MetaFormer-3
他也迎来第三了 不过 搬来时还是感觉 是之前的补偿 凑乎看吧 这次是新国的口号~~
视觉 Transformer 一般性的宏观架构,而不是令牌混合器 (Token Mixer) 对模型的性能更为重要。宏观架构才是通用视觉模型真正需要的. 来自 Sea AI Lab,新加坡国立大学
论文名称:
MetaFormer Is Actually What You Need for Vision
MetaFormer Baselines for Vision (Extended version)
论文地址:
https://arxiv.org/pdf/2111.11418.pdf
https://arxiv.org/pdf/2210.13452.pdf
与卷积神经网络 (CNN) 相比,视觉 Transformer 模型在多种计算机视觉任务中展现出了巨大的潜力。很多工作也开始卷 Transformer 模型的具体架构。以 Transformer 为代表的通用视觉模型的每个模块的架构如下图1所示。每个 Block 一般由两部分组成。其一是用于融合空间位置信息的令牌混合器 (Token Mixer) 模块,其二是用于融合通道信息的 Channel MLP 模块。当令牌混合器取不同的形式时,通用视觉模型也变化为不同的类型。比如在 ViT 中,Token Mixer 就是自注意力模块 (Self-Attention) ;在 MLP-Mixer 中,Token Mixer 就是 Spatial MLP;在 Swin Transformer 中,Token Mixer 就是 Window-based Self-Attention;在 GFNet 中,Token Mixer 就是 2D-FFT。
这几个工作都训出了很好的性能,把所有这些结果放在一起,似乎只要模型采用的一般架构确定了之后,就可以获得有希望的结果。

图1:通用视觉模型的每个模块的架构
这两篇文章为领域带来了全新的视角,即:当前普遍的看法是基于自注意力机制 (Self-Attention) 的令牌混合器 (Token Mixer) 对视觉 Transformer 架构的能力是贡献最大的。但是最近的很多研究也表明了 Self-Attention 模块其实是可以被更加简洁的 MLP 模块所取代,所得到的模型仍然表现得很好。基于这一观察,这两篇文章的核心观点是:视觉 Transformer 一般性的宏观架构,而不是令牌混合器 (Token Mixer) 对模型的性能更为重要。
什么是 MetaFormer?
在本文中,作者给出了 MetaFormer 的一般性定义,即:MetaFormer 是一种通用架构,其中不指定令牌混合器的具体类型,而其他组件与视觉 Transformer 相同。

MetaFormer 描述了一种通用架构,通过不同的令牌混合器的具体设计,可以获得不同的模型。
PoolFormer 架构
从 ViT 的提出开始,很多工作非常重视令牌混合器的具体架构是什么,并专注于设计各种高效的零派混合器。相比之下,这些工作很少注意到一般的架构,也就是 MetaFormer。本文认为这种 MetaFormer 的一般性的宏观架构对视觉 Transformer 和 MLP 的模型的成功贡献最大。为了验证这个猜想,作者搞了一个极其简单,简单到尴尬的令牌混合器 (Token Mixer):池化操作 (Pooling)。池化操作只有最最基本的融合不同空间位置信息的能力,它没有任何的权重。

import torch.nn as nn
class Pooling(nn.Module):
def __init__(self, pool_size=3):
super().__init__()
self.pool = nn.AvgPool2d(
pool_size, stride=1,
padding=pool_size//2,
count_include_pad=False,
)
def forward(self, x):
"""
[B, C, H, W] = x.shape
Subtraction of the input itself is added
since the block already has a
residual connection.
