作者:vivo 互联网前端团队-Wan Anwen、Hu Feng、Feng Wei、Xie Tao
进入互联网“下半场”,靠“人海战术”的研发模式已经不再具备竞争力,如何通过技术升级提升研发效能?前端通过Babel等编译技术发展实现了工程化体系升级,如何进一步通过编译技术赋能前端开发?或许我们 wepy 到uniapp 编译的转换实践,能给你带来启发。
一、 背景
随着小程序的出现,借助微信的生态体系和海量用户,使服务以更加便捷方式的触达用户需求。基于此背景,团队很早布局智能导购小程序(为 vivo 各个线下门店导购提供服务的用户运营工具)的开发。
早期的小程序开发工程体系还不够健全,和现在的前端的工程体系相差较大,表现在对模块化,组件化以及高级JavaScript 语法特性的支撑上。所以团队在做技术选型时,希望克服原生小程序工程体系上的不足,经过对比最后选择了腾讯出品的 wepy 作为整体的开发框架。
在项目的从0到1阶段,wepy 确实帮助我们实现了快速的业务迭代,满足线下门店导购的需求。但随着时间的推移,在技术上,社区逐步沉淀出以 uniapp 为代表的 Vue 栈体系和以 Taro 为代表的 React 栈跨端的体系,wepy 目前的社区活跃度比较低。另外随着业务进入稳定阶段,除少量的 wepy 小程序,H5 项目和新的小程序都是基于 Vue 和 uniapp 来构建,团队也是希望统一技术栈,实现更好的跨端开发能力,降低开发和维护成本,提升研发效率。
二、思考
随着团队决定将智能导购小程序从 wepy 迁移到 uniapp 的架构体系,我们就需要思考,如何进行项目的平稳的迁移,同时兼顾效率和质量?通过对当前的项目状态和技术背景进行分析,团队梳理出2个原则3种迁移思路。
2.1 渐进式迁移
核心出发点,保证项目的平稳过渡,给团队更多的时间,在迭代中逐步的进行架构迁移。希望以此来降低迁移中的风险和不可控的点。基于此,我们思考两个方案:
方案一 融合两套架构体系
在目前的项目中引入和 uniapp 的项目体系,一个项目融合了 wepy 和 uniapp 的代码工程化管理,逐步的将 wepy 的代码改成 uniapp 的代码,待迁移完成删除 wepy 的目录。这种方案实现起来不是很复杂,但是缺点是管理起来比较复杂,两套工程化管理机制,底层的编译机制,各种入口的配置文件等,管理起来比较麻烦。另外团队每个人都需要消化 wepy 到 uniapp 的领域知识迁移,不仅仅是项目的迁移也是知识体系的迁移。
方案二 设计 wepy-webpack-loader
以 uniapp 为工程体系基础,核心思路是将现有 wepy 代码融入到 uniapp 的体系中来。我们都知道 uniapp 的底层依赖于 Vue 的 cli 的技术体系,最底层通过 webpack 实现对 Vue 单组件文件和其他资源文件的 bundle。
基于此,我们可以开发一个 wepy 的 webpack 的 loader,wepy-loader 类似于 vue-loader 的能力,通过该 loader 对 wepy 文件进行编译打包,然后最终输出小程序代码。想法很简单,但我们想要实现 wepy-loader工作量还是比较大的,需要对 wepy 的底层编译器进一步进行分析拆解,分析 wepy 的依赖关系,区分是组件编译还是 page 编译等,且 wepy 底层编译器的代码比较复杂,实现成本较高。
2.2 整体性迁移
构建一个编译器实现 wepy 到 uniapp 的自动代码转换。
通过对 wepy 和 uniapp 整体技术方案的梳理,加深了对两套架构差异性的认知和理解,尤其 wepy 上层语法和 Vue 的组件开发的代码上的差异性。基于团队对编译的认知,我们认为借助 babel 等成熟编译技术是有能力实现这个转换的过程,另外,通过编译技术会极大的提升整体的迁移的效率。
2.3 方案对比

通过团队对方案的深入讨论和技术预研,最终大家达成一致使用编译转换的方式(方案三)来进行本次的技术升级。最终,通过实现 wepy 到 uniapp 的编译转换器,使原本 25人/天的工作量,6s 完成。
如下动图所示:


