析数据(格式整理、偏差检测降噪、数据清洗、去除脏数据和无用数据或噪声和缺失值、数据标准化或可视化等、设定数据集即数据拆分;此部分主要完成可用数据的数据特征提取等工作)、选择模型、设置损失函数loss (0-1损失函数,当预测错误时,损失函数为1,当预测正确时,损失函数值为0)、设置学习率(数据集大小不同学习率不同)、训练、评估、调参(超参调整)、预测模型应用。
8.以下属于人工神经网络的应用方向的是(ABCD )。
A.自动控制 B.信号处理 C.软测量 D.智能计算
软测量是对难以测量或者暂时不能测量的重要变量,选择另外一些容易测量的变量,通过构成某种数学关系来推断或者估计,以软件来替代硬件的功能。

9.Python语言的特点有(ABD )。
A.简单易学 B.开源 C.面向过程 D.可移植性
10.传统机器学习的应用领域有(ABD )。
A.信用风险检测 B.销售预测 C.语音合成 D.商品推荐
语音合成,又称文语转换(Text to Speech)技术,能将任意文字信息实时转化为标准流畅的语音朗读出来。它涉及声学、语言学、数字信号处理、计算机科学等多个学科技术,是中文信息处理领域的一项前沿技术。
11.下列说法不正确的是( CD )。
A.Pandas库中处理数据缺陷时经常会使用dropna将缺陷数据清除
B.Pandas库中isnull判断数据是否为空
C.Pandas不能读取csv文本
D.Pandas能够读取word文件
12.一个完整的人工神经网络包括(AC )。
A.一层输入层 B.多层分析层 C.多层隐藏层 D.两层输出层
13.按照学习方式的不同,可以将机器学习分为以下哪几类( ABC )。
A.有监督学习 B.无监督学习 C.半监督学习 D.自主学习
14.以下属于深度学习框架的有:( ABCD )。
A.Keras B.TensorFlow C.PaddlePaddle D.PyTorch
15.( B)和( C)是分类任务中最常用的两种评估指标。
A.查全率 B.错误率 C.准确率(精度) D.查准率
16.机器学习的核心要素包括(ACD )。
A.数据 B.操作人员 C.算法 D.算力
17.关于sigmoid函数,以下描述正确的是:( ABD)。
A.输出值的范围为0-1之间的实数
B.输入值靠近0的位置,输入与输出近似线性关系
C.输入值靠近0的位置,斜率近似为0
D.输入值是任意的实数
18.在多分类学习中,经典的拆分策略有( ACD)。
A.一对其余(One vs Rest) B.二对二(Two vs Two)
C.多对多(Many vs Many) D.一对一(One vs One)
19.a = numpy.array([[1,2,3],[4,5,6]]) 下列选项中可以选取数字5的索引的是(AC )。
A.a[1][1] B.a[2][2] C.a[1,1] D.a[2,2] A选项按0开始算
20.以下哪些属于分类问题的是:( BCD)。
A.多标签单分类 B.单标签多分类 C.二分类 D.多标签多分类
21.如何判断一个理想的训练集?( ABC )。
A.理想的训练集具有均衡的多样性分布,不容易发生过拟合现象
B.相对于样本的数量,样本自身的代表性和质量更为重要
C.数据集的内容与模型需要达成的目标具有高度的一致性
D.交叉验证方法可以弥补数据集的缺陷
22.机器学习与数据挖掘之间的关系和区别为(ABC )。
A.数据挖掘可以视为机器学习和数据库的交叉。
B.数据挖掘主要利用机器学习界提供的技术来分析海量数据,利用数据库界提供的技术来管理海量数据。
C.机器学习偏理论,数据挖掘偏应用。
D.两者是相互独立的两种数据处理技术。
试题解析: D数据挖掘可以视为机器学习和数据库的交叉,两者并不相互独立。
23.下列哪些函数语句可以设置坐标轴的刻度:( AB )。
A.plt.xticks() B.plt.yticks() C.plt.xlabel() D.plt.ylabel()
24.在现实世界的数据中,缺失值是常有的,一般的处理方法有( ABCD )。
A.忽略 B.删除 C.平均值填充 D.最大值填充
25.以下哪些方法可以用于评估分类算法的性能:(ABC )。
A.F1 Score B.精确率 C.AUC D.预测结果分布
评价分类器的性能指标:[Evaluation Metric]
ACC [accuracy] 准确度、Precision 精确度、Recall 召回率、F1-score、AUC
分类器在测试数据集上进行预测正确或者不正确,可以分为4种情况,分别是:
TP : 将正类预测为正类数
FN : 将正类预测为负类数
FP : 将负类预测为正类数
TN: 将负类预测为负类数
1. ACC 准确率
对于给定的测试集,分类器正确分类样本数与总样本数之比。
![]()
但在binary classification 且正反例不平衡的情况下,尤其是我们对minority class 更感兴趣的时候,accuracy评价基本没有参考价值。
2.Precision 精确率
or positive predictive value
![]()
3.Recall 召回率
sensitivity or true positive rate (TPR)
![]()
4. F1-Score
为精确率和召回率的调和均值
![]()
精确率和召回率都高时,F1 值也会高。
5,AUC
5.1 ROC曲线
ROC曲线描述的是分类混淆矩阵中FPR-TPR两个量之间的相对变化情况。
![]()
![]()
如果二元分类器输出的是对正样本的一个分类概率值,当取不同阈值时会得到不同的混淆矩阵,对应于ROC曲线上的一个点。
ROC曲线反映了FPR与TPR之间权衡的情况,通俗地来说,即在TPR随着FPR递增的情况下,谁增长得更快,快多少的问题。
TPR增长得越快,曲线越往上屈,反映了模型的分类性能就越好。当正负样本不平衡时,这种模型评价方式比起一般的精确度评价方式的好处尤其显著。
5.2 AUC曲线
AUC(Area Under Curve)ROC曲线下的面积。AUC的取值范围在0.5和1之间。
使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而AUC作为数值可以直观的评价分类器的好坏,值越大越好。
方法1:计算出ROC曲线下面的面积,即AUC的值。我们的测试样本是有限的,所以得到的AUC曲线必然是一个阶梯状的。计算的AUC也就是这些阶梯下面的面积之和。计算的精度与阈值的精度有关。
方法2:一个关于AUC的很有趣的性质是,它和Wilcoxon-Mann-Witney Test(秩和检验)是等价的。而Wilcoxon-Mann-Witney Test就是测试任意给一个正类样本和一个负类样本,正类样本的score有多大的概率大于负类样本的score。
有了这个定义,我们就得到了另外一种计算AUC的办法:得到这个概率。具体来说就是统计一下所有的 M×N(M为正类样本的数目,N为负类样本的数目)个正负样本对中,有多少个组中的正样本的score大于负样本的score。当二元组中正负样本的 score相等的时候,按照0.5计算。然后除以MN。实现这个方法的复杂度为O(n^2)。n为样本数(即n=M+N)。
方法3:实际上和上述第二种方法是一样的,但是复杂度减小了。它也是首先对score从大到小排序,然后令最大score对应的sample 的rank为n,第二大score对应sample的rank为n-1,以此类推。然后把所有的正类样本的rank相加,再减去M-1种两个正样本组合的情况。得到的就是所有的样本中有多少对正类样本的score大于负类样本的score。然后再除以M×N。
ROC(Receiver Operating Characteristic,受试者工作特征)曲线是一种比较两个分类模型有用的可视化工具。ROC曲线显示了给定模型的真正例率(TPR)和假正例率(FPR)之间的权衡,纵轴是“真正例率(TPR)”,横轴是“假正例率(FPR)”。