"""
return self.pool(x) - x

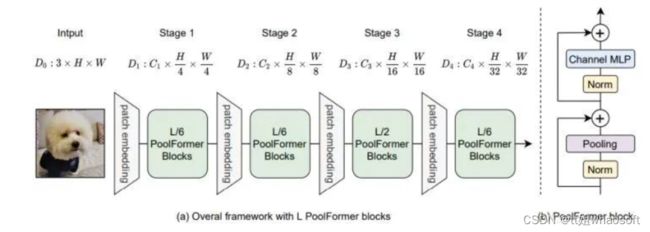
图2:PoolFormer 架构
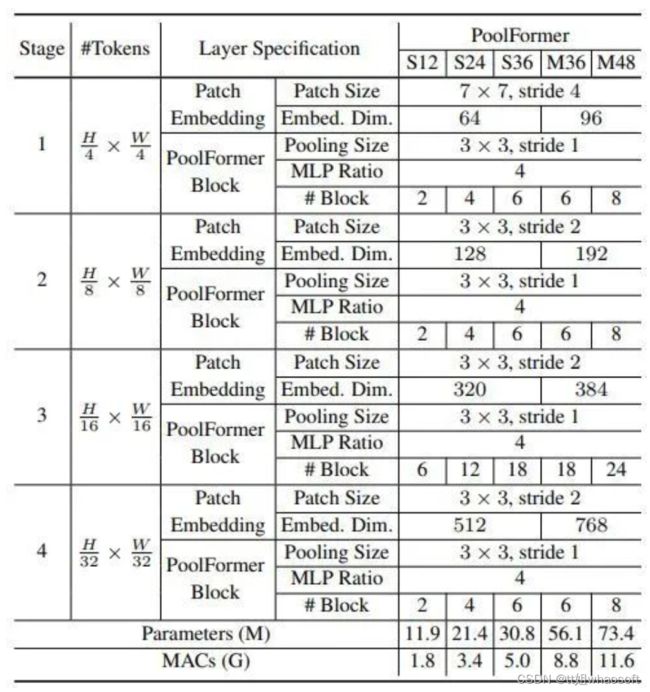
图3:PoolFormer 模型参数
PoolFormer 通用视觉任务的实验结果
令人惊讶的是,这个被称为 PoolFormer 的派生模型取得了非常有竞争力的性能,甚至优于一些性能优良的 Transformer 和 MLP 模型。
ImageNet-1K 分类实验结果
如下图4所示是 PoolFormer 的 ImageNet-1K 分类结果。令人惊讶的是,尽管使用的是极其简单的池化令牌混合器,PoolFormer 仍然可以达到非常有竞争力的性能。比如,PoolFormer-S24 只使用了 21M 的参数和 3.4G MACs 的计算量就达到了超过 80% 的 ImageNet-1K 分类精度,其性能和效率都超过了经典的 DeiT-S 模型和 ResMLP-S24 等等。即使与更多改进的 ViT 和 MLP 模型相比,PoolFormer 仍然显示出更好的性能。具体来说,PVT-Medium 在 44M 的参数和 6.7G 的 MACs 下获得了 81.2 的 top-1 精度。而 PoolFormer-S36 在参数减少 30%(31M) 和 6.7G 的情况下达到了 81.4 的 top-1 精度。
与 RSB-ResNet[1] 相比,PoolFormer 仍然表现得更好。在大约 22M 参数 3.7GMACs 的情况下,RSB-ResNet-34可以获得 75.5% 的精度,而 PoolFormerS24 的精度可以达到 80.3%。由于池化层的局部空间建模能力比神经卷积层差很多,PoolFormer 的竞争性能只能归功于其通用架构 MetaFormer。
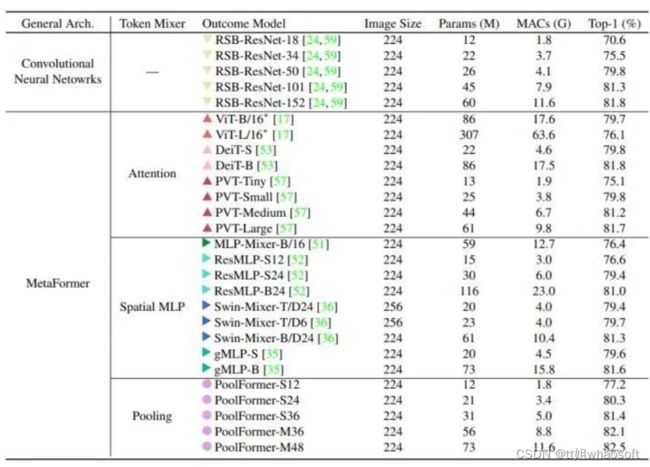
图4:ImageNet-1K 分类结果
目标检测和实例分割实验结果
如下图5所示是在 COCO benchmark 上验证的目标检测和实例分割实验结果。作者使用 PoolFormer 作为 Backbone,RetinaNet 和 Mask R-CNN 作为检测头。使用 1× 的训练策略,训练模型 12 Epochs。基于PoolFormer 的 Backbone 搭配 RetinaNet 作为检测头进行目标检测,其表现一直优于同类的 ResNet Backbone。比如,PoolFormer-S12 取得了36.2的 AP,大大超过了 ResNet-18 的31.8的 AP。