三、架构设计
3.1 wepy 和 uniapp 单文件组件转换
通过对 wepy 和 uniapp 的学习,充分了解两者之间的差异性和相识点。wepy 的文件设计和 Vue 的单文件非常的相似,包含 template 和 script 和 style 的三部分组成。
如下图所示,

所以我们将文件拆解为 script,template,style 样式三个部分,通过 transpiler 分别转换。同时这个过程主要是对 script 和 template 进行转换,样式和 Vue 可以保持一致性最终借助 Vue 进行转换即可。
同时 wepy 还有自己的 runtime运行时的依赖,为了确保项目对 wepy 做到最小化的依赖,方便后续完全和 wepy 的依赖进行完全解耦,我们抽取了一个 wepy-adapter 模块,将原先对于 wepy 的依赖转换为对wepy-adapter 的依赖。
整体转换设计,如下图所示:

3.2 编译器流水线构建

如上图所示,整个编译过程就是一条流水线的架构设计,在每个阶段完成不同的任务。主要流程如下:
3.2.1 项目资源分析
不同的项目依赖资源不同的处理流程,扫描项目中的源码和资源文件进行分类,等待后续的不同的流水线处理。
静态资源文件(图片,样式文件等)不需要经过当中流水线的处理,直达目标 uniapp 项目的对应的目录。
3.2.2 AST抽象语法树转换
针对 wepy 的源文件(app,page,component等)对 script,template 等部分,通过 parse 转换成相对应的AST抽象语法树,后续的代码转换都是基于对抽象语法树的结构改进。
3.2.3 代码转换实现 - Transform code
根据 wepy 和 uniapp 的 Vue 的代码实现上的差异,通过对ast进行转换实现代码的转换。
3.2.4 代码生成 - code emitter
根据步骤三转换之后最终的ast,进行对应的代码生成。
四、项目搭建
整体项目结构如下图所示:

4.1 单仓库的管理模式
使用 lerna 进行单仓库的模块化管理,方便进行模块的拆分和本地模块之间依赖引用。另外单仓库的好处在于,和项目相关的信息都可以在一个仓库中沉淀下来,如文档,demo,issue 等。不过随着 lerna 社区不再进行维护,后续会将 lerna 迁移到 pnpm 的 workspace 的方案进行管理。
4.2 核心模块
- wepy-adapter - wepy运行期以来的最小化的polyfill
- wepy-chameleon-cli - 命令行工具模块
- wepy-chameleon-transpiler - 核心的编译器模块,按照one feature,one module方式组织
4.3 自动化任务构建等
Makefile - *nix世界的标准方式
4.4 scripts 自动化管理
shipit.ts 模块的自动发布等自动化能力
4.5 单元测试
- 采用Jest作为基础的测试框架,使用typescript来作为测试用例的编写。
- 使用@swc/jest作为ts的转换器,提升ts的编译速度。
- 现在社区的vitest直接提供了对ts的集成,借助vite带来更快的速度,计划迁移中。
五、核心设计实现
5.1 wepy template 模版转换
5.1.1 差异性梳理
下面我们可以先来大致看一下wepy的模板语法和uniapp的模板语法的区别。