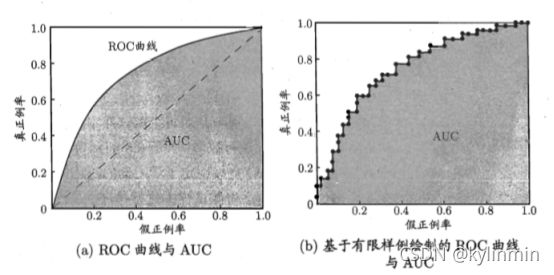
图(a)中,给出了两条线,ROC曲线给出的是当阈值变化时假正例率和真正例率的变化情况。左下角的点所对应的是将所有样例判为反例的情况,而右上角的点对应的则是将所有样例判为正例的情况。虚线给出的是随机猜测的结果曲线。
现实任务中通常利用有限个测试样例来绘制ROC图,此时仅能获得有限个(真正例率,假正例率)坐标对,无法产生图(a)中光滑的ROC曲线,只能绘制如图(b)所示的近似ROC曲线。
绘图过程:给定m+个正例和m-个反例,根据学习器预测结果对样例进行排序,然后把分类阈值设为最大,即把所有样例均预测为反例,此时真正例率和假正例率均为0,在坐标(0,0)处标记一个点。然后,将分类阈值依次设为每个样例的预测值,即依次将每个样例划分为正例。设前一个标记点坐标为(x,y),当前若为真正例,则对应标记点的坐标为(x,y+1/m+);当前若为假正例,则对应标记点的坐标为(x+1/m-,y),然后用线段连接相邻点即可。
若一个学习器的ROC曲线被另一个学习器的曲线完全“包住”,则可断言后者性能优于前者;如果曲线交叉,可以根据ROC曲线下面积大小进行比较,也即AUC(Area Under ROC Curve)值.
AUC可通过对ROC曲线下各部分的面积求和而得。假定ROC曲线由坐标为{(x1,y1),(x2,y2),...,(xm,ym)}的点按序连接而形成(x1=0,xm=1),则AUC可估算为