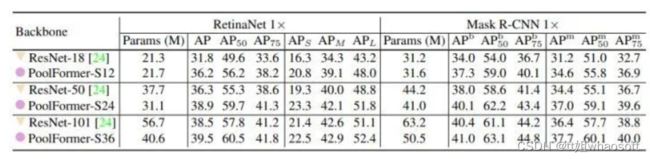 图5:目标检测和实例分割实验结果
图5:目标检测和实例分割实验结果
语义分割实验结果
如下图6所示是在 ADE20K 上验证的语义分割实验结果。作者使用 PoolFormer 作为 Backbone,Semantic FPN 作为分割头。训练模型 80K iteration。基于PoolFormer 的 Backbone 搭配 Semantic FPN 作为分割头进行语义分割,其表现一直优于同类的 ResNet Backbone 和 PVT。这些结果进一步表明了 MetaFormer 的巨大潜力。
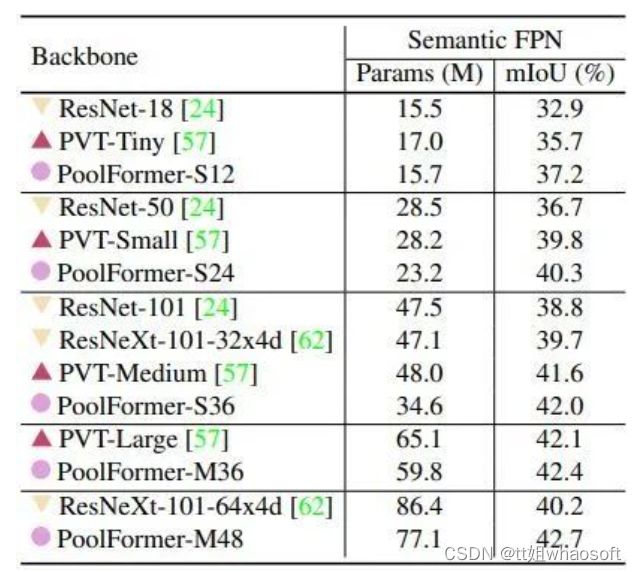
图6:语义分割实验结果
MetaFormer 通用视觉任务的实验结果
如下图7所示是 MetaFormer 通用视觉任务的实验结果。作者把池化操作进一步换成了多种不同的简单操作 (如 Identity Mapping,Global Random Matrix,Depthwise Convolution 等),精度分别达到了 74.3%,75.8%,78.1%,证明只要有 MetaFormer 这样的宏观架构,即使是用完全随机的令牌混合器 (Global Random Matrix),也能很好地工作,更不用说与其他更好的令牌混合器了。当进一步把令牌混合器换成带有可学习参数的 Depth-wise Convolution 之后,S12 级别的模型可以训出 78.1% 的性能。到目前为止,已经在 MetaFormer 中指定了多种令牌混合器,所有得出的模型都保持了良好的结果,说明 MetaFormer 架构确实是模型 work 的关键。

图7:MetaFormer 通用视觉任务的实验结果
接下来作者进一步把 stage3 和 stage4 的 Pooling 操作换成 Attention 和 SpatialFC 操作。因为 Pooling 操作可以处理更长的输入序列,而 Attention 和 SpatialFC 操作则擅长捕捉全局的信息。因此,MetaFormer 的其中一种很自然而然的设计思路就是在前面的 stage 使用 Pooling 操作,在后面的 stage 放一些 Attention 和 SpatialFC 操作。从图7的实验结果也可以看出,这样的设计的性能可以分被实现 81.0% 和 77.9% 的 top-1 精度。
这些结果表明,将 MetaFormer 的池化和其他令牌混合器结合起来,可能是进一步提高性能的一个有希望的方向。下一节将继续探索如何使得 MetaFormer 的性能继续提升。
MetaFormer 的性能还可以再提升吗?