图:wepy模板和uni-app模板
从上图可以看出,wepy模板使用了原生微信小程序的wxml语法,并且在采用类似Vue的组件引入机制的同时,保留了wxml< import/ >、< include/ >标签的能力。同时为了和wxml中循环渲染dom节点的语法做区别,引入了新的< Repeat/ >标签来渲染引入的子组件,而uni-app则是完全使用Vue风格的语法来进行开发。
所以总结wepy和uni-app模板语法的主要区别有两点:
- wepy使用了一些特定的标签用来导入或者复用其他wxml文件例如< import >和< include >。
- wxml使用了xml命名空间的方式来定义模板指令,并且对指令值的处理更像是使用模板引擎对特定格式的变量进行替换。
下表列举一些两者模板指令的对应转换关系。
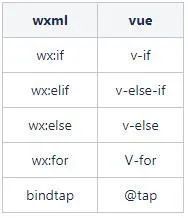
此外,还有一些指令的细节需要处理,例如在wepy中wx:key="id"指令会自动解析为wx:key="{{item.id}}",这里便不再赘述。
5.1.2 核心转换设计
编译器对template转换主要就需要完成以下三个步骤:
- 处理wepy引入的特殊的标签例如。
- 将wxml中使用的指令、特殊标签等转换为Vue模板的语法。
- 收集引入的组件信息传递给下游的wepy-page-transform模块。
- wepy特殊标签转换
首先我们会处理wepy模板中的特殊标签< import/ >、< include/ >,主要是将wxml的文件引入模式转换成Vue模板的组件引入模式,同时还需要收集引入的wxml的文件地址和展示的模板名称。由于< include/ >可以引入wxml文件中除了< template/ >和< wxs/ >的所有代码,为了保证转换后组件的复用性,我们将引入的xx.wxml文件拆成了xx.vue和xx-incl.vue两个文件,使用< import/ >标签的会导入xx.vue,而使用< include/ >标签的会导入xx-incl.vue,转换import的核心代码实现如下:
transformImport() {
// 获取所有import标签
const imports = this.$('import')
for (let i = 0; i < imports.length; i++) {
const node = imports.eq(i)
if (!node.is('import')) return
const importPath = node.attr('src')
// 收集引入的路径信息
this.importPath.push(importPath)
// 将文件名统一转换成短横线风格
let compName = TransformTemplate.toLine(
path.basename(importPath, path.extname(importPath))
)
let template = node.next('template')
while (template.is('template')) {
const next = template.next('template')
if (template.attr('is')) {
const children = template.children()
// 生成新的组件标签例如
//
const comp = this.$(`<${compName} />`)
.attr(template.attr())
.append(children)
comp.attr(TransformTemplate.toLine(this.compName), comp.attr('is'))
comp.removeAttr('is')
// 将当前标签替换为新生成的组件标签
template.replaceWith(comp)
}
template = next
}
node.remove()
}
}具体的WXML文件拆分方案请看WXML转换部分。
- wepy 属性转换
上文中已经介绍了,wepy模板中的属性使用了命名空间+模板字符串风格的动态属性,我们需要将他们转换成Vue风格的属性。转换需要操作模板中的节点及其属性,这里我们使用了cheerio, 快速、灵活、类jQuery核心实现,可以利用jQuery的语法非常方便的对模板字符串进行处理。
上述流程中一个分支中的转换函数会处理相应的wepy属性,以保证后续可以很方便的对转换模块进行完善和修改。由于属性名称转换只是简单的做一下相应的映射,我们重点分析一下动态属性值的转换过程。
WXML中使用双中括号来标记动态属性中的变量及WXS表达式,并且如果变量是WXS对象的话还可以省略对象的大括号例如
< view wx:for="{{list}}" > {{item}} < /view >、< template is="objectCombine" data="{{for: a, bar: b}}" >< /template >所以当我们取到双中括号中的值时会有以下两种情况:
- 得到WXS的表达式;
- 得到一个没有中括号包裹的WXS对象。此时我们可以先对表达式尝试转换,如果有报错的话,给表达式包裹一层中括号再进行转换。考虑到WXS的语法类似于Javascript的子集,我们依然使用babel对其进行解析并处理。
核心代码实现如下:
/**
*
* @param value 需要转换的属性值
*/
private transformValue(value: string): string {
const exp = value.match(TransformTemplate.dbbraceRe)[1]
try {
let seq = false
traverse(parseSync(`(${exp})`), {
enter(path) {
// 由于WXS支持对象键值相等的缩写{{a,b,c}},故此处需要额外处理
if (path.isSequenceExpression()) {
seq = true
}
},
})
if (!seq) {
return exp
}
return `{${exp}}`
} catch (e) {
return `{${exp}}`
}
}到这里,我们已经能够处理wepy模板中绝大部分的动态属性值的转换。但是,上文也提及到了,wepy采用的是类似模板引擎的方式来处理动态属性的,即WXML支持这种动态属性< view id="item-{{index}}" >,如果这个 < view / >标签使用了wx:for指令的话,id属性会被编译成item-0、item-1... 这个问题我们也想了多种方案去解决,例如字符串拼接、正则处理等,但是都不能很好的覆盖全部场景,总会有特殊场景的出现导致转换失败。
最终,我们还是想到了模板引擎,Javascript中也有类似于模板引擎的元素,那就是模板字符串。使用模板字符串,我们仅仅需要把WXML中用来标记变量的双括号{{}}转换成Javascript中的${}即可。
5.2 Wepy App 转换
5.2.1 差异性梳理
wepy 的 App 小程序实例中主要包含小程序生命周期函数、config 配置对象、globalData 全局数据对象,以及其他自定义方法与属性。
核心代码实现如下:
import wepy from 'wepy'
// 在 page 中,通过 this.$parent 来访问 app 实例
export default class MyAPP extends wepy.app {
customData = {}
customFunction() {}
onLaunch() {}
onShow() {}
// 对应 app.json 文件
// build 编译时会根据 config 属性自动生成 app.json 文件
config = {}
globalData = {}
}uniapp的 App.vue 可以定义小程序生命周期方法,globalData全局数据对象,以及一些自定义方法,核心代码实现如下:
可以看到,wepy的page类也是通过继承来实现的,页面文件 page.wpy 中所声明的页面实例继承自 wepy.page 类,该类的主要属性介绍如下:

5.4.2 核心转换设计
基于page的api特性以及实现方案,具体的转换设计思路如下:

5.4.3 痛点难点
1.非阻塞异步与异步
在进行批量pages转换时,需要同时对pages.json进行读取、修改、再修改的操作,这就涉及到使用阻塞 IO/ 异步 IO来处理文件的读写,当使用异步IO时,会发起多个进程同时处理pages.json, 每个读取完成后单独处理对应的内容,数据不是串行修改,最终导致最终修改的内容不符合预期,因此在遇到并行处配置文件时,需要使用阻塞式io来读取文件,保障最终数据的唯一性,具体代码如下:
// merge pageConfig to app config
const rawPagesJson = fs.readFileSync(path.join(dest, 'src/pages.json'))
// 数据操作
fs.writeFileSync(
path.join(dest, 'src', 'pages.json'),
prettJson(pagesJson)
)2.复杂的事件机制
在转换过程中,我们也碰到一个比较大的痛点:page.wepy 继承至 wepy.page,wepy.page 代码较复杂,需要将明确部分单独抽离出来。例如说 events 中组件间数据传递:$broadcast、$emit、$invoke,$broadcast、$invoke需要熟悉其使用场景,转换为 Vue 中公共方法。
5.5 Wepy WXML 转换
template转换章节中提到了wepy模板中可以直接引入wxml文件,但是uni-app使用的Vue模板不支持直接引入wxml,故我们需要将wxml文件处理为uniapp可以引入的Vue文件。我们先来看一下wepy中引入的wxml文件的大致结构。
{{item.text1}}
{{item.text2}}
this is footer
5.5.1 差异性梳理
从上面的代码可以看出,一个WXML文件中支持多个不同name属性的< template/ >标签,并且支持通过在引入设置data来传入属性。从上面的示例模板中我们可以分析出,除了需要将wepy使用的WXML语法转换成vue模板语法外(这里的转换交给了template模块来处理),我们还需要处理以下的问题。
- 确定引入组件时的传参格式
- 确定组件中传入对象的属性有哪些
- 处理< import/ >和< include/ >引入的文件时的情况
5.5.2 核心转换设计
1.确定引入组件时的传入属性方式
首先需要将wepy组件引入形式改成Vue的组件引入方式。以上面的代码为例,即将< import/ > 、< script/ >对的引入形式改写成< component-name / > 引入方式。我们会在转换开始前对代码进行扫描,收集模板中的引入文件信息,传递给wepy-page-transform模块处理,在转换后的Vue组件的< script/ >中进行引入。并且将< script is="foo" data="{{item, pic}}" / > 转换为< FooBar is="foo" :data=(待定) / > 。这里就需要确定属性传递的方式。
从上面的代码中可以看到,在WXML文件的< template/ >会自动使用传入的data属性作为隐式的命名空间,从而不需要使用data.item来获取item属性。这里很自然的就会想到原来的< script is="foo" data="{{item, pic}}" / >可以转换成< FooBar compName="foo" :key1="val1" :key2="val2" ... / >。
其中,key1,val1,key2,val2等为原data属性对象中的键值对,compName用来指定展示的部分。这样处理的好处是,引入的WXML文件中使用相应的传入的属性就不需要做额外的修改,并且比较符合我们一般引入Vue组件时传入属性的方式。
虽然这种方案可以较少的改动WXML文件中的模板,但是由于传入的对象可能会在运行期间进行修改,我们在编译期间比较难以确定传入的data对象中的键值对。考虑到实现的时间成本及难易程度,我们没有选择这种方案。
目前我们所采用的方案是不去改变原有的属性传入方式,即将组件引入标签转换为< FooBar compName="foo" :data="{item, pic}" / >。从而省去分析传入对象在运行时的变动。这里就引出了第二个问题,如何确定组件中传入的参数有哪些。
2.确定组件中的传入的对象属性