AUC给出的是分类器的平均性能值,它并不能代替对整条曲线的观察。一个完美的分类器的AUC为1.0,而随机猜测的AUC值为0.5
AUC考虑的是样本预测的排序质量,因此它与排序误差有紧密联系。给定m+个正例,m-个反例,令D+和D-分别表示正、反例集合,则排序”损失”定义为

Lrank对应ROC曲线之上的面积:若一个正例在ROC曲线上标记为(x,y),则x恰是排序在期前的所有反例所占比例,即假正例,因此:
![]()
AUC值是一个概率值,当你随机挑选一个正样本以及负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值,AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。
26.在类不平衡数据集中,(A )和(B )通常作为更合适的性能度量。
A.查全率 B.查准率 C.错误率 D.准确率
一、 经验误差与过拟合
错误率:把分类错误的样本数占样本总数的比例,如果m个样本中有a个样本分类错误,则错误率E = a/m
精度:1- a/m
训练误差(经验误差):学习器在训练集上的误差
泛化误差:在新样本上的误差
过拟合:对训练样本某些特点学的太过,导致泛化性能下降
欠拟合:对训练样本的一般性质尚未学好
二、 数据集划分
1. 留出法
留出法直接将数据集D划分为两个互斥的集合,其中一个作为训练集S,另一个作为测试集T。
常见做法为:1/5 ~ 1/3 样本作为测试集
训练/测试集的划分要尽可能保持数据分布的一致性,避免因数据划分而引入的额外偏差。
因此,单独的使用留出发得到的估计结果往往不够稳定可靠,在使用留出法时,一般要采用若干次随机划分,重复进行实验评估后取平均值作为留出法的评估结果。
2. 交叉验证法
交叉验证法先将数据集D划分为K个大小相似的互斥子集,每个子集尽可能保持数据分布的一致性,即从D中通过分层采样得到。每次用K-1个子集的并集作为训练集,余下的那个作为测试集。从而进行K次训练和测试,最终返回K个测试结果的均值。通常将交叉验证法称为: K折交叉验证。
与留出法相似,将数据集D划分为K个子集的方式有多种,为减小因样本划分不同而引起的差别,K折交叉验证通常要随机使用不同的划分重复P次,最终评估结果为这P次K折交叉验证的均值,例如常见的有10次10折交叉验证
假定D中包含m个样本,若令K = m,则得到了交叉验证法的一个特例:留一法
留一法不受随机样本划分方式的影响,因此留一法的评估结果往往比较准确。不过也有缺陷:在数据集较大的时候计算开销较大。
3. 自助法
给定m个样本的数据集D,对其采样产生数据集D2:每次随机从D中挑选一个样本,将其拷贝放入D2,然后将样本放回D,使得该样本在下次采样时仍有可能被采到。这个过程执行m次后,就得到了包含m个样本的数据集D2
经过数学极限的计算,初始数据集D中越有36.8%的样本未出现在采样数据集D2中。于是,可将D2当作训练集,D\D2当作测试集("\ "表示集合减法)
自助法在数据集较小、难以有效划分训练、测试集时很有用。此外,自助法能从初始数据集中产生较多不同的训练集,这对集成学习等方法有很大好处。然而,改变了初始数据集的分布会引入估计偏差。因此,在初始数据量足够的情况下,留出法和交叉验证法更常用一些。
三、调参与最终模型
1、在进行模型评估与选择时,除了要对使用学习的算法进行选择,还要对参数进行设定。
2、在模型选择完成后,学习算法和参数配置已经设定,此时应用数据集D重新训练模型,而不是训练集,这才是最终提交给用户的模型。
四、 性能度量
1、回归
回归任务最常用的性能度量是“均方误差”
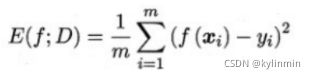
2. 分类