至此,ViT 的抽象宏观架构, MetaFormer,已被证明对一个通用视觉架构的 work 起了很关键的作用。原班人马作者又在新的一个工作中进行了下一步的探索,即:MetaFormer 的性能还可以再提升吗?
在这个工作里面,作者再一次将目光从令牌混合器上移开,使用了几种最最基本的 token mixer:**恒等映射 (Identity mapping),全局随机合并 (Global Random Mixing),可分离卷积 (Separable Convolution),以及原始的自注意力机制 (Self-attention)**。并给出了下面3个观察:
-
MetaFormer 保证了稳定的性能下限: 使用恒等映射作为令牌混合器 (其实压根就没有令牌混合的功能),搞出一个叫 IdentityFormer 的模型,让我们惊讶的是,这个极其粗糙的模型已经达到了令人满意的精度 (73M Params 和 11.5 GMACs 实现了 80.4% 的 ImageNet-1K 精度)。IdentityFormer 的结果表明,MetaFormer 确实是一个可靠的体系结构,即使使用恒等映射这种无效的令牌混合机制,它也能确保良好的性能下界。
-
MetaFormer 搭配任意令牌混合器,都能实现不错的性能: 为了进一步探究 MetaFormer 对令牌混合器的泛化性,作者进一步将令牌混合器替换为一个随机矩阵。这样以来,虽然也有令牌混合的功能,但是混合的方式也是完全任意的。具体而言,只在前两个 stage 使用随机矩阵,后两个 stage 依然使用 Identity mapping。该衍生模型被称为 RandFormer,这个模型提高了 IdentityFormer 1.0%,实现了 81.4% 的 ImageNet-1K 精度。这个结果验证了 MetaFormer 与令牌混合器的泛化性和兼容性。
-
MetaFormer 毫不费力地实现最先进的性能: 作者进一步尝试向 MetaFormer 中加入更多类型的令牌混合器,比如很久之前提出的可分离卷积 (Separable Convolution),以及原始的自注意力机制 (Self-attention),得到的模型分别称之为 ConvFormer 和 CAFormer,具体而言:
-
ConvFormer 的性能超越了 ConvNeXt [2] : 使用了可分离卷积作为令牌混合器之后,得到一个不含任何注意力机制的纯 CNN 模型,精度超越 CVPR 2022 的 ConvNeXt。
-
CAFormer 在 ImageNet-1K 上创下了新纪录: 使用了自注意力机制作为令牌混合器之后 (前2个 stage),在 ImageNet-1K 上在224×224 的分辨率下达到了 85.5% 的 top-1 精度的新记录。
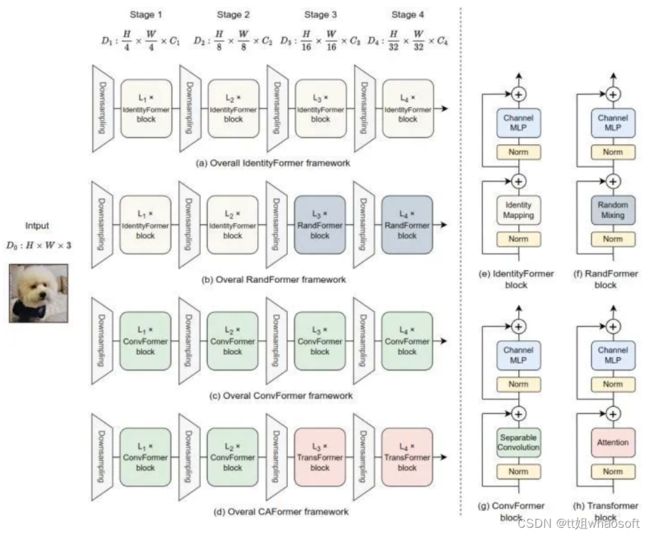
图8:IdentityFormer, RandForemr, ConvFormer 和 CAFormer 的总体架构
新的激活函数 StarReLU
作者在这个工作里面给出了一个新的激活函数 StarReLU 和2个小改动。
ReLU 激活函数
原始 Transformer 模型使用 ReLU 作为默认的激活函数,ReLU 的表达式可以写成: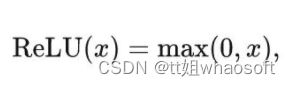
每个单元的计算量花销是 1 FLOP。
GELU 激活函数