由于Vue的模板中不会自动使用传入的对象作为命名空间,我们需要手动的找到当前待转换的模板中所使用到的所有的变量。相应的代码如下:
searchVars() {
const self = this
const domList = this.$('template *')
// 获取wxml文件中template节点下的所有text节点
const text = domList.text()
const dbbraceRe = new RegExp(TransformTemplate.dbbraceRe, 'g')
let ivar
// 拿到所有被{{}}包裹的动态表达式
while ((ivar = dbbraceRe.exec(text))) {
addVar(ivar[1])
}
// 遍历所有节点的属性,获取所有的动态属性
for (let i = 0; i < domList.length; i++) {
const dom = domList.eq(i)
const attrs = Object.keys(dom.attr())
for (let attr of attrs) {
const value = dom.attr(attr)
if (!TransformTemplate.dbbraceRe.test(value)) continue
const exp = value.match(TransformTemplate.dbbraceRe)[1]
try {
addVar(exp)
} catch (e) {
addVar(`{${exp}}`)
}
}
}
function addVar(exp: string) {
traverse(parseSync(`(${exp})`), { // 利用babel分析表达式中的所有变量
Identifier(path) {
if (
path.parentPath.isMemberExpression() &&
!path.parentPath.node.computed &&
path.parentPath.node.property === path.node
)
return
self.vars.add(path.node.name) // 收集变量
},
})
}
}收集到所有的变量信息后,模板中的所有变量前面需要加上传入的对象名称,例如item.hp\_title需要转换成data.item.hp\_title。考虑到模板的简洁性和后续的易维护性,我们把转换统一放到< script/ >的computed字段中统一处理即可:
3.处理 < import/ >和< include/ >两种引入方式
wepy模板有两种引入组件的方式,一种是使用< import/ >< script/ >标签对进行引入,还有一种是使用< include/ > 进行引入,< include/ > 会引入WXML文件中除了< template/ >和< wxs/ >的其他标签。这里的处理方式就比较简单,我们把< include/ > 会引入的部分单独抽取出来,生成TItem-incl.vue文件,这样即保证了生成代码的可复用性,也降低< import/ >标签引入的部分生成的TItem.vue文件中的逻辑复杂度。生成的两个文件的结构如下:
this is footer
六、阶段性成果
截止到目前,司内的企微导购小程序项目通过接入变色龙编译器已经顺利的从 wepy 迁移到了 uniApp 架构,原本预计需要 25人/天 的迁移工作量在使用了编译器转换后缩短到了 10s。这不仅仅只是提高了迁移的效率,也降低了迁移中的知识迁移成本,给后续业务上的快速迭代奠定的扎实的基础。
迁移后的企微导购小程序项目经测试阶段验证业务功能 0 bug,目前已经顺利上线。后续我们也会持续收集其他类似的业务诉求,帮助业务兄弟们低成本完成迁移。
七、总结
研发能效的提升是个永恒的话题,此次我们从编译这个角度出发,和大家分享了从wepy到uniapp的架构升级探索的过程,通过构建代码转换的编译器来提升整体的架构升级效率,通过编译器消化底层的领域和知识的差异性,取得了不错的效果。
当然,我们目前也有还不够完善的地方,如:编译器脚手架缺乏对于部分特性颗粒度更细的控制、代码编译转换过程中日志的输出更友好等等。后续我们也有计划将 wepy 变色龙编译器在社区开源共建,届时欢迎大家一起参与进来。
现阶段编译在前端的使用场景越来越多,或许我们真的进入了Compiler is our framework的时代。