1. 错误率和精度
这是分类任务中最常用的两种性能度量,既适用于二分类任务,也适用于多分类任务。
错误率是分类错误的样本占样本总数的比例;精度是分类正确的样本数占样本总数的比例。

2. 查准率、查全率和F1
由于错误率和精度将每个类看的同等重要,因此不适合用来分析类不平衡数据集。
在类不平衡数据集中,正确分类稀有类比正确分类更多类更有意义。此时查准率和查全率比准确率和错误率更合适。对于二分问题,稀有类样本通常标记为正例,而多数类样本标记为负例。
统计真实标记和预测结果的组合可以得到如下所示的混淆矩阵:

- 查准率(P):被分为正类的样本中实际正类的样本比例。
- 查全率(R) : 实际为正类的样本中被分为正类的样本比例。
- P = TP / ( TP + FP)
- R = TP / ( TP + FN)
P-R曲线
以查准率为纵轴、查全率为横轴作图,得到P-R曲线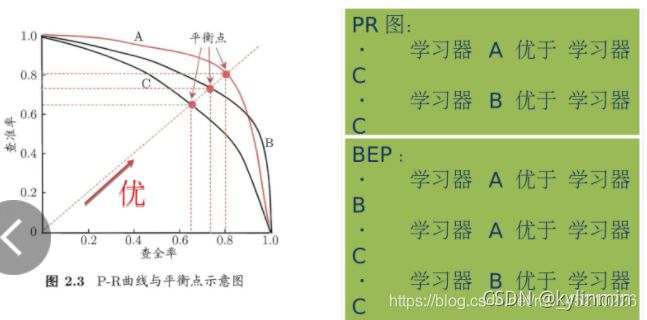 当两条曲线交叉时可用以下判断:
当两条曲线交叉时可用以下判断:
平衡点(BEP) : 它是查全率 = 查准率时的取值。
F1 = ( 2 * TP)/ 样例总数+ TP – FN
若对查准率或查全率有不同的偏好:

β > 1 时查全率有更大影响,β <1 时查准率有更大影响,β = 1 时退化为标准F1.
若有多个二分类混淆矩阵(全局) :
先在混下矩阵上分别计算出查准率和查全率,记为 (P1,R1),(P2,R2),(P3,R3),(P4,R4)...再计算平均值,这样就得到**宏查找率(macro-P),宏查全率(macro-R),以及相应的宏F1 :
![]()
还可先将各混淆矩阵的对应元素进行平均,得到TP、FP、TN、FN的平均值,再基于这些平均值计算出微查准率、微查全率、微F1

3. ROC和AUC
真正例率(TPR):TPR = TP / (TP + FN)
假正例率(FPR):FPR = FP / (TN + FP)

AUC:ROC曲线下的面积

4. 代价敏感错误率与代价曲线
为均衡不同类型错误所照成的不同的损失,为错误赋予非均等代价 ,以二分类为例,引入了代价矩阵:

在非均等代价下,我们所希望的不再是简单的最小化错误次数,而是希望最小化总体代价。

代价曲线的绘制

试卷分析:多选题考察较为基础,主要涉及基本概念和基础知识运用的考查,知识点方面涵盖Python基础、Python第三方库科学计算基础软件包NumPy、结构化数据分析工具Pandas、绘图库Matplotlib、科学计算工具包SciPy等的具体应用、机器学习基本流程、数据集划分、机器学习基础知识、英文专业术语、AUC等,试题中出现的难点主要有对机器学习算法一般性能标准的理解。总的来说,题目有一定难度。