GPT,BERT,ViT 等模型使用 GELU 作为默认的激活函数,GELU 的表达式可以写成:

Squared ReLU 激活函数
为了简化 GELU 的运算,Primer[3] 这个工作发现 CDFGD 可以使用 ReLU 替换。
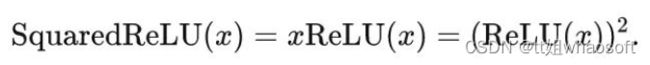 每个单元的计算量花销是 2 FLOPs。尽管 Squared ReLU 比较简单,但作者发现它在某些模型上的性能不如GELU 激活函数。作者认为,性能较差的原因可能是由于输出分布的偏移造成的。
每个单元的计算量花销是 2 FLOPs。尽管 Squared ReLU 比较简单,但作者发现它在某些模型上的性能不如GELU 激活函数。作者认为,性能较差的原因可能是由于输出分布的偏移造成的。
StarReLU 激活函数

但是,在以上公式的推导中,作者假设输入呈现出标准正态分布,这一假设很强。为了使得激活函数可以适应不同的情况,可以将 scale 和 bias 设置为可学习的参数,因此,激活函数可以统一写成:
缩放分支输出和不使用偏置
为了能把 ViT 架构做得更深,CaiT[4] 这个工作提出使用 LayerScale 方法,即给可学习分支的输出乘以一个可学习的系数: 但是最后发现 ResScale 性能最好。
但是最后发现 ResScale 性能最好。
然后,作者在 FC 层,卷积层,归一化层中都不使用偏置项,发现这样不但不会影响性能,而且还能够带来轻微的提升。
IdentityFormer 和 RandFormer 架构
IdentityFormer 的令牌混合器 (恒等映射函数实质上没有令牌混合的功能):
 PyTorch 代码如下:
PyTorch 代码如下:
import torch
import torch.nn as nn
# Identity mapping
from torch.nn import Identity
# Random mixing
class RandomMixing(nn.Module):
def __init__(self, num_tokens=196):
super().__init__()
self.random_matrix = nn.parameter.Parameter(
data=torch.softmax(torch.rand(num_tokens, num_tokens), dim=-1),
requires_grad=False)
def forward(self, x):
B, H, W, C = x.shape
x = x.reshape(B, H*W, C)
x = torch.einsum('mn, bnc -> bmc', self.random_matrix, x)
x = x.reshape(B, H, W, C)
return x
模型架构参数如下图9所示。
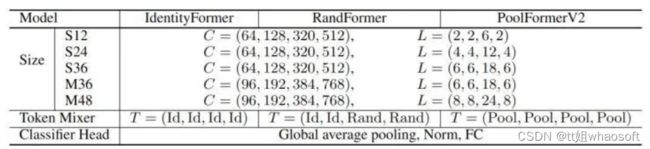
图9:IdentityFormer 和 RandFormer 的架构参数
ConvFormer 和 CAFormer 架构
ConvFormer 的令牌混合器:

PyTorch 代码如下:
import torch
import torch.nn as nn
# Separable Convolution
class SepConv(nn.Module):
"Inverted separable convolution from MobileNetV2"
def __init__(self, dim, kernel_size=7, padding=3, expansion_ratio=2, act1=nn.ReLU, act2=nn.Identity,
bias=True):
super().__init__()
med_channels = int(expansion_ratio * dim)
self.pwconv1 = nn.Linear(dim, med_channels, bias=bias) # pointwise conv implemented by FC
self.act1 = preconv_act()
self.dwconv = nn.Conv2d(med_channels, med_channels, kernel_size=kernel_size,
padding=padding, groups=med_channels, bias=bias) # depthwise conv
self.act2 = act_layer()
self.pwconv2 = nn.Linear(med_channels, dim, bias=bias) # pointwise conv implemented by FC
def forward(self, x):
# [B, H, W, C] = x.shape
x = self.pwconv1(x)
x = self.act1(x)
x = x.permute(0, 3, 1, 2) # [B, H, W, D] -> [B, D, H, W]
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # [B, D, H, W] -> [B, H, W, D]
x = self.act2(x)
x = self.pwconv2(x)
return x
模型架构参数如下图10所示。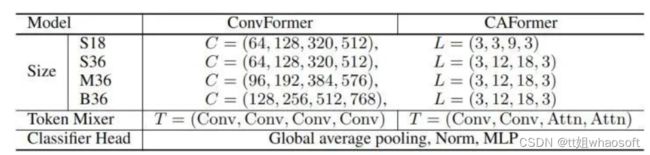 图10:ConvFormer 和 CAFormer 的架构参数
图10:ConvFormer 和 CAFormer 的架构参数
新MetaFormer 通用视觉任务的实验结果
ImageNet-1K 实验结果
训练方式1:先以 224×224 的分辨率在 ImageNet-1K 数据集上训练 300 Epochs (不使用 LayerScale,但是在最后的两个 stage 使用 ResScale。优化器使用 AdamW,Batch Size 设置为 4096,CAFormer 除外 (使用 LAMB 优化器)),再以 384×384 的分辨率在 ImageNet-1K 数据集上微调 30 Epochs。
训练方式2:先以 224×224 的分辨率在 ImageNet-21K 数据集上训练 90 Epochs,再以 224×224 或者 384×384 的分辨率在 ImageNet-1K 数据集上微调 30 Epochs。
如下图11所示是 IdentityFormer 和 RandFormer 与 RSB-ResNet 等模型对比的实验结果,下划线部分代表冻结参数的参数量。虽然令牌混合器只是恒等映射和冻结参数的随机映射矩阵,但是 IdentityFormer-S12/S24 也超过了 RSB-ResNet-18/34 4.0%/2.7% 的精度。通过缩放模型尺寸到 ~ 73M 参数和 ~ 12G MACs, IdentityFormer-M48 可以实现 80.4% 的精度,该精度已经超过 RSB-ResNet-50 的 79.8%。IdentityFormer 的结果表明,MetaFormer 对于模型性能的下限有个稳定的保底。也就是说,如果采用 MetaFormer 作为通用框架来开发自己的模型,在类似IdentityFormer-M48 的 Params 和 MACs 的情况下,精度不会低于80%。而且,RandFormer 可以持续提升 IdentityFormer 的精度。RandFormer 的结果表明了 MetaFormer 与令牌混合器的通用兼容性。因此,当配备了奇奇怪怪的令牌混合器时,可以放心 MetaFormer 的性能。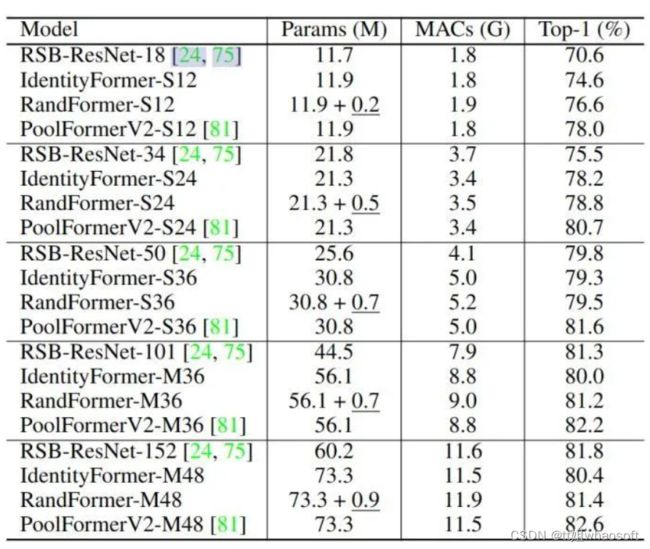 图11:IdentityFormer 和 RandFormer 实验结果
图11:IdentityFormer 和 RandFormer 实验结果
如下图12所示是 ConvFormer 和 CAFormer 与 ConvNeXt 等模型对比的实验结果,ConvFormer 实际上可以看作是一种没有任何注意力机制的纯 CNN 模型。从图中可以观察到,ConvFormer 明显优于强 CNN 基线模型ConvNeXt。比如在 224 ×224 的分辨率下,ConvFomer-B36 (100M 参数和 22.6 GMACs) 比 ConvNeXt-B (198M参数和34.4 GMACs) 高出 0.5% 的 top-1 精度。
而且,CAFormer 的性能更显著。CAFormer 只是把 ConvFormer 的前两个阶段由可分离卷积替换成了自注意力机制,但它已经持续优于其他不同规模的模型,如下图12所示。值得注意的是,CAFormer 在 ImageNet-1K 上创造了 224×224 直接训练 300 Epochs 的新记录 85.5% 的 top-1 精度,优于 MViTv2-L 等。 whaosoft aiot http://143ai.com
ConvFormer 和 CAFormer 的结果表明,即使是配备了可分离卷积这种几年前提出的 "老式" 令牌混合器,仍然可以取得显著的性能,这些结果表明MetaFormer可以提供很高的潜力。有了这些结论,当进一步将令牌混合器换成其他更高级的形式以后,取得更好的性能其实也已经不足为奇了。
图12:ConvFormer 和 CAFormer 实验结果
总结
本文介绍的这两篇文章为领域带来了全新的视角,即:视觉 Transformer 一般性的宏观架构,而不是令牌混合器 (Token Mixer) 对模型的性能更为重要。为了验证这个猜想,作者搞了一个极其简单,简单到尴尬的令牌混合器 (Token Mixer):池化操作 (Pooling)。池化操作只有最最基本的融合不同空间位置信息的能力,它没有任何的权重。但是基于它所构建的 PoolFormer 架构依然能取得不俗的性能。不仅如此,把令牌混合器分别换成恒等映射和冻结参数的随机矩阵的结果表明 MetaFormer 对于模型性能的下限有个稳定的保底,及其对于令牌混合器的通用兼容性。即使是配备了可分离卷积这种几年前提出的 "老式" 令牌混合器,仍然可以取得显著的性能,这些结果表明MetaFormer可以提供很高的潜力。